

一、概述
在大数据平台建设初期,安全也许并不是被重点关注的一环。大数据平台的定位主要是服务数据开发人员,提高数据开发效率,提供便捷的开发流程,有效支持数仓建设。大数据平台的用户都是公司内部人员。数据本身的安全性已经由公司层面的网络及物理机房的隔离来得到保证。那么数据平台建设过程中,需要考虑哪些安全性方面的问题?
环境隔离,数据开发人员应当只需关注自己相关业务域的数据,也应该只能访问这一部分数据。从数据的角度,减小了被接触面,降低了被误操作的可能。从数据开发人员的角度,只能访问自己业务域的数据,在数据开发的过程中,可以减少干扰项,提高效率。
数据脱敏,有些敏感数据即使是公司内部的数据开发人员,也需要限制其直接访问的权限。
明晰权责,各业务域数据都有相应的负责人,对自己的数据负责。同时,所有数据访问与操作都有审计信息记录,对数据的转化与流动有据可查。
最后,大数据平台的目标是赋能数据开发人员,提高数据开发效率,而安全管理必然会降低数据平台的便利性。如何平衡安全和便利性的关系,尤为重要。
有赞大数据平台安全建设是在大数据平台本身的发展以及数仓元数据建设的过程中不断演进的。概括起来可以分为三个阶段。
二、基于 ranger +组件 plugin 的权限控制
在大数据平台刚开始构建的时候,我们重点关注的是基础服务、任务调度、监控预警等方面。数据安全这一块,只有有限的几个数仓同学有数据读写权限,而各业务组的同学都只有读权限。随着公司的发展,业务量的提升,按业务进行数据隔离的需求开始变的强烈。
当时,我们对各方需求进行了梳理,主要为以下几点。将数据按业务域划分,数据开发人员只能访问相关业务域的数据,粒度为表或字段级别。业务域可以和公司组织架构相对应,相关部门默认有相应权限。可以方便的进行权限申请与审批。调研对比各种实现方案之后,我们选择了 ranger +组件 plugin 的权限管理方案。其中 ranger+ hiveServer2 plugin 的架构图如下( ranger + spark thrift server plugin 类似):
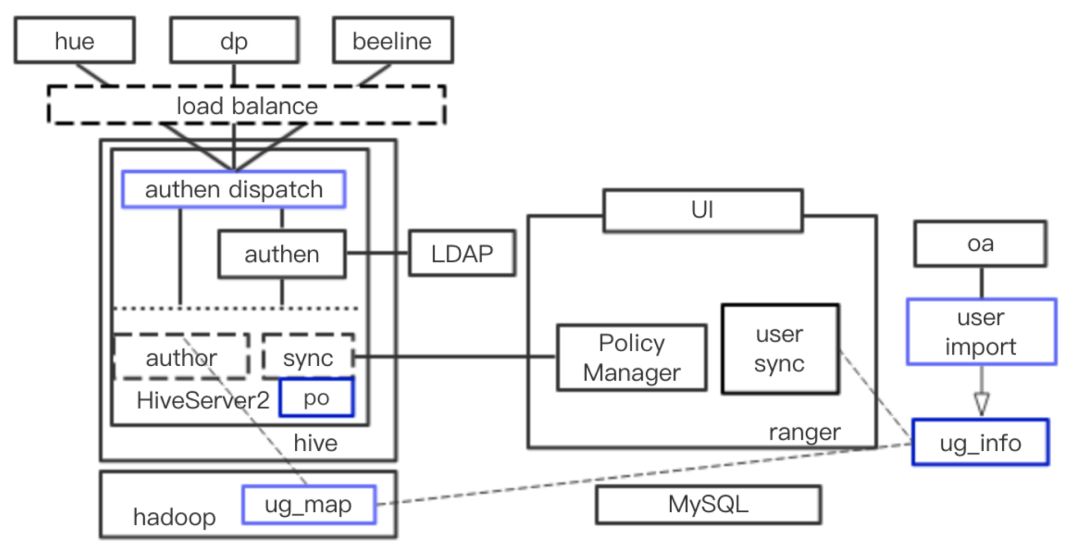
所有数据访问在 Hive Server 中进行鉴权,通过公司的 LDAP 服务进行用户认证。当时的入口有 hue、数据平台和 beeline,只有 beeline 的用户需要进行 LDAP 认证,而 hue 和数据平台的用户已经认证过了,只要传 proxy user 过来进行鉴权即可。为了支持业务域与公司组织架构相对应,需要从公司的 OA 系统将部门组织信息分别导入 ranger 以及 hadoop 进行用户组的映射。另外,扩展 hue 增加了一个权限申请与审批的模块。
这样的方案基本满足了业务数据隔离的需求。但是在用户使用过程中,还是收到了很多不满的反馈,主要原因就是阻碍了用户使用的便利性。数据开发人员可能在数据平台进行数据查询,发现没有数据访问权限之后,需要到 hue 上申请权限。权限审批人员收到申请通知之后,需要登录 ranger web UI,进行权限配置。数据管理人员需要直接在 ranger 中配置初始权限。这些都是很不方便的点。另外,ranger 支持的查询引擎有限,想要增加查询引擎(如 presto)就需要定制化开发。因此,这种 ranger + plugin 的做法,执行引擎的可扩展性并不好。由此,我们进入了安全建设的第二阶段。
三、基于 ranger 的权限管理服务
为了提高用户使用的便利性,我们需要收敛数据平台的入口,下线 hue,所有的数据访问及权限申请与审批都直接可在数据平台上完成。并且,当用户访问到某个无权限的数据时,可以直接一键申请。为了提升执行引擎可扩展的能力,我们需要将 ranger 与执行引擎解耦,执行引擎可以不用鉴权。因此,我们在元数据系统中增加了权限管理服务模块,通过 Restful 接口与 ranger 交互。架构图如下:
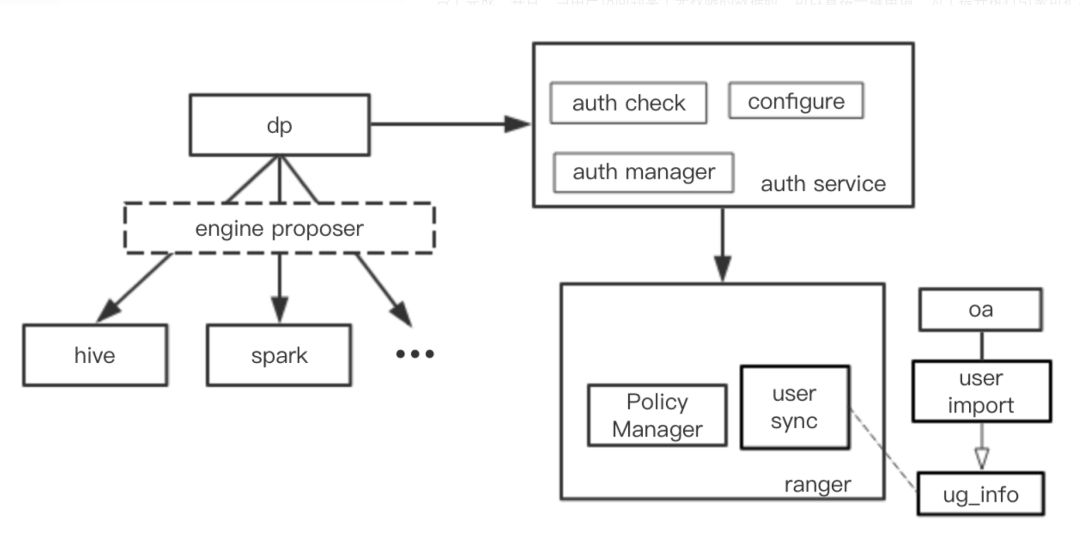
所有数据访问直接在数据平台这个入口,通过权限管理服务进行鉴权。支持权限一键申请及一键审批。还可以支持临时权限等特殊请求。数据管理人员也不用在 ranger 中配置策略,而是通过权限管理页面直接进行数据业务域配置,然后自动映射为 ranger 中的策略。另外,我们还在这一阶段建立了完整的审计体系,做到了所有数据访问与操作有据可查。
四、基于 column masking 的数据脱敏
随着公司业务的进一步增长,对敏感数据的脱敏需求变的更加强烈。我们需要将各种手机号、邮箱地址之类的敏感字段进行脱敏处理,例如手机号只显示后四位。ranger 虽然支持 column masking,但是我们在第二阶段已经将 ranger 与执行引擎进行解耦。因此,我们需要在数据平台层面,对数据进行脱敏。我们采用的方案是 SQL 重写。架构图如下:
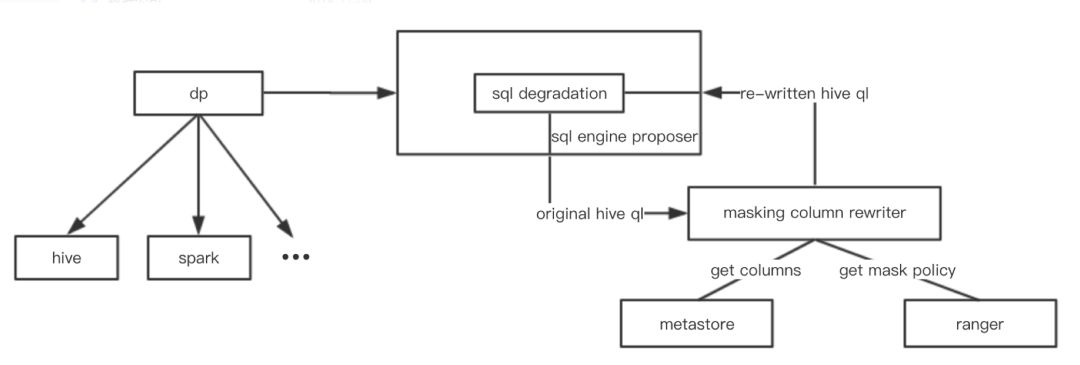
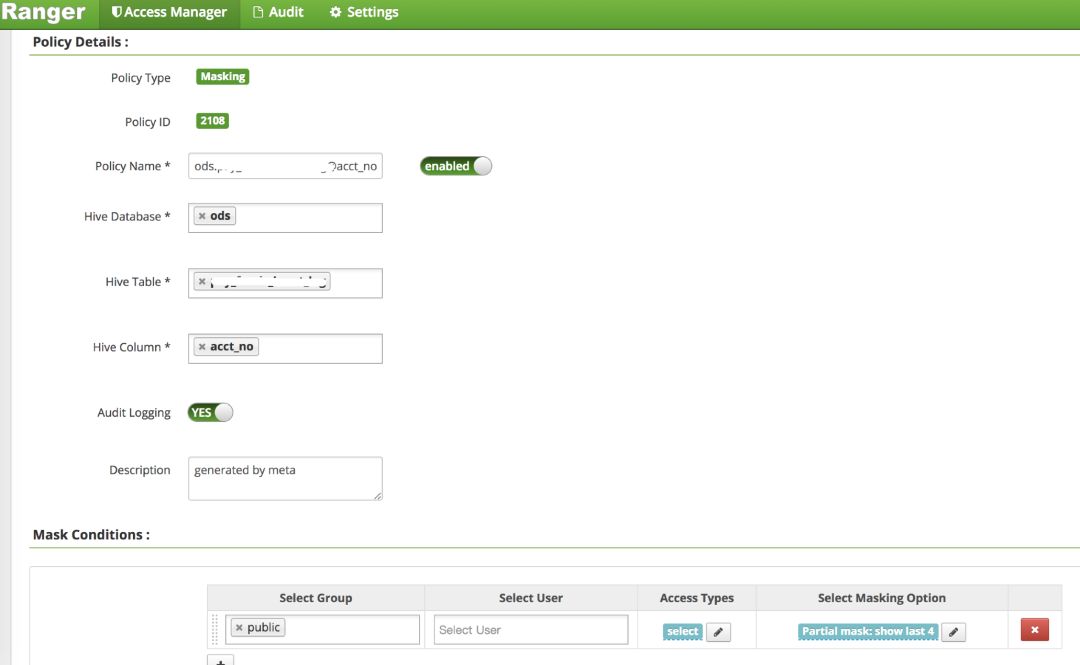
SQL Engine Proposer 是我们开发的一个智能执行引擎选择服务,可以根据查询的特征以及当前集群中的队列状态为 SQL 查询选择合适的执行引擎。数据平台向某个执行引擎提交查询之前,会先访问智能执行引擎选择服务。在选定合适的执行引擎之后,通过敏感字段重写模块改写 SQL 查询,将其中的敏感字段根据隐藏策略(如只显示后四位)进行替换。而敏感字段的隐藏策略存储在 ranger 中,数据管理人员可以在权限管理服务页面设置各种字段的敏感等级,敏感等级会自动映射为 ranger 中的隐藏策略。例如表 ods.xxx 中的列 acct_no 的敏感等级为 2,那么映射为 ranger 中的策略如下:
当某个查询语句为
经过脱敏重写,最终执行的查询语句为
我们使用 antlr4 来处理执行引擎的语法文件,实现 SQL 重写。其中,spark 和 presto 都是使用的 antlr4,所以他们的语法文件直接拿过来用即可。由于 hive 目前使用的是 antlr3 的版本,我们将 hive 的语法文件使用 antlr4 的语法重写了一遍。之所以要全部用 antlr4,是为了最大程度的重用 visitor 的逻辑。基于同样的方法,我们实现了字段血缘的追溯,从而可以进行字段的敏感等级传递。
五、未来展望
大数据平台的安全建设并不是一项孤立的工作,而是随着大数据平台支持的业务量和业务种类越来越多,与大数据平台本身的进化而一起发展的。随着有赞实时数仓的建设、机器学习平台的构建等等新业务的发展,安全建设仍有很长的路要走。
最后打个小广告,有赞大数据团队基础设施团队,主要负责有赞的数据平台 (DP), 实时计算 (Storm, Spark Streaming, Flink),离线计算 (HDFS,YARN,HIVE, SPARK SQL),在线存储(HBase),实时 OLAP(Druid) 等数个技术产品,欢迎感兴趣的小伙伴联系 qunyan@youzan.com
作者简介:大数据平台是有赞共享技术的核心团队之一,该团队主要由数据技术、数据产品、算法挖掘、广告平台四个小团队组成,目前共有 34 位优秀的工程师组成。
转载来自公众号“有赞 Coder”:https://mp.weixin.qq.com/s/4G_OvlD_5uYr0o2m-qPW-Q









评论