

在 Pinterest,我们每天都要进行数千个实验。我们主要依靠日常实验指标来评估实验效果。日常实验管道运行一次可能会花费 10 多个小时,有时还会超时,因此想要验证实验设置、触发的正确性以及预期的实验性能时就没那么方便了。当代码中存在一些错误时这个问题尤为突出。有时可能要花几天时间才能发现错误,这对用户体验和重要指标造成了更大的损害。我们在 Pinterest 开发了一个近实时实验平台,以提供更具时效性的实验指标,从而帮助我们尽快发现这些问题。
可能出现的问题有:
实验导致 impression 的统计数据显著下降,因此需要尽快关闭实验。
与对照组相比,实验导致搜索的执行次数显著增加。
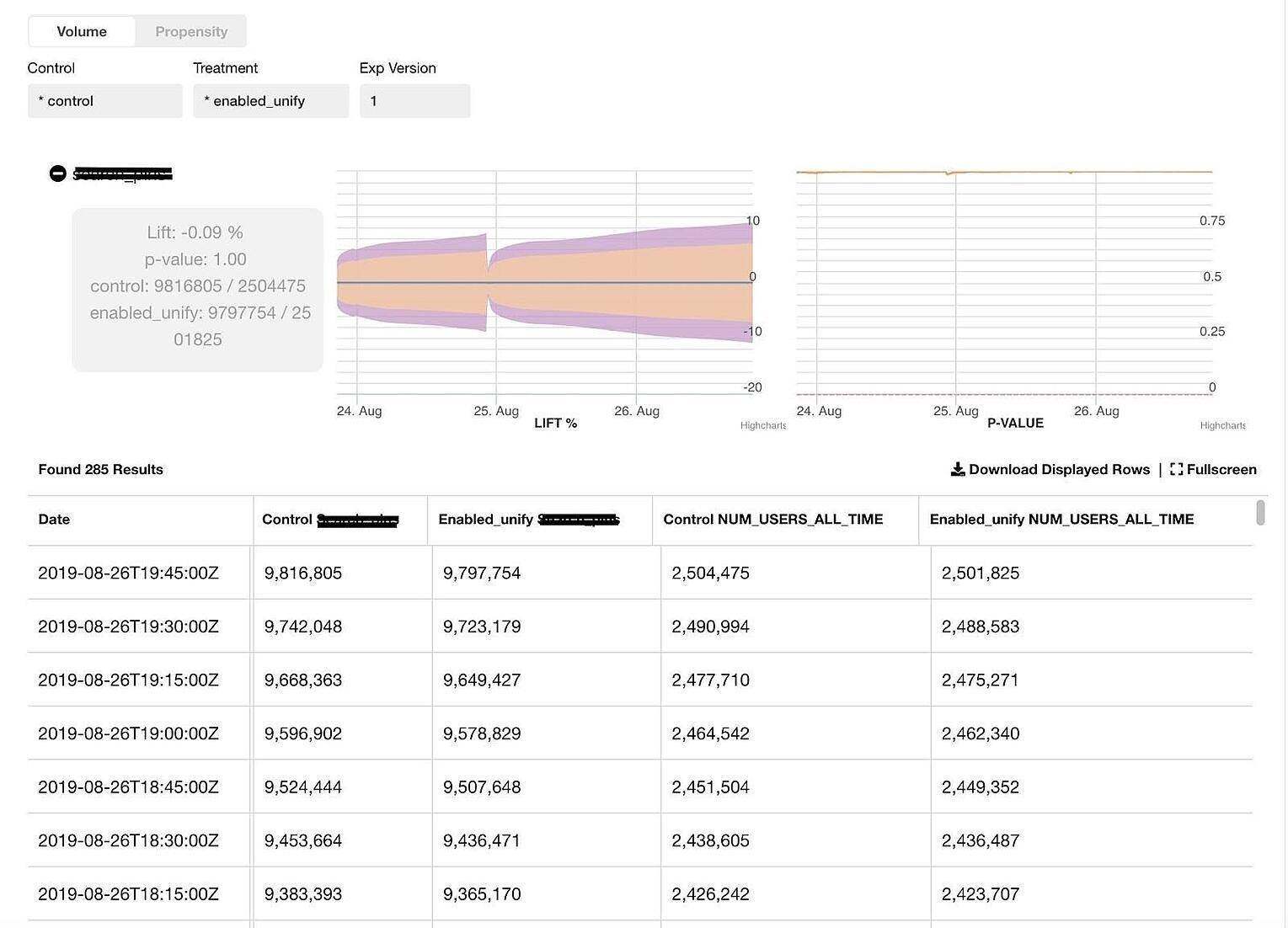
图 1-带有置信区间的实时实验指标
上图的面板显示了所选事件的实验组和对照组的流量(也就是动作数)和倾向(也就是 unique user 的数量)。自实验开始以来,这些计数已经累计了 3 天时间。如果在 3 天后发生了 re-ramp(分配给实验组和对照组的用户数量增加),则计数会归零 0 并重新开始累计 3 天时间。
为了确保实验组与对照组之间的对比在统计上是有效的,我们做了一些统计检验。由于指标是实时交付的,因此每次按顺序收到新记录时,我们都必须进行这些检验。这需要与传统的固定视野检验不一样的方法,否则会带来较高的假正率。我们考虑过几种顺序测试方法,包括赌徒破产、贝叶斯A/B检验和Alpha消耗函数方法。为了保证数值稳定性,我们从 t 检验+ Boferroni 校正(将我们的案例作为多次检验进行处理)开始,并为我们的初始实现预先确定了检验次数。
高阶设计
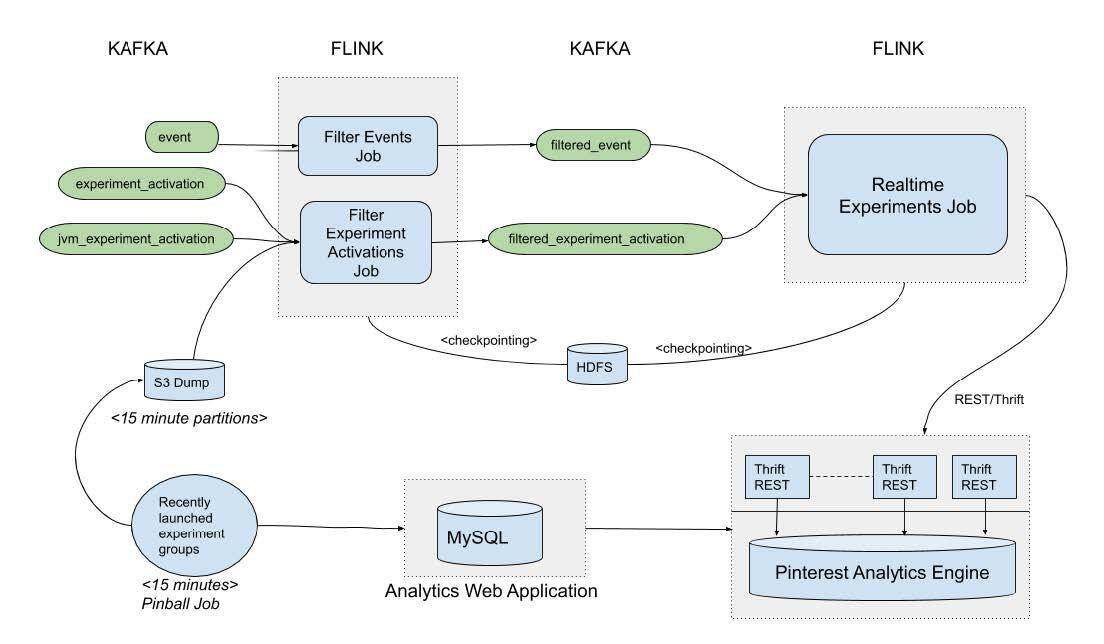
图 2-实时实验管道的高阶设计
实时实验管道包括下列主要组件:
最近 ramp 的实验组作业→每 5 分钟将一个 CSV 文件发布到一个 S3 位置。这个 CSV 是过去 3 天中所分配用户有所增加的实验组的快照。通过查询托管实验元数据的内部 Analytics(分析)应用程序的 MySQL 数据库,就能获得这一信息。
筛选事件作业→我们分析了 Pinterest 上的数百种用户动作。这一作业仅保留最关 key 的业务事件,这些事件已插入“filtered_events”Kafka 主题中。这些事件被剥离掉了不需要的字段,因此 filtered_events 主题相当轻巧。该作业运行在 Flink processing 时间内,并且通过 Flink 的增量检查点,每隔 5 秒将其进度保存到 HDFS 中。
过滤实验 Activation 作业→每当一个用户被触发进入一个实验时,都会创建一个 Activation(激活)记录。触发规则取决于实验逻辑,一名用户可以被触发进入一个实验数百次。我们只需要最近 3 天启动,或组分配增加的实验的 Activation 记录即可。
为了过滤 Activation 记录,此作业使用 Flink 的广播状态模式。每 10 秒检查一次“最近 ramp 的实验组”作业所发布的 CSV 的更改情况,并将其发布到一个 KeyedBroadcastProcessFunction 的所有分区上,该函数也消费 Activation。
KeyedBroadcastProcessFunction 将广播的 CSV 与 Activation 流结合在一起,就可以过滤掉那些最近 3 天内未 ramp-up 实验的 Activation 记录。此外,“group-ramp-up-time”已添加到 Activation 记录中,并插入“filtered_experiment_activations”kafka 主题中。
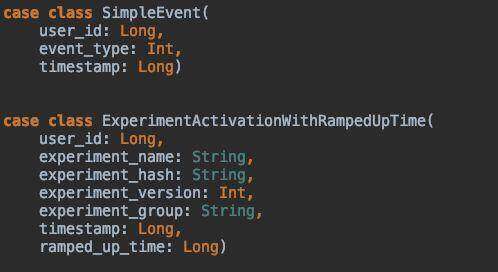
图 3-Scala 对象被插入中间层 Kafka 主题中
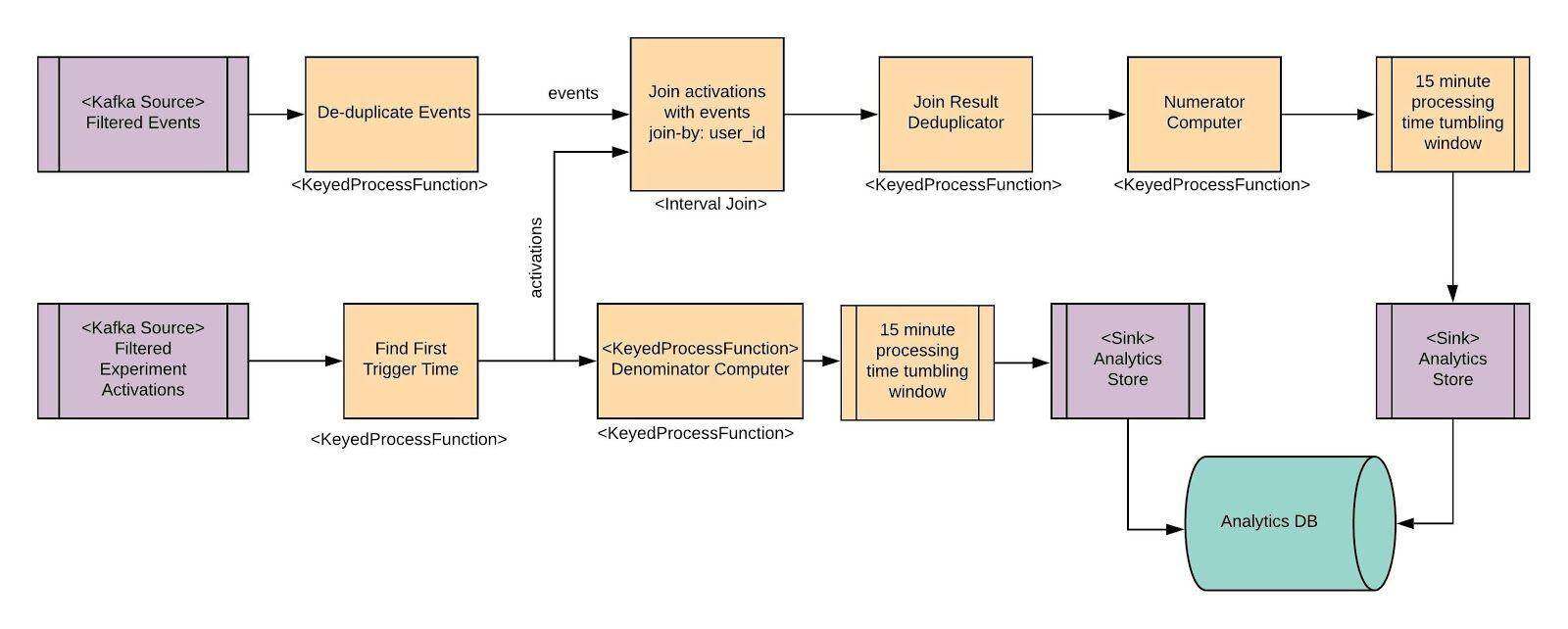
图 4-实时实验累积作业图
上面是实时累积(Aggregation)Flink 作业的高阶概览。这里简单提及了一些 operator,后文中还将详细介绍另一些 operator。Source operator 从 Kafka 读取数据,而 sink 使用一个 REST 接口写入我们的内部 Analytics Store 上。
删除重复事件→这里用一个 KeyedProcessFunction 实现,由(event.user_id,event.event_type,event.timestamp)作为 key。这里的思想是,如果来自同一用户的相同事件类型的事件具有相同的时间戳,则它们是重复事件。第一个这样的事件被发送到下游,但也会缓存进状态持续 5 分钟时间。任何后续事件都将被丢弃。5 分钟后,一个计时器会启动并清除状态。这里的假定是所有重复事件之间的间隔都在 5 分钟之内。
查找首次触发时间→这里是一个 Flink KeyedProcessFunction,由(experiment_hash,experiment_group,user_id)作为 key。这里的假设是,为一个用户收到的第一个实验 Activation 记录也是具有第一个触发时间的 Activation。一个实验 ramp-up 以后,收到的第一个 Activation 将发送至下游,并保存为状态并持续 3 天时间(我们累积了实验组 ramp-up 以来为期 3 天的计数)。经过 3 天的 ramp 时间后,一个计时器将清除状态。
15 分钟的 processing 时间 tumbling 窗口→事件进入并向下游发送结果时,Numerator Computer 和 Denominator computer 都将累积计数。这意味着数百万条记录,但是我们不需要如此频繁地将结果发送到 Analytics Store 上。我们可以在 processing 时间内运行一个持续 15 分钟的 Flink tumbling 窗口,这样效率更高。对于 Numerator Computer 来说,这个窗口由(“experiment_hash”,“experiment_group”,“event_type”,“timestamp”)作为 key。当窗口在 15 分钟后触发时,将获取带有 max_users 的记录并将其发送到下游的 Analytics Store sink。
连接事件和 Activation
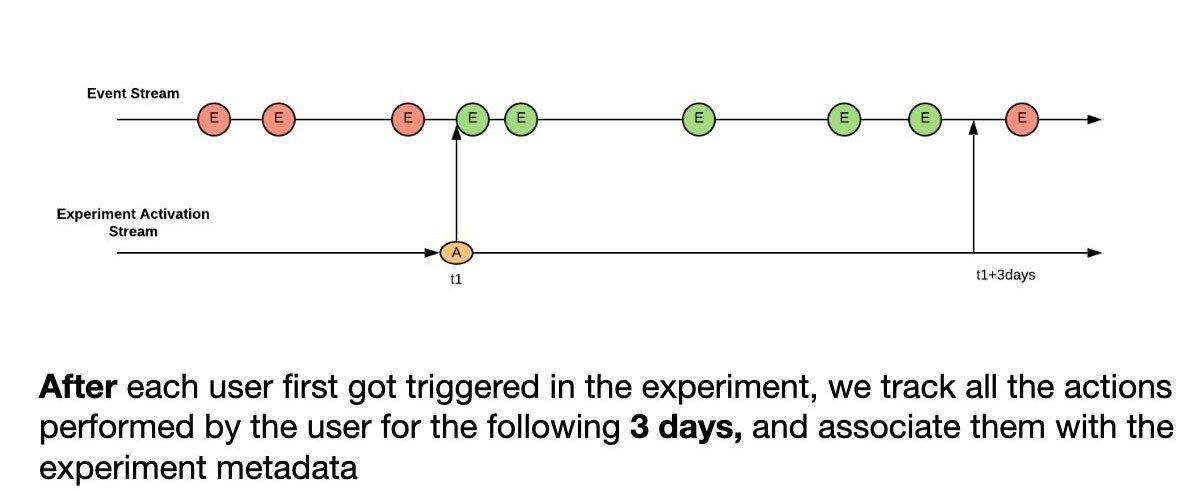
图 5-通过用户 ID 连接 Activation 流与事件流
我们使用 Flink 的 IntervalJoin operator 实现流到流的连接。IntervalJoin 会在接下来的 3 天内缓冲每位用户的单个 Activation 记录,并且所有匹配事件都将与 Activation 记录中的其他实验元数据一起发送到下游。
这种方法的局限性:
对我们的需求而言,IntervalJoin operator 有点不够灵活,因为它的间隔是固定的而不是动态的。比如说,用户可以在实验启动 2 天后加入进来,但 IntervalJoin 还是会为这名用户运行 3 天时间,也就是说我们停止累积数据后还会运行 2 天时间。如果 3 天后组很快 re-ramp,则一位用户也可以有 2 个这样的连接。这种情况会在下游处理。
事件和 Activation 不同步:如果 Activation 作业失败并且 Activation 流被延迟,则可能会丢失一些数据,因为没有匹配 Activation 的事件还会继续流动。这将导致计数不足。
我们研究了 Flink 的 IntervalJoin 源代码。它会在“左侧缓冲区”中缓冲 Activation 3 天时间,但事件将被立即删除。目前似乎无法通过配置更改此行为。我们正在研究使用 Flink 的协同处理函数来实现这个 Activation 到事件的连接,该函数是用于流到流连接的更通用的函数。我们可以将事件缓冲 X 分钟,这样即使 Activation 流延迟了 X 分钟,管道也可以处理延迟而不会出现计数不足。这将帮助我们避免同一用户的两次连接,并能形成更加动态的管道,其可以立即感知到实验组的 re-ramp,并支持更多动态行为,例如在组 re-ramp 时自动扩展累积的覆盖范围 。
Join Results Deduplicator
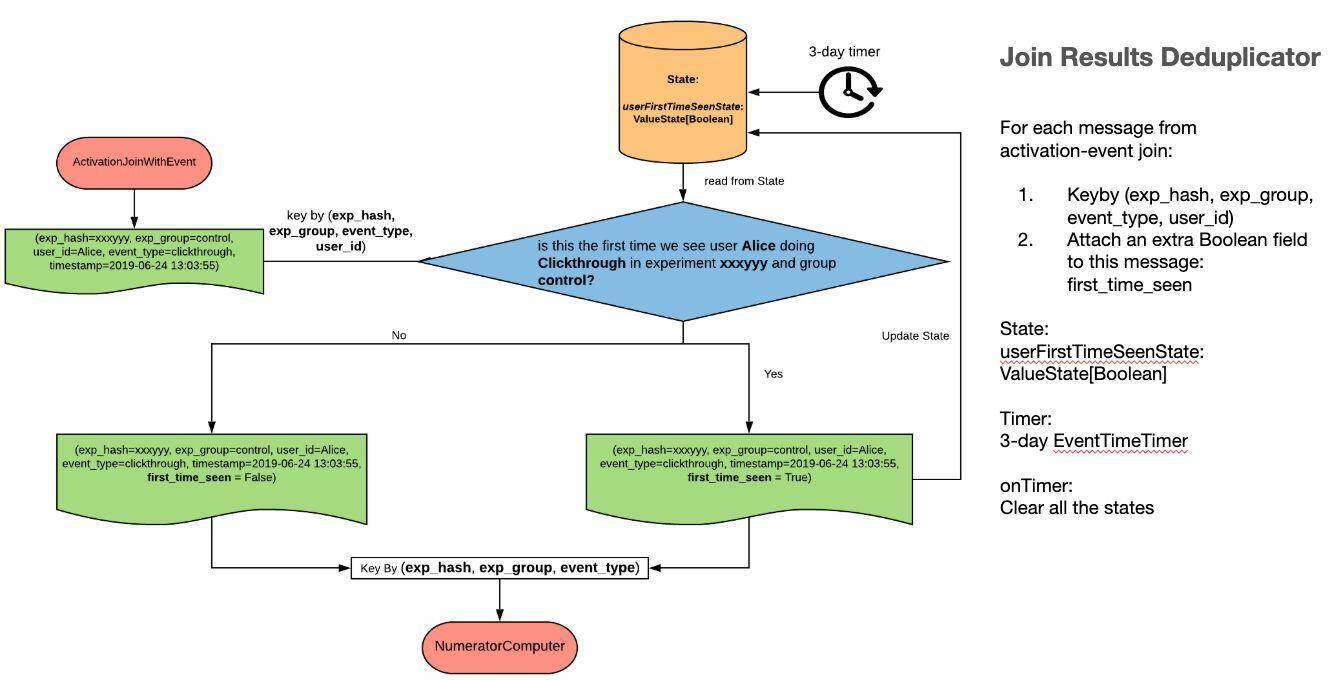
图 6-Join Results Deduplicator
Join Results Deduplicator 是一个 Flink KeyedProcessFunction,它由 experiment_hash,experiment_group,event_type,user_id 作为 key。这个 operator 的主要目的是在向下游发送记录时插入“user_first_time_seen”标志——下游 Numerator Computer 使用这个标志来计算倾向编号(# unique users),而无需使用设置的数据结构。
这个 operator 将状态存储到 last-ramp-time+ 3 天,之后状态将被清除。
Numerator Computer
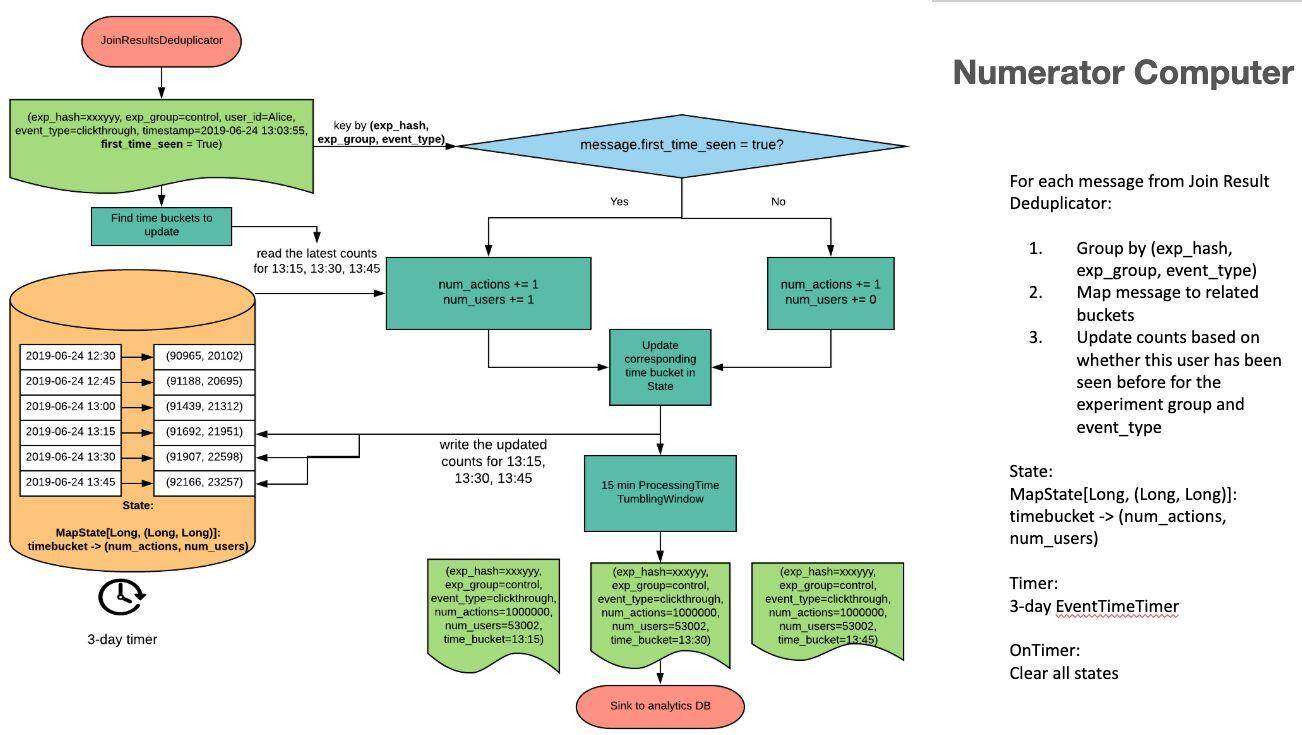
图 7-Numerator Computer
Numerator Computer 是一个 KeyedProcessFunction,由 experiment_hash,experiment_group,event_type 作为 key。它会在最后 2 小时内一直滚动 15 分钟的存储桶(bucket),每当有新记录进入时都会更新这些桶。对于流量来说,每个动作都很重要;因此对于每个事件,动作计数都会增加。对于倾向数字(unique user)——它取决于"first_time_seen”标志(仅在为 true 时递增)。
随着时间的流逝,存储桶会滚动/旋转。每次新事件进入时,存储桶数据都会向下游刷新到 15 分钟的 tumbling 窗口中。
它有一个时间为 3 天的计时器(从 ramp-up 时间→3 天),可在触发后清除所有状态,这样就能在 ramp-up3 天后重置/清除计数,完成归零。
垃圾消息与处理
为了使我们的流管道具有容错能力,Flink 的增量检查点和 RocksDB 状态后端被用来保存应用程序检查点。我们面临的一项有趣挑战是检查点失败。问题似乎在于检查点流程需要花费很长时间,并且最终会超时。我们还注意到,在发生检查点故障时通常也会有很高的背压。
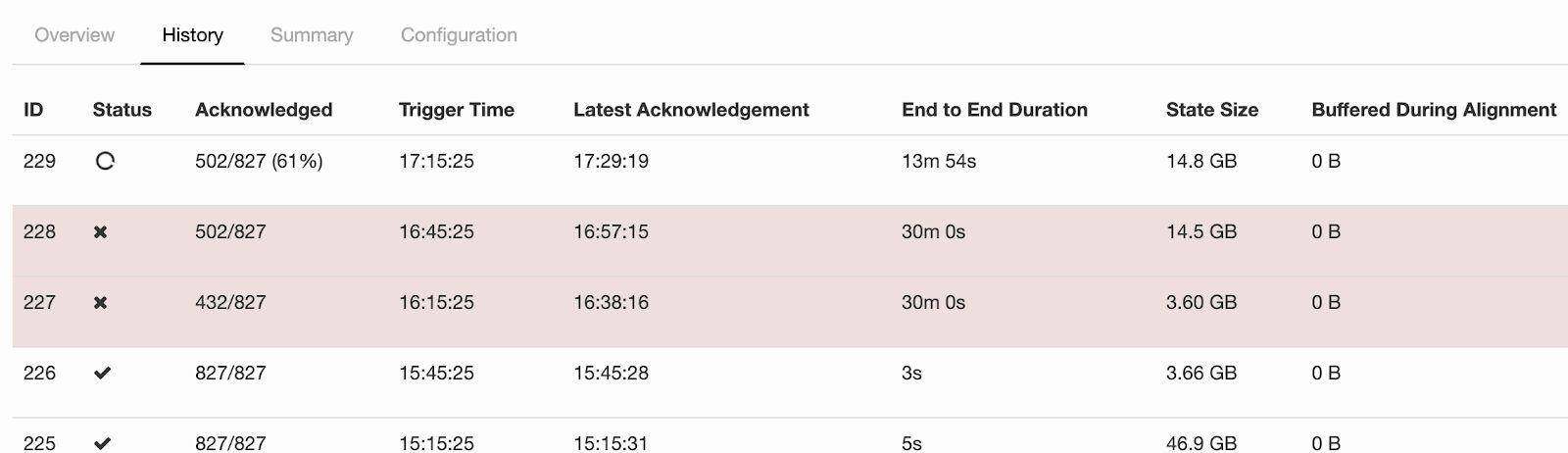
图 8-Flink UI 中显示的检查点故障
在仔细检查了检查点故障的内部机制之后,我们发现超时是由于某些子任务未将确认发送给检查点协调器而导致的,整个检查点流程都卡住了,如下所示。
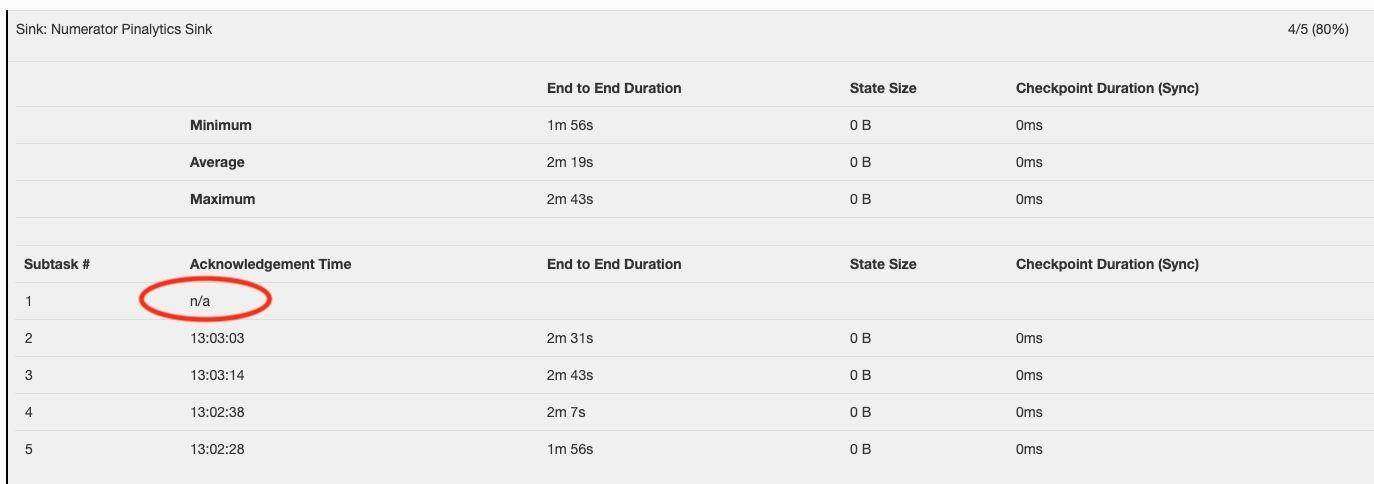
图 9-子任务未发送确认
然后我们针对导致失败的根本原因应用了一些调试步骤:
检查作业管理日志
检查在检查点期间卡住的子任务的任务管理器日志
使用 Jstack 详细查看子任务
原来子任务运行很正常,只是抽不出空来处理消息。结果,这个特定的子任务具有很高的背压,从而阻止了 barrier 通过。没有 barrier 的收据,检查点流程将无法进行。
在进一步检查所有子任务的 Flink 指标之后,我们发现其中一个子任务产生的消息数量比其对等任务多 100 倍。由于消息是通过 user_id 在子任务之间分区的,这表明有些用户产生的消息比其他用户多得多,这就意味着那是垃圾消息。临时查询我们的 spam_adjusted 数据集后也确认了这一结果。

图 10-不同子任务的消息数
为了缓解该问题,我们在“过滤器事件作业”中应用了一个上限规则:对于一个小时内的用户,如果我们看到的消息多于 X 条,则仅发送前 X 条消息。应用上限规则后,检查点就不再出现故障了。
数据稳健性和验证
数据准确性对于实验指标的计算而言更为重要。为了确保我们的实时实验流程按预期运行,并始终提供准确的指标,我们启动了一个单独的每日工作流,其执行与流作业相同的计算,但使用的是临时方式。如果流作业结果违反以下任一条件,则会提醒开发人员:
在同一累积期间(本例中为 3 天),计数不应减少
如果在第一个累积期之后进行了 re-ramp,则计数应从 0 开始再累积 3 天
流结果与验证流结果之间的差异不应超过某个阈值(在我们的例子中为 2%)。
通过查询实验元数据,我们分别在 3 种情况下对实验进行了验证:
单次 ramp-up 实验
在初始累积期间内进行多次 ramp-up 实验
在初始累积期后进行多次 ramp-up 实验
这一流程如下所示:
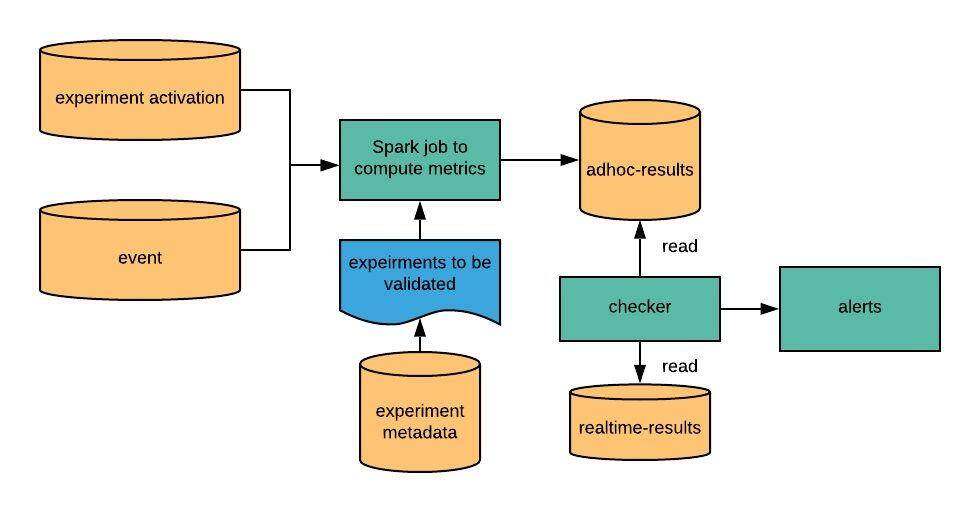
图 11-验证流程
规模
在这一部分中,我们提供了一些基本统计信息,展示实时实验管道的规模:
输入主题流量(一天的平均值):
100G 检查点
200~300 个实验
8 个 master,50 个 worker,每个都是 ec2 c5d.9xlarge
计算的并行度为 256
未来计划
支持更多指标,例如 PWT(pinner 等待时间),这样如果实验导致 Pinner 的延迟异常增加,则可以尽快停止。
可能更新管道以使用 Flink 的协同处理功能代替“间隔连接”,使管道更具动态性和弹性,以应对事件流和 Activation 流之间的不同步问题。
分区:研究分区可以支持的分区类型,因为分区会导致状态增加。
通过电子邮件或 Slack 支持实时警报。
致谢
实时实验分析是 Pinterest 在生产环境中的第一个基于 Flink 的应用程序。非常感谢我们的大数据平台团队(特别感谢 Steven Bairos-Novak、Jooseong Kim 和 Ang Zhang)构建了 Flink 平台并将其作为服务提供出来。同时还要感谢 Analytics Platform 团队(Bo Sun)出色的可视化效果,Logging Platform 团队提供实时数据提取,以及 Data Science 团队(Brian Karfunkel)提供的统计咨询!
原文链接:
https://www.ververica.com/blog/real-time-experiment-analytics-at-pinterest-using-apache-flink

InfoQ主编

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论