

我们可能会看到有更多的开放接口和元框架,但它们也有缺点。
深度学习、无服务器功能和流处理有何共同之处?它们除了成为计算领域的大趋势之外,支持这些变化的开源项目正在以一种全新的、也许是独特的方式进行构建。在每一领域中,都出现了仅限 API 专用的开源接口,这些接口必须与许多受支持的独立后端之一一起使用。这种模式可能会对业界带来好处,因为这种模式为开发者带来了较少的重写,且易于采用、性能改进和为公司带来盈利的承诺。我将在本文中阐述这种模式,并提供有关它的第一手资料,讨论它对开源的意义,然后探讨我们应该如何培育这种模式。
通常,新的开源项目既提供了新的执行技术,也提供了用户编程时所要用到的 API。API 的定义在一定程度上可以视为一种创造性活动,它从历史上借鉴了类似的概念(如 Storm 的 spouts 和 bolts ,或 Kubernetes 的 pods)来帮助用户快速了解如何使用这一新事物。API 特定于项目执行引擎:它们一起构成一个单独的整体。用户阅读项目文档来安装软件,与接口交互,并从执行引擎中受益。
几个重要的新项目结构不同。它们没有执行引擎;相反,它们是为几个不同的执行引擎提供公共接口的元框架(metaframeworks)。Keras 是第二大流行的深度学习框架,就是这种趋势的一个例子。正如创建者 François Chollet 最近试图解释的那样,“Keras 是一个接口,而不是一个端到端的框架。”同样的,Apache Beam,一种大型数据处理框架,也是一种自我描述的“编程模型”。这是什么意思呢?你能用自己的编程模型来做什么呢?答案是:真的并不能做什么,因为这两个项目都需要外部的后端。就拿 Beam 这种例子来说,用户编写的管道可以在八个不同的“运行器(runner)”上执行,包括六个开源系统(其中五个来自 Apache)和三个专有的厂商系统。同样的,Keras 也支持 TensorFlow、微软认知工具包(Microsoft’s Cognitive Toolkit,CNTK)、Theano、Apache MxNet 等。Chollet 在 GitHub 最近的一次交流中简要描述了这种方法:“事实上,我们将来甚至会扩展 Keras 的多后端的方面。……Keras 是深度学习的前端,而不是 TensorFlow 的前端。”

相似之处不止于此。Beam 和 Keras 最初都是由 Google 员工在同一时间(2015 年)以及相关领域(数据处理和机器学习)创建的。然而,似乎这两个小组都独立地得到了这个模型。这究竟是怎么发生的?这对于这个模型意味着什么呢?
Beam 的故事
2015 年,我在 Google 担任产品经理,专注于 Cloud Dataflow(云数据流)。Dataflow 工程团队的传奇地位可以追溯到 Jeff Dean 和 Sanjay Ghemawat 于 2004 年发表的著名论文 MapReduce。与大多数项目一样,MapReduce 定义了一种执行方法和一种编程模型来利用它。虽然执行模型仍然是批处理的最新技术,但使用编程模型的体验并不那么令人愉快,因此 Google 很快就开发了一个更简单的抽象编程模型 Flume(图 1 的第一步)同时,对低延迟处理的需求,导致了一个新的项目,该项目使用通常的执行模型和编程模型,成为 MillWheel(即图 1 中的第二步)。有趣的是,这些团队围绕着这样的一个想法走到了一起,Flume 是用于批处理的抽象编程模型,带有一些扩展,也可以是流的编程模型(第三步)。这一关键见解是 Beam 编程模型的核心,当时称为 Dataflow Model(数据流模型)。
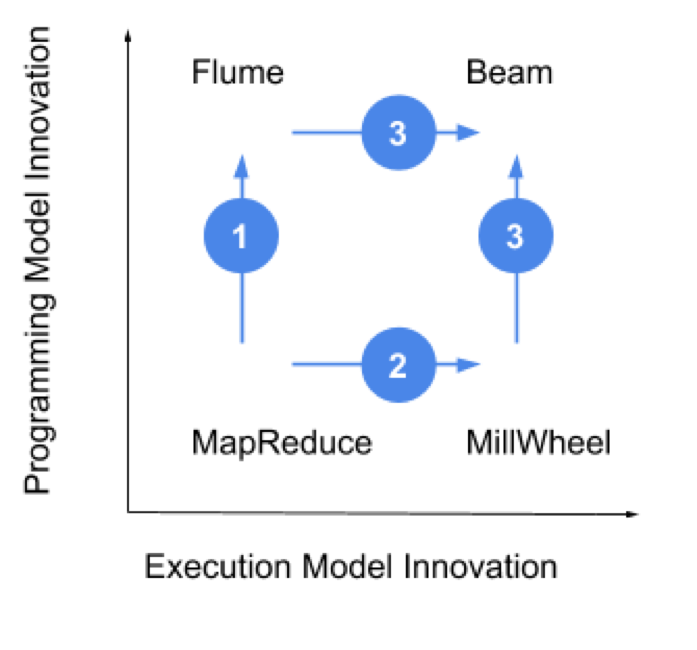
从 Beam 的故事中,得到了一套原则:
创新有两个层次:编程模型和执行模型。过去我们假设它们需要藕合,但是开放接口挑战了这种假设。
通过将代码与抽象解耦,我们还将贡献者社区解耦为接口设计者和执行引擎创建者。
通过抽象和解耦(技术上和组织上),社区吸收创新的速度加快了。
在 Keras 的案例中,考虑以上这些原则。尽管 TensorFlow 很受欢迎,但用户很快意识到它的 API 并不适合日常使用。Keras 的简单抽象在 Theano 用户中已经拥有强大的追随者,因此它成为 TensorFlow 的首选 API。从那时起,Amazon 和 Microsoft 分别推出了 MxNet 和 CNKT 作为后端。此举意味着,选择独立开放接口 Keras 的开发人员现在就可以在所有四个主要框架上执行,而无需任何重写代码。各家组织都在使用所有最聪明的团队研发的最新技术。像 PlaidML 这样的新项目,可以很快找到受众;Keras 开发人员无需学习新接口就可以轻松地尝试 PlaidML。
无服务器的故事
就像 Beam 一样,无服务器框架的开放接口的远景也像 Beam 一样,也是在不断发展的,并不是立即就显现出来。我记得在 2015 年的《Hacker News》(《黑客新闻》)看到的 JAWS(JavaScript AWS)的公告,就在那一年,Keras 和 Beam 诞生了。几个月之后,JAWS 团队在 Re:Invent 上展示了他们的 AWS Lambda 特定框架。它包含了 Lambda 提供的构建、工作流和最佳实现,这就是 Amazon 的功能即服务(Function as a Service,FaaS)。但 Lambda 只是几个私有云和开源 FaaS 产品中的第一个。JAWS 框架很快就重新命名为 Serverlessand 并为新手提供支持。
直到 2017 年 8 月 Auste Collins 宣布推出 Event Gateway(事件网关)时,无服务器仍然不是一个开放的 API 接口。Event Gateway 是“无服务器架构中缺失的一块”。即使在今天,无服务器也没有提供自己的执行环境。Gateway 指定了一个新的 FaaS API,可以抽象并使用任何流行的执行环境。Collin 对 Event Gateway 的价值主张可借鉴 Keras 或 Beam:“用户的任何事件都可以有来自任何其他云服务的多个订阅者。Lambda 可以与 Azure 交互,也可以与 OpenWhisk 交互。这使得企业得到了完全的灵活性,……它还可以保护你免受厂商锁定,同时也让你对未来可能带来的任何其他事物保持开放。”
驱动力
作为风险投资者,我发现自己在问一些怀疑的问题:元框架是真正的趋势吗?这一趋势的背后是什么?为什么是现在才发生?这里的一个关键因素当然是云托管服务。
实际上,Google 内部所有的托管服务都采用了独特的 Google 特定 API。例如,Google 的 Bigtable 是第一个 noSQL 数据库。但由于 Google 不愿透露细节,开源社区就想出了自己的实现方案:HBase、Cassandra 等等。将 Bigtable 作为外部服务提供意味着要引入另一个 API,以及一个要引导的专用 API。相反,Google Cloud Bigtable 是使用兼容 HBase 的 API 一起发布的,这意味着任何 HBase 用户都可以采用 Google 的 Bigtable 技术,而无需更改任何代码。提供开放接口背后的专用服务似乎是 Google Cloud 的新兴标准。
其他云厂商也纷纷效仿。Microsoft 在每个转折点都在拥抱开源和开放接口,而 Amazon 被客户所逼,很不情愿地拥抱开源和开放接口。这两家公司最近共同推出了 Gluon,这是一个开放的 API,像 Keras 一样,可以在多个深度学习框架上执行。云厂商在开放的、被广泛采用的 API 后面公开专有服务的趋势,对用户来说不啻为一场胜利,用户因此可以免于厂商锁定,并且可以轻松采用。
展望未来
随着云服务的增加,复杂性和创新速度也在不断提高,我们有望能够看到更多开放接口和元框架的出现,但它们也有缺点。额外的抽象层引入了间接性。调试可能会变得更加困难。功能可能会滞后,或者根本不受支持;接口可能提供执行引擎共享的访问功能,但省略了复杂或很少使用的增值功能。最后,一种新的执行方法不见得能立即适用于现有的 API。比如,PyTorch 和 Kafka Streams 最近越来越流行,但它们还没有符合 Keras 和 Bram 提供的开放接口。这不仅给用户带来了困难的选择,而且对 API 框架的概念也提出了挑战。
综上所述,以下是一些取得成功的建议:
对 API 开发人员来说: 当你发现在 API 上话费大量时间在讨论无关紧要的琐事时,请考虑:
(1),它本身就是一个创新载体;
(2),与整个行业合作,把事情做好。
这就是开源社区和治理方面的关键所在。要在分布式系统中达成共识是件很困难的事情,但 François Chollet、Tyler Akidau 和 Austen Collins 在他们各自的领域都做了出色的工作。例如,Clooins 一直在与 CNCF 的无服务器工作组合作,将 Cloud Events 建立为行业标准协议。
对服务开发人员来说: 最重要的是关注性能。开放接口现在是你的发型渠道,让你可以专注于成为最佳的执行框架。伟大的技术,将不会再有被那些不愿尝试或采用的落伍者所束缚的风险。由于转换成本低,开发者将可以很容易地看到改进。观察基准测试将成为标准做法。
对用户来说: 有关这些开放接口的社区将会变得活跃。用户需要这些社区保持活跃,以保持 API 用例驱动和相关。还可以尝试不同的可用后端。这是一种新的有效的自由,它将激励性能和创新。
对每个人来说: 可以考虑帮助完成本文中提到的那些项目,开放接口仍然是全新的事物,它们的未来取决于先驱者的成功。
原文链接:
https://www.scalevp.com/blog/why-your-next-open-source-project-may-only-be-an-interface

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论