

要点总结
分布式消息系统支持流和队列两种语义。这两种语义最适合使用的场景有所不同。
Pulsar 的独特之处在于它同时支持流和队列使用场景。
Pulsar 采用多层架构,可以轻松扩展 topic 的数量和大小,比其他消息系统的操作更便捷。
Pulsar 实现可扩展性、可靠性和其他特性之间的良好平衡。这有助于替换 Iterable 采用的 RabbitMQ 消息系统,并最终替换其他消息系统(如 Kafka 和 Amazon SQS)。
Iterable 公司每天代表客户发送大量营销消息,包括电子邮件、通知、短信、应用程序消息等,并且每天处理更多的用户数据更新、事件、自定义工作流状态。Iterable 日常处理的很多消息都可能触发系统中的其他操作,从而导致系统越来越复杂,产品易用性越来越低。随着客户数量不断增加,降低系统复杂性迫在眉睫。
Iterable 可以在架构的某些部分改用分布式消息系统,主要用于存储需要 consumer 处理的消息,追踪 consumer 处理消息时的状态,从而降低系统复杂性,保证 consumer 专注于处理消息。
Iterable 使用工作队列执行客户指定的营销工作流、webhooks 和其他类型的工作安排或进展。其他组件(如提取用户和事件)使用流模型处理有序消息流。分布式消息系统通常支持流和队列两种语义,而最适合使用这两种语义的场景则有所不同。
流和队列
在流消息系统中,producer 追加数据到“仅追加”消息流中。在每个消息流中,必须按特定顺序处理消息,consumer 在消息流中标记消息的位置。我们可以采取某种策略(如对用户 ID 进行哈希处理)对消息进行分区,使分区成为单独的数据流,增加并行度。由于每个流中的数据不可变,且只保存偏移 entry,因此处理时不会遗漏消息。流适用于重视消息顺序(如提取数据)的场景。Kafka 和 Amazon Kinesis 都使用流语义处理消息。
在队列消息系统中,一个队列可能有多个 producer 和 consumer。producer 向队列发送消息,consumer 从队列中接收消息。接收消息后,consumer 开始处理消息,并在处理完每条消息后向队列消息系统发送 ack。由于多个 consumer 共用一个队列,消息顺序并不重要,因此基于队列的系统很容易对 consumer 进行扩展。消息队列系统适用于不需要按特定顺序执行任务的队列,例如,发送同一封邮件给多个收件人。RabbitMQ 和 Amazon SQS 都是基于队列的消息系统。
通常情况下,消息队列系统可以简化消息级别错误的处理。例如,在发生错误后,RabbitMQ 可以轻松地将消息发送到特定队列,由该队列保留特定时间后,再将消息发送回到原始队列进行重试。RabbitMQ 还可以反馈 ack 失败,这样可以在消息发送失败后重新发送。大多数消息队列在收到 ack 后不会将消息存储在 backlog 中,因此系统无法找到需要新发送的消息,这就增加了调试和灾备的难度。
基于流的系统(如 Kafka)也可以用于队列使用场景,但使用起来有些麻烦。Kafka 支持多种特性,很多客户决定在队列中使用 Kafka。但是由于 Kafka 不能严格按照流指定的顺序处理消息,为开发人员增加很多额外工作。如果 consumer 无法消费消息,导致消息处理速度降低或需要重新消费消息,那么同一流上其他消息的处理速率也会受到影响。常见的解决方案是将消息发布到另一个 topic 进行重试,但这会增加应用程序的状态管理,提高复杂性。
为什么 Iterable 需要新消息系统
Iterable 一直使用 RabbitMQ 的特性,处理大量内部消息。我们自定义存活时间(Time-to-Live,TTL),用于指定重试次数,并实现消息处理中的显示延迟。例如,我们可能会延迟发送营销邮件(在收件人最可能查看邮件时,再发送营销邮件)。我们还需要查阅 ack 失败,来确定重新发送失败的队列消息。
Iterable 的架构简图如下:
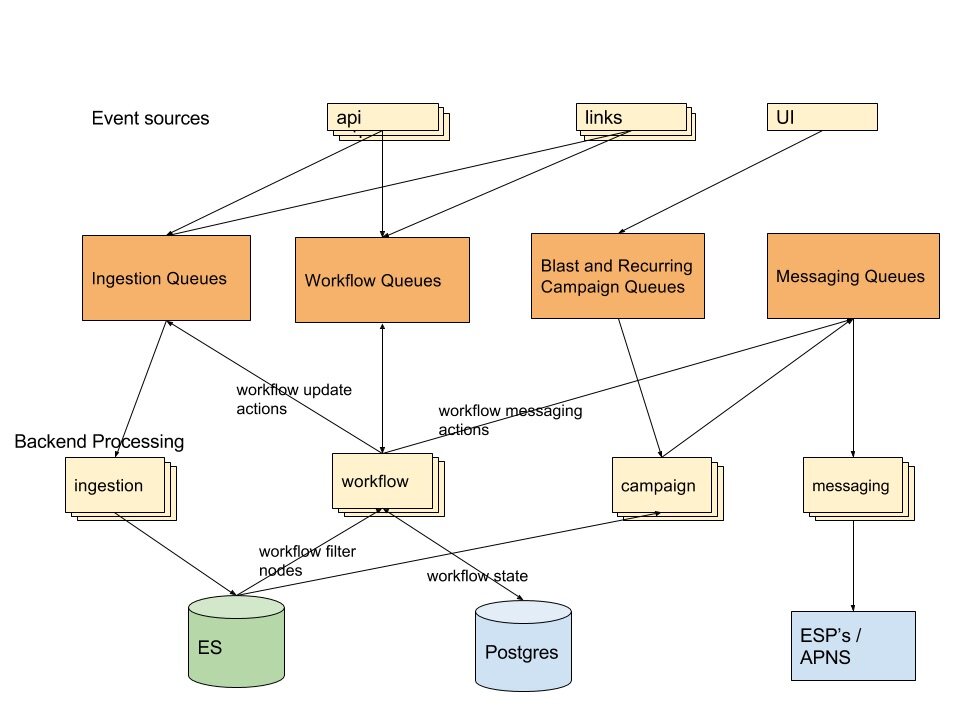
在评估 Pulsar 时,我们使用 Kafka 提取消息,使用 RabbitMQ 处理上文提到的所有队列。Kafka 具备相应的性能和排序保证,非常适合提取消息,但由于缺少必要的队列语义,不适合其他使用场景。RabbitMQ 的特性(如延迟)对我们至关重要,这就增加了我们寻找替代方案的难度。
在扩展系统时,RabbitMQ 出现以下问题:
在高负载场景中,RabbitMQ 经常出现流量控制问题。在内存或其他资源受到限制时,broker 落后于 producer,流控制机制降低 producer 的速度。但这会影响 producer,导致服务延迟和其他工作区域的请求失败。例如,我们发现当大量消息的生存时间同时终止时,流控制发生的频率增加。在这种情况下,RabbitMQ 尝试将所有到期的消息一次传输到目标队列,但这会急剧增加 RabbitMQ 实例的内存容量,从而触发 producer 的流控制机制,阻止 producer 发布消息。
RabbitMQ 的 broker 在收到 ack 后不会存储消息,增加了调试的难度。也就是说,broker 端无法设置消息的保留时间。
RabbitMQ 的复制组件不足以应对我们的使用场景,导致难以复制消息,RabbitMQ 因而成为消息状态的单点故障。
RabbitMQ 难以处理大量队列。我们有很多需要专用队列的使用场景,经常需要一次性处理 1 万多个队列。在处理这个数量级的队列时,RabbitMQ 的管理页面和 API 经常出现问题。
评估 Apache Pulsar
整体来看,Apache Pulsar 支持我们需要的全部特性。尽管在 Pulsar 和 Kafka 的对比中,Pulsar 云服务提供商和用户都在强调 Pulsar 的流处理特性,但我们发现 Pulsar 非常适合处理队列。Pulsar 的共享订阅模式支持将 topic 用作队列,因而可以向同一 topic 内的 consumer 提供多个虚拟队列。Pulsar 也原生支持延迟发送消息。在我们刚开始测试 Pulsar 的时候,支持这些特性的系统并不多见。
除了上述特性外,Pulsar 的分层架构还简化了扩展 topic 数量和大小的操作。
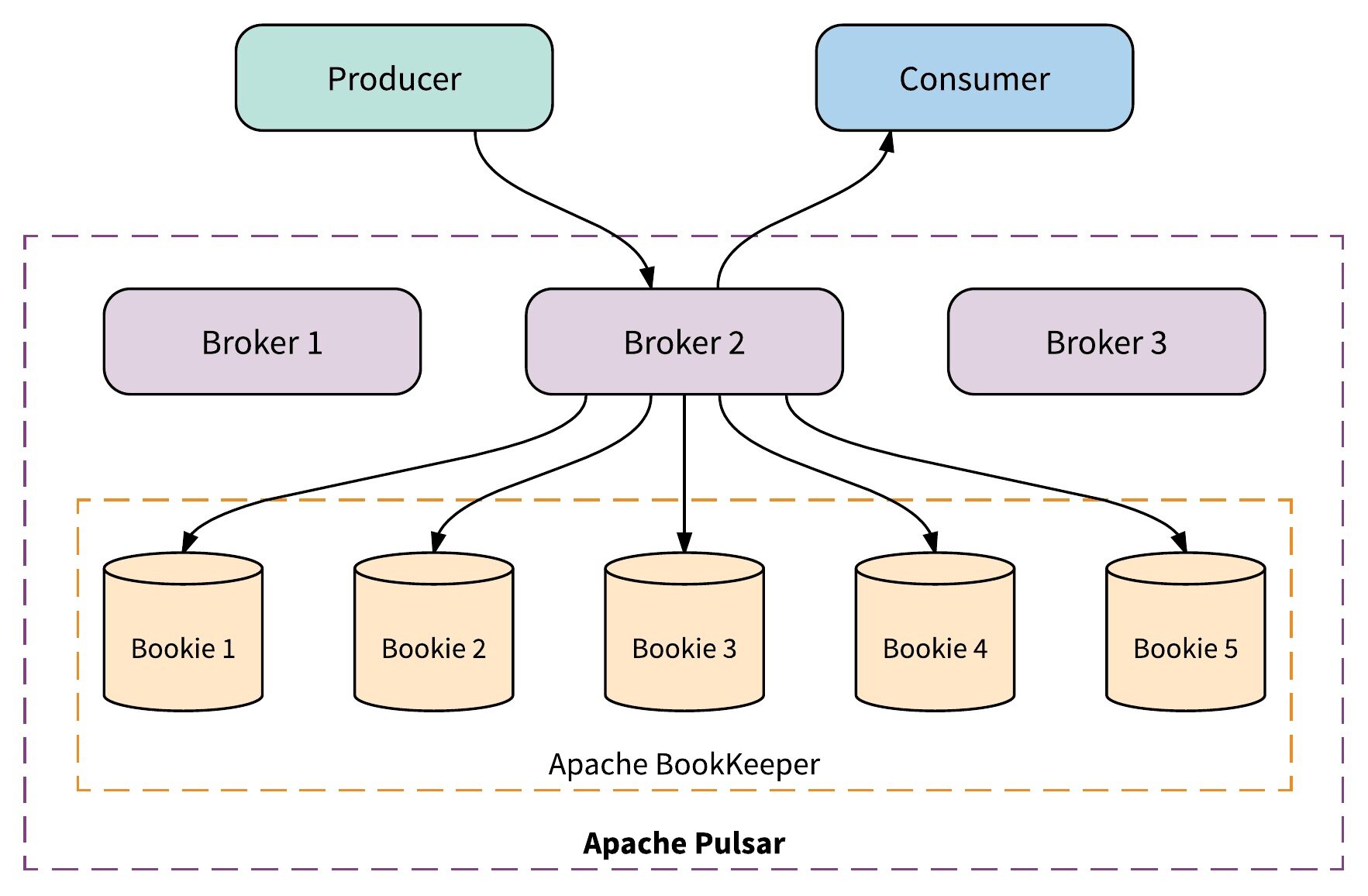
Pulsar 的顶层为 broker,负责从 producer 接收消息并发送消息到 consumer,但不存储消息。一个 broker 负责一个 topic 分区,但 broker 不存储 topic 状态,topic 的 owner broker 可以随意互换。因此用户可以添加 broker,轻松扩大吞吐量,并可以在添加后立即使用新 broker。Pulsar 也因而可以处理 broker 故障。
Pulsar 的底层为 BookKeeper,负责将 topic 数据分片存储在整个集群中。需要增加存储时,可以添加 BookKeeper 节点(bookie)到集群中,然后用这些新节点来存储新的分片。Broker 与 bookie 相互协调,更新 topic 的状态。Pulsar 使用 BookKeeper 存储大量 topic,这对 Iterable 当前的使用场景而言非常重要。
在评估了几个消息系统后,我们决定使用 Pulsar,因为 Pulsar 的可扩展性、可靠性和特性之间达到了完美的平衡,足以取代 Kafka、Amazon SQS 等消息系统。
初试 Pulsar:发送消息
Iterable 平台的主要任务之一就是代表客户定时发送营销电子邮件。因此,我们为不同的客户分别创建队列,将这些消息发送到相应的队列中,再检查并发送这些消息。Pulsar 提供的队列让我们最终决定放弃 RabbitMQ。
将营销邮件作为对 Pulsar 的第一项测试有两个原因。一是我们使用 RabbitMQ 主要用于发送消息;二是发送消息是我们使用 RabbitMQ 处理的较为复杂的使用场景。对 Iterable 来说,这一测试场景的风险并不低。但在对 Pulsar 进行全面测试后,我们发现 Pulsar 更适合为 Iterable 处理队列。
Iterable 平台主要处理以下三种常见的营销消息:
同时发送营销消息给所有收件人。假设客户希望发送通知邮件给最近一个月的活跃用户,我们查询 ElasticSearch 获取用户列表,然后设置定时发送消息,再发送这些消息到相应的 Pulsar topic。
为每个收件人指定发送时间。发送时间可能是固定的(如收件人所在时区的早上 9 点),也可能根据我们的发送时间优化算法确定。但无论是哪种情况,我们都需要在指定时间发送队列消息,即延迟处理消息。
用户触发的消息发送。用户使用自定义流程或发起交易(如在线购物)时,触发消息发送。
在上述场景中,同一时间发送的消息数量可能会相差很大,因此我们需要消息系统可以根据实际情况扩缩 consumer 的数量。
迁移到 Apache Pulsar
虽然在负载测试中,Pulsar 表现良好,但是我们不确定 Pulsar 是否能够承受实际生产环境的高负载。这也是我们特别关心的问题,因为我们想要利用 Pulsar 的一些新特性(如Nack、延时发送消息)。
为了检测 Pulsar 的性能,我们部署了并行管道,同时向 RabbitMQ 和 Pulsar 发送消息,并配置不实际处理消息的 consumer 进行 ack。另外,我们还模拟了延迟消费,以便了解 Pulsar 在特定生产环境中的表现。我们对测试 topic 和生产 topic 同时使用 consumer 级别的特性标记,因此可以逐一迁移 consumer 进行测试,最终用于生产环境。
在测试期间,我们发现了 Pulsar 的一些错误。例如一个与延迟消息相关的竞态条件问题,但在 Pulsar 开发人员的帮助下,这些问题都得以定位和解决。这是我们发现的最严重的问题,它会导致 consumer 出现假死,消息积压。
我们还发现 Pulsar producer 默认启用批处理。例如,Pulsar 积压 metric 返回的是批数量而不是消息数量,增加为消息积压设置报警阈值的难度。后来,我们在 Nack 和批处理之间的交互中发现了一个更严重的错误,Pulsar 团队也及时修复了这个错误。我们最终决定不使用批处理。在 Pulsar 中,禁用 producer 批处理操作简单,Pulsar 性能也满足了我们的需求。Pulsar 在新的版本中可能会合并上文提到的错误修复。
消息延迟下发和 Nack 在当时属于 Pulsar 新特性,我们觉得在使用中可能会出现一些问题,所以我们决定在初试阶段只发布消息到测试 topic,并在几个月内逐步迁移到 Pulsar。如果出现问题,我们可以迅速定位并及时解决问题,不影响客户的使用。市场营销业务的整体迁移历时大约六个月,这期间 Pulsar 实现了预期表现,我们感到十分满意。
迁移全部完成后,我们发现增加 consumer 后,业务规模得到拓展,但运营成本降低了一半。迁移到 Pulsar 前,我们的业务成本较高,可能是因为我们在使用 RabbitMQ 时,为了提高性能,超额配置了实例。到目前为止,我们的 Pulsar 集群已经运行了六个多月,没有出现任何问题。
实施和工具
在后端,Iterable 主要使用 Scala,因此我们需要使用支持 Pulsar 的 Scala 工具。我们一直在使用 pulsar4s 库,也对新特性做了一些贡献,例如延迟发送消息。我们还贡献了一个基于 Akka Streams 的连接器,作为 source 接收消息,还支持 ack。
例如,我们可以这样消费命名空间中的所有 topic。
使用正则表达式为 consumer 添加订阅,这样 consumer 不必了解特定的 topic 划分策略,可以自动订阅新创建的 topic。由于 Pulsar 支持大量 topic,可以在发布消息时自动创建新 topic,因此可以轻松为新消息类型或单独的消息创建新 topic。Pulsar 帮助用户可以更轻松地限制不同 consumer 和消息类型的速率。
结语
Pulsar 是一个正在快速发展的开源项目,因此我们需要随时关注 Pulsar 的动态,深入了解 Pulsar 的各个方面。Pulsar 的文档还不太完善,我们经常需要联系社区,寻求帮助。社区的小伙伴们十分热情,我们也乐于参与到 Pulsar 的开发中,为 Pulsar 的新特性添砖加瓦。
Pulsar 采用分层架构,不仅具有高可扩展、高可用、低延迟等特性,还同时支持流和队列,因而可以代替 Iterable 架构中正在使用的多个分布式消息系统。Pulsar 支持我们的 Kafka、RabbitMQ 和 SQS 用例。迁移到 Pulsar 后,我们可以专心使用一个统一的架构,熟悉 Pulsar 的各项操作和工具即可。
我们在 2019 年初开始接触 Pulsar。到目前为止,Pulsar 已经取得了巨大的进展,尤其是入门文档和相关培训。Pulsar 也新增了许多工具,例如,Pulsar Manager 用于管理集群。一些公司提供托管和管理 Pulsar 的服务,便于初创公司和小型团队上手 Pulsar。
总而言之,Iterable 迁移到 Pulsar 的过程非常成功,期间也遇到了一些挑战。Iterable 的使用场景目前还不多见。我们原以为会出现一些问题,但测试解决了大多数问题,将对客户的影响降到最低。我们对 Pulsar 的表现充满信心,打算将 Pulsar 同时用于 Iterable 平台其他的新旧组件中。
原文链接:
https://www.infoq.com/articles/pulsar-customer-engagement-platform/

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 2 条评论