

在上一期我们 webpack 系列中,我们介绍了针对普通文件的 resolve 流程 和 loader 的 resolve 主流程。本期我们就来介绍 loader 的基本配置以及匹配规则。如有疑问或想要交流,欢迎在文末留言。
本篇来分析下 webpack loader 详细的分析部分,由于涉及内容比较多,所以总共分成三篇文章来分析:
loader 的基本配置以及匹配规则
loader 的解析执行详解
loader 的实践
1.loader 的配置
webpack 对于一个 module 所使用的 loader 对开发者提供了 2 种使用方式:
webpack config 配置形式
形如:
inline 内联形式
2 种不同的配置形式,在 webpack 内部有着不同的解析方式。此外,不同的配置方式也决定了最终在实际加载 module 过程中不同 loader 之间相互的执行顺序等。
2.loader 的匹配
在讲 loader 的匹配过程之前,首先从整体上了解下 loader 在整个 webpack 的 workflow 过程中出现的时机。
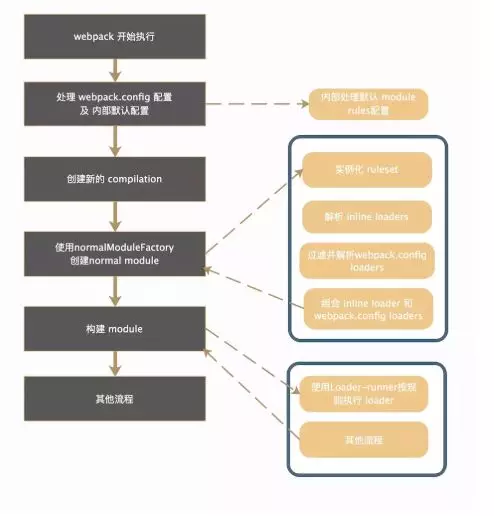
在一个 module 构建过程中,首先根据 module 的依赖类型(例如 NormalModuleFactory)调用对应的构造函数来创建对应的模块。在创建模块的过程中(new NormalModuleFactory()),会根据开发者的 webpack.config 当中的 rules 以及 webpack 内置的 rules 规则实例化 RuleSet 匹配实例,这个 RuleSet 实例在 loader 的匹配过滤过程中非常的关键,具体的源码解析可参见 Webpack Loader Ruleset 匹配规则解析。实例化 RuleSet 后,还会注册 2 个钩子函数:
当 NormalModuleFactory 实例化完成后,并在 compilation 内部调用这个实例的 create 方法开始真实开始创建这个 normalModule。首先调用 hooks.factory 获取对应的钩子函数,接下来就调用 resolver 钩子(hooks.resolver)进入到了 resolve 的阶段,在真正开始 resolve loader 之前,首先就是需要匹配过滤找到构建这个 module 所需要使用的所有的 loaders。首先进行的是对于 inline loaders 的处理:
首先是根据模块的路径规则,例如模块的路径是以这些符号开头的 ! / -! / !! 来判断这个模块是否只是使用 inline loader,或者剔除掉 preLoader, postLoader 等规则:
! 忽略 webpack.config 配置当中符合规则的 normalLoader
-! 忽略 webpack.config 配置当中符合规则的 preLoader/normalLoader
!! 忽略 webpack.config 配置当中符合规则的 postLoader/preLoader/normalLoader
这几个匹配规则主要适用于在 webpack.config 已经配置了对应模块使用的 loader,但是针对一些特殊的 module,你可能需要单独的定制化的 loader 去处理,而不是走常规的配置,因此可以使用这些规则来进行处理。
接下来将所有的 inline loader 转化为数组的形式,例如:
最终 inline loader 统一格式输出为:
对于 inline loader 的处理便是直接对其进行 resolve,获取对应 loader 的相关信息:
简单总结下匹配的流程就是:
首先处理 inlineLoaders,对其进行解析,获取对应的 loader 模块的信息,接下来利用 ruleset 实例上的匹配过滤方法对 webpack.config 中配置的相关 loaders 进行匹配过滤,获取构建这个 module 所需要的配置的的 loaders,并进行解析,这个过程完成后,便进行所有 loaders 的拼装工作,并传入创建 module 的回调中。
本文转载自公众号滴滴技术(ID:didi_tech)。
原文链接:
https://mp.weixin.qq.com/s/CdMGRVPO9KxYr1F-dVJkYw

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论