

本文由 dbaplus 社群授权转载。
分享概要
1、PG 社区的独特性
2、PG 的商业能力和创新能力
3、PG 新版本与新特性
4、PG on 云
最近几年我在推过 PG 的活动中,走过差不多 15、16 个国内城市,遇到不少参会者问到这样一些问题:
学生非常关心学习 PG 能从事什么样的工作、未来发展机会如何?
用户特别关心迁移到 PG 是不是最终状态?它是不是未来的趋势?
作为一个开源数据库,背后是不是有商业公司在控制着它?
所以,我首先会分享 PG 社区的内容。
一、PG 社区的独特性
如果说 99%的开源数据库都是被商业公司控制的,那么 PG 是那 1%。
要说商业公司为什么要把数据库开源出来?为什么要改协议?这个我们先来分析一下:今天你要研发一款数据库,并且得到市场的认可,如果不开源的话,你会发现这个数据库必须要有很好的渠道才能赚钱,所以商业公司选择开源,培养背书群体,扩大生态,收割大客户。
至于为什么要改协议?我们看到许多商业开源数据库都有对应的付费版本,例如企业版,高级周边工具等。随着上云成为了大趋势,“云开源数据库服务”吞噬着开源数据库市场,用户更多选择的是云服务,而不是开源数据库的企业版,这就造成了商业开源公司与云发生利益冲突,改协议是商业开源数据库厂商被迫的选择。
而 PG 是一个纯社区的数据库,背后没有被任何一家公司所控制。我们来看一下以下这张图:
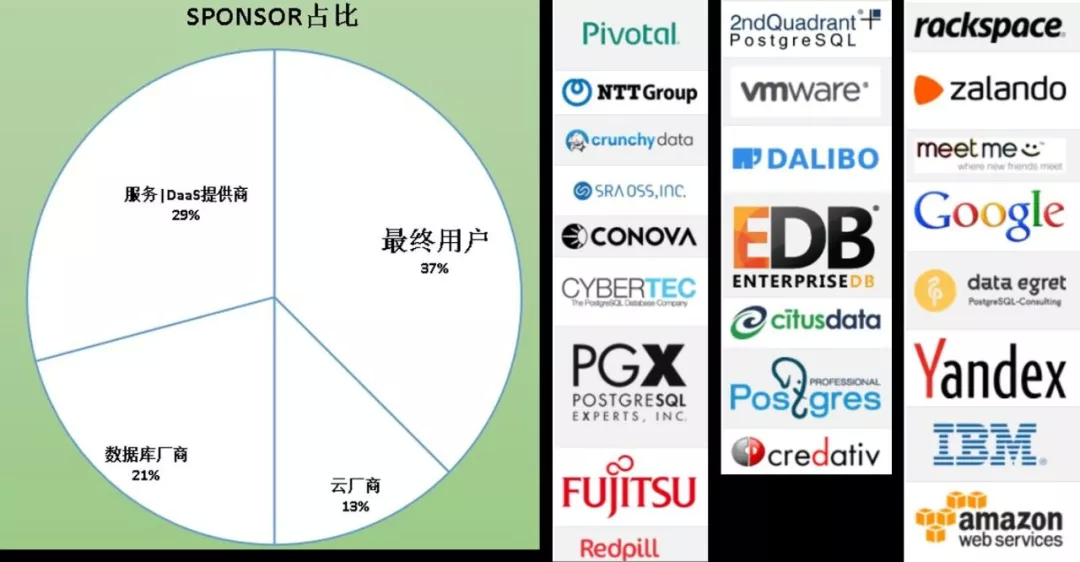
饼图展现的是给 PG 贡献代码的占比,我们先看数据,后面再跟大家分析一下原因。看图你会发现占最大头的是用户,第二是数据库服务商,这里的服务包括培训、技术支持类的服务等。这两大块加起来就有 66%了,剩下的就是数据库厂商和云厂商。
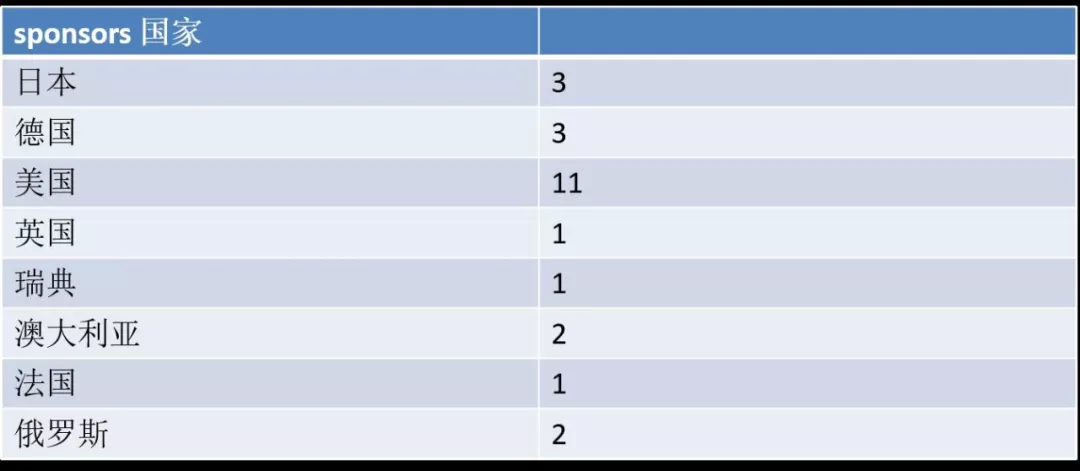
上图是给 PG 贡献代码的国家分布,上面没有中国有点遗憾,但可能是因为这个至少要贡献两年以上才入列,所以中国估计过两年会出现在这里。
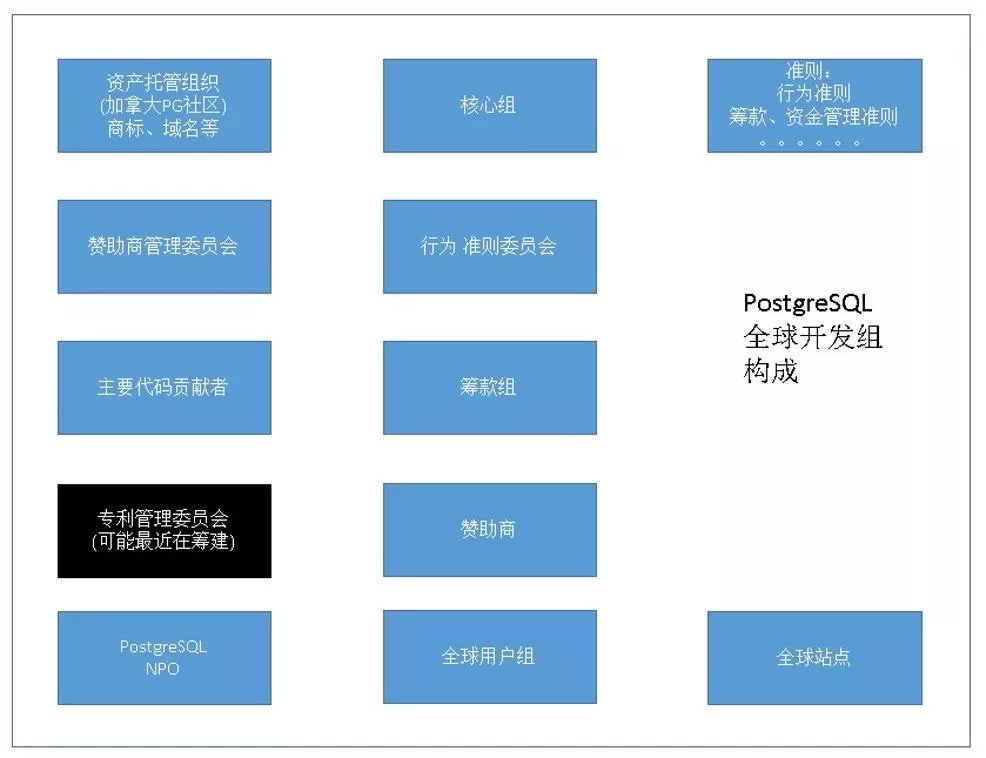
PG 作为一个开源的社区数据库活了这么久(追述到 ingres 的话有 43 年历史),感觉牙齿不但没掉还越来越锋利。凭什么?PG 有组织有纪律,从上图可以看到首先是资产托管组织,包括商标、域名等,每年的开发者峰会在加拿大举办。
另外还有核心组、行为准则团队,类似于组织部,有专门管赞助的委员会、筹款组等等。将来可能会组建专门负责管理专利的委员会,因为作为开源数据库会发现专利可能是一个非常容易存在的漏洞点,PG 对专利控制还是比较严格的。
回过头分析刚刚给 PG 社区贡献代码的企业,他们为什么要持续贡献核心代码?
对于数据库厂商来说,推一款新的商业数据库通常都需要背书,试问小厂产品谁为你背书?
只有技术的厂商,很难挑战已有数据库市场格局。
只有渠道的厂商,需要抓住窗口期,快速占领市场,避免重复造轮子,需要一款可以无法律风险,二次开发与分发的开源数据库。目前达到商业化成熟度的唯有 PG。
所以数据库厂商需要通过贡献核心代码,社区所有的用户都可以为之背书。
对于数据库服务提供商来说,开源产品的服务提供商,怎么才能体现他们的能力?谁能证明他们的牛逼?贡献代码,贡献代码之后用 PG 的那些人就可以为之背书。
对于最终用户来说,他们希望社区长久,期望可以享受免费的、可持续发展的、开源的、不被任何商业公司、不被任何国家控制的企业级的数据库。而且 PG 用的人越多,越多人背书,使用越靠谱,就像滚雪球一样越滚越大,所以最终用户愿意贡献代码,实际上是在推动开源产品的发展,对客户自己也是有利的。
对于云厂商来说,自己做一款数据库在云上卖需要培养生态,需要市场背书,需要大量研发资源,可能还需要重复造轮子。那么基于 PG,就能免去自己培养生态,避免重复造轮子,而且 PG 的代码基础已经具备商业化基础。另外,不断提供代码也是防止其他厂商控制 PG 失去市场主导能力的方法。
开源许可独特性
除了以上这些原因,还有很重要的一点,开源许可独特性。PG 的开源许可是类 BSD 许可,可以随意分发、闭源或开源,可以被用于商业目的或其他场合。

PG 开源中心的这行字(见红框),说的是不管怎么使用、拷贝、修改、分发这个软件,只要把这一行放到你的输出版本里面去就行了。是不是活雷锋?所以云厂商选择这么友好的纯社区版本感觉像拣到宝一样。
架构独特性
作为一款开源出来拿去直接用的数据库,PG 采用了开放接口的设计,是最具扩展能力的数据库。基于 PG 的图数据库、流数据库、GIS、时序数据库、推荐数据库、搜索引擎等;围绕 PG 的应用垂直化插件机器学习、图像识别、分词、向量计算、MPP 等,基本上都是使用 PG 扩展接口扩展出来的。
商业趋势
目前全球都在提高安全、合规、正版化意识,对于数据库厂商、云厂商来说,从长远来看,纯社区具有这么强的可扩展能力的数据库,PG 可以说是首选。生态已经摆在这里了,还有不去用的理由吗?
技术趋势
首先,PG 是一款远远超越当前关系数据库的多模数据库,因为它的开放性,可以随意扩展。
其次,在内置并行计算方面,我接触过很多用户的数据库就跟蜘蛛网一样,为什么?因为用户的业务需求很多,关系数据库处理不了,需要将数据同步到其他引擎:最常见的有计算平台、搜索引擎,还有一些客户要同步到流计算平台,空间,时序数据库平台等。同步会带来硬件、管理、开发成本的增加,同时会引入数据丢失、延迟等风险。如果数据库提供并行计算、搜索、时空等多模能力的话,没必要把平台建这么复杂。
再次,PG 开始在内核中支持存储引擎的扩展,可以解决行存、列存、内存引擎,多样化的多版本控制,等不同场景不同需求的问题。
最后,在芯片支持方面,PG 对芯片友好,例如 ARM 芯片的支持。
以上四方面满足市场的既要又要还要的需求,即:既要 SQL 通用性,又要 NOSQL 扩展性,还要多模开发便捷性;既要 OLTP 又要 OLAP。
二、PG 的商业能力与创新能力
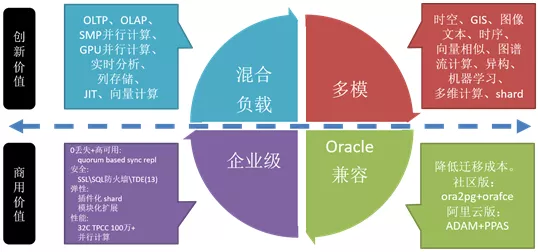
对于数据库的商用价值来讲,首先是能不能扛住企业级的需求,也就是能不能做到零丢失、高可用、安全;弹性这一块就是能不能横向扩展、能不能做模块化;而性能这一块 TP、AP 都可以跑。Oracle 兼容性体现两块:社区版本有这样的插件,加完这个插件在 Oracle 数据类型然后还有函数,还有操作服务这一块做的兼容,包括包也做的一些。因为用户我见过大量的使用 PLsql 的存储过程或函数,一个业务部就有上百万行,使用 PG 的 plpgsql 可以改造这些 oracle plsql 存储过程代码。
另一方面吗,阿里云提供兼容 Oracle 的数据库 PPAS(实际上也是基于 PG 的),我们兼容了 PLsql 语法,能够减轻用户区改造存储过程到 PG 的工作,所以说这个东西熟悉之后你会发现 PLPgsql 能够满足功能差不多,没有会弱到哪里去,其实做得挺好的。
在创新能力上,其实我们刚刚讲到了一块关于边缘计算,边缘计算分两块:基于 GPU 的并行,对用户是透明的,数据库会根据 sql 的成本、代价去启动 GPU 并行计算。
阿里在这里同样开源,阿里因为在线上有很多的用户,包括影像处理、移动跟踪做了 GPU 加速。这就是创新价值。
多模使得 PG 这个数据库得以满足那些你曾经想都不敢想的需求。
三、PG 新版本与新特性
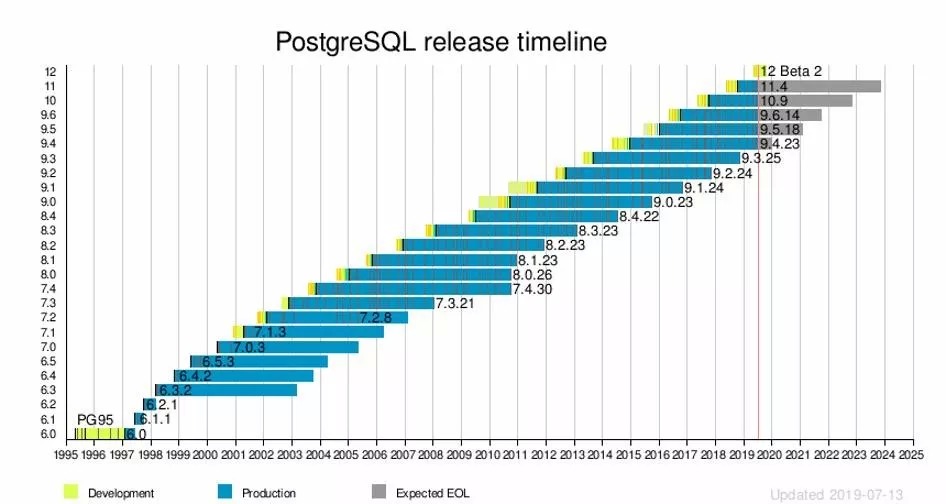
上图展示的是 PG 版本发布节奏,如果每年股票是这样涨的话大家肯定很开心。作为背后没有商业公司没有驱动的开源数据库,PG 每年发一个大版本,每个大版本会持续维护五年,有组织有纪律就是不一样。
PG 11 新特性
PG 11 是去年发的,有什么新特性?在此说明一下,我这里说的特性全部基于 PG 自己,比如基于 11 以前的版本,其实有很多功能很早之前就已经支撑。
1)分区表增强
hash 分区;
支持触发器;
支持默认分区;
允许修改分区字段。
2)并行计算增强
对业务完全透明的并行计算,几乎覆盖所有的场景,平均 20 倍的提升。
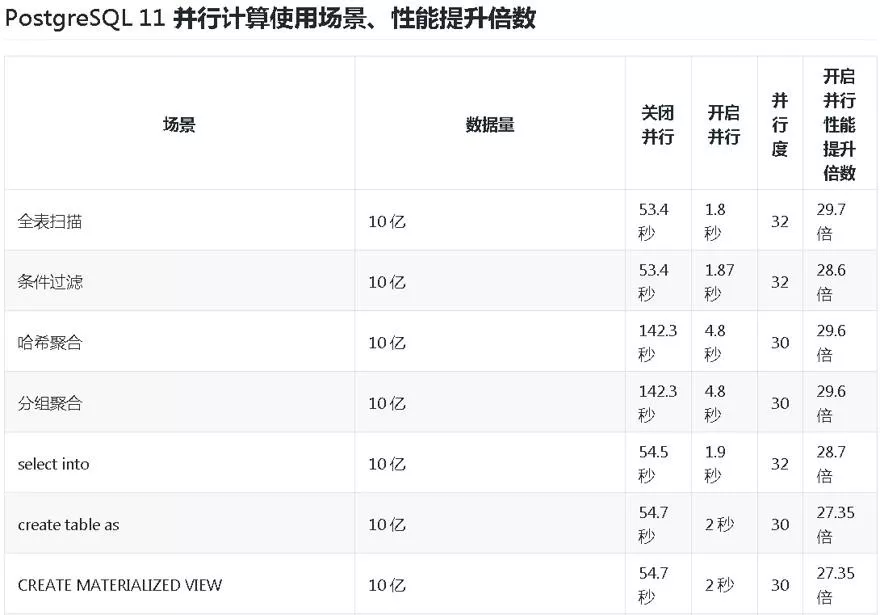

以上这个 CASE 数据量 10 亿的表,大家觉得 10 亿做排序要多久?不到 3 秒,不开并行需要 70 多秒。
什么时候要用并行计算?通常是实时分析,复杂查询,马上就要看到结果,原来需要 T+1,现在就想做实时。
我们来看一下这些 CASE,第一个是最简单的全表扫描,要将近 1 分钟。开并行只需要 1.8 秒。
哈希聚合,因为我们做分析一定会涉及到聚合,处理大量的数据,有哈希聚合、分组聚合。10 亿记录的聚合需要花多少时间?5 秒!不开并行需要 140 多秒。
做数据分析处理一般流程比较长,会有中间结果。这些中间结果可能是通过 create table as 这种方式出来的,这种操作能不能支持运行?也可以。同样也是 10 亿的数据量,差不多 1.9 秒。
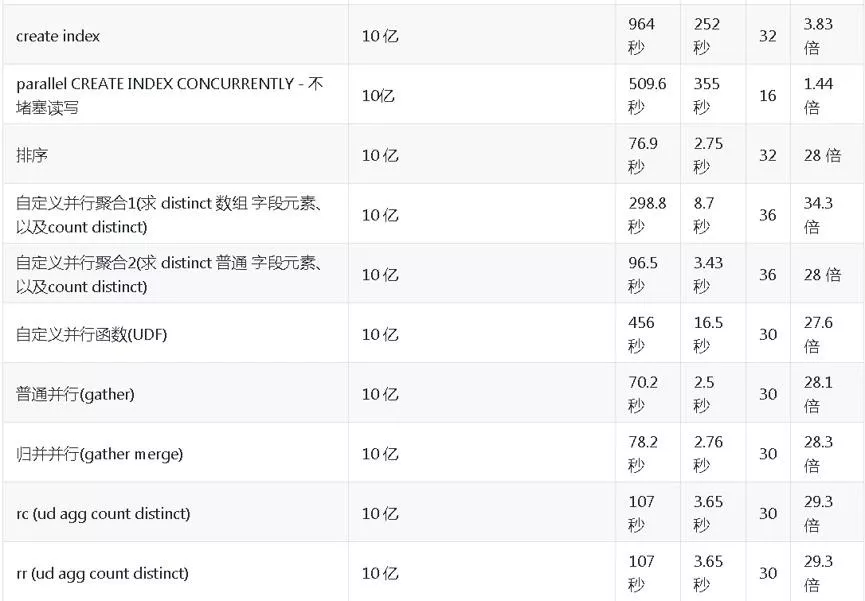
创建索引,想不想很快完成?比如说这个索引膨胀,你想快速重建索引发现性能不行,10 亿记录不带并行将近 1000 秒,开启并行后只需要 252 秒。
关于聚合的话,数据库会提供一些聚合函数,比如说平均值、标准方差,有些时候发现数据库提供聚合的方式不够用,不能满足你的业务要求。所以的话需要自定义聚合,自定义聚合操作也支持并行,这边也做了两个测试,一个求(count distinct)个数,另一个求 count distinct 数组元素个数。分别从 300,100 秒降到了 8 秒,3 秒。
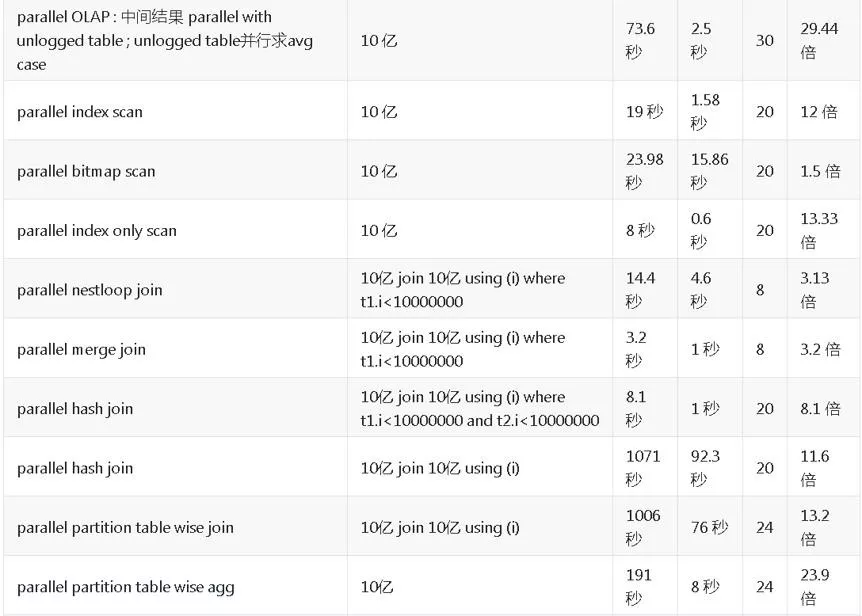
另外还进行了其他复杂查询(join、cte、subquery、排序、分区查询等),不再一一赘述,性能平均提速 20 倍左右。
3)btree index include 索引叶子附加属性
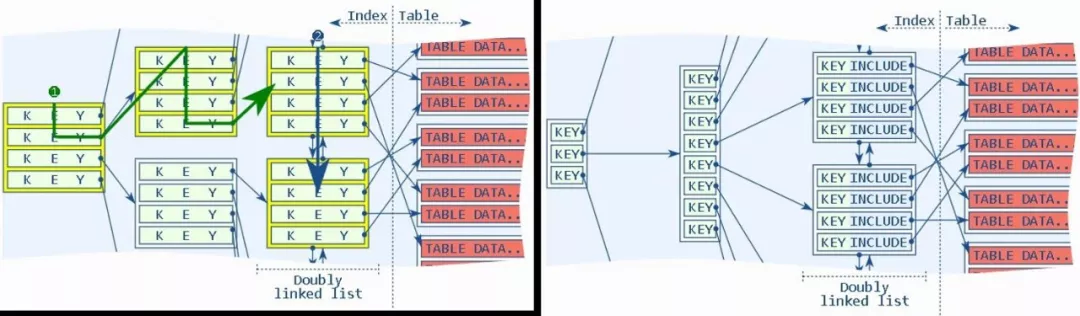
这个特性比较有意思,创建索引的时候一般怎么做?制定字段放进去,这些字段是我要查的。我这里举一个例子说,用非索引组的表,数据怎么存放?写进来没有任何顺序。
比如说有这样的业务做移动对象跟踪,共享单车,我们在手机里可以看历史轨迹,由上报的点组成。一般来说行程会涉及到上千个点。上报的数据是一条一条插进来的,这个世界有很多人同时骑车,也就是说很多人都在上报数据。你去查某一笔订单的轨迹,我们怎么通常怎么优化?在订单号加索引,感觉挺快的。但是有没有想过这个问题在那里?你的数据是无序存储,1000 条记录可能是分布在 1000 个数据块,如果同时有大量并发查询可以把 IO 打满,即使这个数据在内存,也很容易触达内存带宽上限。
最后怎么解决这个问题?通常建个合索引,可以查出来。当然可以了,但是这里出现另外一个问题,这个 Key 在索引 page 的每个层面都是多个 Key,他的这种 split 概率就会增加。但是实际上查询条件就是驱动列,就是你的订单号的哪一列。所以实际上可以创建索引的时候还是用订单号,但是我把你的时间放到 leaf page,同一个订单的附加字段的数据被放到了同一个订单所在的叶子里面。这个时候来查询,因为这个数据一千个点只落在三五数据块。Include index 相比较索引组织表的好处:我可以创建很多个按你的要求来的索引组织,好像同一份数据有很多数据组织结构一样。然而索引组织表只有一种结构。
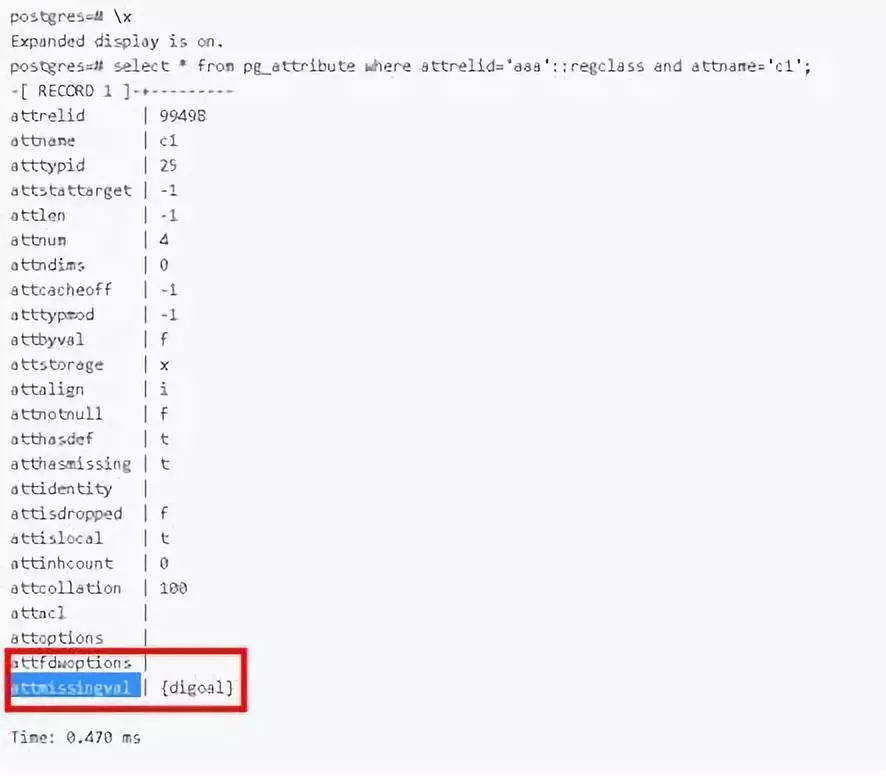
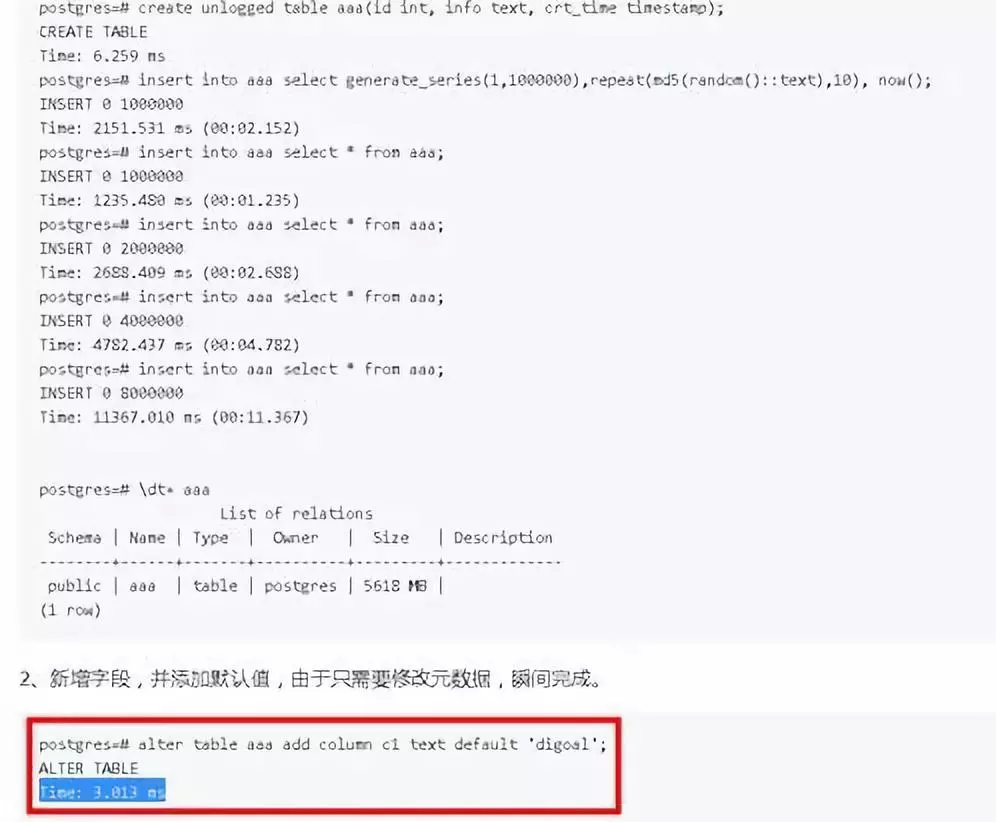
4)添加字段(含默认值)更快
以前添加字段不加否认值就是改一个原数据,以前加默认值做 table rewrite 所以慢。现在我们会变成甭管加什么字段,甭管是否包括默认值,总之瞬间完成。对用户特别友好。
5)支持存储过程
在存储过程中,支持子事务提交。
PG 12 新特性
1)AM 接口
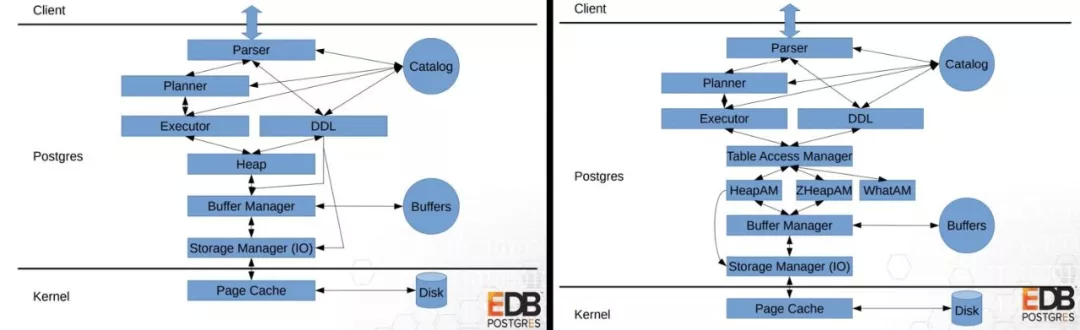
如上图所示,左边是 12 以前的版本,右边是 12 版本。12 中间加了一层访问方法,这里面有索引方法或表访问方法,剥出来的好处就是我们可以在这个地方加新的数据存储结构,例如加内存表、列存表,压缩表等,都可以在这一层去做。
所以就有了列存的引擎,这里举两个例子,zedstore(列存)和 zheap(支持回滚段)。列存压缩率高,支持向量计算,非常适合做批量计算,分析领域的性能提升很明显。
第二就是 zheap,把回滚段从数据存储剥离出来,旧的版本拷贝到回滚段去,查到过去的版本去回滚段查,减少膨胀问题。
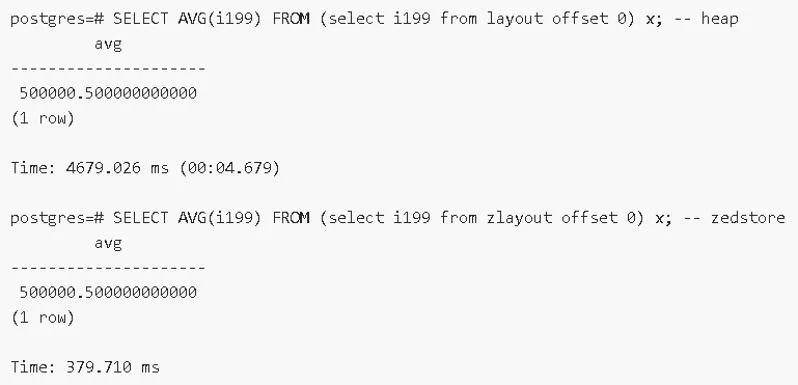
2)分区表-大量分区性能提升
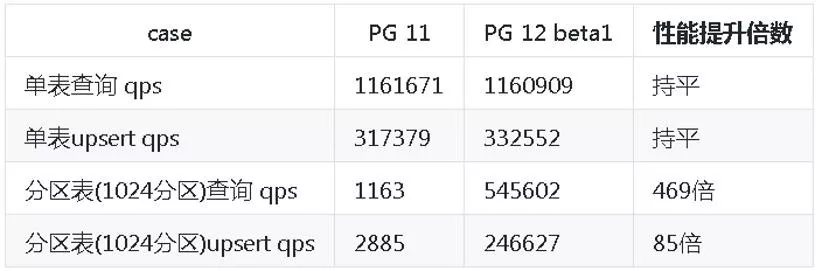
原生分区(包括 11 的版本)分区很多有性能问题,12 这一块已经优化掉,在 1000 个分区时,查询有提升 400 多倍。分区越多,性能提升越明显。
3)GiST index include 索引叶子附加属性
正轨迹,时空搜索;
按结果集(索引)聚集存储,消除回表 IO 放大。
4)CTE 物化、非物化
物化的下推,在 12 版本里面可以指定要不要物化,如果是物化的话,物化的子句跟外面完全隔离,相当于这一层单独计算。如果指定不要物化,那么优化器会考虑子句外面的条件,可以将条件传递给非物化子句,提前过滤,提高性能。

5)日志采样
日志采样,相当于之前做审计日志,你要么全开,要么全关。实际上有的用户要的是不要所有的采下来,比如说做排错,同类错误不需要都被记录下来,采样就可以了。又比如说查询访问量特别大,如果所有的 sql 全审计下来会影响性能。使用这个采样的功能,不会影响性能。
6)COPY WHERE


Copy 时支持过滤条件,可以在导入数据时过滤不需要的记录。
四、PG on 云
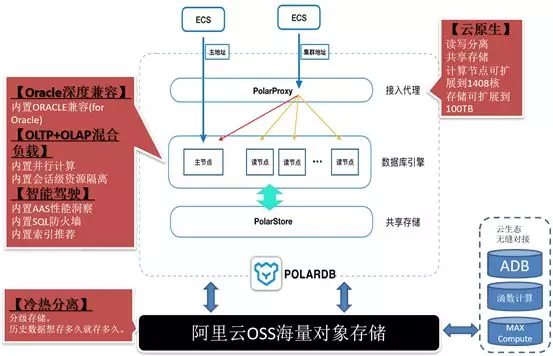
作为阿里巴巴自主研发的下一代关系型分布式云原生数据库,PolarDB 目前兼容三种数据库引擎:MySQL、PostgreSQL、高度兼容 Oracle 语法。计算能力最高可扩展至 1000 核以上,存储容量最高可达 100T。
兼容 Oracle 语法的引擎:高度兼容 Oracle 语法,降低 Oracle 迁移风险、缩短迁移周期,助力企业快速替换 Oracle,进入云智能时代。
兼容 PostgreSQL 的引擎:完全兼容 PostgreSQL,支持计算与存储分离、独立伸缩,存储按量付费。业务透明读写分离(该项功能开发中)。适合中大型企业核心业务场景。
作者介绍:
digoal(德哥),PostgreSQL 中国社区发起人之一、常委、兼任社区大学校长。阿里云数据库首席专家团队成员,提供数据库首席专家服务。现任职于阿里云数据库团队,主要负责阿里云 PostgreSQL 产品线,包括 RDS PG、PPAS(兼容 Oracle)、POLARDB 兼容 PG、Oracle 语法引擎的产品设计、推广、应用落地与生态构建。
原文链接:

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论