

据估计,如今地球上有 6000 多种语言,我们穷其一生也不可能通晓那么多语言。那么,如何理解罕见语言呢?有不少科学家正在研究如何利用人工智能使用这些语言工作,XTREME 便是其中之一。
自然语言处理面临的主要挑战是构建这样一套系统:不仅能用英语,而且也能用世界上所有约 6900 多种语言工作。虽然世界上大多数语言都没有足够的数据来单独训练健壮的模型,但幸运的是,许多语言确实共享了相当多底层结构。
在词汇层面,语言中经常会有同源词,比如英语中的“desk”和德语的“tisch”,都是来自于拉丁文的“discus”。同样,许多语言也以相似的方式标记语义角色,例如在汉语和土耳其语中,使用介词来标记时空关系。
在自然语言处理中,为了克服数据稀疏性问题,有许多方法利用多语言的共享结构进行训练。从历史上看,这些方法大多集中于用多种语言执行特定任务。过去几年,在深度学习进步的推动下,试图学习通用多语言表示(如 mBERT、XLM、XLM-R)方法的数量有所增加,这些方法旨在获取跨语言共享知识,这些知识对许多任务都是有用的。然而,在实践中,对这些方法的评估大多集中在一小部分任务上,并且针对相似的语言。
为了鼓励对多语言学习进行更多研究,我们发表了论文《XTREME:用于评估跨语言泛化的大规模多语言多任务基准》(XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization)。XTREME 涵盖了 40 种不同类型的语言(跨 12 个语系),包括 9 个任务,这些任务都需要对不同层次的语法或语义进行推理。选择 XTREME 中的语言是为了最大限度地提高语言多样性、现有任务的覆盖率和训练数据的可用性。
在这些语言中,还有许多尚未充分研究的语言,如 达罗毗荼语系(Dravidian languages)泰米尔语(Tamil)(印度南部、斯里兰卡和新加坡语言)、泰卢固语(Telugu)和马拉雅拉姆语(Malayalam)(印度南部语言),以及 尼日尔 - 刚果语系(Niger–Congo languages)斯瓦希里语(Swahili)和约鲁巴语(Yoruba)(非洲语言)。我们提供了代码和数据,包括运行各种基准的示例,可在 GitHub 上获得。
地址:https://github.com/google-research/xtreme
XTREME 任务和语言
XTREME 中包含的任务涵盖了一系列范式,包括文档分类、结构化预测、文献检索和问答系统。因此,为了使模型在 XTREME 基准测试上取得成功,它们必须学习泛化到许多标准跨语言迁移设置的表示法。
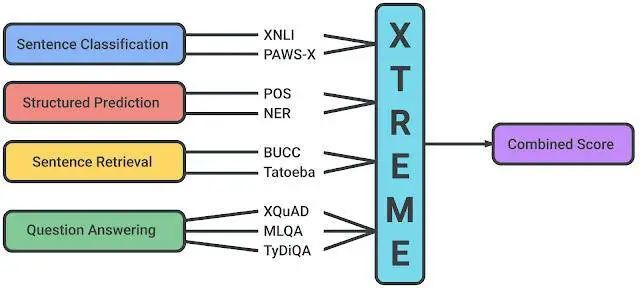
XTREME 基准测试中支持的任务
每个任务都包含 40 种语言的一个子集。为了获得更多用于 XTREME 分析的低资源语言数据,我们将自然语言推理(XNLI)和问答系统(XQuAD)这两个具有代表性任务的测试集从英语自动翻译成其他语言。我们的实验表明,在这些任务中使用翻译后的测试集的模型表现出了与使用人类标记的测试集相当的性能。
零样本评估
要评估使用 XTREME 的性能,首先必须对模型进行多语言文本的预训练,并使用鼓励跨语言学习的目标。然后,对特定任务的英语数据进行微调,因为英语是最有可能提供标签数据的语言。然后,XTREME 评估这些模型的零样本跨语言传输性能,也就是说,在没有特定任务数据的其他语言上对这些模型进行评估。如下图所示,三个步骤的过程,包括从预训练到微调再到零样本迁移。
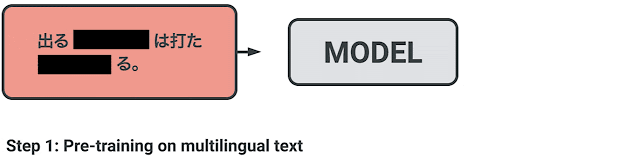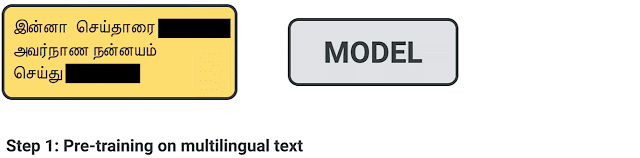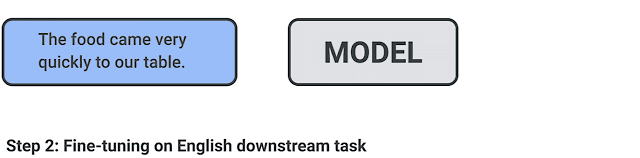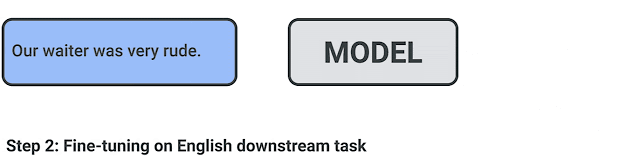
针对给定模型的跨语言迁移学习过程:对多语言文本进行预训练,然后对下游任务进行英语微调,最后使用 XTREME 进行零样本评估。
在实践中,这种零样本设置的好处之一是计算效率:预训练模型只需对每个任务的英语数据进行微调,然后就可以直接在其他语言上进行评估了。不过,对于有其他语言的标签数据的任务,我们也会在语言数据上进行微调对比。最后,我们通过获得所有 9 个 XTREME 任务的零样本得分来提供一个综合得分。
迁移学习的测试平台
我们使用几种较优的预训练多语言模型进行实验,包括 multilingual BERT,一种流行的 BERT 模型的多语言扩展:XLM 和 XLM-R,两个更大的多语言 BERT 版本,以及大规模多语言机器翻译模型 M4。这些模型有一个共同特点,就是它们已经对来自多语言的大量数据进行了预训练。在我们的实验中,我们选择了这些模型的变体,这些变体在大约 100 种语言上进行了预训练,其中包括基准测试的 40 种语言。
我们发现,尽管模型在大多数现有英语任务上实现了接近人类的表现,但在其他许多语言上的表现却明显低于人类。在所有模型的结构化预测和问答系统任务中,英语的表现与其他语言的表现差距最大,而在结构化预测和文档检索中,不同语言的结果分布最大。
为说明这一点,在下图中,我们按任务和语言的不同,显示了在所有语系中表现最好的模型 XLM-R 在零样本设置中的情况。不同任务之间的得分没有可比性,所以主要关注的应该是不同任务之间语言的相对排名。正如我们所看到的,许多高资源的语言,特别是印欧语系的语言,其排名一直较高。相比之下,该模型在其他语系,如汉藏语系、日本 - 琉球语系、朝鲜语系、尼日尔 - 刚果语系等语言上的表现较差。
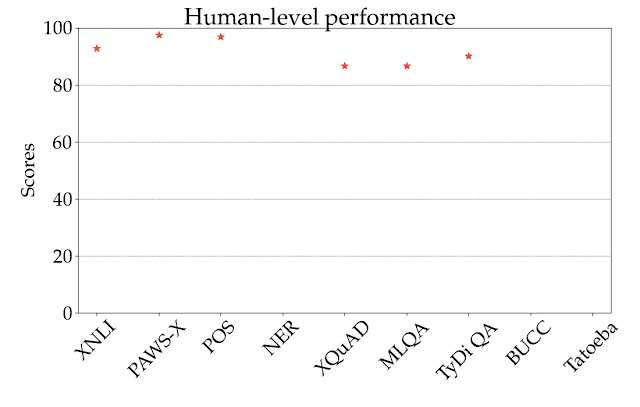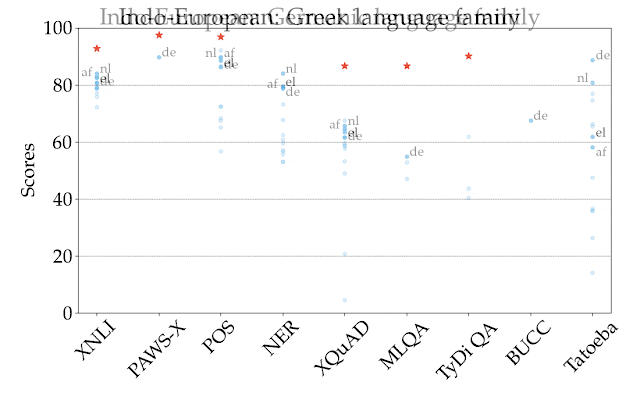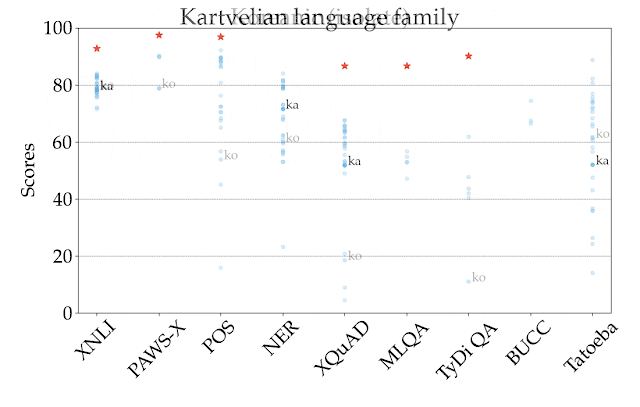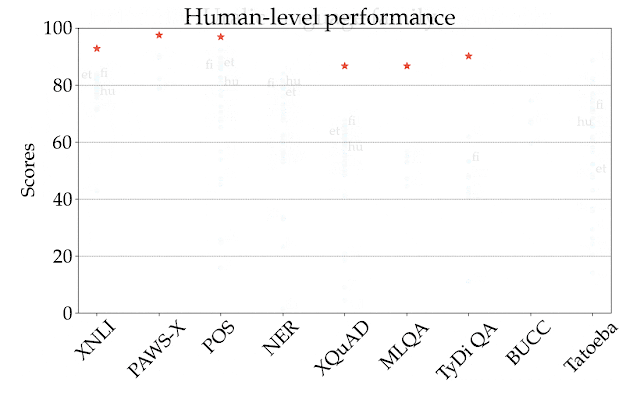
XTREME 中所有任务和语言在零样本设置下的最佳表现模型 XLM-R 的性能。所报的分数是基于特定任务的度量标准的百分比,在不同任务中并不能直接比较。人类的表现(如果有的话)以红星表示,每种语系的具体示例均以其 ISO 639-1 编码表示。
总的来说,我们进行了一些有趣的观察。
在零样本设置中,M4 和 mBERT 在大多数任务中都能与 XLM-R 竞争,而在特别有挑战性的问答系统任务中,后者的表现要优于它们。例如,在 XQuAD 上,XLM-R 的得分为 76.6,而 mBERT 和 M4 的得分分别为 64.5 和 64.8,在 MLQA 和 TyDi QA 上也有类似的得分差距。
我们发现,使用机器翻译的基准,无论是翻译训练数据还是测试数据,都非常有竞争力。在 XNLI 任务中,mBERT 在零样本设置中得分为 65.4,而在使用翻译训练数据时得分为 74.0。
我们观察到,少样本设置(即使用有限数量的语言内标记数据,如果可用的话)对于较简单的任务(如命名实体识别)特别有竞争力,但对于较复杂的问答系统任务来说,作用不大。这一点可从 mBERT 的表现中看出,在少样本设置中,mBERT 在命名实体识别任务上的表现提到了 42%,得分从 62.2 提高到 88.3,但对于问答系统任务(TyDi QA),只提高了 25%(得分从 59.7 提高到 74.5)。
总的来说,在所有模式和环境中,英语与其他语言的表现仍存在较大差距,这说明跨语言迁移的研究仍然有很大的潜力。
跨语言迁移分析
与之前关于深度模型的泛化能力的观察类似,我们发现,与具有更多预训练数据的 XLM-R 相比,如果一种语言有更多的预训练数据可用,如 mBERT,那么结果就会有所改善。然而,我们发现,这种相关性对于结构化预测任务、词性(part-of-speech,POS)标记和命名实体识别(named entity recognition,NER)来说并不成立,这表明当前的深度预训练模型无法充分利用预训练数据迁移到这类语法任务中。我们还发现,模型在迁移到非拉丁文脚本时存在困难。这在词性标记任务上表现得尤为明显,mBERT 在西班牙语上的零样本正确率为 86.9,而在日语上的零样本正确率仅为 49.2。
对于自然语言推理任务 XNLI,我们发现,模型对一个英语测试实例和另一种语言的同一个测试实例进行预测,大约有 70% 的时间,模型会做出相同的预测。半监督的方法可能有助于提高实例预测与它们在不同语言翻译之间的一致性。我们还发现,这些模型很难预测英语训练数据中没有出现的词性标记序列,因为它们是在英语训练数据上进行微调的,这凸显了这些模型很难从用于预训练的大量未标记数据中学习其他语言的语法。对于命名实体识别,模型在语言距离很大的英语训练数据中没有出现的实体时最困难:印尼语(Indonesian)和斯瓦西里语(Swahili)的正确率分别为 58.0 和 66.6,而葡萄牙语(Portguese)和法语(French)的正确率分别为 82.3 和 80.1。
多语言迁移学习研究进展
尽管英语只占世界人口的 15% 左右,但它一直是自然语言处理领域最新进展的焦点。我们相信,在深度上下文表示的基础上,我们现在有了工具,可以在服务于世界上其他语言的系统上取得实质性的进展。我们希望,XTREME 能够推动多语言迁移学习的研究,就像 GLUE 和 SUperGLUE 这样的基准模型如何推动深度单语言模型的发展一样,包括 BERT、RoBERTa、XLNet、AIBERT 等。
作者简介:
Melvin Johnson,Google Research 高级软件工程师。
Sebastian Ruder,DeepMind 研究科学家。
原文链接:
https://ai.googleblog.com/2020/04/xtreme-massively-multilingual-multi.html
公众号推荐:
2024 年 1 月,InfoQ 研究中心重磅发布《大语言模型综合能力测评报告 2024》,揭示了 10 个大模型在语义理解、文学创作、知识问答等领域的卓越表现。ChatGPT-4、文心一言等领先模型在编程、逻辑推理等方面展现出惊人的进步,预示着大模型将在 2024 年迎来更广泛的应用和创新。关注公众号「AI 前线」,回复「大模型报告」免费获取电子版研究报告。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论