

本文由 dbaplus 社群授权转载。
自研背景
可插拔的 HBase 索引组件
NoSQL 兴起无疑是大数据时代的标志性事件,创新者们不断打破关系型数据库“一种存储模式解决所有问题”的思路,发明了很多不同的产品应对细分的数据访问模式,它们提供了更好的服务特性,比如低延时、高并发等等。HBase 是其中极具代表性的产品,作为 Hadoop 生态体系的明星产品,时至今日已在很多企业得到广泛应用。
NoSQL 这种为特定的数据使用模式设计存储系统的思路,收获了性能的大幅提升,但随着存储数据量的激增,对解决方案整体性价比的满意度却在不断走低。毕竟,相较几个 TB 和数百 TB,存储成本对用户的冲击力是不同的,人们总是不满于线性增长的成本,希望能花更少的钱做更多的事。
通过适度拓展数据访问模式提升性价比,成为业内很多技术方案追求的目标。
光大银行是金融行业中较早引入 HBase 的,经过若干年建设已经积累了大量数据。如果仅是为了满足不同条件的查询,就 copy 一个同等规模的集群,是各方都难以接受的。
HBase 作为一种 KV 数据库,数据访问模式以主键为核心,当面对非主键查询时,其原生解决方案 Filter 无法满足大多数联机应用的性能需求。所以,很多基于 HBase 的二级索引方案都在尝试应对复杂查询场景的需求。
Pharos 是基于 HBase 的技术中间件,研究起点同样是二级索引,致力于提升多条件复杂查询的性能,应用在海量数据低延时复杂查询场景。
构建思路
三种二级索引方案的选型与分析
在启动研发工作前,我们对现存的二级索引方案进行了分析,除原生 Filter 外大致可以分为三种。
Elastic Search + HBase
这个方案流行度最高,在 ES 中存储索引信息,HBase 存储数据本身,两者协同完成索引查询。方案的优点是组合成熟产品,实施难度低;但缺点也有很多,首先是整体架构复杂、设备投入增加、运维成本高;其次是性能相对较低,每一次索引查询,都要先访问 ES 获得匹配的索引后,再访问 HBase 读取数据内容,查询链路延长,带来更多的网络开销;最后是开发技能要求较高,程序员必须熟悉 ES 和 HBase 两种产品接口。
Phoenix
Phoenix 无疑是一款优秀的开源产品,产品的理念是 Put the SQL back in NoSQL。产品成熟,Apache 社区背书,都是该方案的优势。
但因为目标高远,Phoenix 的体量也偏重,这样在没有商业厂商支持下,运维难度很高(2019 年 Cloudera 宣布支持 Phoenix 后,可能会有所改善)。第二点,对 SQL 的支持成为它的核心目标,但在很多查询场景中,SQL 并非不可替代,高性能才是首要目标,性能却是 Phoenix 尚待改进的地方。Phoenix 在整体机制上,并没有实现完善的索引下推,很多情况下索引查询需要从客户端发起两次与服务端的交互,第一次获得匹配的索引信息,第二次才是匹配的数据,这无疑带来了性能损耗。
云厂商方案
在云计算时代,HBase 已经成为云服务的标配,部分公有云也提供了二级索引功能。这个方案的优点当然是厂商的一站式服务,运维成本极低。缺点首先是部分企业因为安全因素无法使用公有云,例如金融行业;其次在于技术方案本身,例如阿里的 HBase 二级索引,其内核依然是 Elastic 与 HBase 的组合,虽然接口上进行封装降低了开发难度,但架构带来的性能损耗依旧存在。
通过上述的分析,我们发现这些方案都不能满足光大银行的应用场景,因此我们决定自研产品。
我们将产品命名为 Pharos,源自英文单词 [Pharos],其含义是灯塔。这个名称有两层含义:
第一层是词义本身,灯塔对夜行的船只进行指引保证其安全地出入港口。而索引指向符合条件的数据地址,用于提升每次查数据访问操作的效率,两者有神似之处;
第二层含义,Pharos 最初是指代亚历山大灯塔,这也是世界上第一座灯塔。而 Pharos 是光大银行首次尝试自研基础产品,我们希望这个命名能够激励团队,做出有开创意义的产品。
设计目标
低延时,架构简单,非侵入性
在 Pharos 设计目标中最重要的有三点:
低延时:我们希望未来 Pharos 的应用场景不仅限于数据查询分析,也能够嵌入到业务交易系统中,这样低延时就是一个刚性需求;
架构简单:这样开发人员可以很容易上手使用,而运维的成本也很低;
非侵入性:是指对 HBase 的侵入,事实上除了前述分析的二级索引方案外,还有一些小众的二级索引方案是直接对 HBase 进行改造,但这种侵入式改造带来了后续的版本维护问题,考虑到多数企业不可能维护独立的 HBase 版本分支,我们的方案直接排除了这种技术路线,必须是对 HBase 非侵入的。
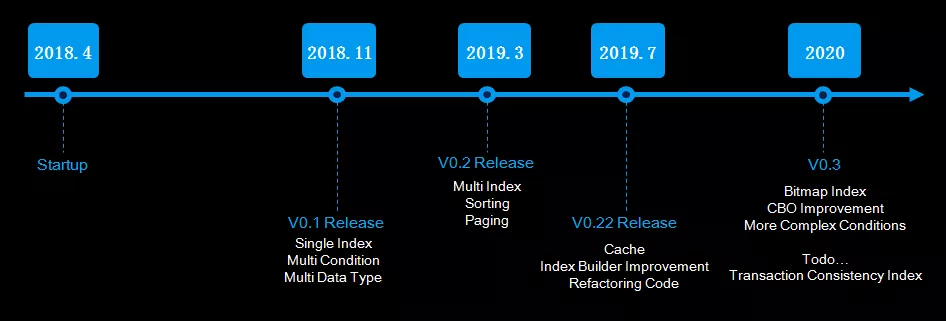
Pharos 的研发是从 2018 年开始的,相对于目前的产品成熟度来说研发过程显得有点长,主要原因是开发人力投入相对较小。我们希望随着产品的应用推广,能扩充人员,加快产品的演进速度。
研发过程,我们受到了很多同类产品的启发,包括 Phoenix、华为与 360 等公司的二级索引方案,也借鉴了很多好的设计方法,这里要特别致敬一下。
设计要点
四大关键设计的权衡
前面讲了 Pharos 的外部特性,接下来我会着重讲一些关键设计时的 tradeoff,希望对大家的研发工作有所帮助。
存储策略
HBase 是没有索引概念的,我们首先要解决的是如何存储索引。
Pharos 采用的方式是在数据表增加一个“独立列族”用于存储索引信息,利用列族对应独立文件的特点,形成独立的索引文件,不会直接受到原始数据量的影响,降低磁盘 I/O 开销。这个设计另一个好处在于,索引与数据同分布,不必干预 HBase 的 Region 分布策略。后续的所有设计都是在同 Region 基础上,这大大简化了实现的复杂度。
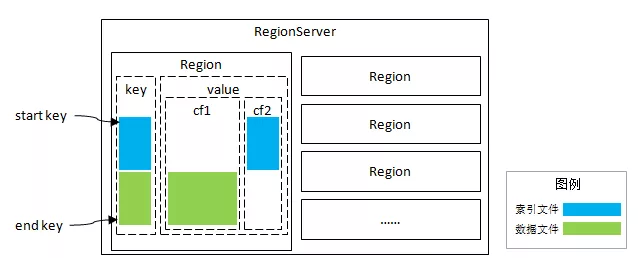
这种索引与数据同分布的模式,可以简称为“分区索引”;而索引与数据各自存储的方式,则成为“全局索引”。“全局索引”的缺点在于无法完成索引查询的下推,优点是可以进行全局控制,例如唯一索引。选择“分区索引”是因为我们期望实现低延时目标,当然同时也就放弃了对“唯一索引”的支持,至少目前是不支持的。
存储模型
索引记录的 Key 部分,最开始是 Region 头信息,保证与数据的同分布,而后是被索引字段的信息,接下来是存储索引名称等信息,数据记录的 Key 则被拼接为尾部信息;value 部分则存储反序列化的元数据。
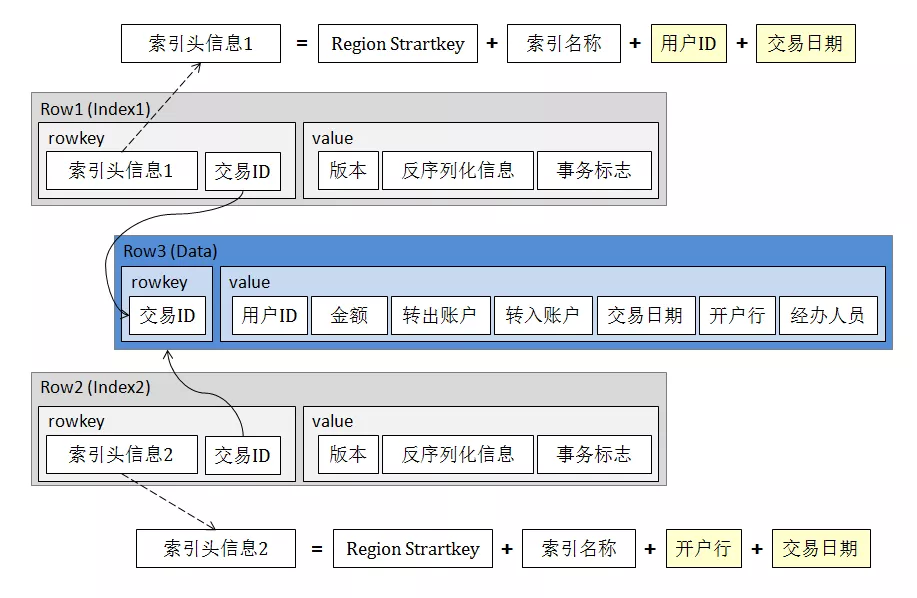
可以看到,这样设计的优点是索引检索速度快,存储成本也比较小。所以,当查询条件较复杂需要建立多个索引时,整体存储成本依然是可接受的。
分页机制
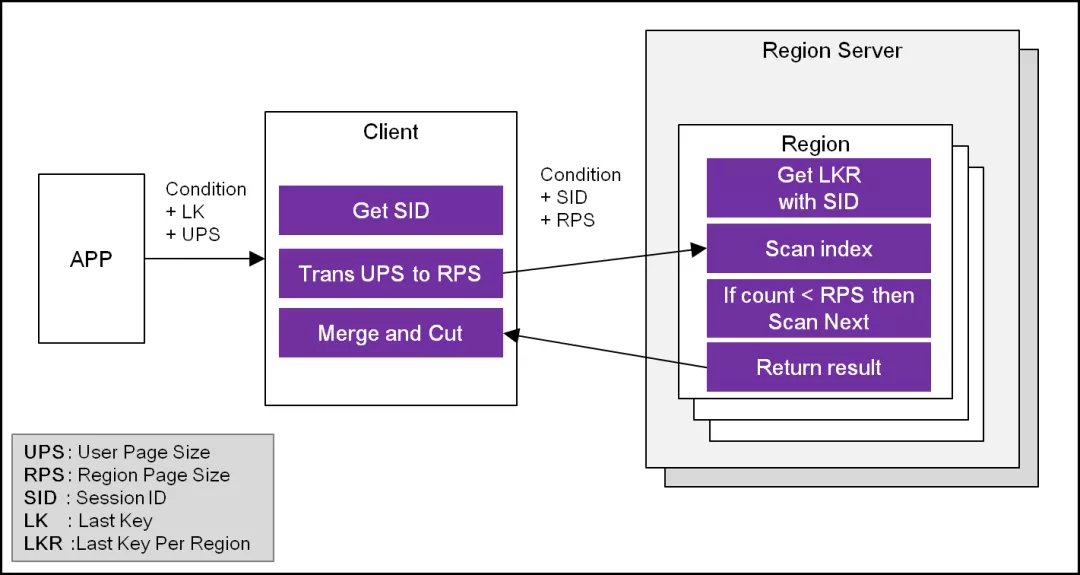
传统的后台分页方法是由应用服务记录每页的末尾记录主键,这个主键通常是由数据库提供的 row number,数据库本身并不感知分页动作。对于分布式存储的 HBase,每个 Region 都可能存在分页断点,如果延续该思路,应用端要记录大量断点信息,不仅增加传输数据量,也增大了开发的难度。在 Pharos 的设计中,我们通过 Client 作为汇聚点,缓存每个 Region 的断点信息,在 Pharos 的 Client 中增加 Session 概念,应用端仅需持有 Session ID 即可顺利完成翻页操作。
索引与数据的事务一致性(实验版本)
根据 Pharos 的存储设计,我们可以知道索引实质上是与数据行前缀相同的另一行记录,保证索引与数据的一致性要使用跨行事务,但 HBase 本身不支持跨表、跨行事务,这就成为一个死结,也是几乎所有二级索引方案都不支持索引事务一致性的原因。
这个问题的解决比较复杂,所以我们先简单介绍下 HBase 内部机制。HBase 采用 LSM-Tree 模型,在联机写入时,数据在日志和内存中各保留一份,两者通过 MVCC 与日志的协调机制可以保证事务一致性。我画了一张图来表示 HBase 1.2.6 的事务控制逻辑,具体如下:
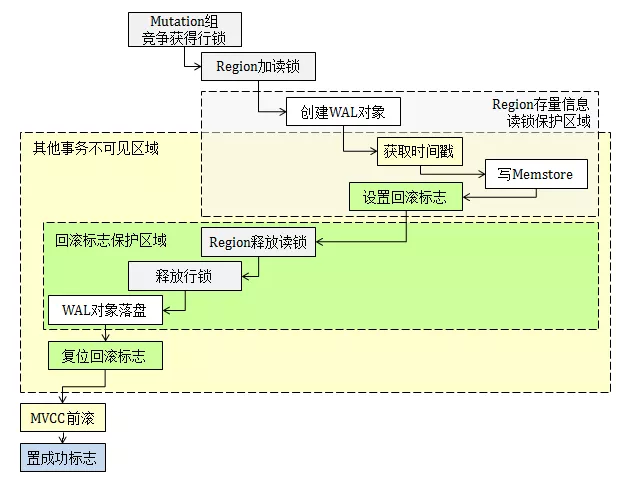
HBase 内部会监控 WAL 的异常,但在 Coprocessor 事件体系中并未开“回滚标志位”,第三方开发者也就无法回滚相关数据行。
按说,到这里问题已经无解了,不过某天恰好受到了 Percolator 事务模型的启发,找到了另一种解决问题的思路。既然无法在写入过程通过回滚控制异常情况,那我们可以延后在读取过程中来补充对异常的操作,也就是说在下一次查询操作中再次确认并维护索引的一致性。
具体处理过程是,在首次写入索引信息时,置事务标志位为“不确定”,数据行更新完成后,将该标志改为“成功”;如果出现回滚,则标志位保留“不确定”状态。查询操作中一旦发现“不确定”标志,则根据索引查找相应的数据行是否存在,如存在,则将该标志更新为“成功”。
我们用流程图来体现处理过程,如下图:
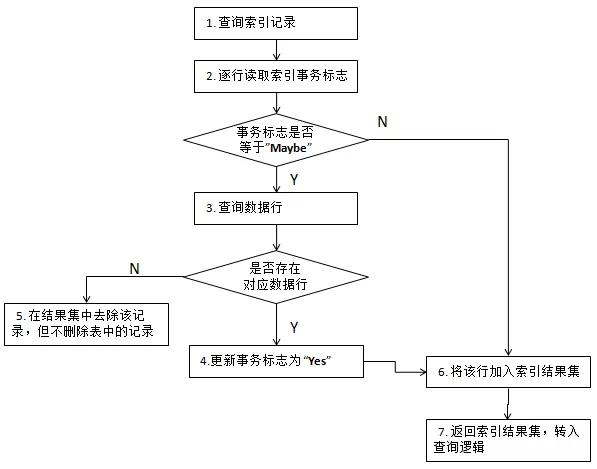
该方式付出的代价是写入时需要两次更新事务标志,相对于仅写入数据行(无索引)肯定增加了一些开销,在测试环境下我们发现损耗在 15%左右,主要是指延时;在查询环节虽然存在确认索引事务的可能性,但因为其发生的概率极低,不会对查询产生实质性影响。
未来展望
彻底解决 Region 分裂问题
目前 Pharos 主要还是在内部使用场景中测试,收集需求和问题,近期我们会发布 V0.3 版本。新版本会推出一些让人激动的特性,主要仍是围绕查询性能的提升,推出 Pharos 自有的数据组织形式,提供更加丰富的查询加速手段,完成从二级索引组件到一个完整的技术中间件的演进。
其中,特别重要的一点是彻底解决了 Region 分裂问题,我要迫不及待地做个剧透。
Region 分裂是 HBase 数据再平衡的手段,保证每个数据节点上的数据量分布大致平均,也会有一些打散热点的效果。但是,分裂机制却破坏了索引与数据的同分布,在同类方案中通常采用很重的更新操作来调整索引的位置,追随数据的分布情况。
这种方式显得过于笨拙,并且更新过程会影响整体方案的可用性。因此,Pharos 在 V0.22 版本中是建议索引延后加载,这样在数据更新导致的重分布完成后再更新索引。
实际操作中,这种方式要重复读取数据文件,延长了整体数据加载周期,对运维操作来说不够友好。在 V0.3 中,我们加入了 Pharos 自有的数据组织方式,实现在 Region 分裂时维持索引的同分布效果。
考虑到篇幅的限制,就介绍到这里。几个月后,我会择机与大家分享在新版本的改进,使用了更多独创性的方法,敬请期待。
作者介绍:
王磊(Ivan),光大银行科技部数据领域架构师,曾任职于 IBM 全球咨询服务部从事技术咨询工作,具有十余年数据领域研发及咨询经验。目前负责全行数据领域系统的日常架构管理、重点系统架构设计及内部研发等工作,对分布式数据库、Hadoop 等基础架构研究有浓厚兴趣。个人公众号:金融数士。
原文链接:
https://mp.weixin.qq.com/s/fzGVDYJ33uMDqPj7Vx6ytA

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论