

背景
配送骑手端 App 是骑手用于完成配送履约的应用,帮助骑手完成接单、到店、取货及送达,提供各种不同的运力服务,也是整个外卖闭环中的重要节点。由于配送业务的特性,骑手 App 对于应用稳定性的要求非常高,体现 App 稳定性的一个重要数据就是 Crash 率,而在众多 Crash 中最棘手最难定位的就是 OOM 问题。对于骑手端 App 而言,每天骑手都会长时间的使用 App 进行配送,而在长时间的使用过程中,App 中所有的内存泄漏都会慢慢累积在内存中,最后就容易导致 OOM,从而影响骑手的配送效率,进而影响整个外卖业务。
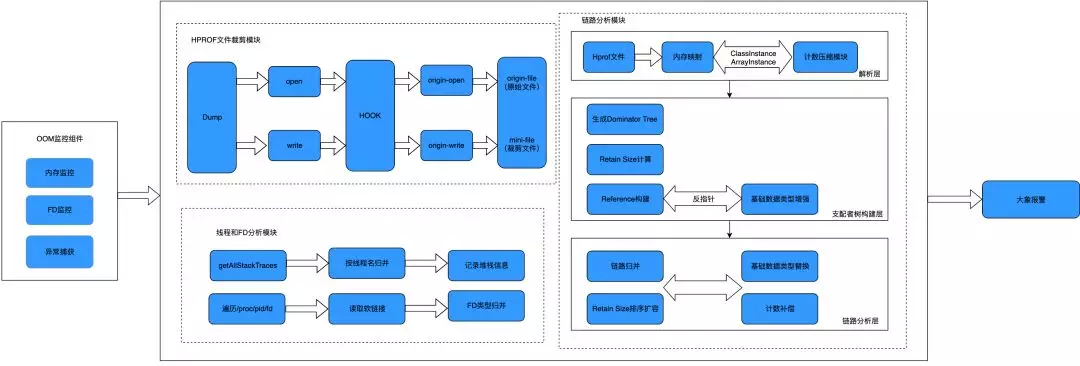
于是我们构建了用于快速定位线上 OOM 问题的组件——Probe,下图是 Probe 组件架构,本文主要分享 Probe 组件是如何对线上 OOM 问题进行快速定位的。
OOM 原因分析
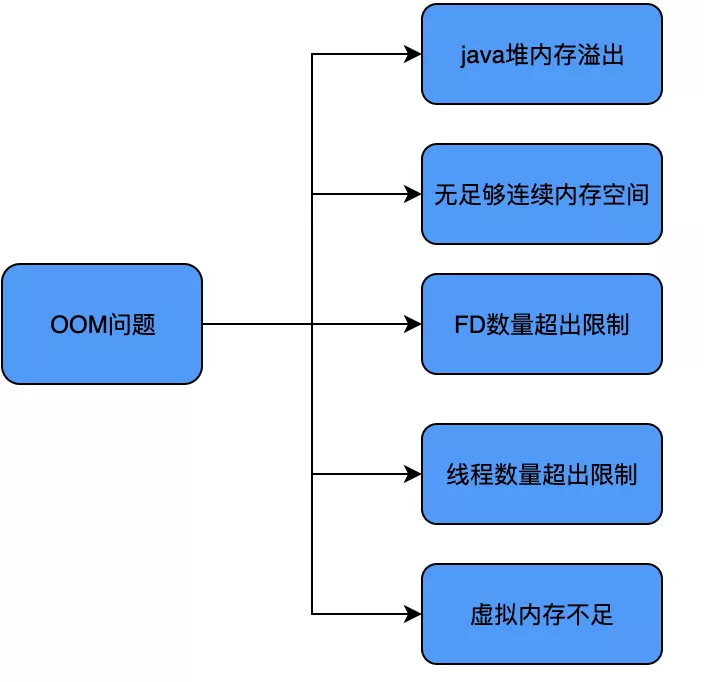
要定位 OOM 问题,首先需要弄明白 Android 中有哪些原因会导致 OOM,Android 中导致 OOM 的原因主要可以划分为以下几个类型:
Android 虚拟机最终抛出 OutOfMemoryError 的代码位于/art/runtime/thread.cc。
下面两个地方都会调用上面方法抛出 OutOfMemoryError 错误,这也是 Android 中发生 OOM 的主要原因。
堆内存分配失败
系统源码文件:/art/runtime/gc/heap.cc
这是在进行堆内存分配时抛出的 OOM 错误,这里也可以细分成两种不同的类型:
为对象分配内存时达到进程的内存上限。由 Runtime.getRuntime.MaxMemory()可以得到 Android 中每个进程被系统分配的内存上限,当进程占用内存达到这个上限时就会发生 OOM,这也是 Android 中最常见的 OOM 类型。
没有足够大小的连续地址空间。这种情况一般是进程中存在大量的内存碎片导致的,其堆栈信息会比第一种 OOM 堆栈多出一段信息:failed due to fragmentation (required continguous free “<< required_bytes << " bytes for a new buffer where largest contiguous free " << largest_continuous_free_pages << " bytes)”; 其详细代码在 art/runtime/gc/allocator/rosalloc.cc 中,这里不作详述。
创建线程失败
系统源码文件:/art/runtime/thread.cc
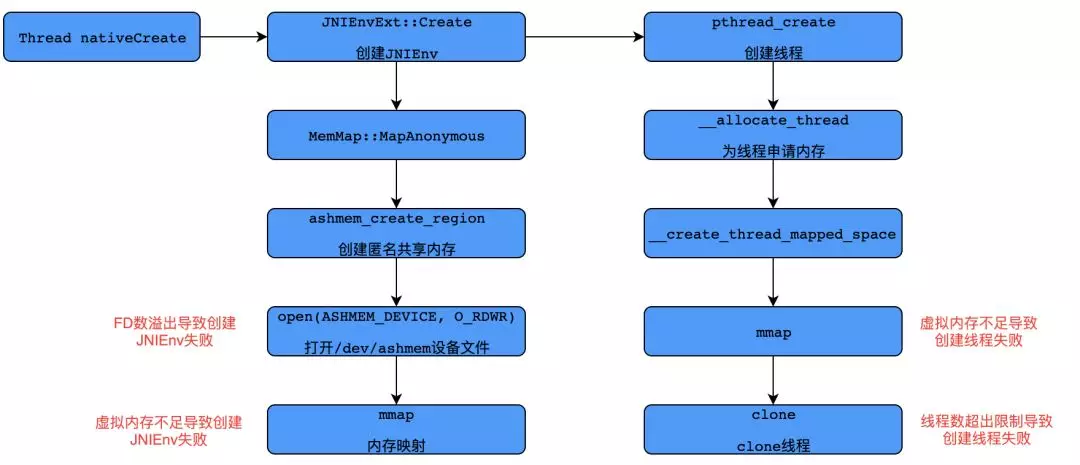
这是创建线程时抛出的 OOM 错误,且有多种错误信息。源码这里不展开详述了,下面是根据源码整理的 Android 中创建线程的步骤,其中两个关键节点是创建 JNIEnv 结构体和创建线程,而这两步均有可能抛出 OOM。
创建 JNI 失败
创建 JNIEnv 可以归为两个步骤:
通过 Andorid 的匿名共享内存(Anonymous Shared Memory)分配 4KB(一个 page)内核态内存。
再通过 Linux 的 mmap 调用映射到用户态虚拟内存地址空间。
第一步创建匿名共享内存时,需要打开/dev/ashmem 文件,所以需要一个 FD(文件描述符)。此时,如果创建的 FD 数已经达到上限,则会导致创建 JNIEnv 失败,抛出错误信息如下:
第二步调用 mmap 时,如果进程虚拟内存地址空间耗尽,也会导致创建 JNIEnv 失败,抛出错误信息如下:
创建线程失败
创建线程也可以归纳为两个步骤:
调用 mmap 分配栈内存。这里 mmap flag 中指定了 MAP_ANONYMOUS,即匿名内存映射。这是在 Linux 中分配大块内存的常用方式。其分配的是虚拟内存,对应页的物理内存并不会立即分配,而是在用到的时候触发内核的缺页中断,然后中断处理函数再分配物理内存。
调用 clone 方法进行线程创建。
第一步分配栈内存失败是由于进程的虚拟内存不足,抛出错误信息如下:
第二步 clone 方法失败是因为线程数超出了限制,抛出错误信息如下:
OOM 问题定位
在分析清楚 OOM 问题的原因之后,我们对于线上的 OOM 问题就可以做到对症下药。而针对 OOM 问题,我们可以根据堆栈信息的特征来确定这是哪一个类型的 OOM,下面分别介绍使用 Probe 组件是如何去定位线上发生的每一种类型的 OOM 问题的。
堆内存不足
Android 中最常见的 OOM 就是 Java 堆内存不足,对于堆内存不足导致的 OOM 问题,发生 Crash 时的堆栈信息往往只是“压死骆驼的最后一根稻草”,它并不能有效帮助我们准确地定位到问题。
堆内存分配失败,通常说明进程中大部分的内存已经被占用了,且不能被垃圾回收器回收,一般来说此时内存占用都存在一些问题,例如内存泄漏等。要想定位到问题所在,就需要知道进程中的内存都被哪些对象占用,以及这些对象的引用链路。而这些信息都可以在 Java 内存快照文件中得到,调用 Debug.dumpHprofData(String fileName)函数就可以得到当前进程的 Java 内存快照文件(即 HPROF 文件)。所以,关键在于要获得进程的内存快照,由于 dump 函数比较耗时,在发生 OOM 之后再去执行 dump 操作,很可能无法得到完整的内存快照文件。
于是 Probe 对于线上场景做了内存监控,在一个后台线程中每隔 1S 去获取当前进程的内存占用(通过 Runtime.getRuntime.totalMemory()-Runtime.getRuntime.freeMemory()计算得到),当内存占用达到设定的阈值时(阈值根据当前系统分配给应用的最大内存计算),就去执行 dump 函数,得到内存快照文件。
在得到内存快照文件之后,我们有两种思路,一种想法是直接将 HPROF 文件回传到服务器,我们拿到文件后就可以使用分析工具进行分析。另一种想法是在用户手机上直接分析 HPROF 文件,将分析完得到的分析结果回传给服务器。但这两种方案都存在着一些问题,下面分别介绍我们在这两种思路的实践过程中遇到的挑战和对应的解决方案。
线上分析
首先,我们介绍几个基本概念:
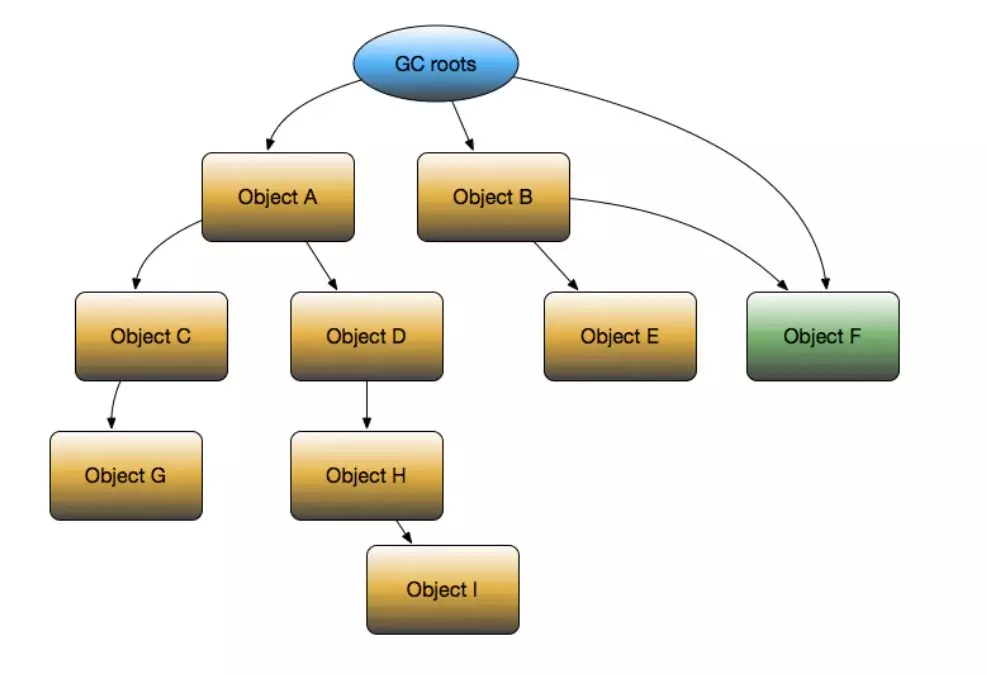
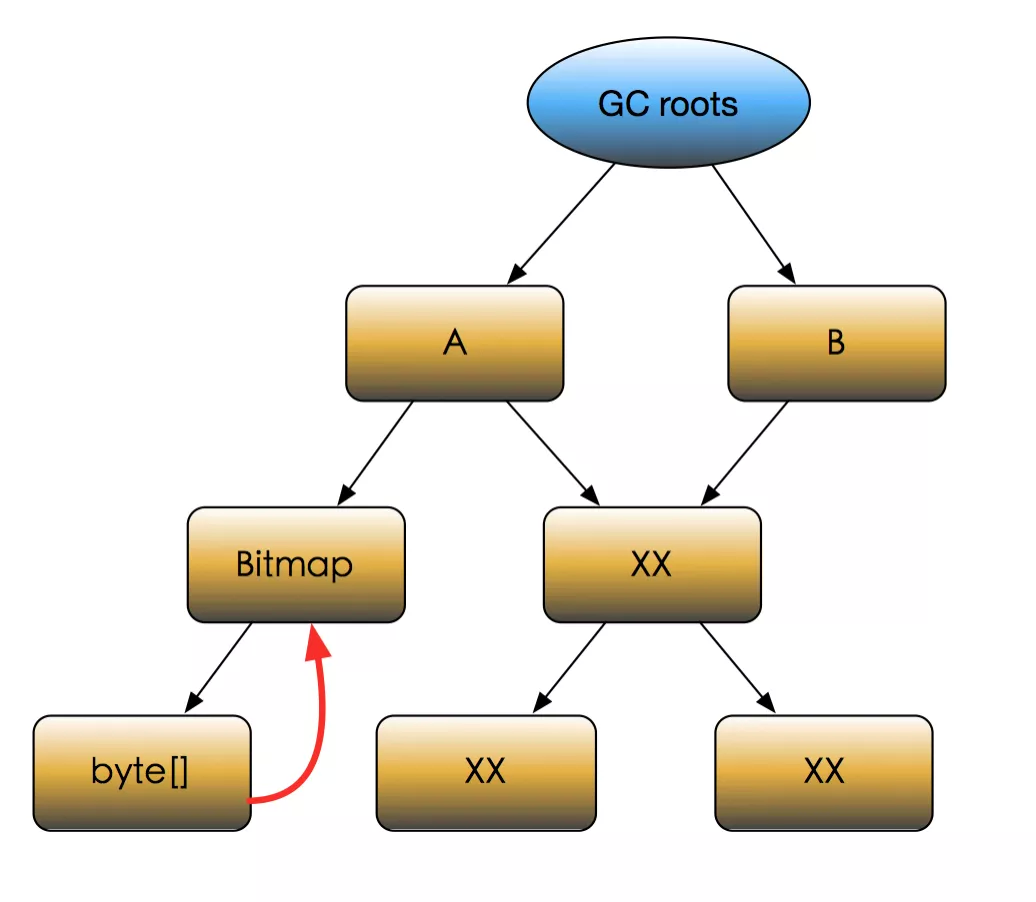
Dominator:从 GC Roots 到达某一个对象时,必须经过的对象,称为该对象的 Dominator。例如在上图中,B 就是 E 的 Dominator,而 B 却不是 F 的 Dominator。
ShallowSize:对象自身占用的内存大小,不包括它引用的对象。
RetainSize:对象自身的 ShallowSize 和对象所支配的(可直接或间接引用到的)对象的 ShallowSize 总和,就是该对象 GC 之后能回收的内存总和。例如上图中,D 的 RetainSize 就是 D、H、I 三者的 ShallowSize 之和。
JVM 在进行 GC 的时候会进行可达性分析,当一个对象到 GC Roots 没有任何引用链相连(用图论的话来说,就是从 GC Roots 到这个对象不可达)时,则证明此对象是可回收的。
Github 上有一个开源项目HAHA库,用于自动解析和分析 Java 内存快照文件(即 HPROF 文件)。下面是 HAHA 库的分析步骤:
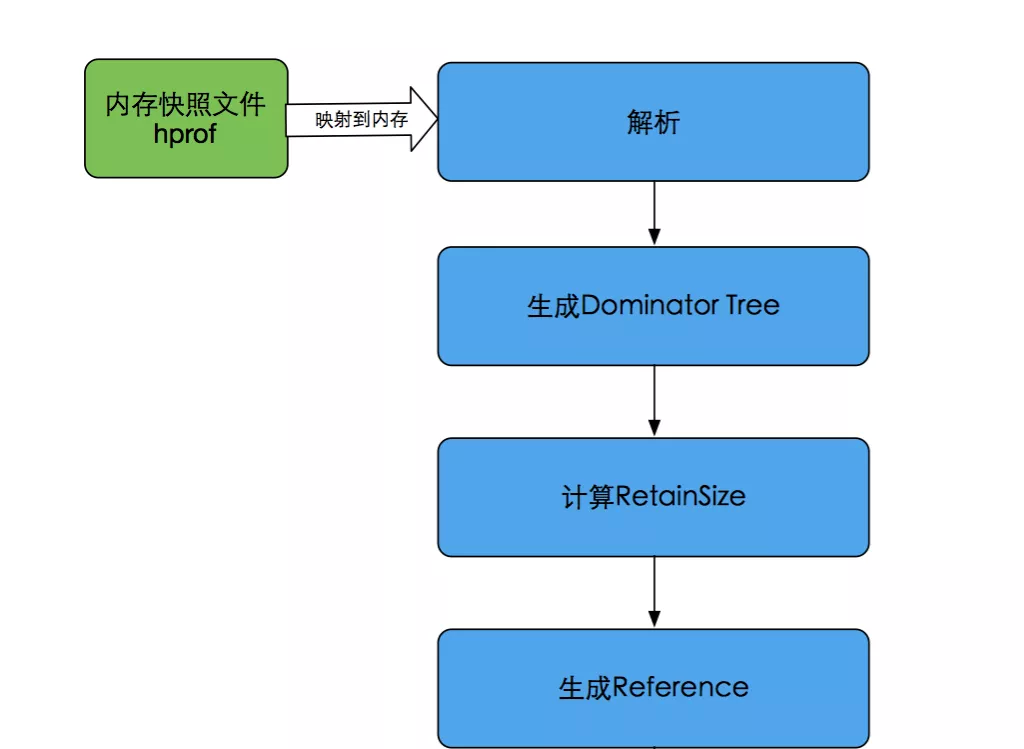
于是我们尝试在 App 中去新开一个进程使用 HAHA 库分析 HPROF 文件,在线下测试过程中遇到了几个问题,下面逐一进行叙述。
分析进程自身 OOM
测试时遇到的最大问题就是分析进程自身经常会发生 OOM,导致分析失败。为了弄清楚分析进程为什么会占用这么大内存,我们做了两个对比实验:
在一个最大可用内存 256MB 的手机上,让一个成员变量申请特别大的一块内存 200 多 MB,人造 OOM,Dump 内存,分析,内存快照文件达到 250 多 MB,分析进程占用内存并不大,为 70MB 左右。
在一个最大可用内存 256MB 的手机上,添加 200 万个小对象(72 字节),人造 OOM,Dump 内存,分析,内存快照文件达到 250 多 MB,分析进程占用内存增长很快,在解析时就发生 OOM 了。
实验说明,分析进程占用内存与 HPROF 文件中的 Instance 数量是正相关的,在将 HPROF 文件映射到内存中解析时,如果 Instance 的数量太大,就会导致 OOM。
HPROF 文件映射到内存中会被解析成 Snapshot 对象(如下图所示),它构建了一颗对象引用关系树,我们可以在这颗树中查询各个 Object 的信息,包括 Class 信息、内存地址、持有的引用以及被持有引用的关系。
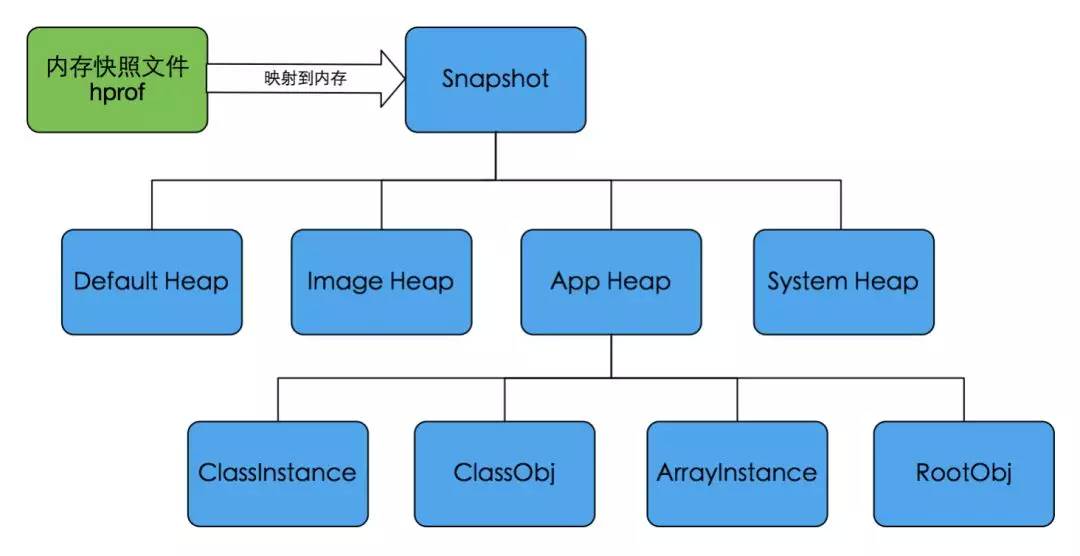
HPROF 文件映射到内存的过程:
为了解决分析进程 OOM 的问题,我们在 HprofParser 的解析逻辑中加入了计数压缩逻辑(如下图所示),目的是在文件映射过程去控制 Instance 的数量。在解析过程中对于 ClassInstance 和 ArrayInstance,以类型为 key 进行计数,当同一类型的 Instance 数量超过阈值时,则不再向 Snapshot 中添加该类型的 Instance,只是记录 Intsance 被丢弃的数量和 Instance 大小。这样就可以控制住每一种类型的 Instance 数量,减少了分析进程的内存占用,在很大程度上避免了分析进程自身的 OOM 问题。既然我们在解析时丢弃了一部分 Instance,后面就得把丢弃的这部分找补回来,所以在计算 RetainSize 时我们会进行计数桶补偿,即把之前丢弃的相同类型的 Instance 数量和大小都补偿到这个对象上,累积去计算 RetainSize。
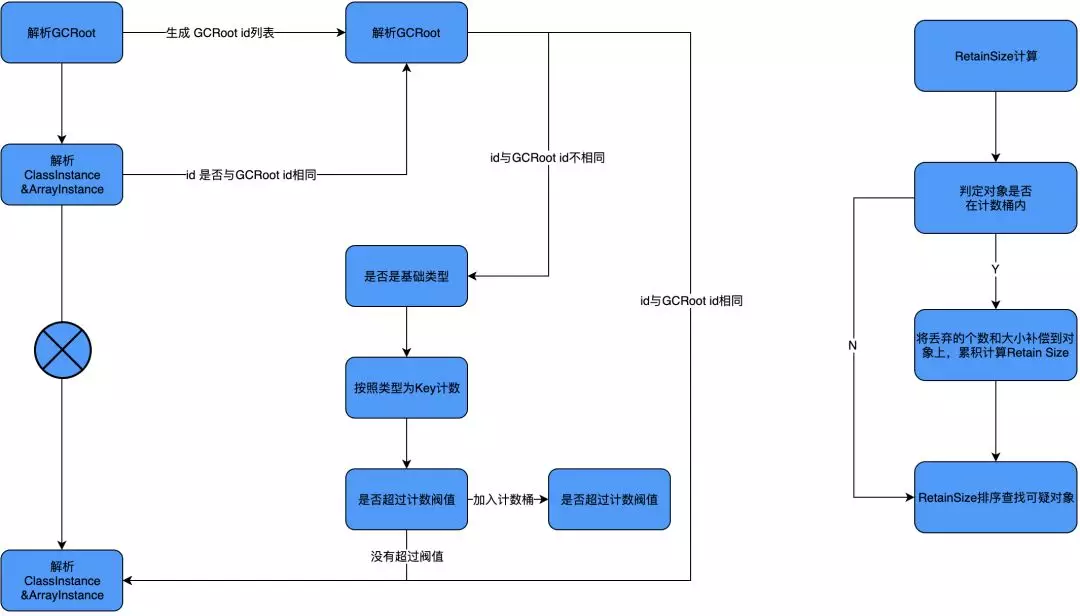
链路分析时间过长
在线下测试过程中还遇到了一个问题,就是在手机上进行链路分析的耗时太长。
使用 HAHA 算法在 PC 上可以快速地对所有对象都进行链路分析,但是在手机上由于性能的局限性,如果对所有对象都进行链路分析会导致分析耗时非常长。
考虑到 RetainSize 越大的对象对内存的影响也越大,即 RetainSize 比较大的那部分 Instance 是最有可能造成 OOM 的“元凶”。
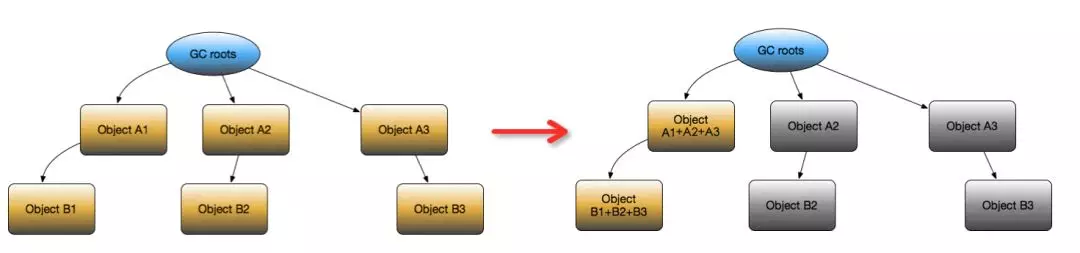
我们在生成 Reference 之后,做了一步链路归并(如上图所示),即对于同一个对象的不同 Instance,如果其底下的引用链路中的对象类型也相同,则进行归并,并记录 Instance 的个数和每个 Instance 的 RetainSize。
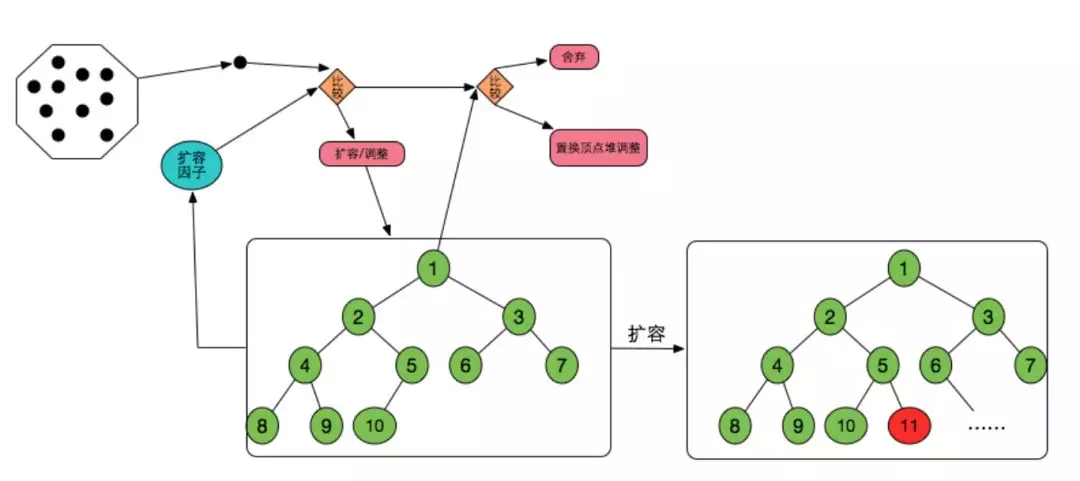
然后对归并后的 Instance 按 RetainSize 进行排序,取出 TOP N 的 Instance,其中在排序过程中我们会对 N 的值进行动态调整,保证 RetainSize 达到一定阈值的 Instance 都能被发现。对于这些 Instance 才进行最后的链路分析,这样就能大大缩短分析时长。
排序过程:创建一个初始容量为 5 的集合,往里添加 Instance 后进行排序,然后遍历后面的 Instance,当 Instance 的 RetainSize 大于总共消耗内存大小的 5%时,进行扩容,并重新排序。当 Instance 的 RetainSize 大于现有集合中的最小值时,进行替换,并重新排序。
基础类型检测不到
为了解决 HAHA 算法中检测不到基础类型泄漏的问题,我们在遍历堆中的 Instance 时,如果发现是 ArrayInstance,且是 byte 类型时,将它自身舍弃掉,并将它的 RetainSize 加在它的父 Instance 上,然后用父 Instance 进行后面的排序。
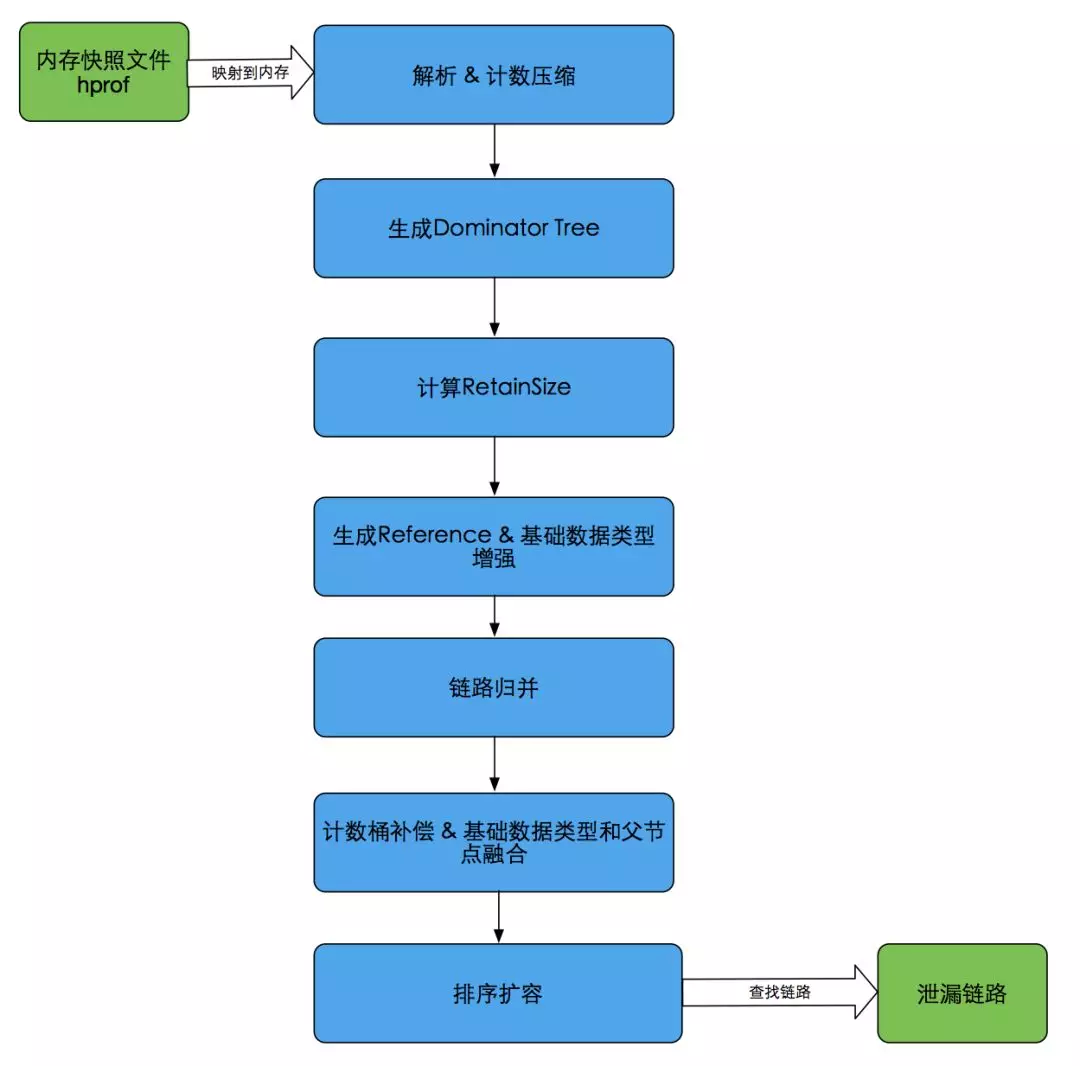
至此,我们对 HAHA 的原始算法做了诸多优化(如下图所示),很大程度解决了分析进程自身 OOM 问题、分析时间过长问题以及基础类型检测不到的问题。
针对线上堆内存不足问题,Probe 最后会自动分析出 RetainSize 大小 Top N 对象到 GC Roots 的链路,上报给服务器,进行报警。下面是一个线上案例,这里截取了上报的链路分析结果中的一部分,完整的分析结果就是多个这样的组合。在第一段链路分析可以看到,有个 Bitmap 对象占用了 2MB 左右的内存,根据链路定位到代码,修复了 Bitmap 泄漏问题。第二段链路分析反映的是一个 Timer 泄漏问题,可以看出内存中存在 4 个这样的 Instance,每个 Instance 的 Retain Size 是 595634,所以这个问题会泄漏的内存大小是 4*595634=2.27MB。
裁剪回捞 HPROF 文件
在 Probe 上线分析方案之后,发现尽管我们做了很多优化,但是受到手机自身性能的约束,线上分析的成功率也只有 65%。
于是,我们对另一种思路即回捞 HPROF 文件后本地分析进行了探索,这种方案最大的问题就是线上流量问题,因为 HPROF 文件动辄几百 MB,如果直接进行上传,势必会对用户的流量消耗带来巨大影响。
使用这种方案的关键点就在于减少上传的 HPROF 文件大小,减少文件大小首先想到的就是压缩,不过只是做压缩的话,文件还是太大。接下来,我们就考虑几百 MB 的文件内容是否都是我们需要的,是否可以对文件进行裁剪。我们希望对 HPROF 无用的信息进行裁剪,只保留我们关心的数据,就需要先了解 HPROF 文件的格式:
Debug.dumpHprofData()其内部调用的是 VMDebug 的同名函数,层层深入最终可以找到/art/runtime/hprof/hprof.cc,HPROF 的生成操作基本都是在这里执行的,结合 HAHA 库代码阅读 hrpof.cc 的源码。
HPROF 文件的大体格式如下:

一个 HPROF 文件主要分为这四部分:
文件头。
字符串信息:保存着所有的字符串,在解析的时候通过索引 id 被引用。
类的结构信息:是所有 Class 的结构信息,包括内部的变量布局,父类的信息等等。
堆信息:即我们关心的内存占用与对象引用的详细信息。
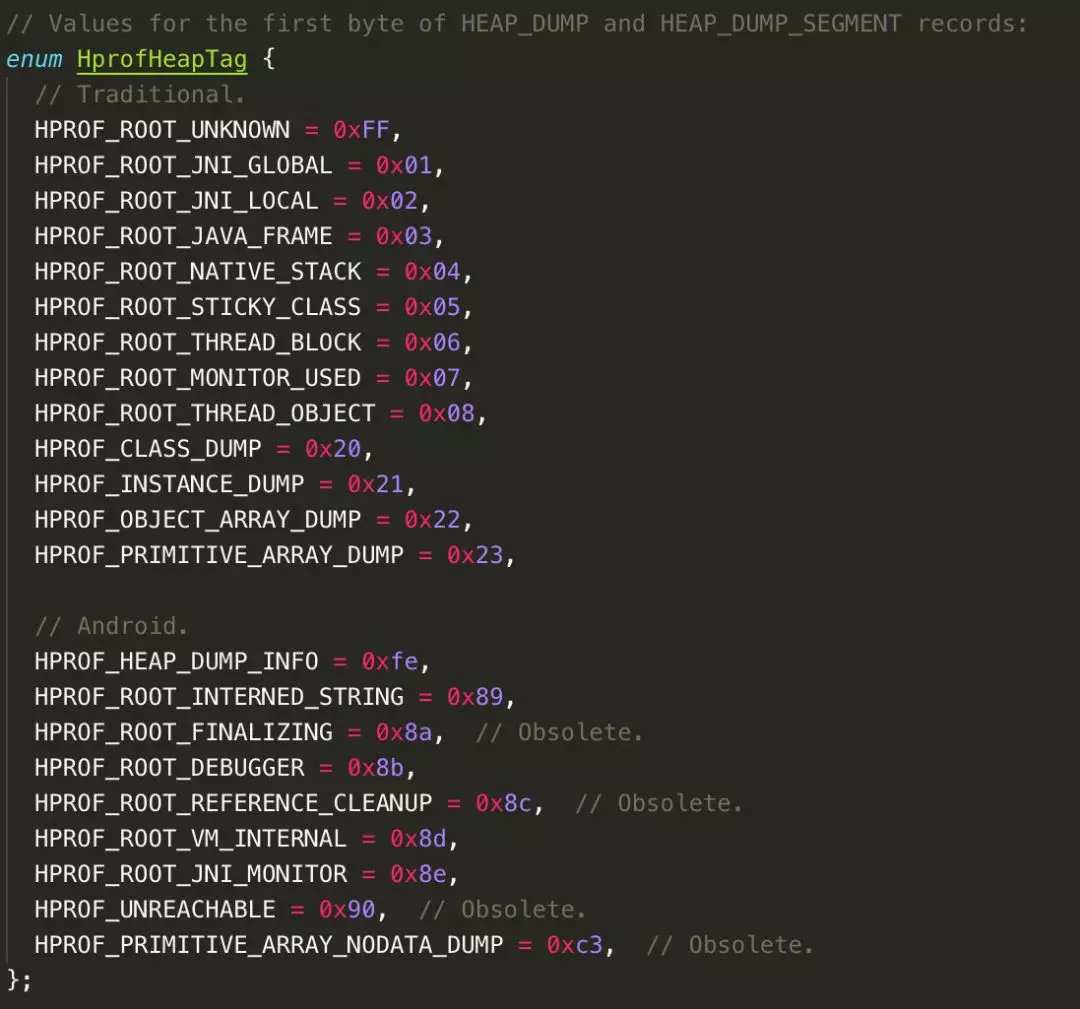
其中我们最关心的堆信息是由若干个相同格式的元素组成,这些元素的大体格式如下图:

每个元素都有个 TAG 用来标识自己的身份,而后续字节数则表示元素的内容长度。元素携带的内容则是若干个子元素组合而成,通过子 TAG 来标识身份。
具体的 TAG 和身份的对应关系可以在 hrpof.cc 源码中找到,这里不进行展开。
弄清楚了文件格式,接下来需要确定裁剪内容。经过思考,我们决定裁减掉全部基本类型数组的值,原因是我们的使用场景一般是排查内存泄漏以及 OOM,只关心对象间的引用关系以及对象大小即可,很多时候对于值并不是很在意,所以裁减掉这部分的内容不会对后续的分析造成影响。
最后需要确定裁剪方案。先是尝试了 dump 后在 Java 层进行裁剪,发现效率很低,很多时候这一套操作下来需要 20s。然后又尝试了 dump 后在 Native 层进行裁剪,这样做效率是高了点,但依然达不到预期。
经过思考,如果能够在 dump 的过程中筛选出哪些内容是需要保留的,哪些内容是需要裁剪的,需要裁剪的内容直接不写入文件,这样整个流程的性能和效率绝对是最高的。
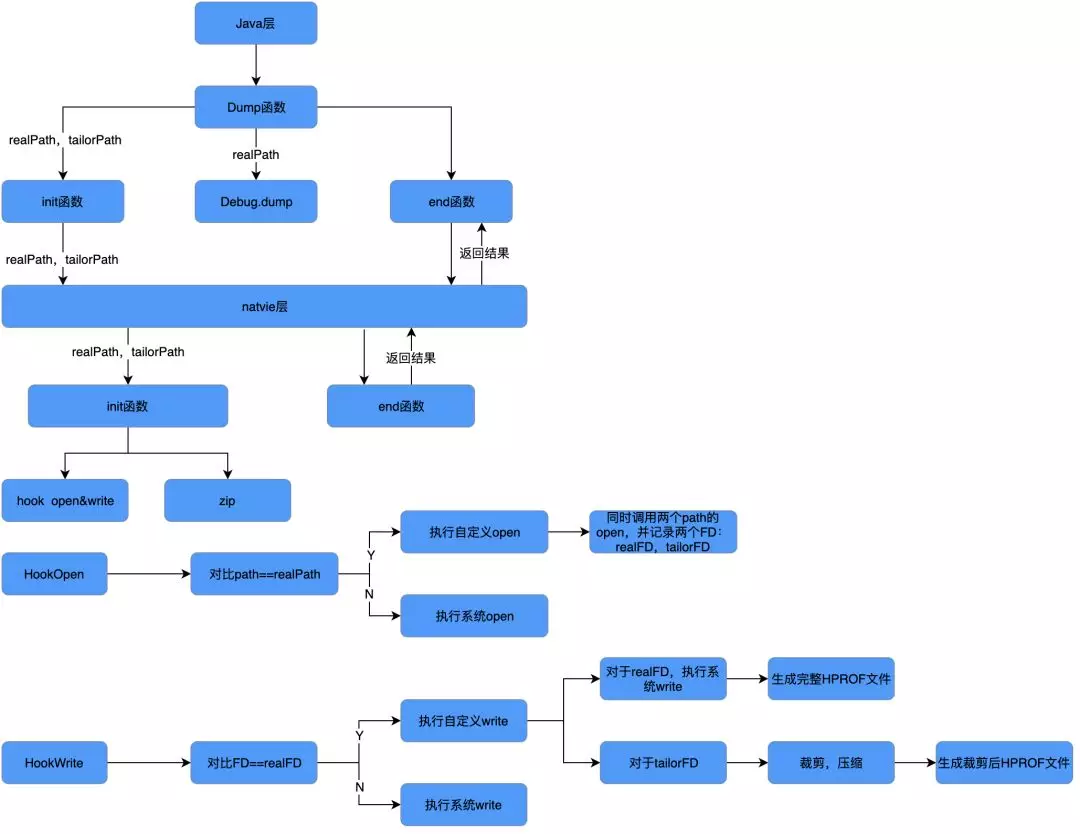
为了实现这个想法,我们使用了 GOT 表 Hook 技术(这里不展开介绍)。有了 Hook 手段,但是还没有找到合适的 Hook 点。通过阅读 hrpof.cc 的源码,发现最适合的点就是在写入文件时,拿到字节流进行裁剪操作,然后把有用的信息写入文件。于是项目最终的结构如下图:

我们对 IO 的关键函数 open 和 write 进行 Hook。Hook 方案使用的是爱奇艺开源的xHook库。
在执行 dump 的准备阶段,我们会调用 Native 层的 open 函数获得一个文件句柄,但实际执行时会进入到 Hook 层中,然后将返回的 FD 保存下来,用作 write 时匹配。
在 dump 开始时,系统会不断的调用 write 函数将内容写入到文件中。由于我们的 Hook 是以 so 为目标的,系统运行时也会有许多写文件的操作,所以我们需要对前面保存的 FD 进行匹配。若 FD 匹配成功则进行裁剪,否则直接调用 origin-write 进行写入操作。
流程结束后,就会得到裁剪后的 mini-file,裁剪后的文件大小只有原始文件大小的十分之一左右,用于线上可以节省大部分的流量消耗。拿到 mini-file 后,我们将裁剪部分的位置填上字节 0 来进行恢复,这样就可以使用传统工具打开进行分析了。
原始 HPROF 文件和裁剪后再恢复的 HPROF 文件分别在 Android Studio 中打开,发现裁剪再恢复的 HPROF 文件打开后,只是看不到对象中的基础数据类型值,而整个的结构、对象的分布以及引用链路等与原始 HPROF 文件是完全一致的。事实证明裁剪方案不会影响后续对堆内存的链路分析。
方案融合
由于目前裁剪方案在部分机型上(主要是 Android 7.X 系统)不起作用,所以在 Probe 中同时使用了这两种方案,对两种方案进行了融合。即通过一次 dump 操作得到两份 HPROF 文件,一份原始文件用于下次启动时分析,一份裁剪后的文件用于上传服务器。
Probe 的最终方案实现如下图,主要是在调用 dump 函数之前先将两个文件路径(希望生成的原始文件路径和裁剪文件路径)传到 Native 层,Native 层记录下两个文件路径,并对 open 和 write 函数进行 Hook。hookopen 函数主要是通过 open 函数传入的 path 和之前记录的 path 比对,如果相同,我们就会同时调用之前记录的两个 path 的 open,并记录下两个 FD,如果不相同则直接调原生 open 函数。hookwrite 函数主要是通过传入的 FD 与之前 hookopen 中记录的 FD 比对,如果相同会先对原始文件对应的 FD 执行原生 write,然后对裁剪文件对应的 FD 执行我们自定义的 write,进行裁剪压缩。这样再传入原始文件路径调用系统的 dump 函数,就能够同时得到一份完整的 HPROF 文件和一份裁剪后的 HPROF 文件。
线程数超出限制
对于创建线程失败导致的 OOM,Probe 会获取当前进程所占用的虚拟内存、进程中的线程数量、每个线程的信息(线程名、所属线程组、堆栈信息)以及系统的线程数限制,并将这些信息上传用于分析问题。
/proc/sys/kernel/threads-max 规定了每个进程创建线程数目的上限。在华为的部分机型上,这个上限被修改的很低(大约 500),比较容易出现线程数溢出的问题,而大部分手机这个限制都很大(一般为 1W 多)。在这些手机上创建线程失败大多都是因为虚拟内存空间耗尽导致的,进程所使用的虚拟内存可以查看/proc/pid/status 的 VmPeak/VmSize 记录。
然后,通过 Thread.getAllStackTraces()可以得到进程中的所有线程以及对应的堆栈信息。
一般来说,当进程中线程数异常增多时,都是某一类线程被大量的重复创建。所以我们只需要定位到这类线程的创建时机,就能知道问题所在。如果线程是有自定义名称的,那么直接就可以在代码中搜索到创建线程的位置,从而定位问题,如果线程创建时没有指定名称,那么就需要通过该线程的堆栈信息来辅助定位。下面这个例子,就是一个“crowdSource msg”的线程被大量重复创建,在代码中搜索名称很快就查出了问题。针对这类线程问题推荐的做法就是在项目中统一使用线程池,可以很大程度上避免线程数的溢出问题。
线程信息:
FD 数超出限制
前面介绍了,当进程中的 FD 数量达到最大限制时,再去新建线程,在创建 JNIEnv 时会抛出 OOM 错误。但是 FD 数量超出限制除了会导致创建线程抛出 OOM 以外,还会导致很多其它的异常,为了能够统一处理这类 FD 数量溢出的问题,Probe 中对进程中的 FD 数量做了监控。在后台启动一个线程,每隔 1s 读取一次当前进程创建的 FD 数量,当检测到 FD 数量达到阈值时(FD 最大限制的 95%),读取当前进程的所有 FD 信息归并后上报。
在/proc/pid/limits 描述着 Linux 系统对对应进程的限制,其中 Max open files 就代表可创建 FD 的最大数目。
进程中创建的 FD 记录在/proc/pid/fd 中,通过遍历/proc/pid/fd,可以得到 FD 的信息。
获取 FD 信息:
得到进程中所有的 FD 信息后,我们会先按照 FD 的类型进行一个归并,FD 的用途主要有打开文件、创建 socket 连接、创建 handlerThread 等。

比如像下面这个例子中,就是 anon_inode:[eventpoll]和 anon_inode:[eventfd]的数量异常的多,说明进程中很可能是启动了大量的 handlerThread,再结合回传上来的线程信息就能快速定位到问题代码的具体位置。
FD 溢出案例:
总结
Probe 目前能够有效定位线上 Java 堆内存不足、FD 泄漏以及线程溢出的 OOM 问题。骑手 Android 端使用 Probe 组件解决了很多线上的 OOM 问题,将线上 OOM Crash 率从最高峰的 2‰降低到了现在的 0.02‰左右。我们后续也会继续完善 Probe 组件,例如 HPROF 文件裁剪方案对 7.X 系统的兼容以及 Native 层的内存问题定位。
作者介绍:
逢搏,美团配送 App 团队研发工程师。
毅然,美团配送 App 团队高级技术专家。
永刚,美团平台监控团队研发工程师。
本文转载自公众号美团技术团队(ID:meituantech)。
原文链接:
https://mp.weixin.qq.com/s/tO1yxFs2qNQlQ2bJ8vGzQA

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 1 条评论