

不友好的评论对于系统而言是一个大问题,因为他们的语气会影响被评论者和未来读者对 Stack Overflow 的贡献意愿。讨论前因后果或意图不是解决这些问题的办法,唯一的选择是处理评论本身。
本文最初发布于 Stack Overflow 官方博客,经原作者授权由 InfoQ 中文站翻译并分享。
作为广受开发者欢迎的社区网站,我们所有人都希望 Stack Overflow 成为一个热情友好的地方。有时候,Stack Overflow 上的评论明显不受欢迎,比如散播仇恨和偏见这样的事情并不少见,如果出现不友好的评论,我们的社区会进行标记,版主也会处理。但有些评论很容易躲过标记系统,我们就需要不断优化技术,本文介绍了 Stack Overflow 过去两年为此做过的事情。
作为开发人员,我们倾向于从系统角度考虑问题。Stack Overflow 是一个很大的系统,由很多子系统组成,旨在帮助人们解决他们遇到的编程问题。这些子系统包括投票、信誉、问题流、评论、Meta、关闭、徽章、标记、培养新贡献者等。系统的任何一部分都不是为了好玩。所有这些子系统一起帮助整个系统实现其目的。当这些子系统出现问题时,它们需要也值得修复。
对于不受欢迎的评论,问题很少在评论者或他们的评论意图, 而是读者体验到的语气上。大多数情况下,评论者并不是有意让他们的评论显得居高临下、不屑一顾,或者我们看到的其他不受欢迎的微妙变种。这些人是真得想帮助别人,即使他们的语气很差。
我们不相信这里有需要驱逐的坏人,所以暂停或禁止用户发言并不是解决办法,剩下的唯一选择是处理评论本身。
调查
我们先自己去看问题。Stack Overflow 的员工将从 Stack Overflow 上随机挑选的评论分为三类:友好的、不友好的和辱骂性的。各人的经验不同,但我们的中位数员工将 6.5% 的评论归为不友好。我们还另外邀请了三组人来对评论进行分类:版主、一组注册用户(来自我们的一般研究列表)、一组对我们最初的博文做出回复的人(他们说自己对使 Stack Overflow 更受欢迎感兴趣)。这些人中,中位人员认为 3.5% 的评论是不友好的。
标记功能的发展历程 Stack Overflow 在 2009 年 4 月 16 日引入了评论标记。一旦用户声望到 15,他们就可以标记评论,以引起版主的注意。一旦一条评论被标记,版主要么接受标记并将其从网站上删除,要么拒绝标记并允许该评论保留。直到 2018 年中,我们一直都用一个相关类型的评论标识来处理任何不友好的东西:offensive 标识。
从 2010 年 3 月开始,我们有了关于 offensive 标识使用情况的可靠数据。我们会计算每天被标记 offensive 标识的评论的百分比(每天被标记的评论数 / 当天发布的评论数),并将它们放在每月的统计图中。
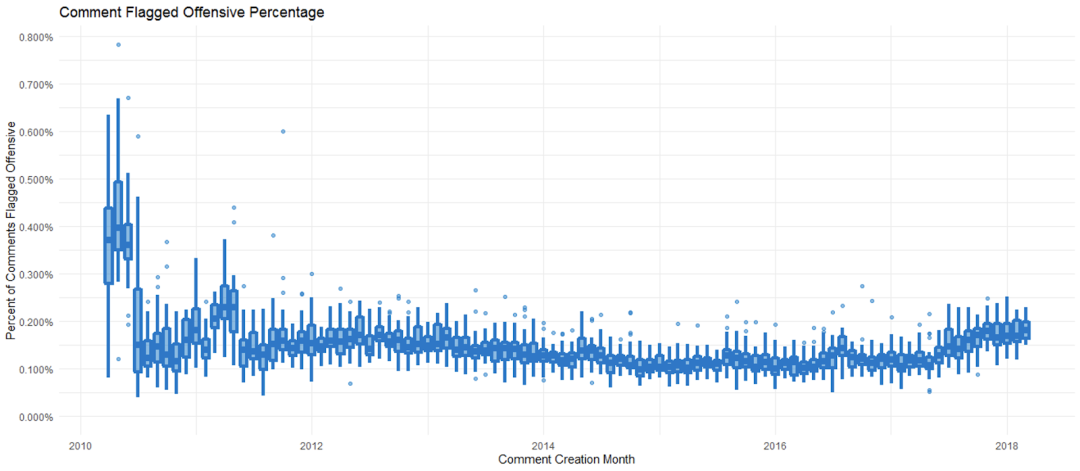
在刚开始的数据中,有两个评论标识百分比升高的时期,这是 Stack Overflow 的开发人员使用评论标识系统进行一些批量清理。月度分布在 2011 年中趋于稳定,在 2017 年中之前一直在缓慢下降,之后才开始上升。月度分布大部分在 0.1% 到 0.2% 之间。在此期间,有 8360 万条评论被发布,其中有 114577 条被标记,整体 offensive 评论百分比为 0.137%。如果我们只计算版主接受的标识,我们估计,在 Stack Overflow 上有 0.105% 的评论是不友好的。
大相径庭的估计
我们对不友好评论的两个估计大相径庭。标记系统估计 Stack Overflow 的不友好评论百分比为 0.105%。非员工中位人员却发现 3.5% 的 Stack Overflow 评论不友好。这两项估计差别很大,但公平地说,它们测量的上下文差别也很大。一个上下文是 Stack Overflow,一个完整的网站,有问题、答案、声望等所有一切内容。另一个上下文只是从随机挑选的评论中提取的文本项。每个上下文中用户的心理状态是不同的:Stack Overflow 上的用户忙于解决自己的问题或帮助别人,评论分类者是按照要求去寻找不友好的评论。
既然测量方法不同,我们应该预料到结果会有一些不同,但是 33 倍的差距太大了,没法忽略。我们进一步假设,Stack Overflow 的评论标记系统存在假阴性或欠标记问题。
自建 or 购买?
我们探索了验证这一假设的方法。有几家公司似乎有这样的工具,我们可以购买,我们研究了这些工具能提供什么。由于这样或那样的原因,它们都法解决我们的问题。即使买了,数据共享或 NDA(保密协议)也存在法律问题。我们做了深入研究,发现他们关注的是相近的问题,即从评论历史中识别有问题的用户,而不是仅对文本本身进行分类。
既然都无法满足我们的需求,我们就开始探索自己构建的可能。2018 年是自然语言处理激动人心的一年。2018 年 5 月,Jeremy Howard 和 Sebastian Ruder 发表了《文本分类的通用语言模型调优》。ULMFiT 使得用很少的标记数据训练非常好的文本分类器成为可能。fast.ai 在 fastai 库中发布了训练 ULMFiT 模型的代码。他们还提供了一个免费的在线课程,教你使用神经网络和这个库。
在 2018 年 7 月,我们第一次尝试运行它,但是我们没有一个大小适当的 GPU 可以使用(我们内部所有的卡都太小了,我们也无法让任何云提供商给我们一个)。10 个月过去了,fastai 库变成了 v1。巧合的是,我们最后的购买选项也被否决了,感觉是时候再试一次了。
ULMFiT
在 2018 年 11 月,我们获得了一个可用的 Azure GPU,并几乎立即取得了成功。ULMFiT 使用两个 Stack Overflow 评论数据集来生成一个分类器。一个无标签的 Stack Overflow 评论数据集,用于将 ULMFiT 的预训练 Wikipedia 语言模型调整到 Stack Overflow 的评论语言。然后使用一个有标签的 Stack Overflow 评论数据集来训练一个 Unfriendly/NotUnfriendly 二元分类器。
对于无标签数据集,我们使用了几十万个随机选择的 Stack Overflow 评论。对于有标签数据集,我们将标记为 offensive 的评论加上 Unfriendly 的标签,并随机选出相同数量的 Stack Overflow 评论,为它们加上 NotUnfriendly 的标签。用了 20 多行 Python 代码(自己去上课看看)和几个小时的训练,我们就得到了一个验证集 AUC 为.93 的模型。我们使用与最高 F1 分数相关联的阈值,并在均匀分割的验证集上测得了 85% 的准确性。

验证预测
我们的感觉是,准确率数值低是由于我们的标签很脏。在 Unfriendly 预测结果部分,我们发现,来自验证集的评论确实不友好,但从未被标记过。这些“假”阳性结果根本不是真的假,它们只是被现有的标记系统遗漏了。在 NotUnfriendly 预测结果部分,我们发现,来自验证集被标记为 offensive 的评论,实际上并不是。比如人们说“谢谢”(厚颜无耻!),真的无伤大雅。这些“假”阴性也不是真的假。ULMFiT 发现并改正了一些脏标签,这表明,欠标记假设是真的,那么 ULMFiT 也能找到一些缺失的标识。
人机共生
我们着手构建系统的其余部分,以便 ULMFiT 能够监视所有的新评论,并向我们的版主提供标记建议,让他们处理。我们需要在这里强调一下。我们过去没有,现在也没有兴趣在我们的系统中构建任何东西,让机器在没有人在场的情况下做出最终决定。我们的愿望不是训练、训练、再训练,然后在未来的某个光辉日子里,把标记处理的职责从我们的版主转给 GPU。我们想要建立一个工具来增强我们系统中人类的能力,而不是取代人类。
这个系统的建立还需要几个月的时间。我们必须把在公司里发现的东西社会化。我们必须将模型封装在 Web API 中。我们与 SRE 合作,使我们的云环境达到最佳状态。当新的评论进来时,我们必须让 Stack Overflow 调用模型,并将标记放到版主的仪表板中。我们的社区团队观察了几个星期,参考标记结果调整了标记阈值。我们看着它们工作,让他们在处理标识时记录过程。在得到一个好的验证分数后,有很多东西需要被删除。到目前为止,训练模型是最简单的部分。当所有这些完成后,我们让 Unfriendly Robot V1 投入工作。
Robot 的效果(截至目前)
Unfriendly Robot V1(UR-V1) 于 2019 年 7 月 11 日至 2019 年 9 月 13 日期间一直在运行。在此期间,Stack Overflow 上有 1,715,693 条评论。UR-V1 标记了 15564 条评论(0.9%),其中 6833 条被我们的版主接受,即 UR-V1 的标记有 43.9% 被接受。在同一时期,人类标记了 4870 条(0.2%)不友好的评论,其中 2942 条被我们的版主接受,即 60.4% 的人类标记被接受。
这个结果好吗?为了估计这一点,可以将人和机器人的性能指标合并为两个新指标:机器人评级(Robot Rating)和检测因子(Detection Factor)。

机器人评级高于 1 表明,机器人标记比人类标记更容易被接受。检测因子高于 2 意味着机器人在 Stack Overflow 上发现的令人反感的评论比人类标记者要多。UR-V1 的机器人评级是 0.72,所以其标记不像人类标记那样经常被接受,有很多假阳性。UR-V1 的检测因子为 3.3。UR-V1 帮助版主删除的评论是人类的 3.3 倍。
8 月底,我们又对机器人进行了训练。我们希望得到一个更好的假阳性率(更高的机器人评级),而不损害被接受标记吞吐量(检测因子)。经过大量的训练,最终,UR-V2 通过了测试。UR-V2 于 2019 年 9 月 13 日投入使用。从那时起,Stack Overflow 上已经有 4251,723 条评论。UR-V2 已经标记了 35341 条评论,其中 25695 条被我们的版主接受。人类已经标记了 11810 条不友好的评论,7523 条被我们的版主接受。UR-V2 的机器人等级为 1.14,检测因子为 4.4。在此期间,UR-V2 标记被接受的频率比人类标记高出 14%,而且它帮助版主删除的评论数量是人类标记者的 4.4 倍。
需要明确的是,尽管当前版本的机器人表现非常好,但我们的人类标记者和以前一样重要。这个机器人之所以能做得这么好,唯一的原因是在人类做的事情的基础上进行的。机器人可以寻找与人类以前标记过的东西相类似的东西,但我们不认为它能识别出真正新颖的不友好模式。只有人类才能做到这一点。所以如果你在评论中看到不友好的地方,请标记出来,你正在帮助 Stack Overflow 变得更好。
更新估计
由最初的人类标记系统发现并由版主删除的不友好评论为 0.105%。非员工中位人员发现有 3.5% 的评论是不友好的。这两个估计值相差 33 倍。由新的 Humans+UR-V2 标记系统发现并由版主确认的不友好的 Stack Overflow 评论为 0.78%。Humans+UR-V2 发现的不友好评论是人类以前发现的不友好评论的 7.4 倍。非 Stack Overflow 员工对不友好评论的估计中值是人类标记系统的 33 倍,而现在是 4.4 倍。
我们希望稍微弱化一下这个发现。人们很容易说:“我们发现 Stack Overflow 上的不友好率是多少了,只要看看机器人评级和检测因子就知道了!比我们想象的要高得多!”事实总是有点模糊。根据这里展示的证据,我们未必就有了一个无懈可击的不友好探测器,我们只是有一个在人类标记的不友好评论数据集上训练过的模型,我们的版主会从它那里接受标记。我们知道,并不是所有机器人标记的评论都是不友好的,版主也确实会接受其中一些标记,因为评论有其他需要删除的原因。我们也相信,机器人无法捕捉所有的东西(仍然会有假阴性需要发现)。
未来展望
我们的目标是在 Stack Overflow 上继续加强大家对不友好评论的共识。我们在这里讨论的工作,其重点是更好地估计目前问题的规模,并解决我们先前的两次估计之间的巨大差距,但这绝不是结束。我们想看看,在我们有机器人之前,我们能对系统中的 1 亿条评论做些什么。我们还在考虑如何使用机器人为评论作者提供即时指导。
我们使用这些模型来帮助评估我们对 Stack Overflow 所做的更改。将 A/B 测试与不友好机器人结合起来,让我们可以在做出更改时对不友好评论进行评估。Julia Silge 博士在她对问答向导的最新研究中指出,使用该向导总体上减少了 5% 的评论,但减少了 20% 的不友好评论。帮助提问者提出更好的问题对此有很大的影响,我们会看看是否可以做进一步的系统性改进。
原文地址:
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


InfoQ 主编

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论