
曹振团:简单先自我介绍一下:我大概 06 年出来工作,那时候我们在做移动增值的方向,那个时候也是一个风口,当 06 年大家在用短信拜年的时候我们做彩信,我们的拜年短信是可以鞠躬的;之后就转战到网易,在网易的时候也是在争抢移动互联网的入口——做应用市场,那时候也打的一片火热;13 年时加入了美团,也就是现在的新美大,进入美团的前半年时间里面一直在摸索一些新的事情和新的方向:我们到底要做什么?大概在 2013 年的 10 月份我们决定做外卖这个事情。
下面简单介绍一下外卖现在的情况:我们从 2013 年 10 月份做外卖的事情,是从餐饮外卖开始的。经过两年多的发展,我们不光可以提供餐饮外卖,也可以提供水果、鲜花、蛋糕、下午茶甚至是超市和便利店一些外送的服务。我们做外卖过程中,我们发现用户对外送的体验有两个关注点:
-
第一个是品质,用户对品质要求非常高,送过来的饭不能凉了,不能不好看,送餐员身上脏兮兮也不行会影响食欲的;
-
另外一个关注点要准时,一定要按时间送到,比如我要求按 12 点送到就一定要按 12 点送到,不能早也不能晚,如果早为什么不好呢?11 点 40 送到不行,我们正在跟老板开会,一会一个电话太烦了;12 点 20 送来也不行,太饿了,我都饿晕了,中午也有很多的安排,吃完饭可能要睡一会,中午不睡下午崩溃呀。
我们发现如果要把用户体验做到极致的话,做得足够好能保证用户得到足够好的体验,我们就要做专送的服务。所以我们正在做的是美团外卖的平台和我们自己的配送服务。
我们从 2013 年 10 月份确立做这个事情,到 11 月份正式上线,到 14 年底 11 月份时突破日订单一百万单,15 年的 5 月份大概突破了每天两百万单,然后大概 15 年 12 月份做到每天三百万单,今年 5 月份的时候我们做到了四百万单每天。我们希望在响应国家大的号召下,我们做供给侧改革。我们希望给大家提供更多的、优质的、可选的外送服务,希望未来的某一天做到每天 1000 万单。
介绍一下我们的业务,也介绍一下在做这个业务过程中技术架构的演进的历程。我们在开始做外卖的时候发现,那时候都是通过电话来点外卖的,小餐馆的老板发传单,我们用传单上的电话给老板打电话下单。我们在思考我们是不是可以把电话点餐的事情变成网络点餐,让用户只需要在网络上点点点就行了,不用打电话。
于是我们在公司周围的商家摸索这个事情,我们早上下了地铁在地铁口发传单。我们怎么能够最快地去验证这个事情是否可行?我们提供了一个非常简单的 Web 版本和 Android 的 App,对于商家那一边我们没有提供任何软件的服务,用户在我们平台里下单以后,我们再打电话给商家下单,有时候我们是发传单的,有时候我们是接线员,用户在我们平台上下单,我们再打电话给商家下单,然后再去写代码。那时候基本上没有太多架构考虑,就是怎么快怎么来,以最快的速度去把我们的功能给变上去。
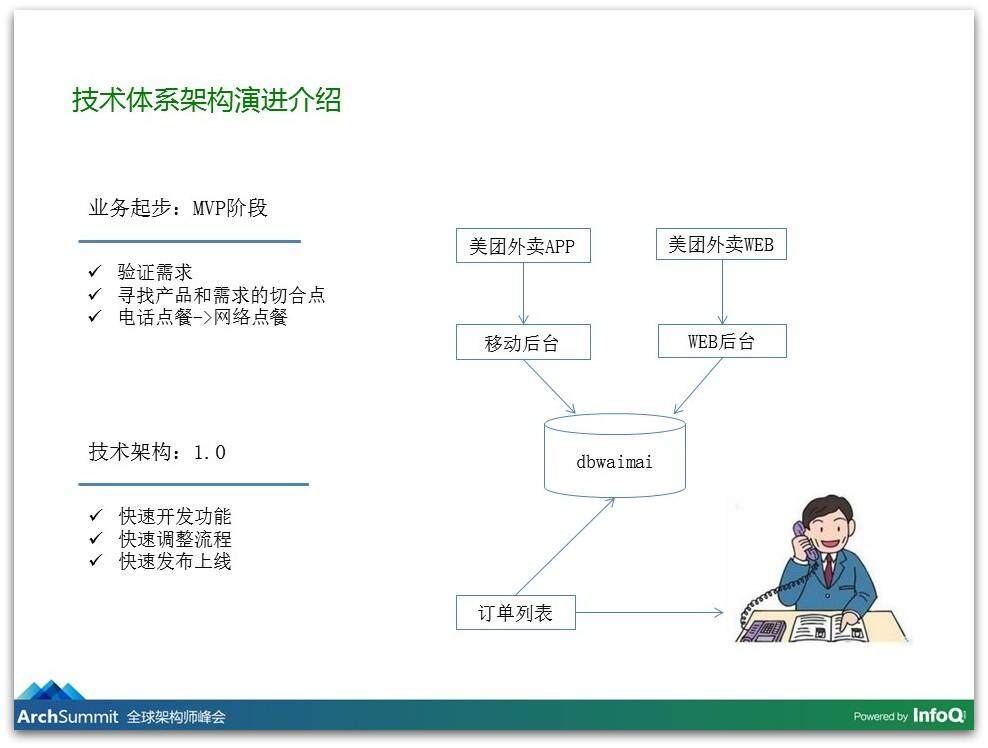
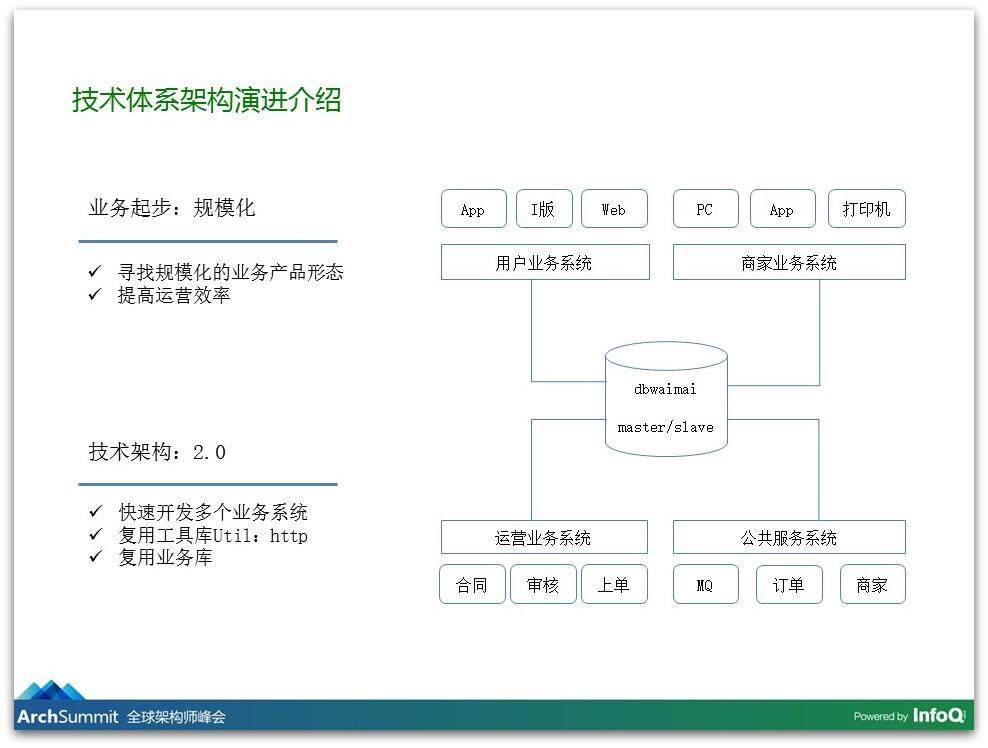
这个事情我们验证之后发现确实可行,我们发现“懒”是极大的需求。因为懒得去换台,所以发明了遥控器,懒得爬楼梯就发明了电梯,人都是很懒的,因为懒得打电话订餐,所以在网上点点点就好了。我们发现这是极强的需求,于是我们就考虑规模化,因为只有规模化之后边际的成本才可以变低,这套软件在一个区域可以用,在一个城市可以用、在全国也可以用,我们的开发成本就是这么多,所以我们在尝试在做规模化。
这个过程爆发性产生了非常多系统,我们在用户这边提供各种 APP,商家这一边我们也开始提供服务。我们给商家提供 PC 的版本、App 版本,还给商家提供打印机。打印机是跟我们后台是联网的,如果用户在我们平台上下单,我们会直接推送到这个打印机上,这个打印机可以直接打出单子,同时可以用林志玲或者郭德纲的声音告诉你:“你有美团外卖的订单请及时处理”,这是对商家非常好的效率提升;同时我们给自身运营的系统加了很多功能,我们有上单、审核等各种各样的系统等爆发性地产生了。
在这个阶段我们业务发展特别快导致我们堆了特别多的系统,这个时候也并没有做非常清晰的架构,就是想把这个系统尽快地提供上线。这时候所有的表都在一个数据库里,大家都对这件事情非常熟悉,我可以做订单,也可以做管理系统。
但是这个事情在规模化、用户量迅速上升之后给我们带来非常大的困扰,因为之前我们是有很多技术欠债的,在这个阶段里面我们就做了重大的架构调整,在这个调整里主要说两点:
-
第一点就是拆,我们把很多耦合在一起的服务做服务化拆分,服务与服务之间通过接口来调用和访问,服务自己保护自己的库:不能访问别人的库,否则叫出轨;你的数据库也不能被别人访问,否则叫绿帽子。
-
第二点是中间件,我们在这个阶段引进了很多中间件,包括了在开源基础上自研的 KV 系统,我们也引用了搜索 Elasticsearch,我们通过 Databus 抓取数据库的变更,把数据库的实时变更刷到缓存和索引里,让这个中间件做到稳定可靠的服务。
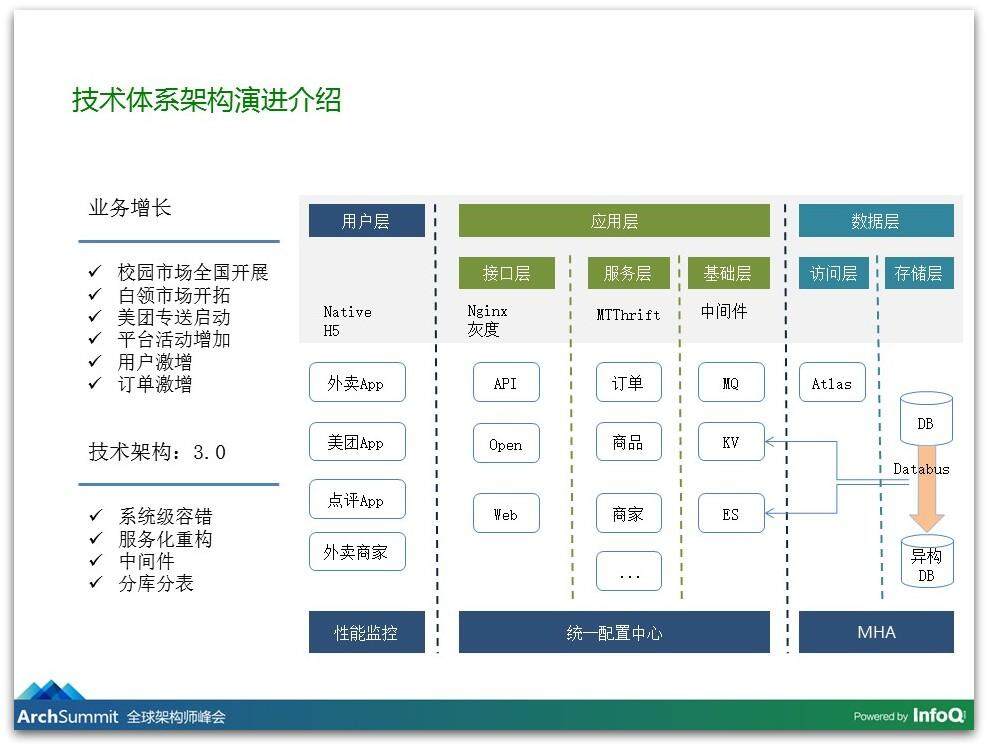
总结一下的话,我们的演进大概分了这样一个阶段:整体上有一个多逻辑耦合在一起的情况按服务化拆分出来,每一个服务独立专注地做一个事情,然后我们再做应用级的容错,到现在我们在做多机房的容错。
在缓存上,我们早期使用了 Redis,在 Redis Cluster 还没发布之前我们用了他们的 Alpha 版本,当然也踩了很多坑。后来我们用了自研的 KV 系统,最早的时候我们把所有业务的 KV 都是共用的,这个也有很大的问题:如果所有的业务共用的 KV 集群,其中某一个业务导致这个 KV 集群有问题的话,所有的业务都受影响。后来我们也做了每一个业务拆分自己专用的 KV 集群。
在数据库这一层上,基本上是把一些大表的查询、对数据库有较大伤害的查询变成了高级的搜索,在数据库和应用层之间加了中间件。在 360 开源的 Atlas 基础上做了我们自己的定制,这个中间件有个好处:我们对数据库的变更对于业务层是透明的,比如说觉得能力不够要扩容,我们加几台从库,业务方是无感知的,而且我们会做 SQL 的分组,即数据库的分组,哪些 SQL 到哪个数据库上,到主库还是从库上去,我们业务是不用关心的。

下面介绍一下做外卖这个事情上遇到的挑战:
-
第一个挑战,外卖这个事情具有一个典型的特点,就是聚集在中午和晚上两个吃饭的高峰期,这天然就是非常集中的秒杀的场景,因为大家会集中在 11 点 10 分到 11 点半去下单。我们在高峰期的时候,有一分钟接进 2 万单的巨大流量;
-
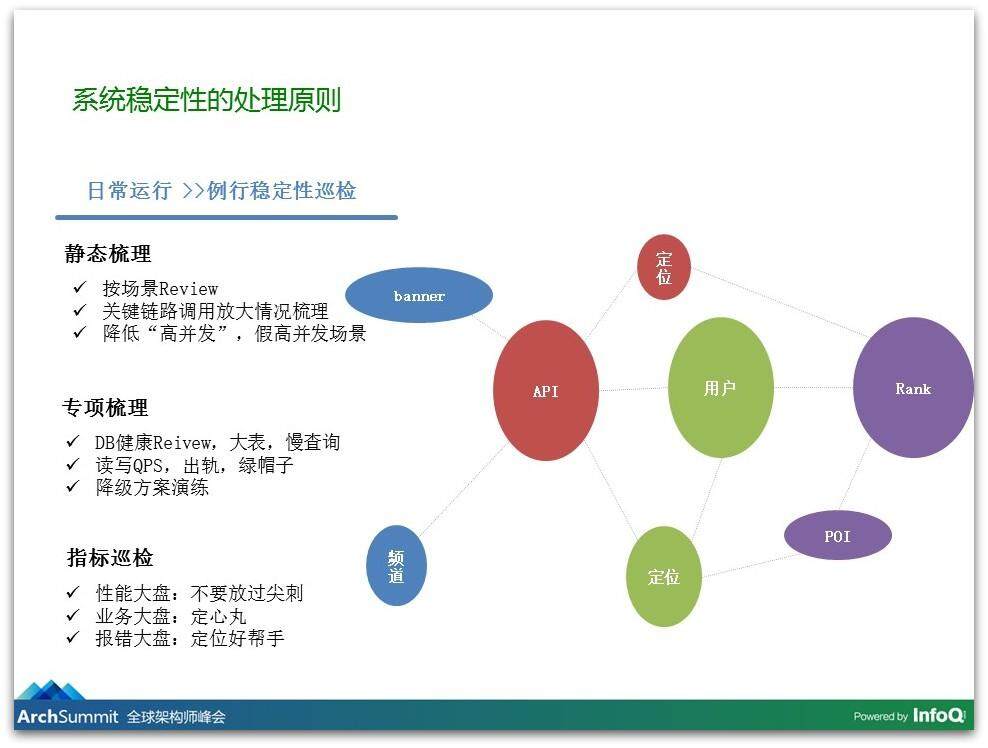
第二个挑战,大家理解送外卖是一个很简单的事情,我点了餐,送过来,我愉快的把它吃掉就结束了,但是做外卖的事情上我们发现确实蛮复杂的,因为我们发现用户要下单,要支付,我们还要调度一个配送员,我们找一个最快最合理的骑手,让他到时间取餐送过去,同时还要给这个骑手最好的路径规划,告诉他走这条路是最快的。所以整个是一个非常复杂的过程,有非常非常多的服务。下面中图是我们服务治理的情况,是服务之间错综复杂的调用情况;
-
另外,外卖还是快速发展的阶段,对我们的挑战是迭代太快了,你可能要频繁的发版,就有稳定性的风险,可能有 Bug,可能有测试不全的情况。另外是项目周期短,业务发展很快有很多业务需求正在排队,架构优化的工作可能排不上去,甚至做技术架构设计的时候可能有一些折中,这是极大的隐患,我们把它叫技术欠债。我们有一个列表记录下来这些技术欠债,会记清楚说这是一个什么样的条件下做的方案,它在什么情况下可能会有哪些问题,需要在什么时候必须去做哪些事情;另外一块在监控的压力也很大,因为业务变化非常快,你今天是这样设置监控规则,明天业务又变了。

介绍一下我们对于稳定性的定义,我们也是拿四个“9”来衡量稳定性,但是我们分别用于两个指标:系统可用性和订单的可用性。
-
系统可用性四个"9"意味着全年的宕机时间不超过 52 分钟,我们是按季度考核的,相当于一个季度系统宕机时间不超过 13 分钟;
-
另外一个维度订单可用性也是四个"9",意味着我们一个季度是一亿单的话,这个季度的订单损失不能超过 1 万单,而我们高峰期一分钟就接近两万单,因此只要这个系统有问题,我们这个 KPI 就无法完成。
我们还是要保证四个"9"的可靠性,而我们怎么去做:我们从四个阶段来扎实地做这些事情:一个是日常运行,二是事前预警,三是事故处理,四是事后总结,我会详细地介绍这四个环节:
一、日常运行
首先在日常运行里面,我们要做好稳定性的架构设计,这里有几个原则:
-
第一个是大系统小做:我们不希望做一个非常大的系统,它什么都能做,我们希望做小的系统,非常专注,功能相对独立。我们先把功能相对独立的系统拆开,在早期发展过程中,你们看我们有一个系统它什么都能干,它其实是一个 Web 项目,还提供了 Web 的服务,同时还提供了 App 的 API 服务,它还消费消息队列,还是 Job 的执行者,这就带来一个问题:你消费消息的逻辑发生变化了,你就要去发版,其实别的功能是没有变化的,发版就会影响到其他的功能。当我们把几个系统拆开,它就是四个独立的系统;
-
第二个原则是依赖稳定性原则,你提供的服务一定是稳定可靠的。这里希望是将易变的和不变的地方拆开。举个例子,对于商家的服务,对于 C 端的用户和服务来说,用到最大的场景就是 GetById,就是知道这个商家的信息就好了,但是我们还有很多对商家管理的服务需求,比如说商家符合什么条件才能上线,需要什么过程才能改他的菜品,这些管理的功能是经常变化的,对于读取的信息是不变的,于是我们把这它拆开,把它变为读的服务和管理的服务。管理的服务可以随时发版,没有关系,读的服务是非常稳定的,基本不发版;
-
最后一个原则是设计这个稳定性的时候需要考虑用户的体验,需要考虑在系统出现问题的时候用户怎么办?相信很多同学都有这个体验:可能 APP 上突然有提示失败、服务器异常、空,不知道什么情况。我相信用户遇到这种情况一定会不停刷新的,这时候如果后台已经有问题的话其实是糟糕的事情,所以设计的时候要考虑到在异常情况下用户的体验和用户如何引导。

日常运行里面,另外一个工作是做例行的稳定性巡检
-
比如说我们做专项的巡检,对 DB 来讲,我们每个月要做 DB 容量的 Review,我们看哪些表是大表、读写的 QPS 以及它的容量,以及未来某一天它能不能支持业务的发展;
-
我们会做静态的梳理,我们按场景梳理,例如首页、Banner、列表页,这些场景用到哪些服务,这些服务又用到了哪些服务,这些过程中,它们对下游的调用是否存在放大的情况。有一些情况是假的高并发。比如说有一个服务是说告诉商家今天有几个新订单,这个功能很简单,就是在前端页面去做轮询,这个过程其实 80%-90% 的查询是无效的,因为一旦有新订单我们就会推送到商家,商家就会及时地处理掉,查这个请求其实是无效的,这么多无效的请求去查订单的服务,最终还要落到数据库上,这是假的高并发,这里我们在前面加一层缓存,把到数据库的这一层假的高并发给干掉;
-
另外一个例行的工作是对指标的巡检,我们有许多的监控指标,尤其是关注它的尖刺,这些尖刺也不会放过。
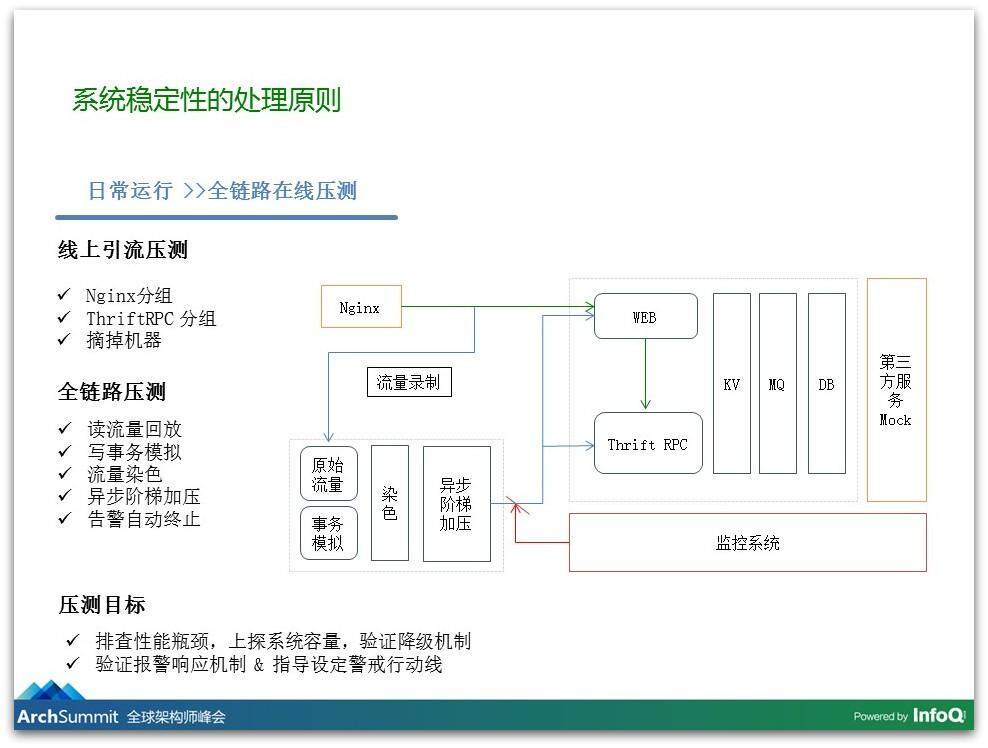
对于平时来讲,给我们增强稳定性最可靠的信心就是在线压测,我们和其他大厂差不多,我们也在做在线压测这个东西,我们有一个在线压测的平台。我们希望通过压测来发现什么呢?首先发现系统里面的性能瓶颈,到底哪个系统是里面最弱的,以及我们要知道系统服务的上限和能力。
另外更关键的是,我们需要通过压测来验证我们的监控和报警机制是否生效的,可能很多时候大家都说我们配置了非常完整的监控方案,但是它可能不生效,一旦不生效就惨了。另外,我们要通过压测指导我们报警的警戒线是怎么设置,到底 CPU 是设置是 30% 还是 70%,什么时候该报警,我们就通过压测来确立。
这个压测告诉我们指导意见,警戒线设置到哪个位置是给你留有充足时间的,如果你的报警发生之后马上挂了,其实报警是没有用的。我们可以通过压测来要设置警戒行动线,到这个时候我们要考虑和关注这个问题,留给稳定性处理有足够的时间。
我们怎么做呢?我们把线上的流量经过日志录取下来,把录取的流量放到我们的压测平台里,这是对于读请求的。对于写请求的,我们做一些事务的模拟,我们有一些模拟的脚本伪造一些根据我们场景做的数据。这些数据再经过一次染色,把真实数据和测试数据隔离开,经过我们异步阶梯加压的模块,我们先通过异步的方式把它迅速打起来,我们可以把量打地非常高;另外我们是通过阶梯性地打,我们不是一次打到 2 万,我们可能先到 5000,然后再到 9000,然后打到 15000,然后再持续 10 分钟,我们对这个监控的流量施压过程和跟我们监控指标关联起来,我们做压测之前先看和哪几个指标关联,哪几个指标到了什么阈值就自动中止压测,毕竟我们是在线上做这些事情,不能对真实线上的情况产生影响。对于其他依赖的服务,比如说支付,这些真的不能压到银行去,外部的服务我们做了一些 Mock。
二、事前预警
对于事前预警阶段,如果真的有事故发生我们希望更早曝露出来触发报警,然后有充足的时间去应对这些事情,我们在这个地方在事前预警阶段我们有一些监控心得:
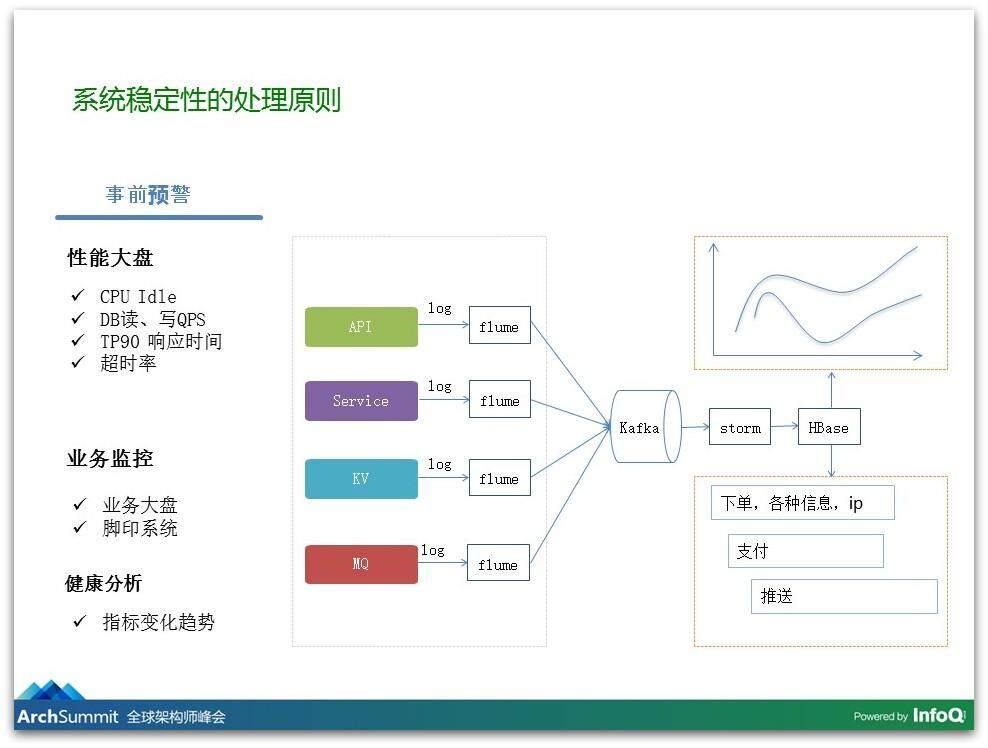
首先是有分层的监控:有系统级的监控,例如性能指标的监控,还有业务监控,我们还有平时健康度的分析,我们的应用是不是健康的。
我们分享一下在业务监控的想法,业务监控其实是最让你放心的,你有一个业务大盘,这个大盘如果有一个波动你就立马发现了,说明现在可能会有影响,你可能会收到报警,例如什么 CPU 的报警,你去看大盘,大盘可能说没有什么影响,这样你不会那么慌。
另外,我们系统里面把订单相关的所有信息和重要节点做了日志的输出,日志通过 flume 收集到 Kafka 再到 Storm 里,我们在 Storm 里对这些日志进行汇聚,汇聚的结果放在 HBase 里,在这些结果里我们有几个非常好的应用:
-
例如首先只要告诉我一个订单号或者手机号,我可以查到这个订单走到了哪个环节,到了哪个服务的哪个服务器挂掉了,解决这类问题非常的方便;
-
另外我们还可以把这些指标做成监控曲线,比如说你要下单,下单量是这么高,到了接单的环节它出现了下降,接单这个服务可能关联的 ABC 三个服务:可能有商家、PC、打印机的接单,到底是哪个服务出了问题导致了大盘的下降,我们的曲线可以非常方便地看出来。
三、事故处理
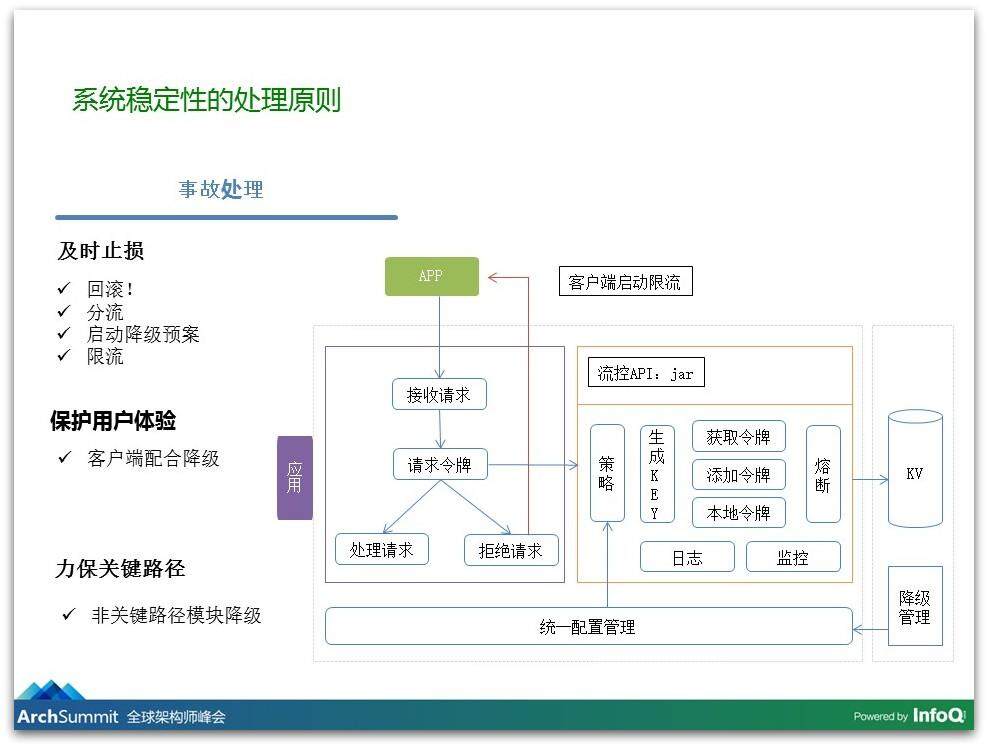
还有可能有一些意想不到的事情发生,真的出现了事故怎么办?第一原则就是及时止损。我们知道发版是导致稳定性变化的第一因素,如果立马确定是由发版引起的这次事故,最快速最有效的方法就是回滚。另外可能还有一些流量异常,对于流量异常我们有限流的模块,我们提供了三种限流的策略:
-
第一种是防刷的,防止用户频繁刷新导致后台的流量继续放大;
-
另外一个策略是等待 + 限时的服务,用户其实在用我们平台的时候,用户确实是需要选的,可能要选来选去才能下单,对于这些服务,我们希望说你愿意等一段时间我们可以提供,比如说你愿意等 10 秒钟,我给你提供 20 分钟的服务,这段时间应该是可以下完单的;
-
还有一种策略是对单机的 QPS 保护:我们压测验证的时候这个服务单机能达到 500QPS 是稳定可靠的,再往高有问题的话,我可以启动这样一个保护,确保你能够以最大的服务能力提供服务而不至于挂掉。另外在单机 QPS 保护中我们需要把关键的路径去放过,你真的不希望用户在下单、支付的这些路径把它干掉或流空掉,这些服务我们就用白名单的方式放过。
四、事故总结
事故发生之后,我们需要对事故做一个非常深刻的总结。这里面有几个非常强的要求,第一是必须找到根源,根源我们采用 5whys 的分析方法,一定要追踪到最根本的原因,从现象开始追踪。另外去要核算清楚这次造成多少损失,因为我们要算我们的稳定性。还有一个方面,你要对这次系统出现问题的过程、你处理的过程和中间的流程进行总结,看哪些地方可以优化。
我建议的做法是:我们需要把这次事故处理的过程详细记录下来,它可能是需要精确到分钟的,比如说某一分钟谁跟谁做了什么动作,这对我们总结很有帮助。因为有可能事故处理过程本身是有问题的,比如说你去扩容花了 30 分钟时间,这是有问题的;比说你在处理过程中做了错误的决定也是有问题的,所以我们把过程中做了详细的记录。我们对于这个事故的总结和 Review,我们希望能看到什么?在这个总结里面,我们希望看到到底哪里出了问题,我们能不能更快的发现它,将来如果再发现,能不能比现在处理的更快一点。
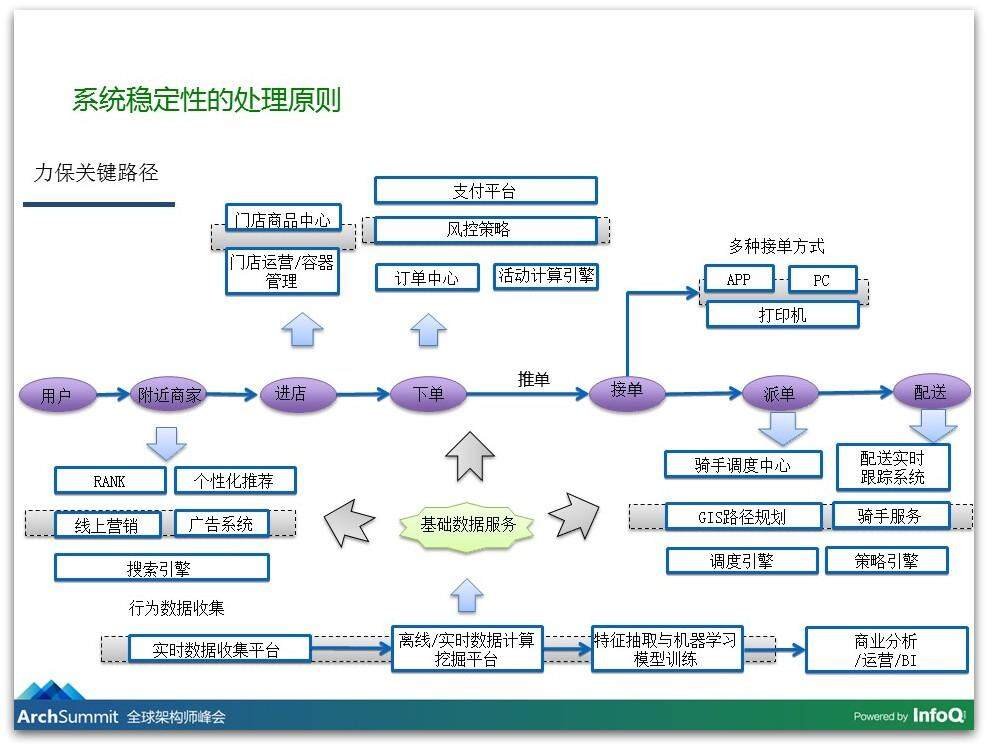
讲完这些处理原则,再介绍一下我们做这个事情的实践。我们对稳定性的要求是极高的,每一个订单的损失我们非常敏感,我们就有一个实践的动作:就是力保关键路径不挂,我们要保住订单,那要保住和订单交易相关的所有路径不能挂,所以平时我们就梳理出了和订单交易的关键路径,从用户下单、从用户开始选门店,然后开始选菜,然后下单,然后到配送完成,这个过程里边每一个环节关联了哪些服务,这些服务都应该具备有降级的功能。
比如说 Rank 服务,用户首先打开我们 App 的时候,我们就会给他最附近的、可以配送到的一些商家,这些服务会给用户之前的购买记录来做推荐,我们会给他更好的排序。如果我们 Rank 的服务出现问题了,我们可以迅速地将这个Rank 的服务给降级掉,改成默认按销量去排序,这样用户也是可以选餐的。所以这个环节里面的每一步我们都可以降级的,从而保证在下单这个关键路径上服务都 OK,其他服务可以接受它的挂掉。
另外,预案的建设,你永远需要想一下你将来可能发生什么,如果发生这些事情的话,我们该怎么办?所以你在做这个事情之前就要去考虑,我们认为性能是功能的一部分,稳定也是功能的一部分,而不是大家做这一次技术方案设计,做完之后再来优化性能和稳定性,我们需要在做这个架构设计的时候考虑到性能和稳定,它们是产品功能的一部分,同时也要考虑到如果性能稳定性出现问题,用户体验是怎样的,用户不希望看到很傻的提示。
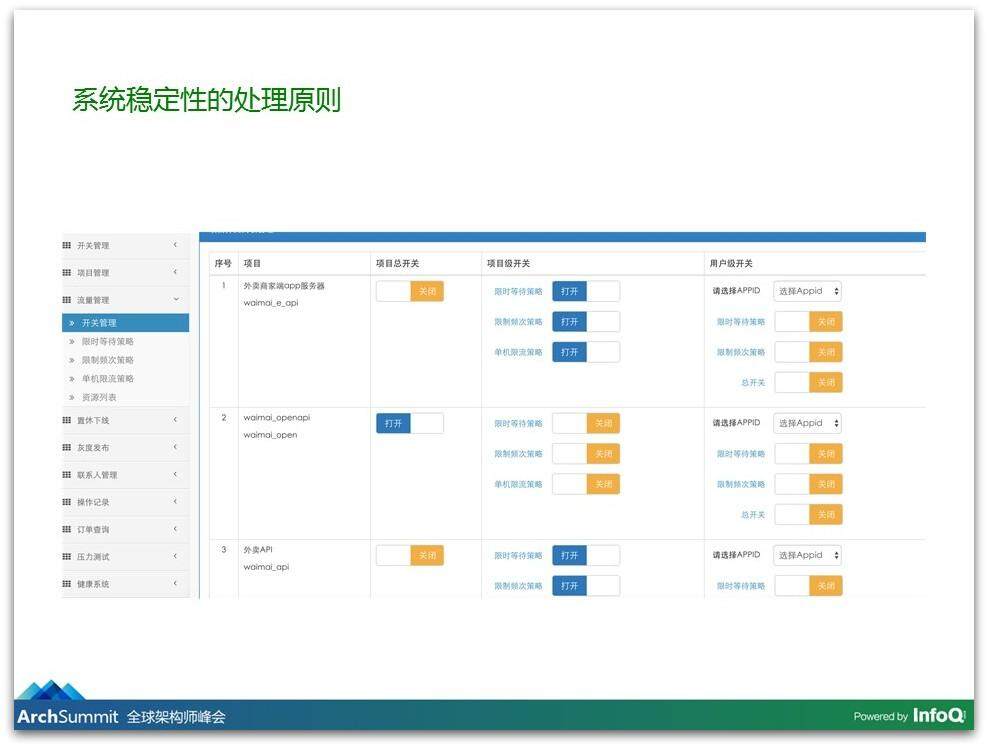
所以我们在功能设计的时候,就考虑到了出现这样的情况我们可能要降级,这个降级的方案可能是一个开关,就会有非常多降级开关,有些情况下是更复杂的场景:如果这个情况发生了,我们可能把这个开关和那个开关给关掉,这是我们的降级管理平台,我们真的把一个降级开关给做成了一个开关,就是开启和关闭,同时我告诉你开启意味着什么、影响着什么。
再介绍一下这个平台里面我们有对灰度的管理,有对压测的管理,有对健康度的分析,另外有一块我们称为核按钮,即如果事情发生之后你要保住的底线,如果我们的系统出现问题,商家不能接单或者配送无法送出的话,用户下的这些单子都会被取消掉,这个体验是很糟的。我下了单,然后 5 分钟你告诉我商家不能接单这个订单被取消掉了,我忍了我换了一家,结果又被取消了,这会骂人的。如果商家不能接单,就不要让用户下单,如果这些情况发生,我们就迅速启动核按钮,把我们筛选的这些不能接单的商家迅速变为休息,可以保证用户向可以服务的商家去下单。
在整个实践的过程中,与稳定性斗智斗勇的过程中,我们总结了非常多的流程,我们叫做标准操作流程 SOP,这些流程涵盖了从需求、开发、测试、上线、监控、故障处理的每个环节,每一个环节都是标准的、非常严格的、经过认真思考的流程来供大家参考的,一定要按照流程来操作。为什么这样做?
给大家举个例子,按照这个步骤走是值得信赖的,每一步都有非常好的预案与系统的配合。比如说出现事故,大家是很慌的,因为那么多人在投诉、那么多人在等着说不能点餐了,为什么,美团外卖怎么了?然后我们处理事故的同学说:你不要慌。怎么可能呢?那么多用户在投诉,老板还在后面问你怎么样了,什么时候才能处理好,怎么可能不慌呢,臣妾做不到呀。这个时候你肯定很慌的,这个时候你还要把很多问题考虑清楚几乎是不可能的,有些同学说我这里需要这么做、我需要写条 SQL,结果忘了 Where 的语句,所以你在非常紧张的情况下根本想不全这件事情的,那怎么办?我们只能提前想好,如果会出现这种情况我们就执行这条 SQL,然后放在那里经过无数人的 Review 和实验,它是可靠和可以被执行的。所以,我们在整个过程里面收集了非常非常多的操作流程,每一步都有非常严格的要求。

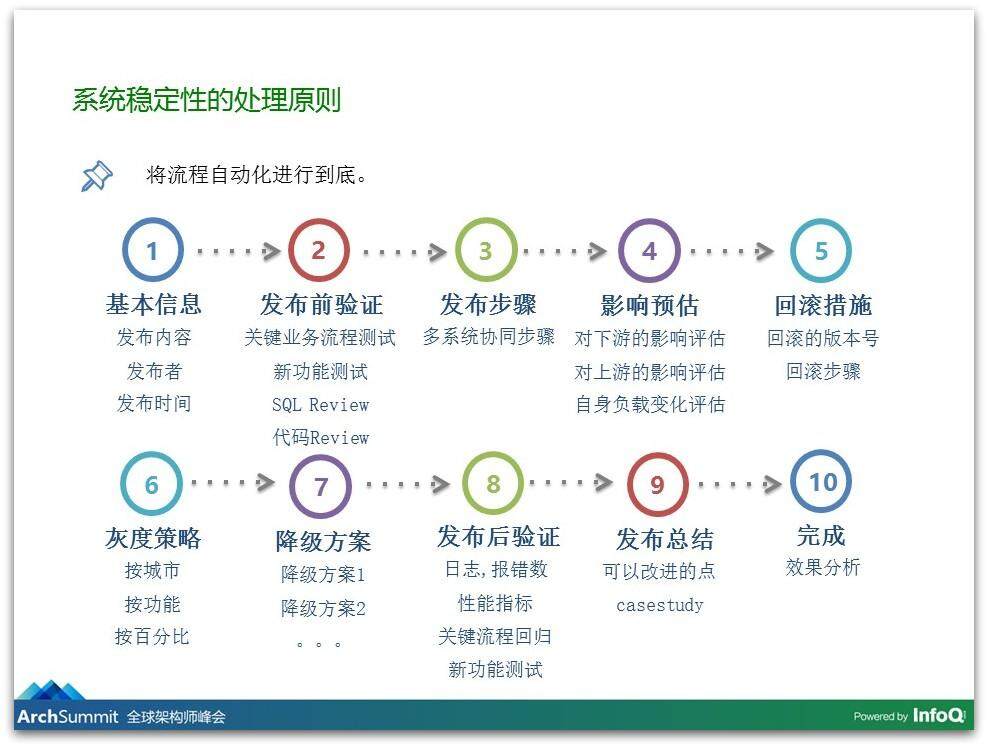
我们梳理完了这些流程,希望把这些流程变成自动化的,否则人工操作的话,我们是可以要求大家严格执行,但是毕竟也是效率低下的,我们需要把很多的操作变成自动化。举个例子,下图是我们发版的流程,看上去还蛮复杂的,一共有 10 步,我们有非常多的要求,你在发版之前需要验证哪些事情,发完版之后要验证哪些功能,最重要的是你要去评估,你要去评估有什么影响,你对下游有什么影响。更重要的是,我们对每次发版都一定要有回滚措施,就是应急预案,你要回滚到哪个版本,如果是一个大的项目,大家一起联合发布的,是怎样的回滚过程,谁先操作谁后操作。对于每一次发版,没有预案是不允许发布的。
大家可能会说,我要改库、我要改表,我已经把表结构变了,还要写数据,这时候无法回滚,回不去了。那不行,那是不可能的,你一定有办法把它回退过去。另外,我们有每一次的降级方案和灰度的策略,如果是这一次发版引发的故障的,发版之后整个过程做一次非常详细的整理,到底哪些地方出了什么问题。
在处理的过程中有几句总结的话跟大家分享:
-
第一句话:你要想稳定性做的非常可靠,灰度、灰度、还是灰度,没有别的方法;你不要把所有的量去验证这个事情。我们对于灰度,可以做到按照城市、按某个功能、按 URL 某个参数来进行灰度,也可以按照一定流量的比例,比如说先灰度 1%,然后到 50%,然后到 100%。 另外我们对于发版是有很强要求的,我们有一个发版的时间窗,周一到周四的下午两点到四点,其他时间是不允许发版的,如果你要发版你要提申请和审批。为什么这么做呢?因为我们外卖特点就是中午流量非常高,晚上流量偏低。中午是非常高的高峰,我们不希望用中午这么大的量来验证,我们希望晚上来验证,晚高峰虽然比中午的高峰低很多,但是也是一个非常大的高峰,我们用这个流量来验证,所以我们把发版的时间调到下午,不要在晚上发版,这样很累可能想不清楚,和你关联的其他同事都不在,很多事情也无法处理,所以我们下午来发版,这样会很稳妥大家都在,通过晚上的高峰来验证,如果没有问题,第二天也很稳妥很安心的,如果有问题则晚上进行压测;
-
第二句话:慢查询往往闯大祸。慢查询是非常讨厌的事情,而且它的出现可能会有非常大的危害,慢查询把一个库打挂的话,我们负载均衡会跑到其他库也继续打挂,然后所有都挂了,解决数据库挂了的问题是非常耗时的,所以对 SQL 有极高的要求,在我们的实践里面我们不允许写 join,不允许写 like,每一次 SQL 都有 Review,上线的流程里面会记录这次上线这次 SQL 是谁 Review 的;
-
第三句话:防御式编程,不要相信任何人和服务。别相信你的下游说,我就调你三次,你放心吧,没事的。别信,肯定有鬼,你要做好对自身的保护,也不要相信下游说别人的提供的服务放心地使,哥向你保证五个 9 的可靠性,没有一个服务能做到 100% 的可靠的,这是必然的,即使是 5 个 9,也有损失的时候,别相信他,要做好对下游的依赖和熔断;
-
第四句话:SOP 保平安。我们把所有的流程都变成标准化流程,这比拜大仙还管用,有时候开玩笑说发版之前没有拜一拜所以挂了,其实不是,而是因为你没有按照标准流程来操作所以挂了,如果每一步都严格按照标准流程来做,它是可信赖的,是不遗不漏的,保证做到方方面面;
-
最后一句话:你所担心的事一定会发生,而且可能马上会发生。最近上了一些功能,你说好像这个地方可能会有问题,你最好赶紧看,也许马上就会有问题。所以我们建议做例行的巡检,定期地对你的服务、服务的指标、依赖的情况,有一天你去看发现突然多了一个服务,可能你还不知道。另外对 DB、KV 这样一些中间件做例行的巡检,及时的发现这些里面可能存在的问题。
讲师介绍
曹振团,美团外卖技术专家 / 架构师,拥有丰富的高并发系统的架构设计和实战经验,专注于高并发架构、高可用分布式系统的设计。目前负责美团外卖业务系统的架构设计及优化工作。2013 年加入美团,早期参与了多个创新业务的探索。经历了美团外卖从无到有的创业过程,以及业务快速发展的高增长期,积累了丰富的从 0 到 1、从 1 到 100 的业务系统的架构设计和优化经验。加入美团之前,在网易网站部工作,负责后台服务的设计和开发工作。
感谢李东辉对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论