

背景
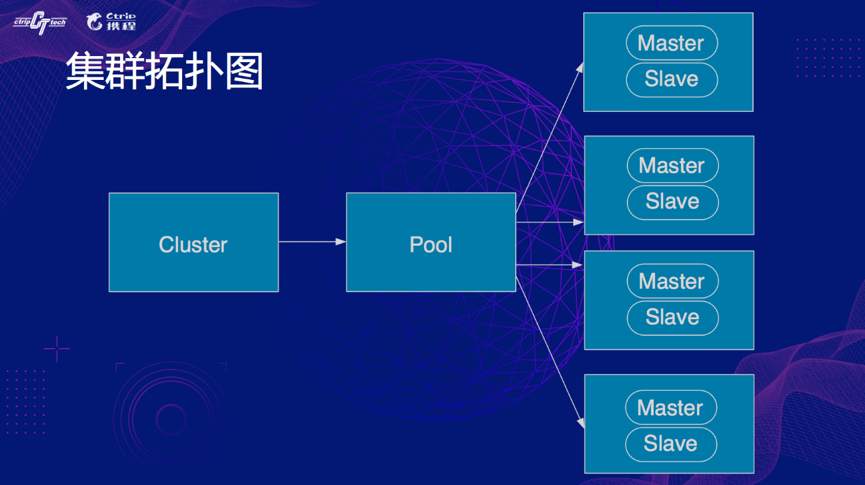
携程大部分应用是基于 CRedis 客户端通过集群来访问到实际的 Redis 的实例,集群是访问 Redis 的基本单位,多个集群对应一个 Pool,一个 Pool 对应一个 Group,每个 Group 对应一个或多个实例,Key 是通过一致性 hash 散列到每个 Group 上,集群拓扑图如截图所示。
这个图里面我们可以看到集群,Pool,Group 还有里面的实例,这是携程 Redis 一个比较常见的拓扑图,如下图:
为什么要容器化
标准化和自动化
Redis 之前是直接部署在物理机上,而 DBA 是根据物理机上设定的 Redis 的版本来选择需要部署的物理机,携程的各个版本的 Redis 非常分散而且不容易维护,如下图所示,容器天然支持标准化,另外容器基于 K8S 自动化部署的效率,根据我们估算,相比人工部署提高了 59 倍。
规模化
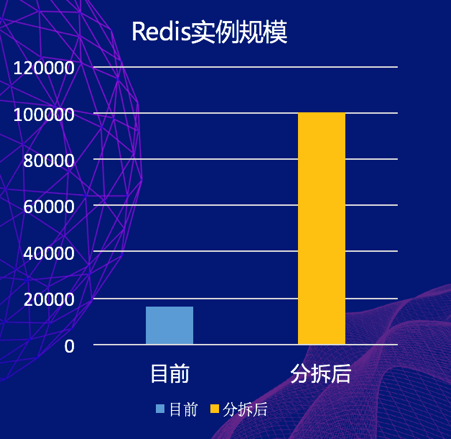
有别于社区的方案比如官方 Redis Cluster 或代理方案而言,携程的技术演进方案需要对大的实例进行分拆 (内部称为 CRedis 水平扩容),实例分拆后,单个实例的内存小了,QPS 降低,单个实例挂掉的影响小很多,可以说是利国利民的项目,但会带来一个问题,实例数急剧膨胀。容器化后我们能对分拆后的实例更好地管理和运维。
另外,分拆过程中需要大量中间状态的实例 Buffer 作为过渡,比如一对 60G 的实例分拆为 5G,中间状态的 Buffer 需要 24 个 60G 的实例,纯人工分拆异常艰难,而且容易出错,依靠容器自动调度生成实例会极大降低 DBA 分拆时的心智负担,极大提升了分拆的效率并减少出错的概率。
提高资源利用率
借助于容器化和上层的 K8S 的编排系统,我们很轻易的就可以做到资源利用率的提升,至于怎么做到的,后面细节部分会涉及。
能不能容器化
既然 Redis 容器化后好处这么多,那么 Redis 能不能容器化呢?对比测试最能说明问题。
实际上我们在容器化前做了很多测试,甚至因为测试模式的细微差别在各个部门之间还有过长时间的争论,但最终下面这几张图的数据获得了大家的一致认可,容器化才得以继续推广下去。
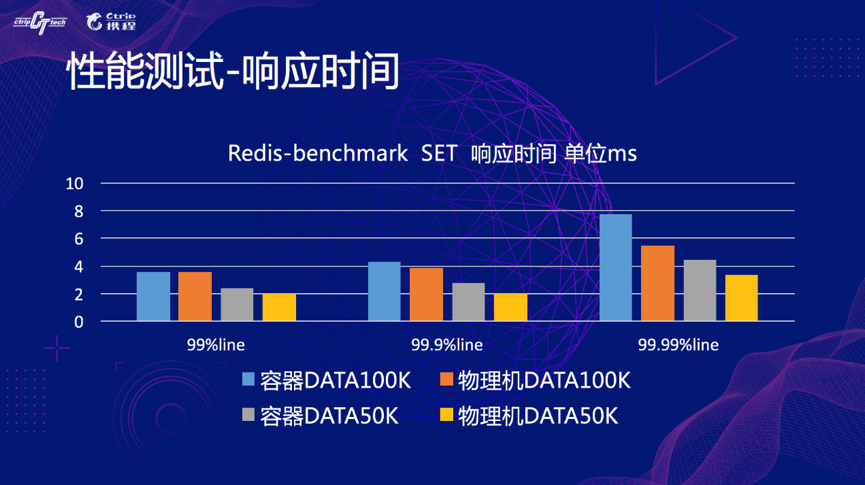
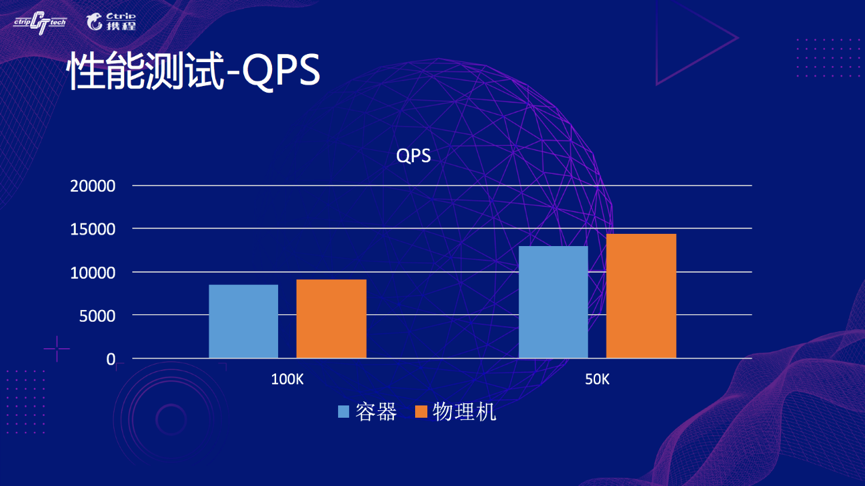
我们 A/B 对比测试都是基于相同硬件的容器和物理机,不挂 slave,图上我们可以看到,Redis 的响应相比物理机要慢一点,QPS 也能看到差距很小,这些差异主要是容器化后经过多个虚拟网卡带来的性能损失。
这第三张图就更明显了,这是我们测试对比生产实际物理机的流量对比,我们测试的流量远高于生产实际运行的单台物理机的流量。
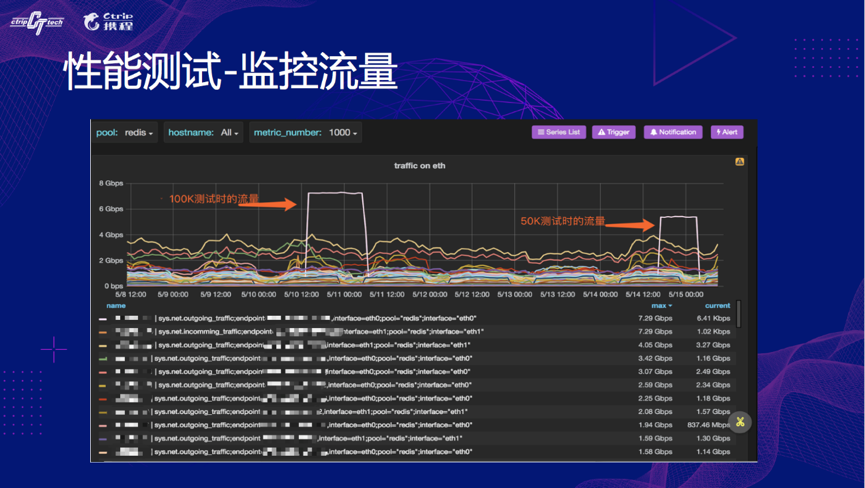
因此总结下来就是,容器与物理机的性能有细微的差别,大概 5-10%,并且携程的使用场景 Redis 完全可以容器化。
架构和细节
总体架构
以上介绍无非是容器化前的一些调研和可行性分析工作。
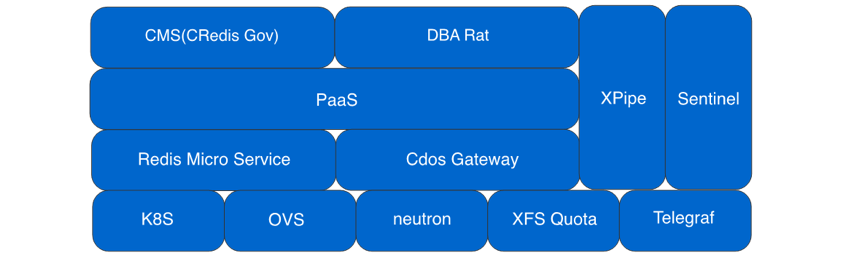
具体的架构如下图所示,首先最上层的是运维和治理工具 CRedis 和 Rat,这个在携程内部是属于框架和 DBA 两个部门,CRedis 不但提供应用访问 Redis 的客户端,本身也做 CMS 的工作,存储 Redis 实例最基本的元数据。
PaaS 层为 Credis/Rat 提供统一的 Redis Group/实例的创建删除接口,下面的 Redis 微服务提供实例申请具体的调度策略,基础设施有很多,这里其实只列举了一部分比较重要的,如网络相关的 ovs 和 neutron,与磁盘配额相关的 quota,以及监控相关的 telegraf 等。xpipe 是携程内部的跨 IDC 的 DR 方案,sentinel 就是官方的哨兵。
容器化遇到的一些问题
在我们容器化方案落地前遇到过一些具体的问题,例如:
Redis 实际上是被应用直连的,我们需要 IP 和宿主机固定,并且 master/slave 不能在一台宿主机上。
部署之前是在物理机上,通过端口来区分不同的实例,所有的监控通过端口来区分。
重启实例 Redis.conf 文件配置不能丢失,这个在容器之前甚至不算需求,但放在容器上就有点麻烦。
Master 挂了不希望 K8S 立刻把它拉起来,希望哨兵来感知到它,因为 K8S 如果在哨兵感知前拉起了它,导致哨兵还没切换 Master/Slave,Master 就活过来并且数据都丢失,这时候一同步到 Slave 上数据也全没有了,等于执行了一个清空操作,这对于业务和 DBA 来说是不能接受的。
实例几乎没有任何的内存控制,就是说实例不管写多大,都是得让 maxmemory 一直加上去,一直加到必须迁移走开始,再把实例迁移走,而不能控制 maxmemory,让应用那边直接写报错。这个是最大的问题,决定了容器化是否能进行下去。如果不控制内存,K8S 的某些功能形同虚设,但如果控制内存,与携程之前的运维习惯和流程不太相符,业务也无法接受。
以上都是我们遇到的一些主要问题,有些 K8S 的原生策略就可以很好地支持,有些则不行,需自研策略来解决。
K8S 原生策略
首先,我们的容器基于 K8S 的 Statefulset,这个几乎没有任何疑问,毕竟 Redis 是有状态的。
其次,nodeAffinity 保证了调度到指定标签的宿主机,podAntiAffinity 保证同一个 Statefulset 的 Pod 不调度到同一台宿主机上,toleations 保证可以调度到 taint 的宿主机上,而该宿主机不会被其他资源类型调度到,如 Mysql,App 等,也就是说宿主机被 Redis 独占,只能调度 Redis 的实例。
上面提到的分拆其实也是基于 nodeAffinity,podAntiAffinity 等特性,我们内部划分出一块虚拟区域叫 slaughterhouse,专门用于分拆,分拆完成再迁到常规区域。
自研策略
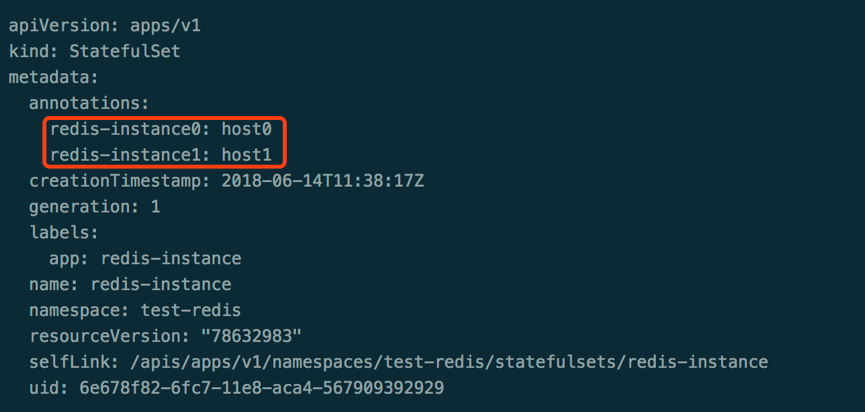
宿主机固定,这个是自研的调度 sticky-scheduler 来提供支持,如下图所示,在创建实例的时候会看 annontation 有没有对应 host,有的话直接会跳过调度固化到该宿主机上,如果没有则进入默认的调度宿主机的流程。
虽然 Redis 对磁盘需求不多,但我们还是得防止 log 或 rdb 文件过大将磁盘撑爆,自研的 chostpath 和 cemptydir 都是基于 xfs 的 quotas 很好的支持磁盘配额,并且我们将 Redis.conf 和 data 目录挂载出来,保证重启容器后配置文件不丢失,还可保证容器重启后可以读 rdb 数据。
比如我们在做风险操作升级 kubelet 时候可能会引起相关的 Pod 重启,但我们先对相关的 Redis bgsave 下,哪怕重启 pod 也会读取对应的 rdb 数据,不会导致完全没有数据的尴尬场面。
监控方面,之前 Redis 部署在物理机上,通过端口来区分不同的实例,所有的监控通过端口来区分,但容器化后每个 Pod 都有一个 IP,自然监控策略要变。
我们的方案是每个 Pod 两个容器,一个是 Redis 本身的实例,一个是监控程序 telegraf,每 60 秒采集一次数据发送到公司的统一监控平台 Hickwall,所有的 telegraf 脚本固化在物理机上,一旦修改方便统一的推送,并且对于 Redis 实例没有任何影响。
实践证明这种监控方案最为理想,比如有一次我们生产迁移集群后,DBA 需要集群的聚合页面,也就是把所有的实例聚合在一起的按集群维度查看的页面,我们修改 telegraf 的脚本将集群的信息随着实例推送过去立刻就能显示在监控页面上,非常方便。
下面两张图清晰地展示出容器的监控页面和物理机完全没有区别。
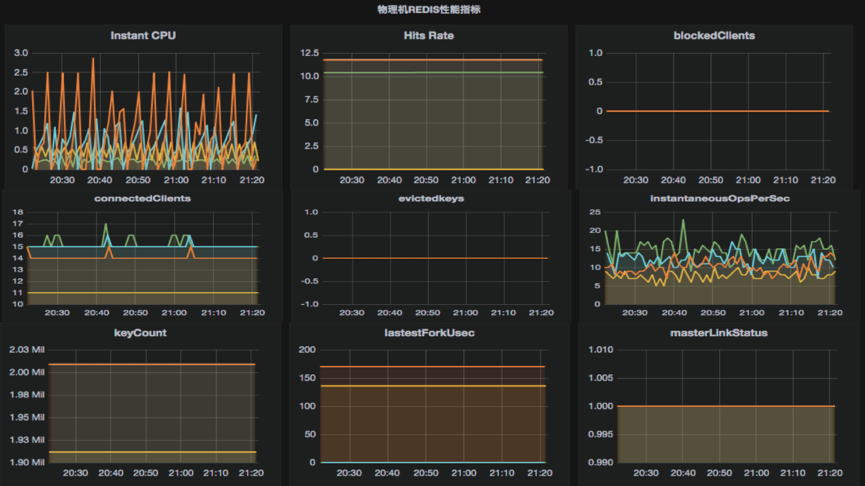
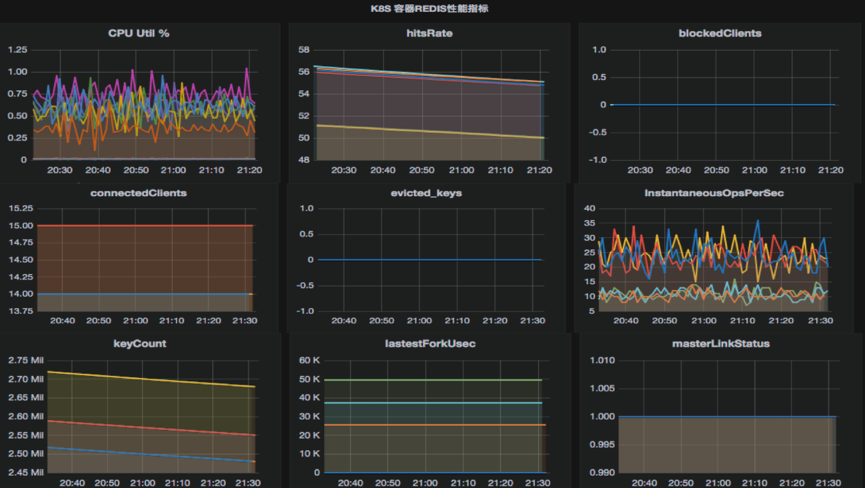
为了解决上文提到的 Master 挂了不希望 K8S 立刻把它拉起来,希望哨兵来感知到它,我们用 Supervisord 作为容器的 1 号进程。当 Redis 挂了,Supervisord 默认不会拉起它,但容器还是活的,Redis 进程却不存在了,想让 Redis 活过来很简单,删除掉 Pod 即可。K8S 会自动重新拉起它。
最后再来看看最困难的,实例几乎没有任何的内存限制。实际上在容器上我们对 CPU 和内存也几乎没有限制。
CPU 不限制主要是几个方面原因,首先,12 核的机器上 CPU quota/period =12, 按理是占满了整个机器,但压测时 CPU 居然有 throttle,这明显不符合我们的客观直觉,我们怀疑 Linux 的 cfs 是有问题的,而且很神奇的是我们设置一个很大的 quota 值后,也就是将 CPU 限额设置到 50 核,throttle 消失了。
其次 Redis 是单线程,最多能用一个 CPU,如果一个 CPU 跑一个 Redis 实例,肯定没问题,实际上我们设置两个实例分配到一个核也是完全可行的。
最后一个原因也是最主要的,Redis 在物理机上运行是没有任何 CPU 隔离的。基于上面三个原因,我们让 CPU 超分。
关于内存超分,下面这张图清晰地说明了问题所在,对于只有一个 100G 的宿主机,只要放上 2 个实例,每个实例 50G,它的内存就超了。内存超分好处很多,比如物理机迁移过来很平滑,用户也很能接受,运维工具几乎不需要修改就能套上去,但是,超分大法好,但 OOM 了怎么办?

方案是不让 OOM 发生,只要策略合适,这显然是可以做到的,在说到杜绝 OOM 的策略之前,先看下普通的调度策略。
我们在调度时对集群重要性进行了划分,主要分为以下几种:
基础集群,比如账号相关的,登陆相关的,虽然订单无关但比订单相关都重要。
接入 XPIPE,订单相关的。
没有接入 XPIPE,订单相关的。
订单无关但相对重要的。
既订单无关的又不重要的。
这样划分后,我们就可以很方便地让集群根据重要性按机器的高中低配来调度,并且让集群是否在多 Region 上打散。为了方便理解,这里一个 Region 可以简单等同于一个 K8S 集群。
单个 Region 如下图,一个 Statefulset 两个 Pod 分别是 Master/Slave,每个 Pod 里面有两个容器,一个是 Redis 本身,一个是监控程序 telegraf,部署在两个 Host 上。
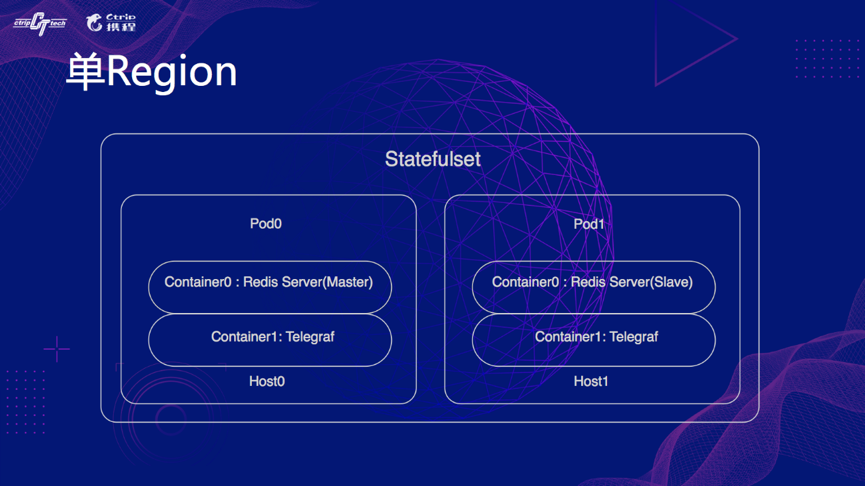
多个 Region 如下图,这时候,其实是有 2 个 Statefulset,这种方案可以扩散到更多 Region,这样哪怕是某个 K8S 集群挂了,重要的集群仍然有对外提供服务的能力。
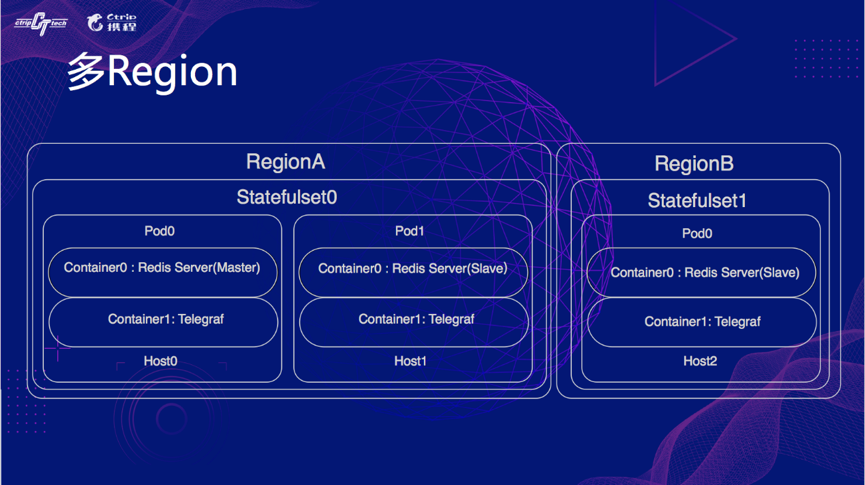
介绍完一般的调度策略后,接着说上文提到的杜绝 OOM 的策略。首先,调度之前,对于不同配置的宿主机限定不通的 Pod 数量,此外设定 10%的占位策略,如下图所示,并且设定 Pod 的 request == maxmemory。

调度中,我们会基于宿主机实际的可用内存进行打分,在 K8S 默认调度后,优选时我们会将实际剩余内存的打分赋值一个非常高的权重,当然基于其他策略的调度比如说 CPU,网络流量之类我们也在研究,但目前最优先考虑的是实际剩余的物理内存。
以上这些策略可以杜绝大部分 OOM,但还不够,因为 Redis 后续还是会自然增长的,所以在运维过程中,我们会有 Job 定时轮询宿主机,看可用内存和上面的 Pod 分配是否合理,对于不合理的 Pod,Job 会自动触发迁移任务,将一些 Pod 迁移到内存更空的机器上去,以达到宿主机整体可用内存方差最小。
还有一些其他的调度后的策略,比如动态调整 Redis 实例的 HZ,我们曾遇到一个情况就是,在物理机上跑着一个实例大小都是 10 多个 G,但跑到容器上后 2 天增加了 20 多个 G。
我们排查后发现 Redis 的 HZ 值设置的过小,导致大量过期的 Key 没时间来得及清理,清理完成后发现,usedmemory 是下来了,但 rss 还保持稳定,也就是碎片率很高,所以我们会动态打开自动碎片整理,整理一次完成后再关闭它,因为同时打开,消耗的 CPU 过高,目前情况下还不是很适合。
最后还有个保底的,基于宿主机内存告警,一般设置为 80%即可,这种保底策略到目前为止也就触发过一次。
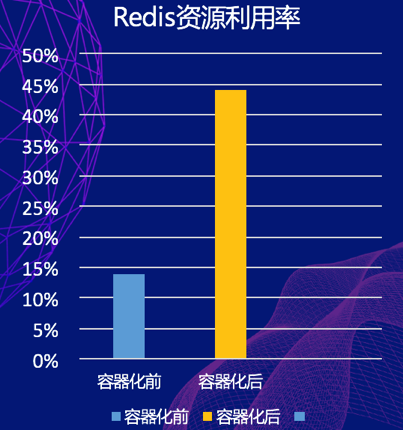
小结下,Redis 跑在容器上,尤其在生产上大规模部署,需要多个组件共同协作才能达成。其次,携程的现状决定了我们必须超分,那么超分后如何不 OOM 是关键,我们从调度过程前中后容器层面和 Redis 层面分别都有相应的策略,调度上的闭环不但保证了 Redis 在容器上的平稳运行,而且资源利用率(如下图所示)也做到了非常大的提升。
一些坑
最后再分享一下实践过程中的一些坑,这些坑其实本身不是 Redis 的问题,但都是在 Redis 容器化过程中发现的。
System Load 有规模毛刺
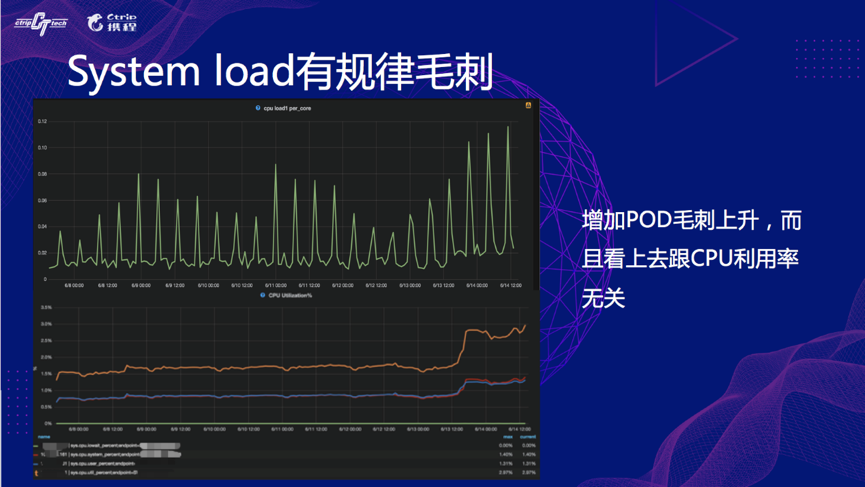
首先是 System Load 有规模毛刺,每 7 小时一次,我们可以看到监控上,增加 Pod 后毛刺上升,但看上去跟 CPU 利用率没什么关系。
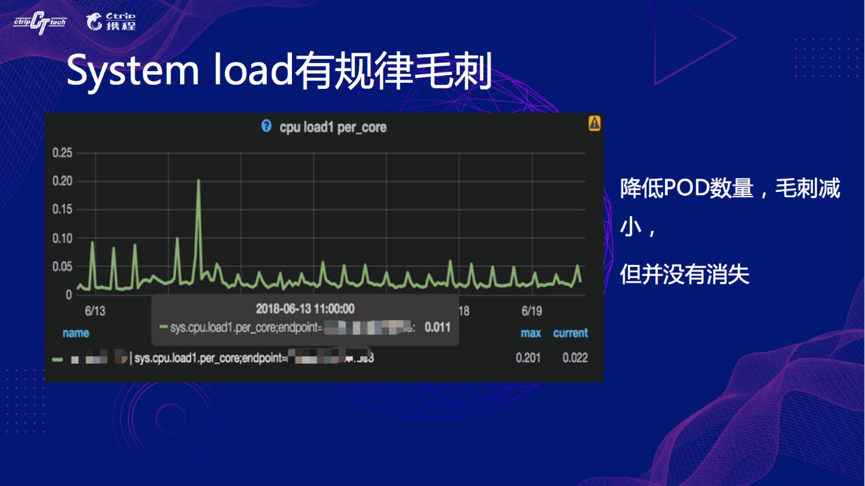
降低 Pod 数量,毛刺减小,但还存在,所以跟 Pod 数量正相关,
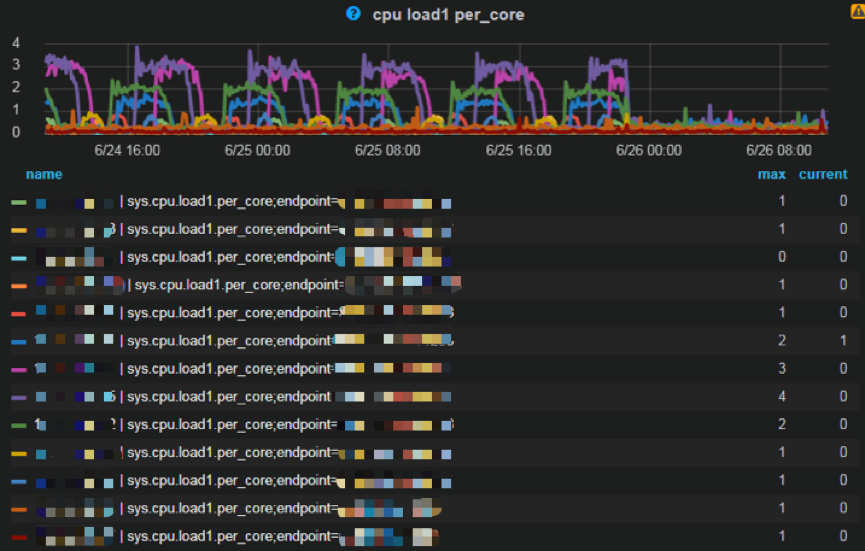
后来我们发现是 telegraf 监控脚本的问题。所有瞬间会产生很多进程的 Job 都会导致 System Load 升高。
对于 Redis 宿主机 load 异常情况,主要是因为监控程序每 1min 生成很多进程采集一次数据, System Load 采集则是每 5.001s 采集一次,当 telegraf 的第一次采集点命中 System Load 采集点后,第二次则需要 5s*(5/0.001)=25000s,导致 Load 有规律每 7 小时飙高。
我们修改 telegraf 中的 collection_jitter 值,用来设置一个随机的抖动来控制 telegraf 采集前的休眠时间,确保瞬间不会爆发上百个进程,修改后,毛刺消失了,如下图所示:
Slowlog 的异常
其次是 Slowlog 的异常,该问题根因在于 4.9-4.13 的内核的一个 bug,会导致 skylake 服务器的时钟变慢,而该时钟不断地被 NTP 修正,所以导致 Slowlog 的两次打点时间过长,升级内核到 4.14 即解决该问题。
Xfs bugs
还有一个是 Xfs 的 bugs,Xfs 我们发现的有两个比较严重的问题,第一个是字节对齐的问题,这个比较隐蔽,简答地说就是内核态的 Xfs header 跟用户态的 Xfs header 里面定义不同,导致内核在写 Xfs 的时候会越界。下图中就是很明显的症状,我们升级 4.14 的内核对内存对齐打了 patch 解决了该问题。

Xfs 第二个问题是 xfsaild 进入 D 状态缓慢导致宿主机大量 D 状态进程和僵尸进程,最终导致宿主机僵死,典型的现象如下图。
这个现象在 4.10 内核发现很多次,并且猜测与 khugepaged 有关系,我们升级到 4.14 并 Backport 4.15-4.19 的 Xfs bugfix,压测问题还是存在,但比 4.10 要难以复现,在 free 内存超过 3G 后不会再复现。目前升级到 4.14.67 Backport 的新内核实际运行中还没出现这个问题。

作者简介
李剑,携程 CIS 资深软件工程师。加入携程之前主要从事音视频流媒体的开发,目前主要负责 Redis 和 Mysql 容器化和服务化的研发。

暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论