

AI 前线导读: 玩过《蒙特祖玛的复仇》(Montezuma’s Revenge)这款视频游戏的玩家可能知道它有多难,更不用说对 AI 来说有多难。这款游戏光是第一关就有 24 个布满了陷阱、绳索、梯子、敌人和隐藏钥匙的房间。最近,来自谷歌 DeepMind 的 OpenAI 和其他公司的研究人员设法让 AI 系统取得了令人瞩目的成绩,但在本周,Uber 的最新研究更是让这个标准再度提高。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
在 Uber 的博客文章中(论文即将发表),Uber 的 AI 科学家介绍了 Go-Explore,这是一个被称为质量多样性的 AI 模型,能够在《蒙特祖玛的复仇》中获得超过 2,000,000 的最高分,平均分数超过 400,000(目前最先进的模型平均分和最高分分别为 10,070 和 17,500)。此外,在测试中,该模型能够“稳定地”闯过第 159 关。
此外,同样值得注意的是,研究人员声称,Go-Explore 是第一个在 Atari 2600 游戏《陷阱》中获得高于 0-21,000 分的人工智能系统,“远远超过”人类的平均表现。
“所有人都说,Go-Explore 将《蒙特祖玛的复仇》和《陷阱》的最好成绩提升了两个数量级,”Uber 团队写道。 “它不需要人类演示也可以超过《蒙特祖玛的复仇》模仿学习算法的最高性能,后者必须要通过人类的演示才能得到解决方案…Go-Explore 与其他深度强化学习算法完全不同。我们认为它可以在各种重要的、具有挑战性的问题上取得快速进展,特别是机器人技术。”
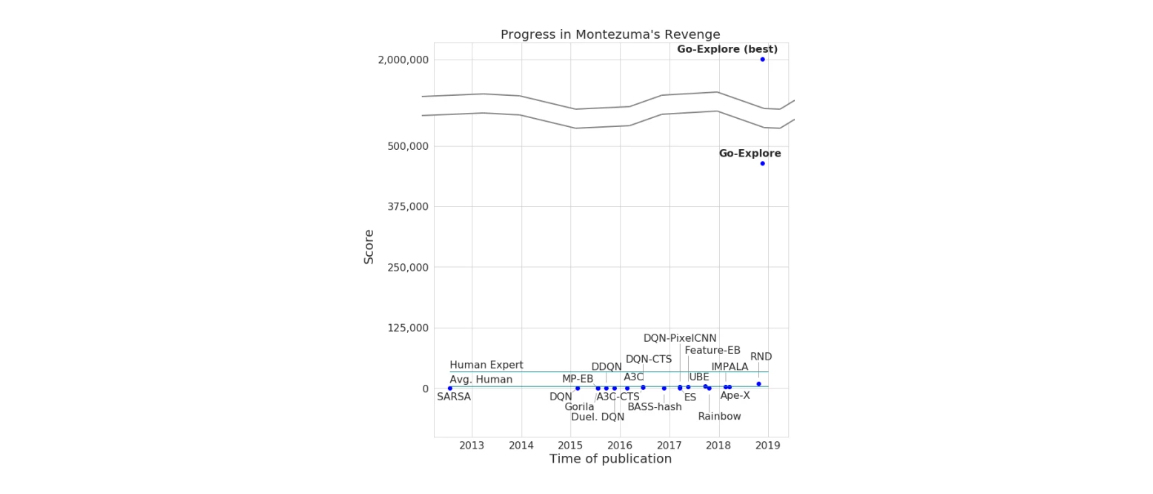
Go-Explore 在《蒙特祖玛的复仇》中的进步。图片来源:Uber
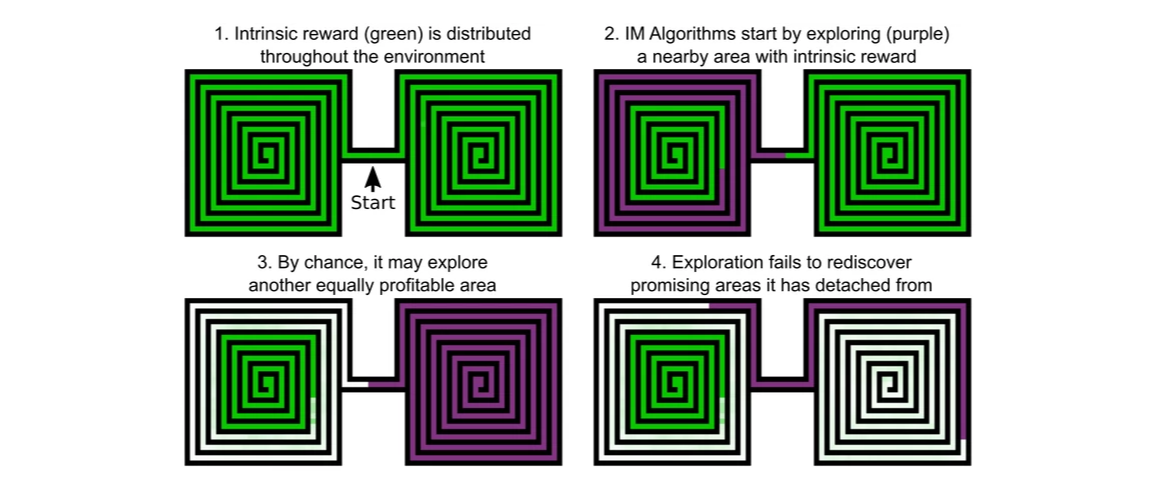
“分离效应”的演示,其中绿色区域表示内在奖励,白色区域表示没有内在奖励,紫色区域表示算法正在探索的位置。图片来源:Uber
探索阶段
在探索阶段,Go-Explore 建立了不同游戏状态的存档(单元),以及各种轨迹或分数。它选择、返回并探索一个单元,在所有它访问过的单元中,如果新的轨迹更好(即得分更高),则变换轨迹。
上述单元仅仅是下采样的游戏帧——由 11*8 个 8 像素强度的灰度图像组成,帧数不足以保证进一步探索合并。

单元演示。图源:Uber
另一个因素进一步提高了 Go-Explore 的稳健性:领域知识。该模型可以输入它正在学习的单元的信息,在《蒙特祖玛的复仇》中包括直接从 x 和 y 位置等像素提取的统计数据,当前房间和获得钥匙的数量。
强化阶段
强化阶段起到防御噪音的作用。如果 Go-Explore 的解决方案对噪声不稳健,它会使深度神经网络更稳健——使用模仿学习算法,模拟人类大脑中神经元行为的数学函数层。
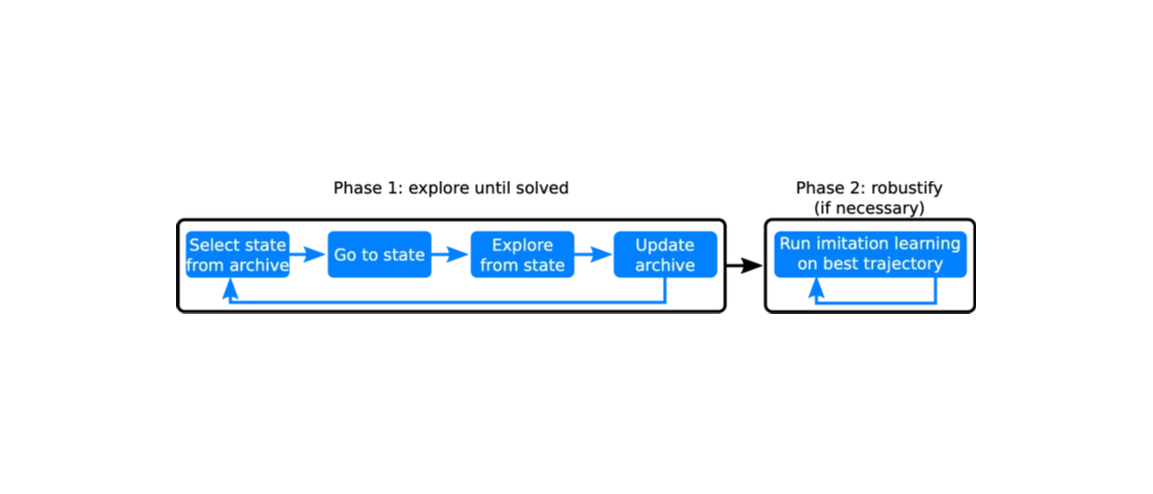
Go-Explore 算法的流程。图片来源:Uber
测试结果
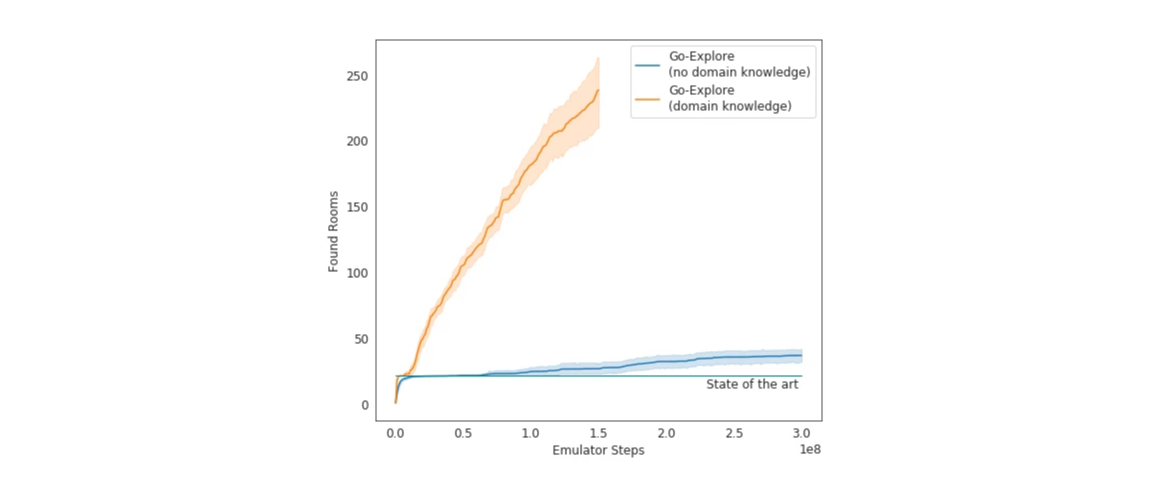
在测试中,Go-Explore 在《蒙特祖玛的复仇》中到达的房间数平均是 37,通过第一关的几率为 65%。这相比之前的最高水平还要更好,此前探索的房间数平均为 22。
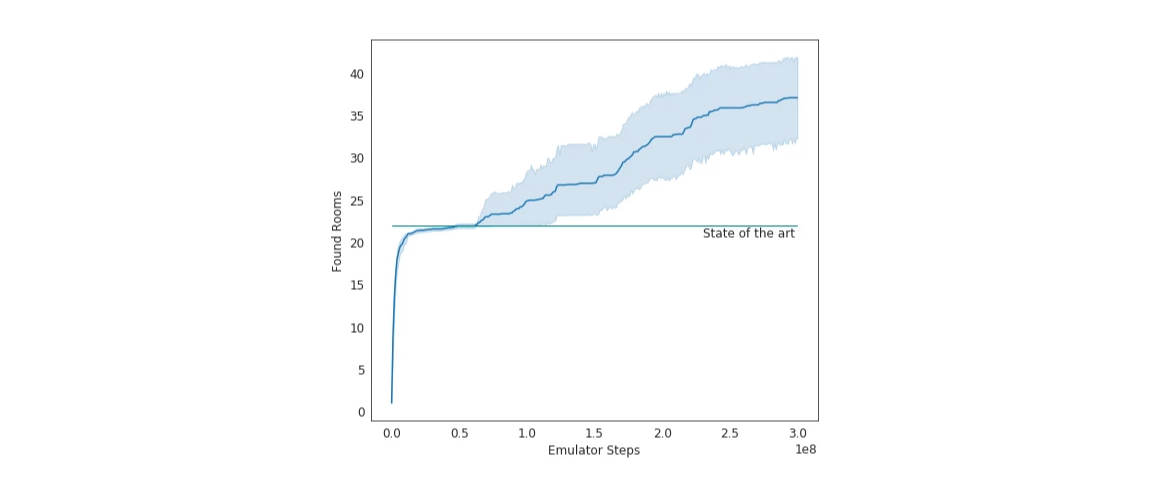
Go-Explore 找到的房间数量。图片来源:Uber
100%由 Go-Explore 生成的策略可以帮助它闯过《蒙特祖玛的复仇》第一关,平均得分为 35,410,超过之前的 10,070 分达三倍,略高于人类专家 34,900 分的平均水平。
在加入领域知识后,Go-Explore 的表现更加出色。它找到了 238 个房间,平均闯过 9 关。经过强化阶段后,它平均可以闯到第 29 关,平均分为 469,209。
Go-Explore 在第一阶段发现的房间数量,基于领域知识的单元表示。图片来源:Uber
相比之下,《陷阱》需要更多的探索,奖励也更稀疏(32 个奖励分散在 255 个房间),但 Go-Explore 能够在只知道屏幕上的位置和房间号的情况下,在探索阶段探索所有 255 个房间,并得到 60,000 的分数。
通过在探索阶段中获得的轨迹,研究人员设法强化了得分超过 21,000 的轨迹,这个分数超过现有所有最先进的算法和人类的平均水平。
Uber 团队表示,未来他们将做更多的工作,让模型具有“更智能”的探索策略和学习表征。
“值得注意的是,Go-Explore 在探索过程中采取的行动是完全随机的(没有任何神经网络!),即使应用于状态矢量空间非常简单的离散化也是有效的,”研究人员写道。“这么简单的探索方式却能获得如此大的成功,这表明,记忆和探索良好的进阶步骤是有效探索的关键,即使是最简单的探索,也可能比寻找新状态,并表示这些状态的现代技术更有用。”
原文链接:
https://venturebeat.com/2018/11/26/uber-ai-reliably-completes-all-stages-in-montezumas-revenge/


陈利鑫

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论 1 条评论