

互联网技术将我们带入了信息爆炸的时代,面对海量的信息,一方面用户难以迅速发现自己感兴趣的信息,另一方面长尾信息得不到曝光。
为了解决这些问题,个性化推荐系统应运而生。美图拥有海量用户的同时积累了海量图片与视频,通过推荐系统有效建立了用户与内容的连接,大幅度提升产品的用户体验。
在美图互联网技术沙龙中美图技术专家蔡淇森分享了美图技术团队在个性化推荐上的实践与探索,希望对打开本篇文章的你有所启发。
美图互联网技术沙龙第十期报名启动,点击底部“阅读原文”免费报名。
概览
随着大数据时代的到来,美图在个性化推荐方面也做了长时间的探索和积累,个性化推荐的目标是连接用户与内容、提升用户体验和优化内容生态。为了实现以上目标,算法需要理解内容,了解平台上可用于推荐的内容;同时也要理解用户,了解用户的兴趣爱好,从而进行精准推荐。
目前美图个性化推荐主要应用于美拍 APP,应用场景有以下三个:
1.场景一:美拍直播,实时的在线个性化排序业务;
2.场景二:美拍热门(即美拍首页),典型的 Feed 流产品,用户可在热门 Feed 流中不断翻页滚动,探索和消费自己可能感兴趣的内容;
3.场景三:播放详情页下的“猜你喜欢”模块,用于推荐相似视频。
在长时间的实践中,我们总结出精准推荐的三个要点,分别是理解内容、理解用户,在这两个基础上从而实现精准的内容推荐。
理解内容
什么是理解内容呢?其主要特征有哪些?
理解内容,即内容的特征提取。美拍 APP 的内容是短视频,其特征可分为四部分:
基础特征,即视频的时长、分辨率、标签等基础属性;
视觉特征,即通过视觉算法,对人物的性别、颜值、年龄、身高,对视频的场景、对象等进行识别;
文本特征,美拍短视频有封面文字、标题、评论等文本信息,可以通过这些文本信息进行文本挖掘,提取一些关键字、topic、情感极性等文本特征;
交互特征,是用户与内容进行行为交互的产物,用户可以对某些内容进行点赞、评论、分享、播放等行为,通过对这些交互数据进行统计分析得到交互特征。
理解用户
对内容有一定理解之后,则要进一步理解用户,从而连接用户与内容。理解用户就是我们常说的用户画像建设,建设用户画像需要了解用户的自然属性,如用户的性别、年龄、所在城市;社会属性,如职业、婚姻状况等;除了自然属性之外我们最重要的是了解用户的兴趣属性,兴趣属性不仅仅限于本平台,比如我们除了了解用户在平台上的兴趣和偏好,也要尽可能去探索用户在平台之外的兴趣爱好(打游戏、逛淘宝等)。
推荐流程
基于对内容和用户的理解可进行精准推荐。美图的推荐流程分为如下三个阶段:
召回阶段:推荐的本质是给不同的用户提供不同的内容排序。美拍APP上有数十亿个短视频,面对如此庞大的量级我们无法对用户计算所有内容的排序。通过统计召回、简单模型、图计算等筛选方式将内容的数量级降到几千至几百之后可以得到初步的推荐结果;
预估阶段:利用机器学习模型、结合超高维度和精细化的特征,以“用户-情境-物品”三个维度联合建模,得到预估模型,再对不同的目标进行预估;
排序阶段:在对目标进行预估之后,要对内容进行排序,从而决定可触达用户的排序。排序阶段会结合新颖性、多样性、准确性三个方面进行综合排序,最终将推荐结果呈现给用户。
在召回阶段,我们已经实施了基于热度、趋势、协同过滤、用户画像、内容、情境和社交关系等一系列召回方式,同时也实践了基于深度学习的召回方法。在预估阶段,较成熟的有大规模离线特征+LR、连续特征+GBDT,也实践了 NFM、DCN 等深度学习预估模型。
基于上述的推荐流程,推荐的整体架构如下图所示:
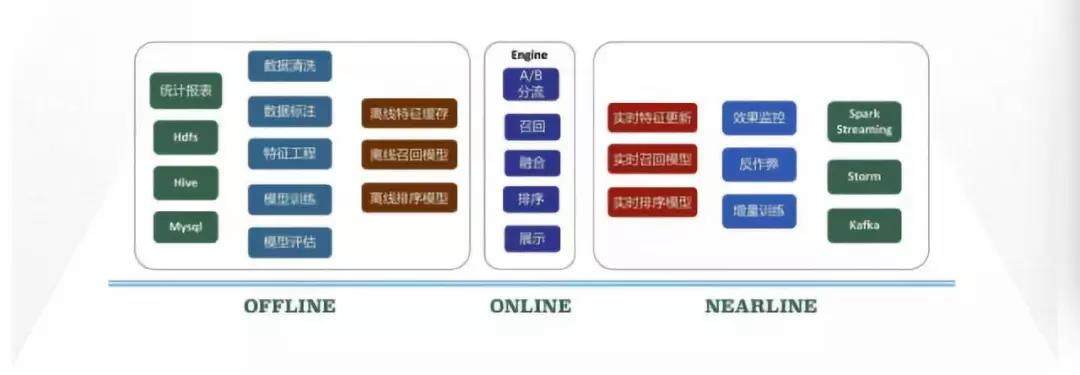
OFFLINE:主要是离线处理流程,对数据进行收集,并从数据出发进行数据清洗、数据标注、特征工程、模型训练、模型评估,最后生成离线特征、离线召回模型和离线排序模型;
NEARLINE:主要是对实时的数据流进行处理,通过获取实时日志,对数据流进行统计、效果监控、反作弊处理、特征更新以及对模型的增量训练,最终得到实时的召回模型和排序模型;
ONLINE:即引擎部分,对流量分流后进行召回、融合、排序,最终将推荐结果返回给应用端。
个性化推荐探索
推荐时效性
天下武功,唯快不破。美图的用户数量逐步增长,而每个用户的兴趣点随着场景、时间也在同步发生变化。平台上新的内容源源不断,一个好的内容型产品往往不会错过任何热点。随着大环境的变化,推荐时效性显得尤为重要,对此推荐效果的提升也有很大优化空间。
在提升推荐时效性方面,我们做了以下几个方面的尝试:
召回时效性
首先建立一个实时更新的相似视频(I2I)索引;当用户播放视频或对其产生有效行为后,利用此索引,得到对应视频的相似视频进行召回。同时通过收集并分析用户的实时行为,计算用户对不同内容类型的实时偏好,并实时获取用户对应偏好类型的实时榜单内容, 从而获得实时召回的结果。
在引擎部分会融合实时及非实时的召回,并进行预估排序,最终将推荐结果综合呈现给用户。
预估时效性
为了优化预估时效性,我们选择了在线学习。如下图所示,以训练LR模型为例,左上是LR模型的预估方程和损失函数,在复杂的线上环境中,样本输入是随机的,即今后计算的方向以及步长也是随机的,实现在线学习可以简单采用在线梯度下降方式,但是选择这种简单的优化方式会造成模型更新的不稳定性和模型效用的不稳定性;同时简单的梯度更新方式会使得模型从旧样本学习到的有效信息被遗忘。

FTRL 则是一种生成解析解的更新方式,详见上图左下的方程式,其中有四个项,第一个项保证参数随着梯度方向进行更新;第二个项保证模型的稳定性,使得每次更新的结果不会远离之前的结果;第三、四个项是常见的 L1 和 L2 正则约束;如上图右侧所示,为更新过程的伪代码。
基于上述 FTRL 的在线学习方法,我们设计了实时特征与在线学习的流程与架构。 Arachnia 收集到日志之后,FeatureServer 通过 Kafka 组件获取到实时日志,进行实时特征计算更新特征。TrainServer 还会收集用户不同行为的日志,分正负样本,得到原始样本,再将原始样本与 FeatureServer 进行交互,索引到对应的特征列表,拼装成模型训练可以直接应用样本,供模型进行更新。
我们设计基于 Parameter Server 架构的模型更新,模型更新阶段从 Parameter Server 获取模型参数,对样本进行预估,计算参数的更新,并将更新结果回流到 Parameter Server 中。由于在复杂的线上环境中,不同行为的日志可能会产生不同程度的延迟,比如在短时间内都是正样本或负样本,这种情况下在线学习的稳定性会受到伤害。因此我们设计了 Balance Cache,控制不同行为日志的消费速度使得样本的正负比例保持稳定。通过这样的架构设计,模型更新及特征更新都实现了秒级别更新。
推荐冷启动
冷启动问题分为用户冷启动和内容冷启动。用户冷启动顾名思义就是指当新用户来到平台时无相关的历史行为,而传统的推荐算法都是采用基于行为的模型,因此无法做出有效的推荐。同理,内容冷启动是指当新内容产生时,它还未在平台上进行有效的流量验证,新内容的精准分发也是一个值得探讨的问题。
用户冷启动
一个内容型平台的用户冷启动目标是将新增用户转化为消费用户,进而转化为留存用户。为了将新增用户转化成消费用户,需要匹配该用户的兴趣类型,进而推荐相关的内容,且推荐的内容要具有吸引眼球的能力,使用户能够在该内容上进行消费。
而吸引用户对内容进行消费的同时,要求推荐的内容具有一定的质量,能够使得用户在内容上进行互动并认可消费过的内容,从而转化为留存用户。
对于用户冷启动问题,也需要在召回和预估两个阶段进行优化。分别为冷启动召回阶段和冷启动预估阶段。
在召回阶段,我们设计了多级别特征组合召回,用户冷启动从定义上来说缺失用户的历史行为,但我们也总能通过产品机制调整、外部合作获得用户一定的基础信息;同时结合用户所处情境对这些特征进行组合,匹配不同特征组合的内容候选集得到初步有效的召回结果。
在预估阶段,使用服务端日志、客户端信息以及第三方数据做特征工程,提取用户特征(比如性别、年龄、职业)、情境特征(比如时间、位置、网络)和视频特征(比如标签、类型、音乐)。基于这些特征以及对应生成样本再进行模型训练,我们的模型训练会预估三个目标,即点击率、时长和留存率,并进行非线性的组合,对内容综合排序,最终呈现给用户。基于上述两个阶段的优化,新增用户留存率有了大幅度的提升。
内容冷启动
内容冷启动也是一个经典的E&E问题(Exploration & Exploitation),即对新内容和旧内容如何选择与权衡的问题。在做精准推荐时,是对旧内容进行有效挖掘的过程,但对于新内容而言,如果未能利用有效的方式将其曝光,那么我们的算法就无法挖掘到新的优质内容,无法形成一个健康的内容生态。
对于新内容而言,其转化率、点击率等效用函数的变化较不稳定,因此它的后验方差会比较大;而对于旧内容,对它的评估是比较稳定的,其后验方差比较低。换言之,对于新内容效用的预估偏差比较大,而对于旧内容的评估是比较稳定合理。针对这样的新旧内容该如何去选择?这就是经典的 E&E 问题、多臂老虎机问题(MAB)。
UCB:假设每个老虎机的中奖概率服从二项分布,在每次选择老虎机时,对中奖概率进行假设检验并得到置信区间,然后选择置信区间上界最高的一台老虎机;
Thompson采样:假设每台老虎机的中奖概率都服从β分布,在选择时对每台老虎机的中奖概率进行去拟合β分布,然后再从β分布中随机采样一个点作为此老虎机的预估分,最后选择预估分最高的一台老虎机。
为了解决内容冷启动问题,可将平台流量分成三部分:随机 Explore、个性化 Explore 和个性化 Exploit。其中,最大的一部分是个性化 Exploit,即通过各种推荐模型,对内容进行有效的精准推荐。随机 Explore 和个性化 Explore 则是针对新内容的探索。此处需要关注两点:首先要根据场景和业务设计合理的流量比例;其次要结合业务目标对业务上的流量效用进行量化,如点击率、播放完整度、时长等。
当新内容产生时,经过 MAB Score 计算,再进行一定的过滤,当它进入到探索候选池里,再进行随机召回,召回成功之后会有对应的排序和展示。当一个新内容得到曝光之后,需要收集它的用户行为反馈以更新 MAB Score。过程中,会过滤曝光次数达到一定上限的内容(我们认为它已经是旧内容),也会过滤 MAB Score 较低的内容,从而形成整个随机 Explore 的闭环。
个性化 Explore 相比于随机 Explore 在新内容产生时,会先利用视觉算法对内容进行分类,视觉分类就是把新内容进行基础的特征提取,归类到某个类目榜单里。接着,结合视觉分类和 MAB Score 维护动态的类目榜单,最后再结合类目榜单和用户实时偏好进行基于内容的召回。同样的,在召回之后,将收集到的用户的行为反馈用于更新 MAB Score 和类目榜单。这就是基于内容召回的个性化 Explore 流程。
内容多样性
多样性、准确性以及新颖性是衡量推荐系统效果非常重要的三个指标。同时最大化这三个指标从而给用户带来惊喜,使得用户在平台上留存,是推荐系统的一个终极目标。但在实际情况下,这三个指标往往需要权衡取舍,例如在大多数情况下,提升准确性的同时,推荐多样性指标可能会降低。因此,我们将问题简化,对多目标问题进行重新建模,在保证一定的多样性和新颖性约束的前提下最大化推荐准确性。
那么,如何保证推荐多样性呢?首先要定义什么内容是一样的,从而知道什么内容是不一样的。我们可以通过运营对视频打标签、通过视觉算法进行视觉分类,而上述几种方法都依赖先验的类目体系,往往无法精确匹配用户时刻变化的细粒度兴趣点。一个 UGC 平台,其重要特性之一就是内容形态快速更新,有各种各样的创意会发展成小众类别,再从小众类别迅速发展成一个新类别,那么这种基于经验知的有监督方法是无法及时响应变化的,因此考虑利用用户行为序列对内容聚类。
内容聚类
在基于用户行为序列的内容聚类中,假设用户对于兴趣点会产生其行为序列,假设某个用户喜欢小鲜肉和舞蹈,那么基于这个兴趣点,他便会观看较多小鲜肉跳舞的视频。这个问题可以类比文本领域的Topic Model问题,当作者写文章时,需要先确定文章主题,再基于主题确定文章中使用到的词。
而对用户兴趣进行建模,我们采用 LDA 的方法将用户类比为一篇文章,用户行为序列里的内容类比为文章里的词,那么可以对内容直接利用 LDA 模型进行聚类,从而匹配到用户兴趣。基于这样的假设,可以采用 word2Vec 对内容生成向量再进行聚类,也可以基于 LDA 的深化版本 DSSM 模型来对内容生成向量。如图 19 右侧所示,是 DSSM 方法的网络结构图。
展望
未来美图希望能够挖掘更多的场景,为用户提供更多的个性化服务,从而全面提升用户的产品体验。我们也希望能够通过个性化的迭代与内容生态变化进行推演,从而更全面地优化内容生态,同时通过建设更深层次的模型进行精准推荐,从有监督的学习模型训练向强化学习的方法转变,进而预估推荐算法的期望收益,大幅度提升用户体验。
本文转载自美图技术公众号。
原文链接:https://mp.weixin.qq.com/s/o0DD1ZVBXPC1CR4an7CZ_g

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论