

作者:Parth Parikh,Kishore Ganesh,Chris Ewald,Cory Massaro,Makrand Rajagopal,Sarthak Kundra
本文最初发布于 Parth Parikh 的个人博客,经原作者授权由 InfoQ 中文站翻译并分享。
注:本指南是我们在 2020 年秋为 MLH 研究员制定的开源软件指南的一部分。但是我坚信,这对任何探索大型代码库的新人都会有所帮助。如果你对这个指南有什么建议,请联系我。
内容列表
选择一个项目
开始探索存储库
使用存储库
检出最初的提交
测试用例、规范和从源代码构建
使用工具帮助理解
Git Log 使用技巧
搜索
发现问题
计划
充分使用问题描述
不要试图遍历整个代码库
弄清楚你那一部分在其中扮演的角色
重现问题
结构化理论
编码和指南
来自导师和维护人员的反馈
调试、日志记录和性能分析
选择一个项目
你的小组长和导师给你发了一个存储库列表,罗列了你可以参与的项目。你要研究这些存储库和相关的问题。最有可能的是,这些存储库已经在 GitHub 上的 MLH-Fellowship 组织中创建了分叉,并且项目板(project board)已经与这些分叉进行了关联:

项目板是一个找问题的好地方。
如果你所选择的存储库还没有创建分叉,或者还没有添加项目板,请联系相关导师,因为他们需要进一步完善他们的工作。
或者,你可能对你想要参与的库或是想要从事的工作有一个非常清晰的愿景。我们鼓励团队成员积极主动!务必在 GitHub 上公开问题并进行讨论,以表明你的意图。
开始探索存储库
探索新存储库无疑是一项令人生畏的任务,会涉及到很多方面——要熟悉语言,理解所使用的工具或框架,组件之间如何相互集成,开发人员使用什么范式,等等。本小节中提到的要点将为你提供保证存储库探索之旅顺利进行的方法。
使用存储库
正如在各种讨论中提到的,熟悉任何开源项目的最佳方法就是使用它。从一个与你将要参与贡献的项目相关的非常简单的想法开始。然后,利用这个开源项目把这个想法变成现实。在整个过程中,要确保自己了解项目的依赖项、特性和重要组件/类。设法集成尽可能多的特性。记住,你的第一个目标是探索这个项目的广度。
如果上面的过程让你觉得很被动,分析下为什么?是因为某个工具、语言、框架,还是别的什么东西?在了解了“为什么”之后,观察项目是如何使用该技术的,并阅读文档。如果文档信息量太大,请跳到教程,或者观看下作者/维护人员提供的相关视频演示。如果还有困惑,请在项目的讨论平台(Github discussion、Slack、Discord 等)上联系贡献者。
最后,MLH-Fellowship 的 kickoff hackathon,其主要目的就是让研究员们广泛地使用他们将在整个奖学金项目中做出贡献的开源项目。所以要好好利用这个机会。
检出最初的提交
总是先做最难的部分。如果最难的部分是不可能完成的任务,为什么要在容易的部分上浪费时间?一旦最难的部分完成了,也就大功告成了。
总是先做容易的部分。你一开始认为容易的部分,结果往往是困难的部分。一旦简单的部分完成了,你就可以把所有的精力都集中在困难的部分了。
—— A. Schapira
通常,最初的提交包含项目的全部要点。通过分析它们,你可以了解该存储库的初始目标。这里是 BentoML 维护者在 2019 年 4 月 2 日做的第一次提交。README指出,BentoML 旨在实现三个目标——简化部署工作流,支持主要框架,以及内置 DevOps 实践。这与/example、/bentoml/artifacts和handlers一起构成了核心组件的主要部分。此外,在他们第48次提交时,文档得到了大幅的改进。
测试用例、规范和从源代码构建
阅读测试代码往往比阅读应用程序代码更容易,这可能是因为程序员不会在晚上 8 点匆忙编写测试。
—— arandr
从这个部分过渡到计划无疑是具有挑战性的。为了简化这种转换,从源代码构建、阅读测试用例以及理解规范都非常有帮助。
测试被认为是最好的文档形式之一。通常,它能让你了解作者期望的工作方式。将测试作为示例参考对于理解任何项目都是一种很好的方式。如果你计划为开源项目编写测试,MIT: 6.005 有一篇很好的测试说明。记住——测试的目的是让你可以信心十足地重构和更改代码。
如果你还没有克隆项目并在本地运行,请确保在计划阶段之前完成这项工作。按照项目上的安装说明(通常在DEVELOPMENT.md中)把它运行起来。通常,当你可以运行项目的测试套件并通过所有(或大部分)测试时,我们就认为此步骤已完成。
研究规范是理解大型代码库的另一个具体步骤。例如,Runc(一个用于生成和运行容器的 CLI 工具)有一个SPEC.md文档介绍了libcontainer组件,其中包含文件系统、运行时和 init 进程、安全性等方面的详细配置。
使用工具帮助理解
了解代码中什么东西在哪里,通常会很有用,在这方面,类似 UML 图之类的东西可以提供帮助。许多项目的文档中都包括这样的高级架构图,因此,一定要看看项目中是否有这样的图。
这是因为它们是整个项目最简洁的表示方法,一个好的架构图可以告诉你很多关于信息如何在代码库中流动的信息。
你的项目没有 UML 图?不用担心,因为有工具可以使梳理大型代码库变得更容易。pyreverse就是这样一个工具,它可以针对你提供的代码库自动生成 UML 类图。
你还可以使用调用图(call graphs)了解哪些函数被调用了,以及它们被调用的顺序。它们是运行时函数执行的可视化表示。例如:
Plain Textclass WhatNumber: def __init__(self): self.odd_counter = 0 def check(self, number): if number%2==1: self.odd(number) elif number%2==0: self.even(number) def odd(self, number): print("{} is odd".format(number)) self.odd_counter += 1 def even(self, number): print("{} is even".format(number))if __name__ == "__main__": obj = WhatNumber() obj.check(2) obj.check(1)
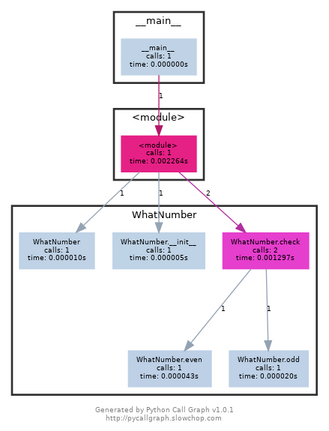
WhatNumber 的代码调用图
调用图还可以包含其他有用的补充信息,比如每次函数调用所花费的时间。
Git Log 使用技巧
正如Hacker News的这个帖子中提到的,你可以使用版本控制来识别任何开源代码库中最常编辑的文件。通常,这些文件是完成所有工作的文件(80/20 规则),你可能需要了解它们。
对应的命令如下:
Plain Text# 最常编辑的 10 个文件 git log --pretty=format: --name-only | sort | uniq -c | sort -rg | head -10# 文件名/目录名中包含单词 NAME 的最常编辑的 50 个文件 git log --pretty=format: --name-only | sort | uniq -c | sort -rg | head -50 | grep NAME
搜索
一个人要想有效地思考,必须愿意忍受焦虑,经受搜索之苦。
—— J. Dewey
搜索工具在导航大型代码库时尤为重要。如果代码是在 Github 上公开的,你可以导航到它的存储库,按/启动 Github 的搜索工具,输入查询,并得到高亮显示的即时搜索结果。
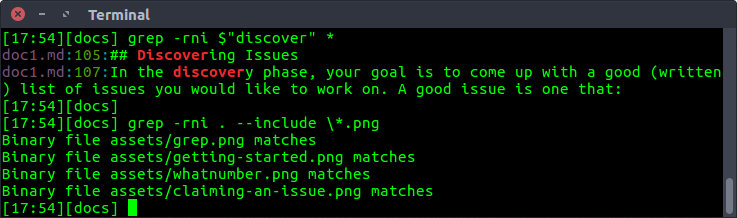
对于本地存储库,使用一个简单的grep命令就可以达到大多数目的:
Plain Text# 对于下面的命令 # r - 递归搜索目录 # n - 打印行号 # i - 大小写敏感搜索 grep -rni $"PATTERN" *# 搜索具体的扩展名 grep -rni . --include \*.EXTENSION
例如:
使用 ctags并将其与 vim 集成是另一种搜索大型代码库的方法:
对于许多流行的编程语言,UniversalCtags都可以从源文件中找出语言对象,生成一个索引(或标签)文件。这个索引文件可以方便文本编辑器和其他工具找出索引项。
发现问题
在发现阶段,你的目标是找出一系列你想要解决的好问题。一个好的问题应该满足以下条件:
你对这个问题感兴趣
你已经具备解决这个问题所需的技能,或者在编程的过程中通过适当的学习就可以习得。
务必在分配给你的项目中找问题。MLH 导师建议,开始的时候搜索带有help wanted、good first issue、MLH或hacktoberfest 标签的问题。导师们还建议,在开始的时候先从比较简单的小问题开始,然后在整个学习过程中逐步解决比较复杂和困难的问题。
总之,选择 3 到 5 个符合上述标准的问题。把它们写在你可以做笔记的地方,并在此基础上进行展开。
计划
互联网上有一则奇谈就是源自 Henry Ford 的工厂。故事的背景是围绕工厂里一台发生故障的大型机器,迷惑不解的工程师,以及一个来拯救世界的超级天才。故事是这样的:福特工厂的一台大型蒸汽机开始出现故障,福特的工程师都不知道发生了什么。但当这个天才——通常是 Nikola Tesla 或 Charles Proteus Steinmetz——介入进来,他将问题隔离到一个无足轻重的部分,只需要稍加修正即可。最后账单只有 1 万美元。
当然,福特表示怀疑,因为这个人所做的只是在受影响的区域画一个差号,所以天才做了分解说明:
1 美元用来指出位置;
9999 美元用于让工程人员知道如何将问题隔离到系统的一个部分中。
故事就是这样,当你面对一个庞大的代码库,想要添加一个小的修复时,你可能会发现自己像 ikola Tesla 一样。不要害怕,你不需要成为天才,你只需要一些基本的原则,让你可以把问题限制到代码库的一个小的、可控的部分。
充分使用问题描述
在许多情况下,你可以省去探查工作,因为项目的维护者通常已经明确了修复将涉及代码库的哪些区域,并且在问题描述中提供了这些信息。
从头开始是没有意义的,所以确保你已经查看了问题描述中提供的所有信息。
不要试图遍历整个代码库
在刚开始的时候,你可能会试图去理解所有的东西。这不仅不必要,而且还会严重损害你的贡献能力,因为十有八九你会感到更加困惑。
大多数存储库已经存在了很长一段时间,多个人对代码库做贡献和扩展,使它发展到现在的样子。在大多数情况下,理解每一行代码是不可能的,你应该试着策略性地处理这个问题。
大多数优秀的开源项目结构都非常好,文件夹层次结构和文件名大多都一目了然。通常,这些层次结构遵循自顶向下的方法:较大的子系统文件夹包含它们的子部件。沿着文件夹的层次结构向下,逐步进入你需要处理的子系统,最终,你的工作范围会缩小到项目的几个文件,这就是你解决这个问题时的工作空间。
如果你是在修复一个 Bug,那么问题可能起源于系统中的其他地方,但是,你所选择的文件是一个很好的起点,你可以尝试从这里出发跟踪问题的来源。当然,探索代码库的一小部分比试图掌握所有正在发生的事情要容易得多。
切纸原理
如果项目是你创建的,你会知道它的来龙去脉。但对于别人的项目,如何才能掌握到同样的程度?
如前所述,我们不可能在很短的时间内掌握一个重要的代码库。不过,你应该知道“切纸原理”,其理念是,当你处理完代码库中的几个小问题时,你对代码库的基本理解会得到改善,直到你对代码库中所有东西的工作原理都有了一些了解。这就是“局外人”熟悉代码的方式,随着时间的推移一小部分一小部分地熟悉代码。
弄清楚你那一部分在其中扮演的角色
既然你已经确定了修复范围,那么你应该将其他所有东西都视为黑盒。明确你那部分代码将获得何种类型的输入,如何使用它们,以及预期有什么输出。
所有这些看起来都很抽象,但其基本思想是,如果要添加新内容,你不需要了解所有其他内容是如何实现的。你只需要假设其他一切都符合项目规范,然后尝试探索你所关注的一小部分代码。
当然,对于每个更改,可能都需要查看代码库的多个不同的部分,其中许多都有 Bug。不过,这只是因为你遇到了一个糟糕的软件,通常,你只需要关注成熟代码库中一个明确定义的方面。
重现问题
如果你的工作是消除漏洞,那么在计划修复之前,你第一步首先要做的无疑是重现问题。在这个过程中,你要搭建项目,确保它可以运行,且所有配置都正确,然后最终重现问题。
有一种简单的方法来重现问题可以在很多方面带来帮助。它有助于加速开发,你可以(而且应该)更进一步,尝试编写一个捕捉这种行为的测试。这样,你不仅可以快速运行测试,而且还可以确保在项目的未来版本中,这个问题不会再次意外出现。
结构化理论
你已经研究了这个问题,缩小了关注范围,现在可以着手解决问题了。如果你发现了错误的根本原因,那么你可以继续进行下一步的工作,做一个解决方案,但如果你被卡住了,有一件事也许可以帮助你摆脱困境,那就是创造性地思考导致问题的潜在原因,并设法验证每个原因是否真得存在。
当你试图想出一个解决方案时,围绕解决问题的多种方法进行集体讨论是有帮助的,因为你可以比较和对比几种方法,并锁定最优的一种。
在巨大的代码库中编辑文件时,你可能会陷入分析瘫痪的状态。可能会有很多想法在你的脑海中浮现,但往往,出于对代码质量的担忧,你只是停在原地,而不是继续前进。
这就是为什么必须分两个阶段进行。第一步是让它可以工作,这会儿还是在你的机器上。有些东西可能是硬编码的,有些部分可能还可以优化,但重要的是你有一些可以工作的东西。将它从一个可工作的状态提升到一个健壮的状态,比试图在第一次就把一切都做好要容易得多。
领会迭代的精神,不要害怕修改代码。一旦概念验证完成,你就可以继续完善它了。
编码和指南
来自导师和维护人员的反馈
另一种有效的(调试)技术是向其他人解释你的代码。通常,你会向自己解释这个 Bug。有时几句话之后,你就会尴尬地说,“没关系,我知道怎么回事了。很抱歉打扰你。”这非常有效;你甚至可以让非程序员作为倾听者。有一所大学的计算机中心在服务台附近放了一只泰迪熊。学生们先向这只熊解释,然后才能与人类顾问交谈。
B. Kernighan & D. Pike (《程序设计实践》)
正如Arandr所提到的,与有经验的维护人员交谈以及向新贡献者解释你的理解是一种有积极意义的习惯。这两种方法都需要对代码库进行积极的思考,通常比“试错”策略要快。
安排一个会议,和你的 MLH 导师/代码维护人员一起看下你的计划。为会议准备一份最详细的计划。在理想情况下,计划是一系列变更的分解,这里的分解是指做这项变更主要需要哪些步骤?这里有一条很好的经验法则:你使用的每个动词都应该有自己的步骤。
下面是一个不错的步骤分解示例:
新建一个类
myApiService.js将
myComponent.js文件中函数getApiResponse的代码提取到自己的类中。这个类的公共方法将是 ……编写一个新的测试测试,覆盖未向
xyz函数传递参数的用例。
会议期间,导师/维护者会帮助你澄清并改进计划。他们可能会要求你改进计划的某些方面,或者直接进入验收阶段。
调试、记录日志及性能分析
调试是一门需要进一步研究的艺术.……最有效的调试技术似乎是那些设计时就内置到程序中的技术——如今,许多最好的程序员会将近一半的程序用于为另一半程序的调试提供便利;这部分程序最终会被丢弃,但最终生产力的提高令人惊讶。
另一个好的调试实践是记录所犯的每一个错误。尽管这可能会很尴尬,但对任何研究调试问题的人来说,这些信息都非常宝贵,而且它还可以帮助你学习如何减少将来的错误数量。
D. Knuth (《计算机程序设计》第一卷)
调试器是每个程序员工具库里最强大的工具之一。理想情况下,为了了解某些函数调用,你应该选择一个请求流,发起一个请求,并在调试器的引导下完成整个请求流。当你在调试器的引导下查看不同的文件时,你正在利用你的视觉记忆。你会记住代码是如何组织的以及文件是什么样子的。对于许多调试器,如gdb和pdb,命令集几乎是一样的。下面这些基本命令,你应该熟悉:
l—— 显示当前行及以下的代码行p—— 在当前上下文中计算表达式并打印其值s—— 逐步执行代码n—— 下一行代码(例如:如果你不想执行argsort(),想跳到下一行,则可以使用n)q—— 退出调试器b—— 设置断点(依赖提供的参数)
在某些情况下,使用数据断点是有好处的。数据断点让你可以在存储在特定内存位置的值发生变化时中断执行。例如,监控变量X变为NULL,找出谁过早地释放了内存导致了悬空指针,观察全局数据访问流,这些都是它的一些用例。Shog9在StackOverflow上提供了更全面的用例。
在这一点上,一个常见的问题是——难道打印语句不够吗?视情况而定!Glen K. Peterson的回答很好地描述了这一观点:
我发现,对于纯粹的软件问题,思考问题并测试系统,了解关于这个问题的更多信息比逐行执行代码要有用得多。使用 print 语句,我就可以看到命令行或日志文件中发生的所有事情并在想象中重现,而且比使用调试器来回切换更容易。
通常,解决最难的 Bug 要抛开计算机来理解问题。有时用一张纸或白板,有时答案会在我做其他事情的时候自己显现出来。最棘手的 Bug 可以通过仔细查看代码来解决,就像在玩 Where's Waldo。其余的,使用打印语句或日志语句似乎就很简单。
不同的人有不同的风格,不同的风格适合不同的任务。Print 语句并不一定是比调试器次一级的方法。这取决于你所做的事情,它们也可能更好用,特别是在没有原生调试器的语言中(Go 有吗?)
在有些情况下,程序失败的部分非常大;程序采用非线性流控方法;程序是多线程;实时运行;或者执行像写文件这样的破坏性操作——更好的选择是使用日志记录和断言,可以看下 StackOverflow 上slugfilter所作的解释。
要了解关于调试的详细内容,可以阅读麻省理工学院讲师 Robert Miller 和 Max Goldman 为课程 6.005:软件构造配套的阅读材料。
从Python文档中可以看出,Profilers 提供了程序的确定性性能分析(deterministic profiling)。其中,概要文件是一组统计信息,描述程序各个部分执行的频率和时间。它们将帮助你了解程序的哪些部分占用了大部分时间和/或资源,以便你可以集中精力优化这些部分。麻省理工学院的阅读材料Missing Semester是一份详细介绍性能分析器的精彩指南。
结论:
对于调试,人们的态度往往是开始时厌恶,执行时不情愿,结束时炫耀。
查看英文原文:General Guide For Exploring Large Open Source Codebases

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论