

编者按:本文节选自方巍著《Python 数据挖掘与机器学习实战》一书中的部分章节。
2.1 搭建 Python 开发环境
Python 可应用于多平台,包括 Linux 和 Mac OSX。本节主要介绍如何在 Windows 平台搭建 Python 开发环境,以及运行和保存相应的 Python 程序。
2.1.1 安装 Anaconda
Anaconda 是 Python 的一个开源发行版本,主要面向科学计算,内含有诸多机器学习算法框架、图像处理模块及经典算法集成模块。Anaconda 的主要优点是预装了很多第三方库,而且增加了 conda install 命令,除了使得安装新的 package 非常方便外,还自带了 Spyder IDE 和 Jupyter Notebook 等编译环境。
单击下载链接https://www.anaconda.com/download/,选择 Windows Python 3.6 版本进行下载并安装,如图 2-1 所示。
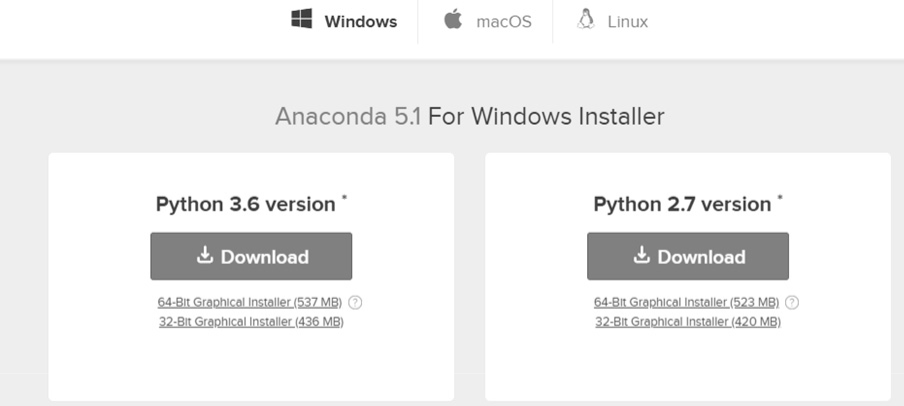
图 2-1 安装 Anaconda
安装时,需要选择安装类型。这里选择管理员权限,并且将路径自动加入到环境变量中,如图 2-2 所示。
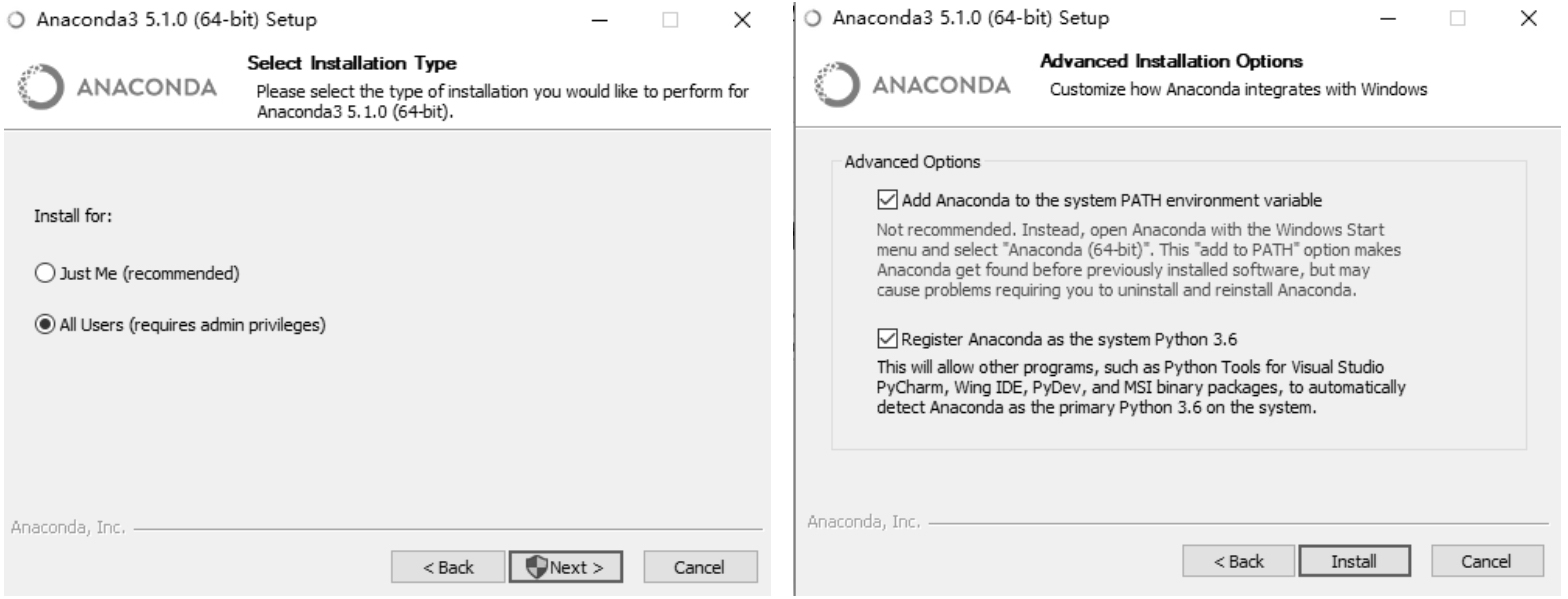
图 2-2 添加环境变量
单击 Install 按钮即可安装。安装完成后,在 Windows 搜索栏中输入 cmd 进入命令行模式,输入 python,检验环境是否创建成功,如图 2-3 所示。

图 2-3 检查环境是否创建成功
2.1.2 安装 Spyder
Spyder 是 Python 的作者为 Python 开发的一个简单的集成开发环境。和其他的 Python 开发环境相比,Spyder 的最大优点就是模仿 MATLAB 的“工作空间”的功能,可以很方便地观察和修改数组的值。
在“开始”菜单中打开 Anaconda3(64-bit),单击 Anaconda Navigator,进入集成环境。首先选择 Environments,然后选择 All,最后输入 spyder,勾选 spyder 复选框进行安装即可,如图 2-4 所示。
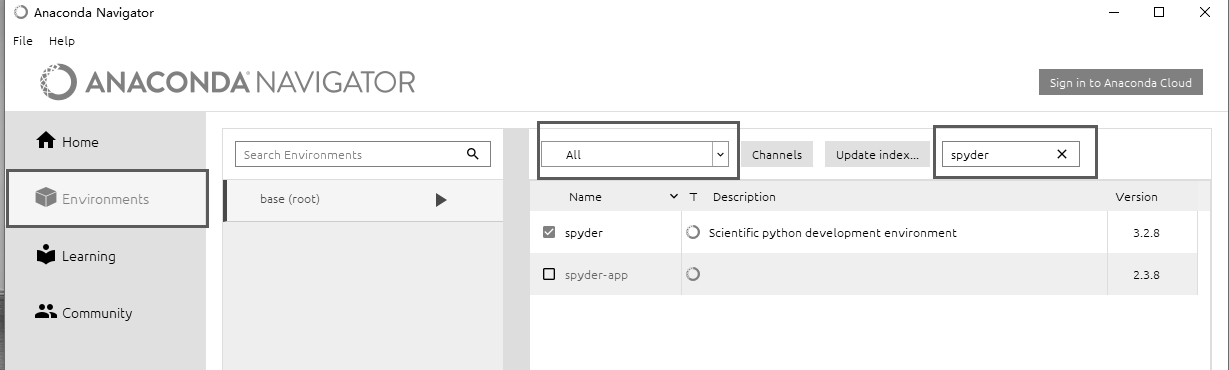
图 2-4 安装 Spyder
此时在“开始”菜单中打开 Anaconda3(64-bit),单击 Spyder,即可进入编辑环境。Spyder 界面如图 2-5 所示。
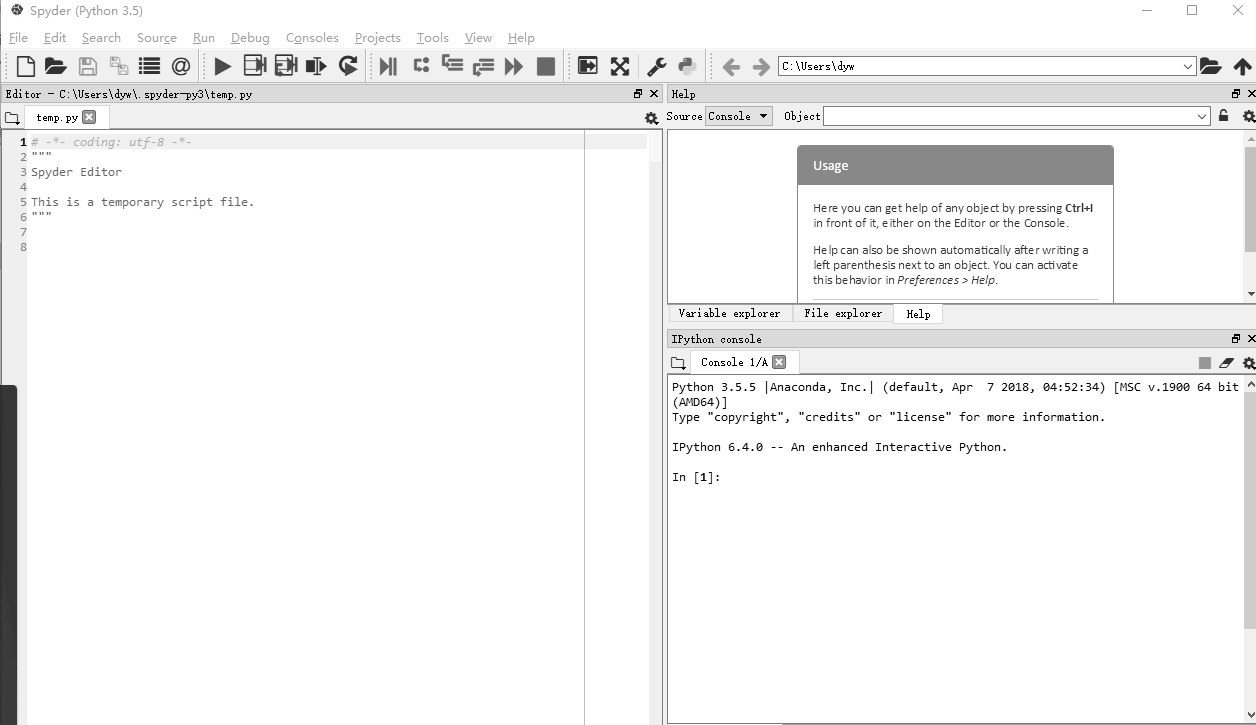
图 2-5 Spyder 界面
2.1.3 运行和保存 Python 程序
如果程序员每次想用 Python 程序时都需要重新输入则费时费力,非常影响效率。当然,如果只是几十行的小程序,重写也是可行的,但对于一些大型的程序,其中可能包含有数十万行甚至更多的代码,想象一下,要把这么多的代码进行重写是多么的困难。幸运地是,程序员可以把程序保存起来,随时随地就可以使用。要保存一个新程序,选择 File→New file 命令,然后会出现一个空白窗口,在菜单条上会有“Untitled0.py”字样。在新窗口中输入下面的代码:
然后选择 file→save as 命令。当提示输入文件名时,输入 hello.py,并把文件保存到桌面即可。不出问题的话,在键盘上按 F5 键,保存的程序就可以运行了,如图 2-6 所示。
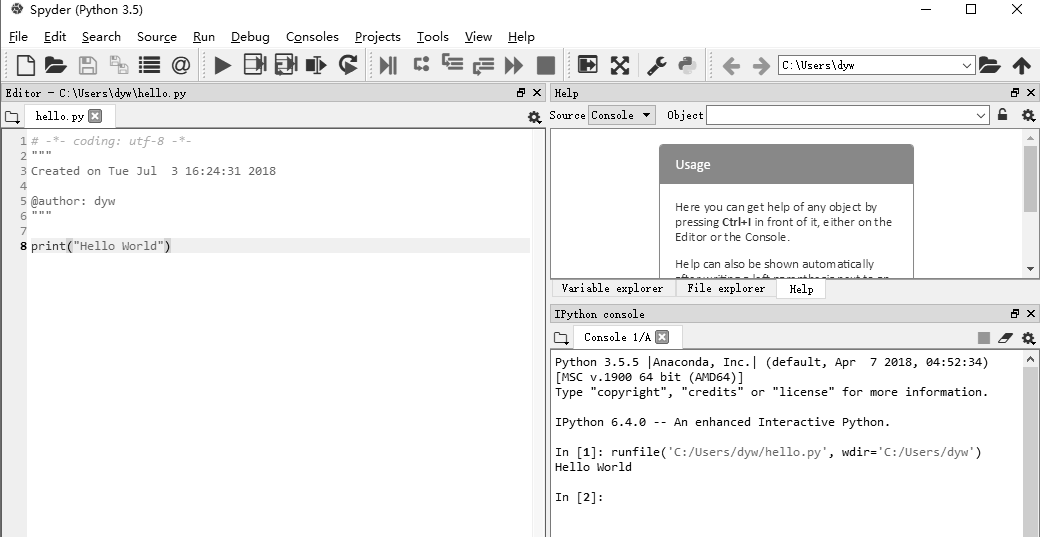
图 2-6 运行和保存程序
2.2 Python 计算与变量
Python 开发环境已经搭建完成,也知道如何运行和保存程序了,现在就可以使用它来编写自己的程序了。本节首先从一些基本的数学运算开始讲解,然后再使用变量进行稍复杂一些的计算。变量是程序中用来保存东西(如数值和矩阵等内容)的一种方式,它们能使程序更加简单明了。
2.2.1 用 Python 做简单的计算
首先,使用 Python 做数值计算。例如,想要得到两个数字乘积的结果,一般可能会用计算器来得到答案,比如计算 9×8.46。那么如何用 Python 程序来运行这个计算呢?
为了清晰地显示代码,在这里暂时不使用 Spyder 作为编译环境,直接使用命令行窗口。步骤如下:
(1)单击“开始”按钮,输入 cmd,进入命令行窗口。
(2)再输入 python,然后按 Enter 键,即进入 Python 编辑环境。
(3)显示当前的 Python 版本。
命令行窗口如图 2-7 所示。
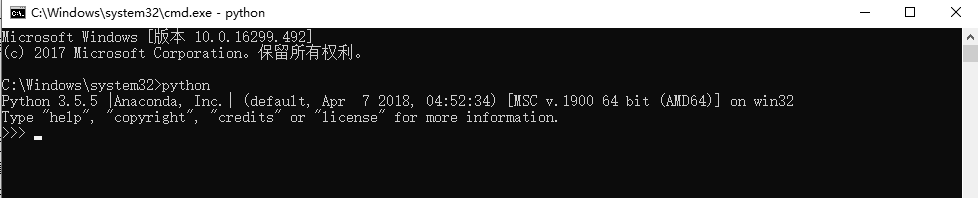
图 2-7 Python 的命令行窗口
命令行中显示了 3 个大于号“>>>”,这 3 个大于号叫做“提示符”。
在提示符后面输入算式:
注意:在 Python 里输入乘法运算时要使用星号“*”而不是乘号“×”。
这是一个非常简单的程序。在本书中,读者将会学到如何扩展这些想法,写出更有用的程序来。
2.2.2 Python 的运算符
在 Python 中,可以做加、减、乘、除运算,以及其他的一些数学运算。Python 中用来做数学运算的基本符号叫做“运算符”,这里罗列了几种最常见的运算符,如表 2-1 所示。
Python 中用斜杠“/”来表示除法,因为这与写分数的方式相似。例如,a=20,b=10,在 Python 程序中计算 a 除以 b,只要输入 20/10,输出结果为 2。要记住“斜杠”是顶部靠右的那个(顶部靠左的是反斜杠“\”)。“%”表示取模,即返回除法的余数,如 a%b 的输出结果是 0。“”表示幂,即返回 x 的 y 次幂,ab 是 10 的 20 次方,输出是 100000000000000000000。
表 2-1 Python 的基本运算符
在 Python 编程语言中,使用括号来控制运算的先后顺序。任何用到运算符的都是一个“运算”。乘法和除法运算比加法和减法优先,也就是说它们先运算。换句话讲,如果在 Python 中输入一个算式,乘法或者除法的运算会在加法或减法之前运算。
提示:请记住乘法和除法总是在加法和减法之前运算,除非用括号来控制运算的顺序。
2.2.3 Python 的变量
变量存储的是在内存中的值,这就意味着在创建变量时会在内存中开辟一个空间。基于变量的数据类型,解释器会分配指定的内存,并决定什么数据可以被存储在内存中。因此,变量可以指定不同的数据类型,可以存储整数、小数或字符。
Python 中的变量赋值不需要类型声明。在内存中创建每个变量时包括了变量的标识、名称和数据这些信息。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。等号“=”用来给变量赋值,其运算符左边是一个变量名,右边是存储在变量中的值。例如:
上例中,1000、1000.0 和 Python 分别赋值给了 counter、miles 和 str 变量。
执行以上程序会输出如下结果:
Python 允许同时为多个变量赋值。例如:
上例中创建了一个整型对象,值为 1000,a、b、c 这 3 个变量被分配到相同的内存空间上。
也可以为多个对象指定多个变量,例如:
上例中,将两个整型对象 1 和 2 分别分配给变量 a 和 b,字符串对象 abc 分配给变量 c。
在内存中存储的数据可以有多种类型。Python 有 5 个标准的数据类型,分别是 Numbers(数字)、String(字符串)、List(列表)、Tuple(元组)和 Dictionary(字典)。下面将重点介绍后 4 种数据类型。
2.3 Python 的字符串
字符串是 Python 中最常用的数据类型。可以使用引号(单引号或双引号)来创建字符串。创建字符串很简单,只要为变量分配一个值即可。例如:
输出结果为:
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用的。在 Python 中访问子字符串时,可以使用方括号“[]”来截取字符串,例如:
输出结果为:
也可以对已存在的字符串进行修改,并赋值给另一个变量,例如:
输出结果为:
上面例子中“+”是字符串运算符。还有很多字符串运算符,如表 2-2 所示。
表 2-2 字符串运算符
这里给出一个简单的例子来实现这些字符串运算符。
输出结果为:
Python 支持格式化字符串的输出。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符“%s”的字符串中。在 Python 中,字符串格式化使用与 C 语言中 printf,函数的语法一样。例如:
输出结果为:
2.4 Python 的列表
序列是 Python 中最基本的数据结构。序列中的每个元素都分配一个数字来表示它的位置(或叫做索引),第一个索引是 0,第二个索引是 1,依此类推。Python 有 6 个序列的内置类型,但最常见的是列表和元组。
序列可以进行的操作包括索引、切片、加、乘和检查成员等。此外,Python 已经内置了确定序列的长度及确定最大和最小的元素的方法。列表是最常用的 Python 数据类型,表现形式为一个方括号内包含若干数据项,各数据项之间以逗号分隔。
创建一个列表,列表的各数据项不需要具有相同的类型,只要把用逗号分隔的不同数据项使用方括号括起来即可。例如:
与字符串的索引一样,列表索引从 0 开始。列表可以进行截取、组合等。可以使用下标索引来访问列表中的值,同样也可以使用方括号的形式截取字符,示例如下:
输出结果为:
可以对列表的数据项进行修改或更新,也可以使用 append()方法添加列表项,示例如下:
输出结果为:
可以使用 del 语句删除列表的元素,例如:
输出结果为:
Python 列表操作符和字符串操作符有些是相似的,如“+”号用于组合列表,“*”号用于重复列表。如表 2-3 所示为常见的列表操作符。
表 2-3 常见的列表操作符
下面给出一个简单的例子来实现这些列表运算符。
输出结果为:
2.5 Python 的元组
Python 的元组与列表类似,不同之处在于元组的元素不能修改;元组使用小括号,列表使用方括号。元组的创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。例如:
元组中只包含一个元素时,需要在元素后面添加逗号,例如:
元组与字符串类似,下标索引从 0 开始,可以进行截取、组合等。元组可以使用下标索引来访问元组中的值,例如:
输出结果为:
元组中的元素值是不允许修改的,但可以对元组进行连接组合,例如:
输出结果为:
元组中的元素值是不允许删除的,但可以使用 del 语句来删除整个元组,例如:
以上实例中,元组被删除后,输出变量会有异常信息,输出如下:
与字符串一样,元组之间可以使用“+”号和“*”号进行运算。这就意味着它们可以组合和复制,运算后会生成一个新的元组。常见的元组运算符如表 2-4 所示。
表 2-4 常见的元组运算符
下面给出一个简单的例子来实现这些元组运算符。
输出结果为:
2.6 Python 的字典
字典是另一种可变容器模型,并且可存储任意类型的对象。
字典的每个键值对(key-value)用冒号分隔,每个键值对之间用逗号分隔,整个字典包括在花括号中,格式如下:
键一般是唯一的,如果重复,最后一个键值对就会替换前面的,值不需要唯一。例如:
输出结果为:
值可以取任何数据类型,但键必须是不可变的,如字符串、数字或元组。这里给出一个简单的字典实例:
也可如此创建字典:
如果要访问字典里的值,只要把相应的键放入熟悉的方括号中即可,例如:
输出结果为:
如果用字典里没有的键访问数据,则会输出错误,例如:
输出结果为:
向字典添加新内容的方法是增加新的键/值对,示例如下:
输出结果为:
在字典操作中,能删除单一的元素也能清空字典,删除一项只需要删除其键的内容。删除一个字典用 del 命令,示例如下:
但这会引发一个异常,因为用 del 后字典不再存在:
图书简介:https://item.jd.com/12623592.html?dist=jd

相关阅读
Python数据挖掘与机器学习实战(一):Python语言优势及开发工具
Python数据挖掘与机器学习实战(二):Python语言简介
Python数据挖掘与机器学习实战(三):网络爬虫原理与设计实现
Python数据挖掘与机器学习实战(四):用 Python 实现多元线性回归
Python数据挖掘与机器学习实战(五):基于线性回归的股票预测
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论