

机器翻译技术的发展一直与计算机技术、信息论、语言学等学科的发展紧密相随。从早期的词典匹配,到词典结合语言学专家知识的规则翻译,再到基于语料库的统计机器翻译,随着计算机运算能力的提升和多语言信息资源的爆发式增长,机器翻译技术逐渐走出象牙塔,开始为普通用户提供实时便捷的翻译服务。
本文将简单介绍机器翻译技术的发展,包含机器翻译的演进历史与基本思想、端到端的神经翻译网络内部细节、技术落地过程中的部分实践经验,以及对翻译技术未来发展方向的一些思考。
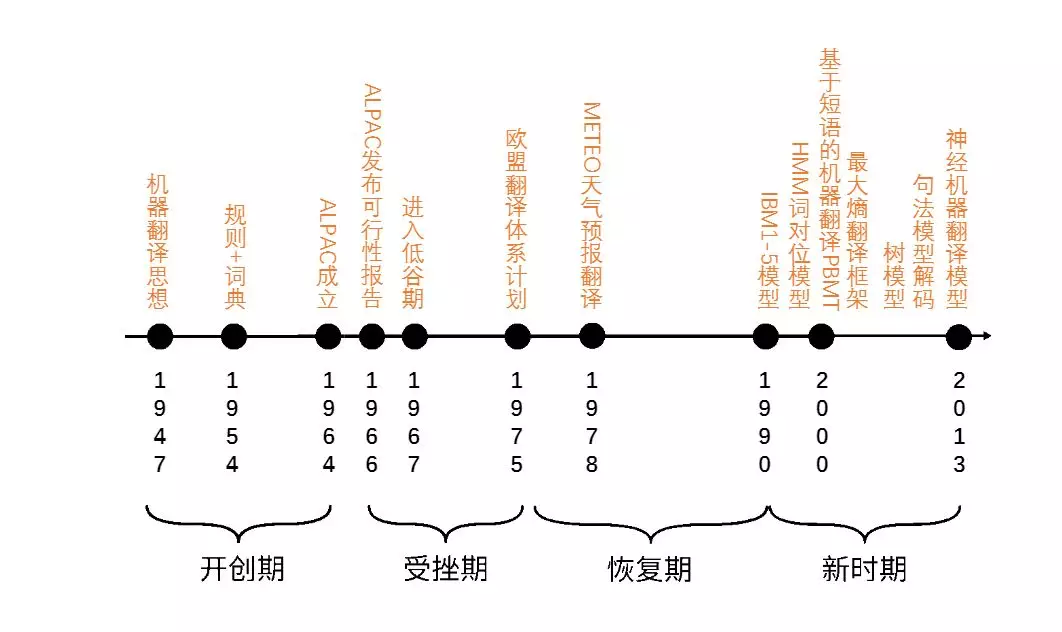
一、发展历程
机器翻译的研究历史可以追溯到 20 世纪三四十年代。走过六十年的风风雨雨,机器翻译经历了一条曲折而漫长的发展道路,学术界一般将其划分为如下四个阶段:
1.1 开创期(1947-1964)
1954 年,美国乔治敦大学(GeorgetownUniversity) 在 IBM 公司协同下, 用 IBM-701 计算机首次完成了英俄机器翻译试验,向公众和科学界展示了机器翻译的可行性,从而拉开了机器翻译研究的序幕。
从 20 世纪 50 年代开始到 20 世纪 60 年代前半期,机器翻译研究呈不断上升的趋势。美国和前苏联两个超级大国出于军事、政治、经济目的,均对机器翻译项目提供了大量的资金支持,而欧洲国家由于地缘政治和经济的需要也对机器翻译研究给予了相当大的重视,机器翻译一时出现热潮。这个时期机器翻译虽然刚刚处于开创阶段,但已经进入了乐观的繁荣期。
1.2 受挫期(1964-1975)
1964 年,为了对机器翻译的研究进展作出评价,美国科学院成立了语言自动处理咨询委员会(AutomaticLanguage Processing Advisory Committee,简称 ALPAC 委员会),开始了为期两年的综合调查分析和测试。
1966 年 11 月,该委员会公布了一个题为《语言与机器》的报告(简称 ALPAC 报告) ,该报告全面否定了机器翻译的可行性,并建议停止对机器翻译项目的资金支持。这一报告的发表给了正在蓬勃发展的机器翻译当头一棒,机器翻译研究陷入了近乎停滞的僵局。
1.3 恢复期(1975-1989)
进入 70 年代后,随着科学技术的发展和各国科技情报交流的日趋频繁,国与国之间的语言障碍显得更为严重,传统的人工作业方式已经远远不能满足需求,迫切地需要计算机来从事翻译工作。
同时,计算机科学、语言学研究的发展,特别是计算机硬件技术的大幅度提高以及人工智能在自然语言处理上的应用,从技术层面推动了机器翻译研究的复苏,机器翻译项目又开始发展起来,各种实用的以及实验的系统被先后推出。
1.4 新时期(1990 至今)
随着 Internet 的普遍应用,世界经济一体化进程的加速以及国际社会交流的日渐频繁,传统的人工作业的方式已经远远不能满足迅猛增长的翻译需求,人们对于机器翻译的需求空前增长,机器翻译迎来了一个新的发展机遇。
二、什么是翻译引擎,如何训练?
当我们拥有充足的平行语料数据时,如何去构建一个机器翻译系统来实现翻译任务?
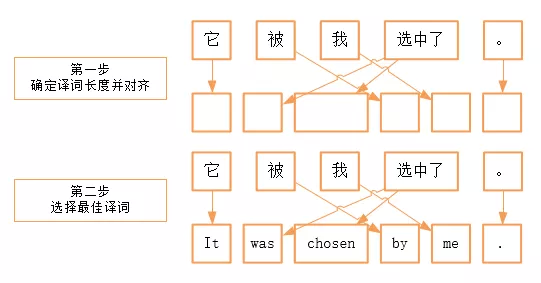
基本实现:调序+翻译=解码器,基于规则或统计的方法,我们可以确定目标语言的语法或习惯如何组织译文的句子结构,然后选择最佳的译词进行句子成分的填充,中间过程少不了各式各样的平滑及消歧手段。
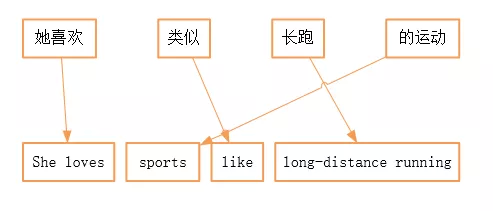
优化实现:基于短语的统计翻译,基本的翻译单元调整到了短语级别,短语不一定具有任何语法意义,在歧义消除、局部排序、解码效率上有一定的优势,减少了机器翻译系统所要面对的复杂度,表现出较好的模型健壮性,常作为统计机器翻译系统研究的基线。
平滑实现:由人工神经网络拟合各个模块的决策,替代人工规则或者统计频率。
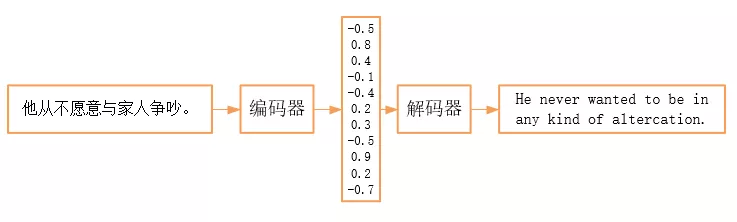
什么是语言模型?
语言模型 P(.)可以用于描述一段序列出现的合理性。
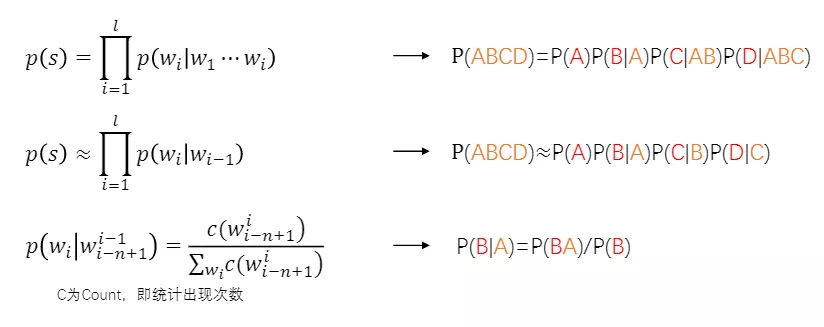
利用语言模型可以生成句子

首先起一个开头,然后对已有文本进行符号化处理,得到一个离散的符号序列,对序列中最后 n 个单词或整个序列进行建模,得到词表中每一个符号作为下一个词的概率,取概率最大的符号作为下一个词。
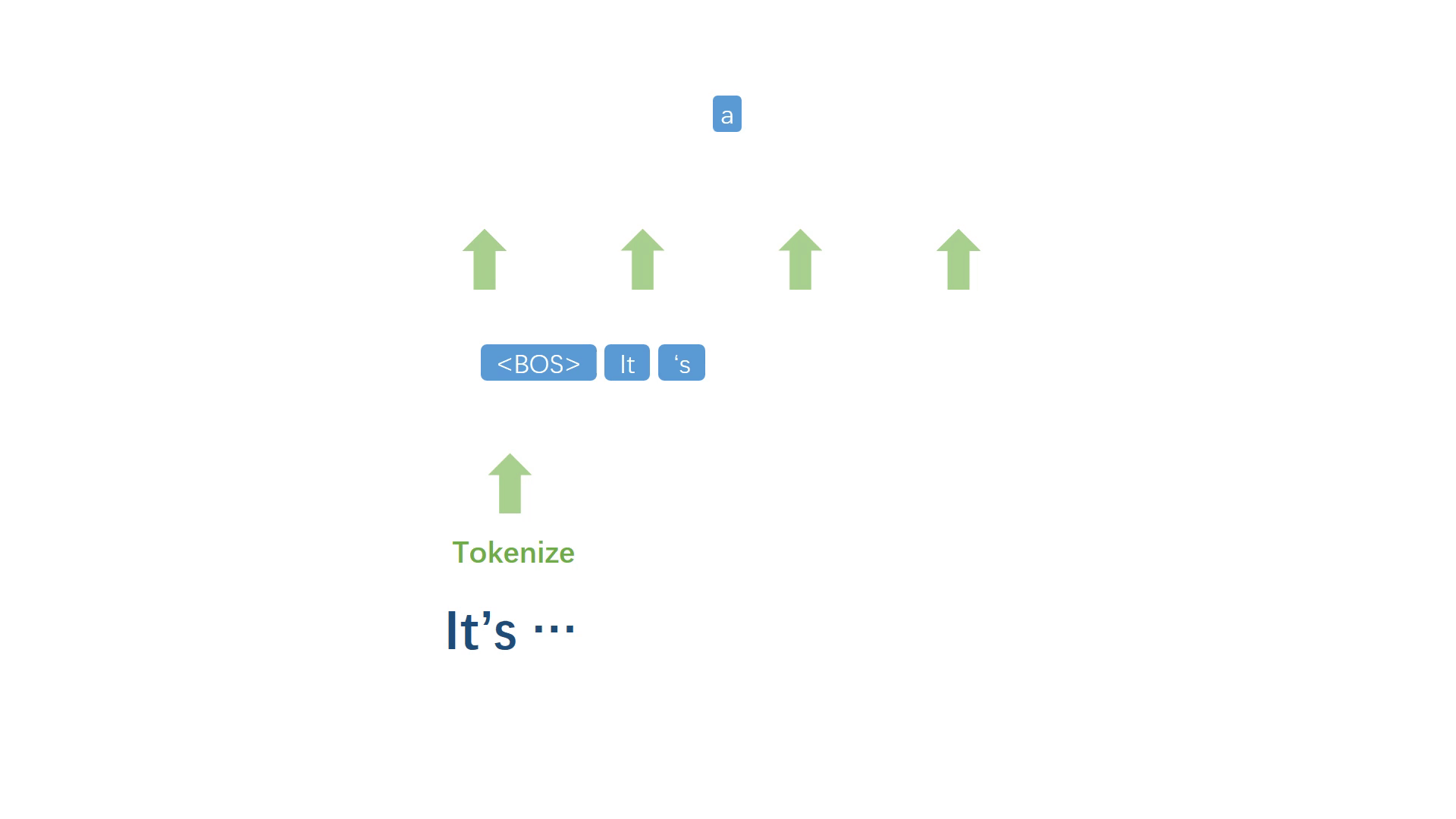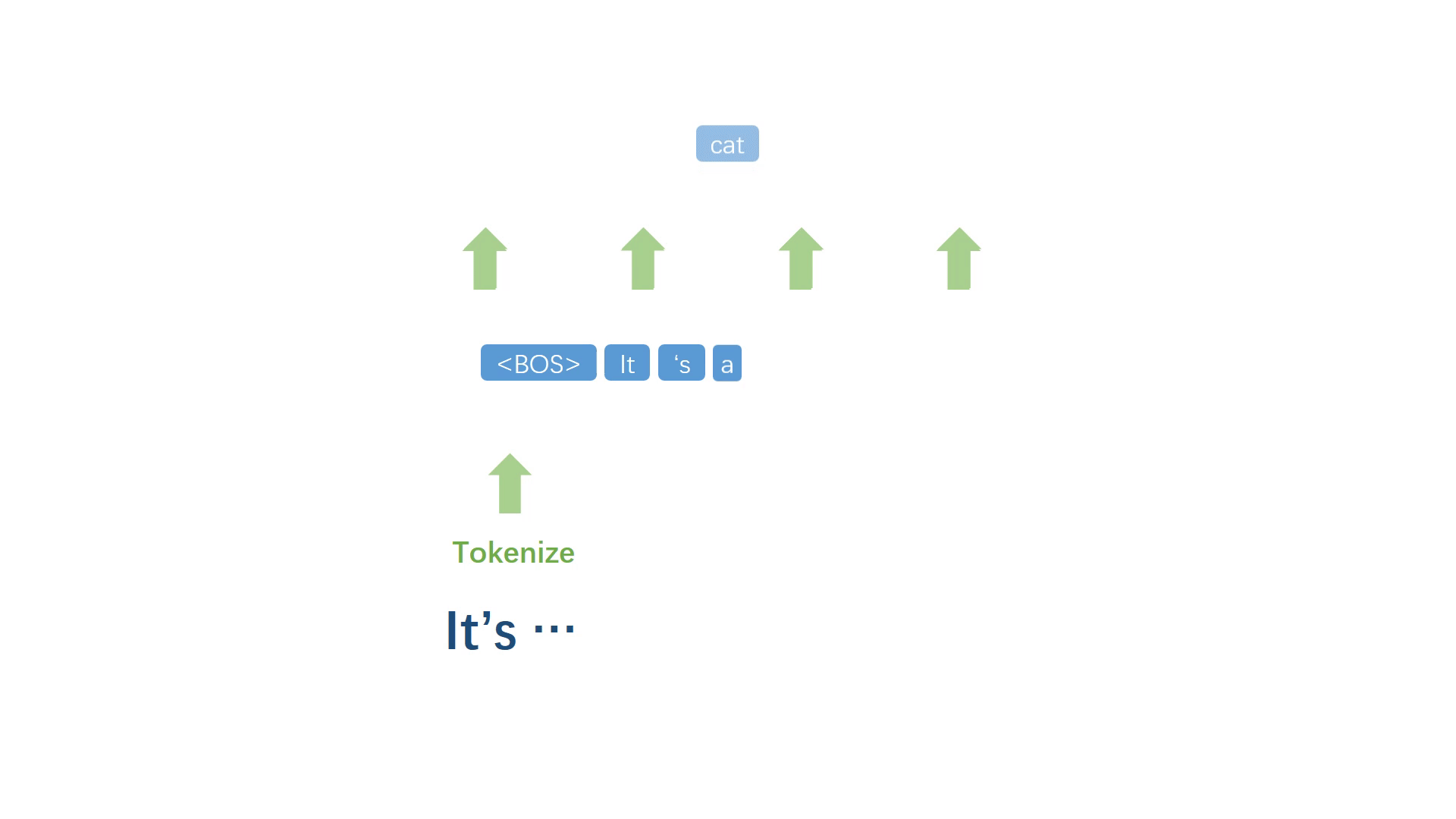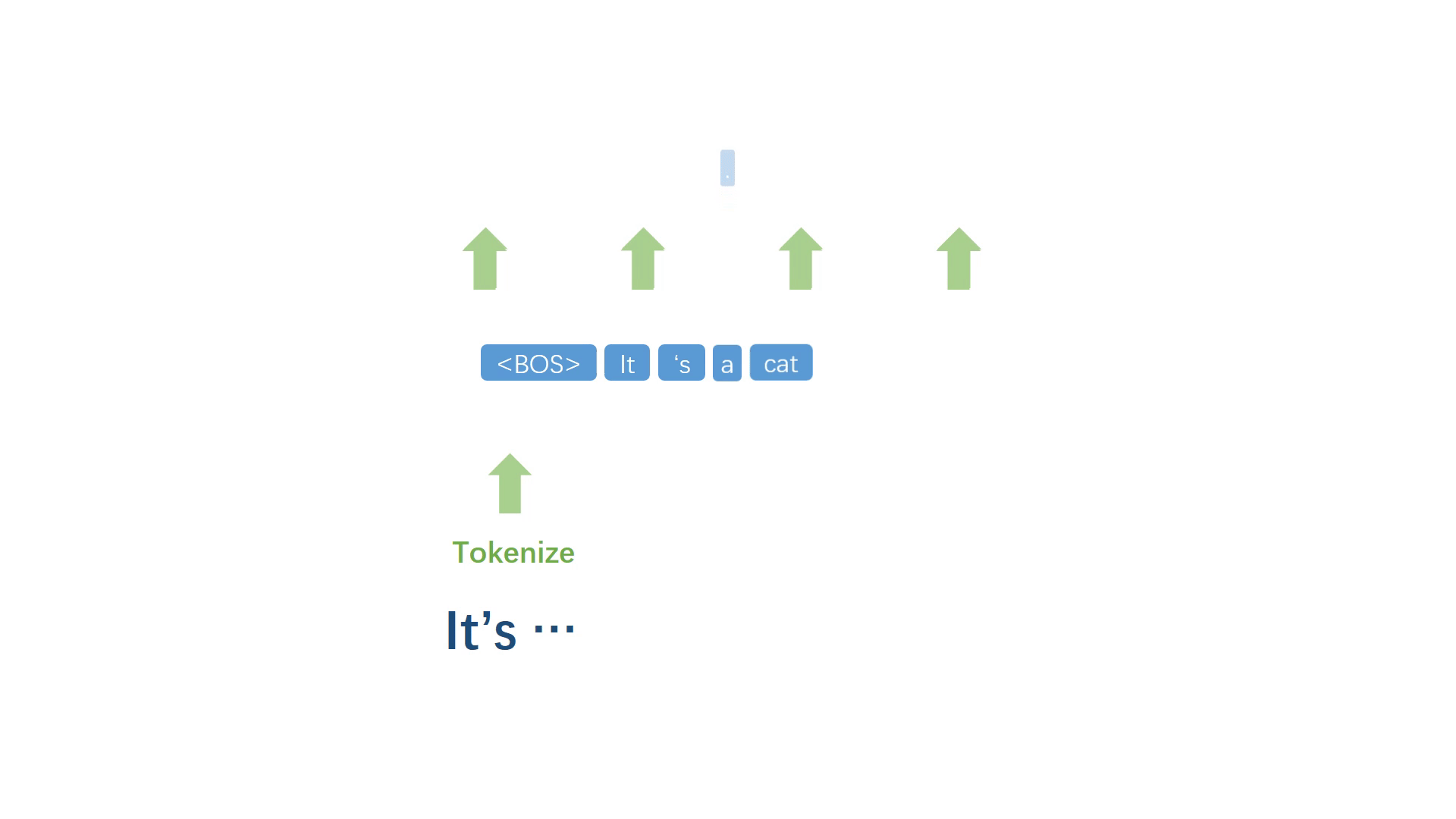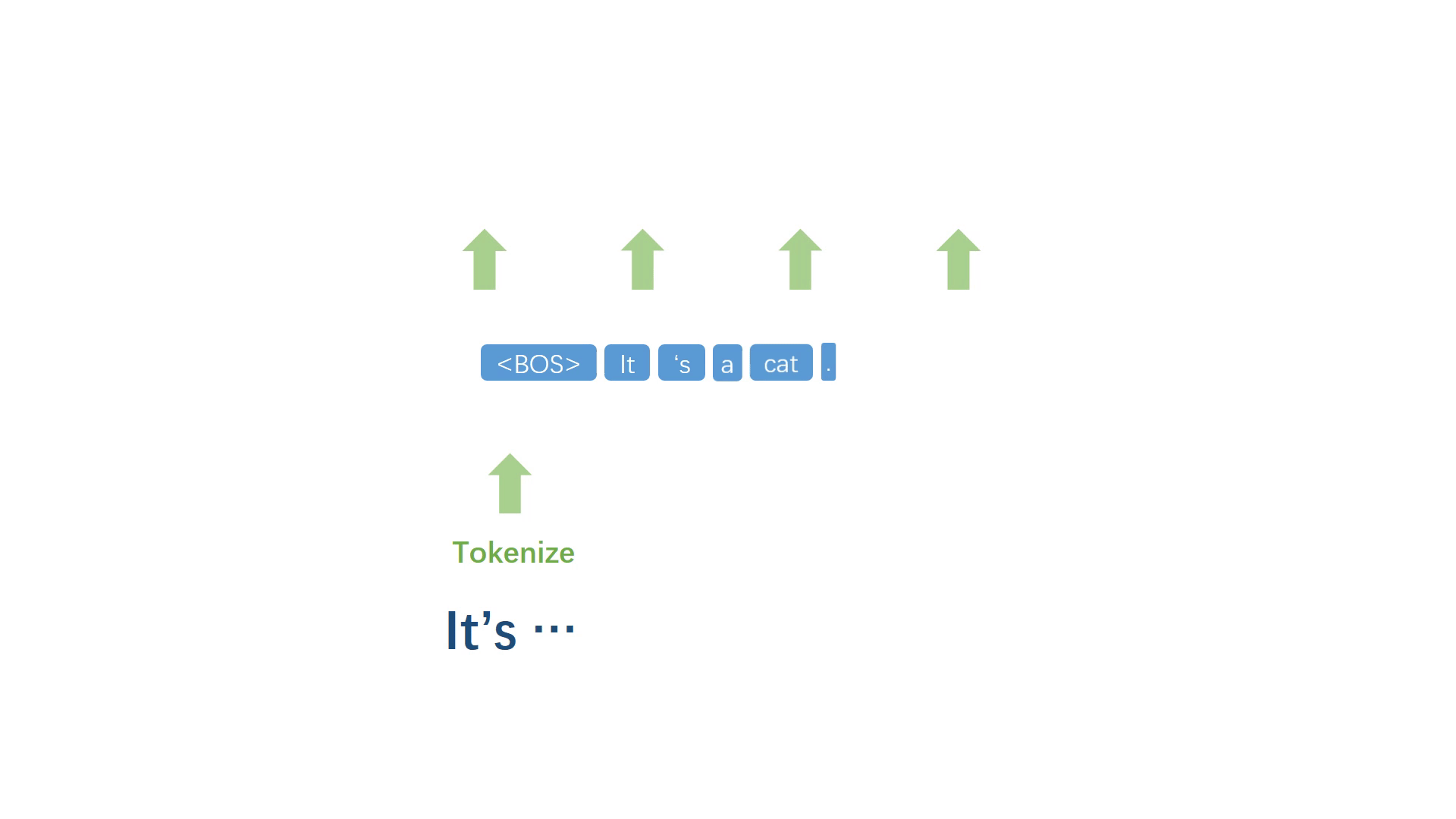
将生成的词加入原句,然后重复上述步骤反复迭代,不断生成之后的每一个词。
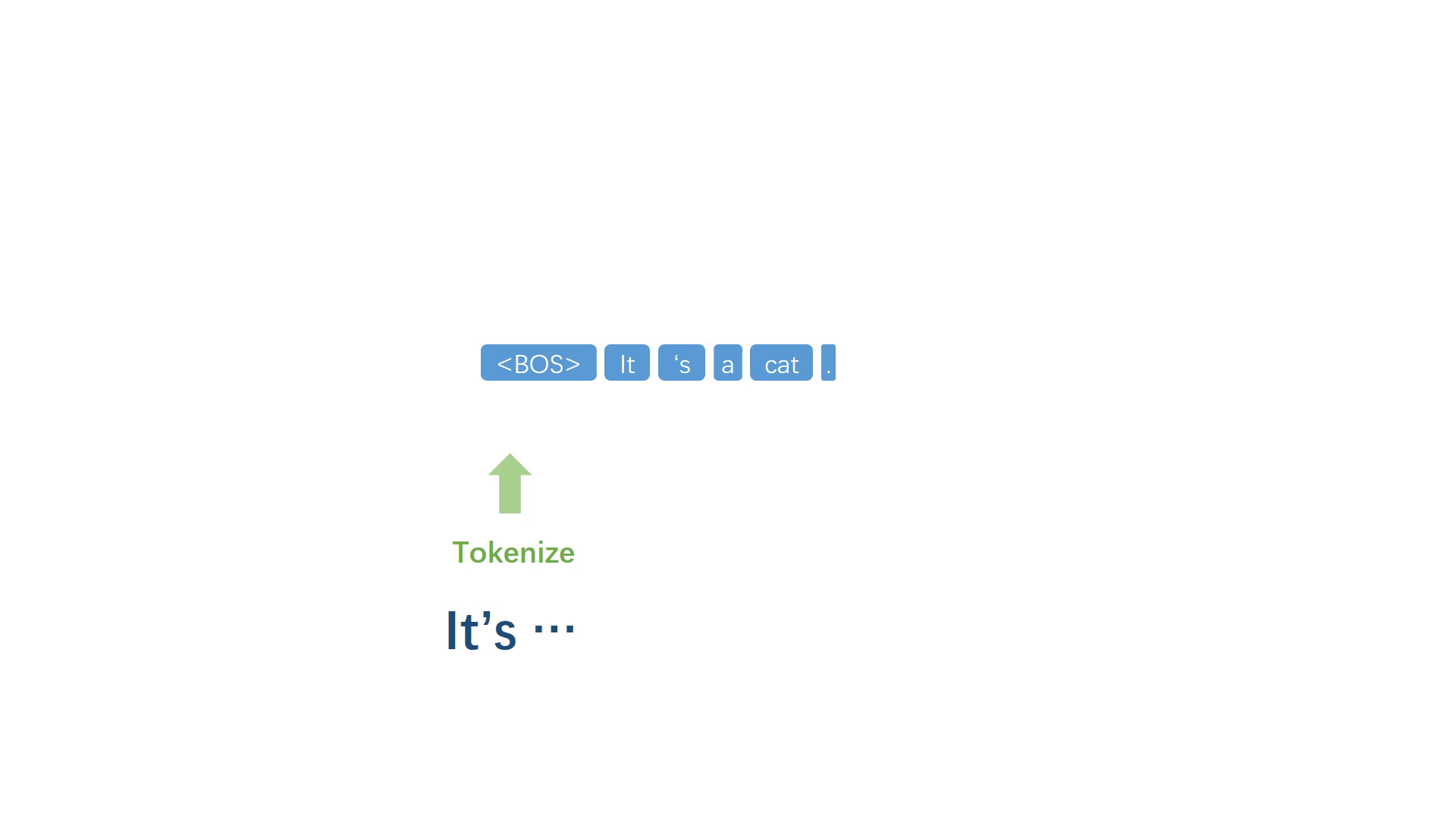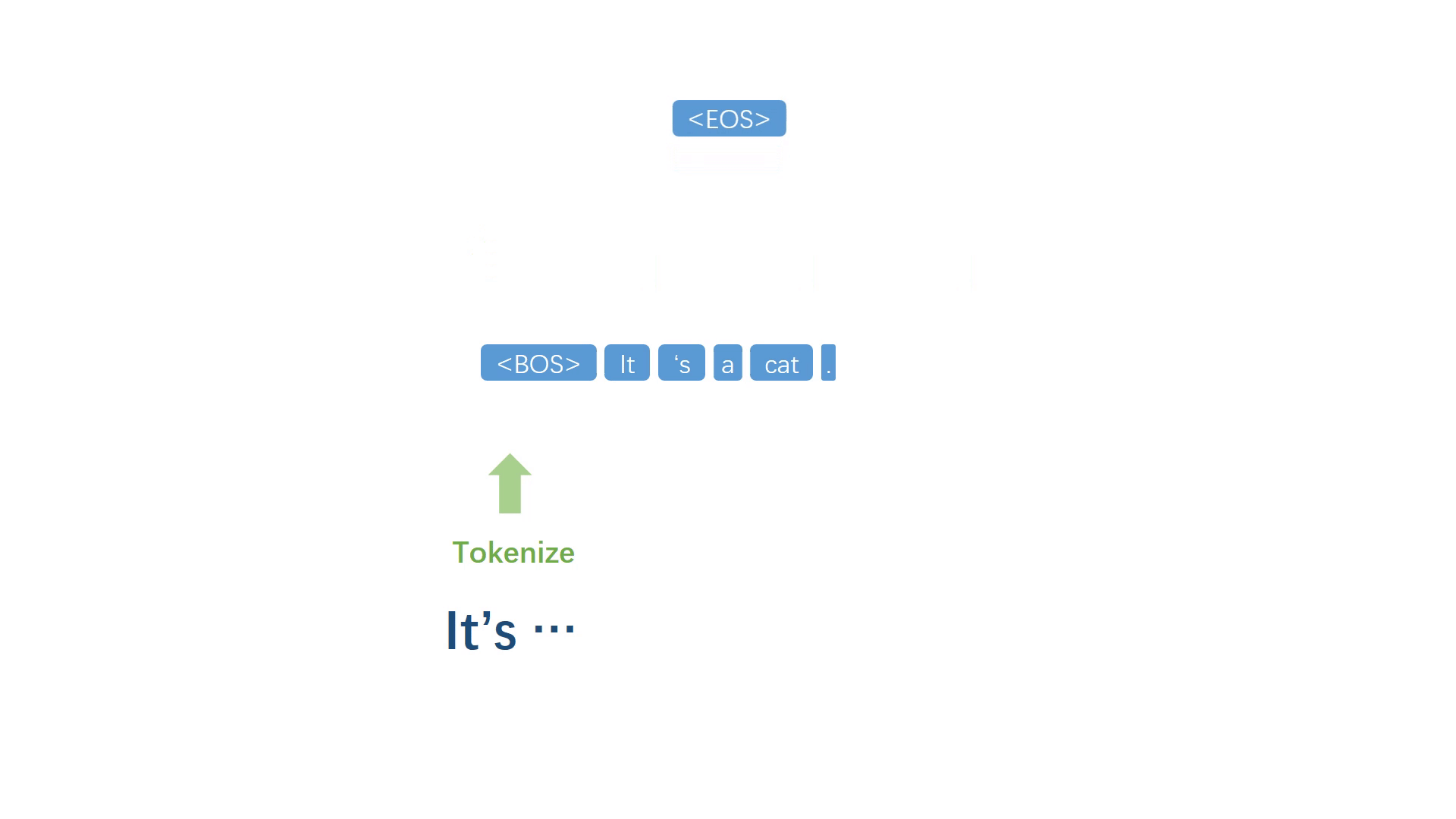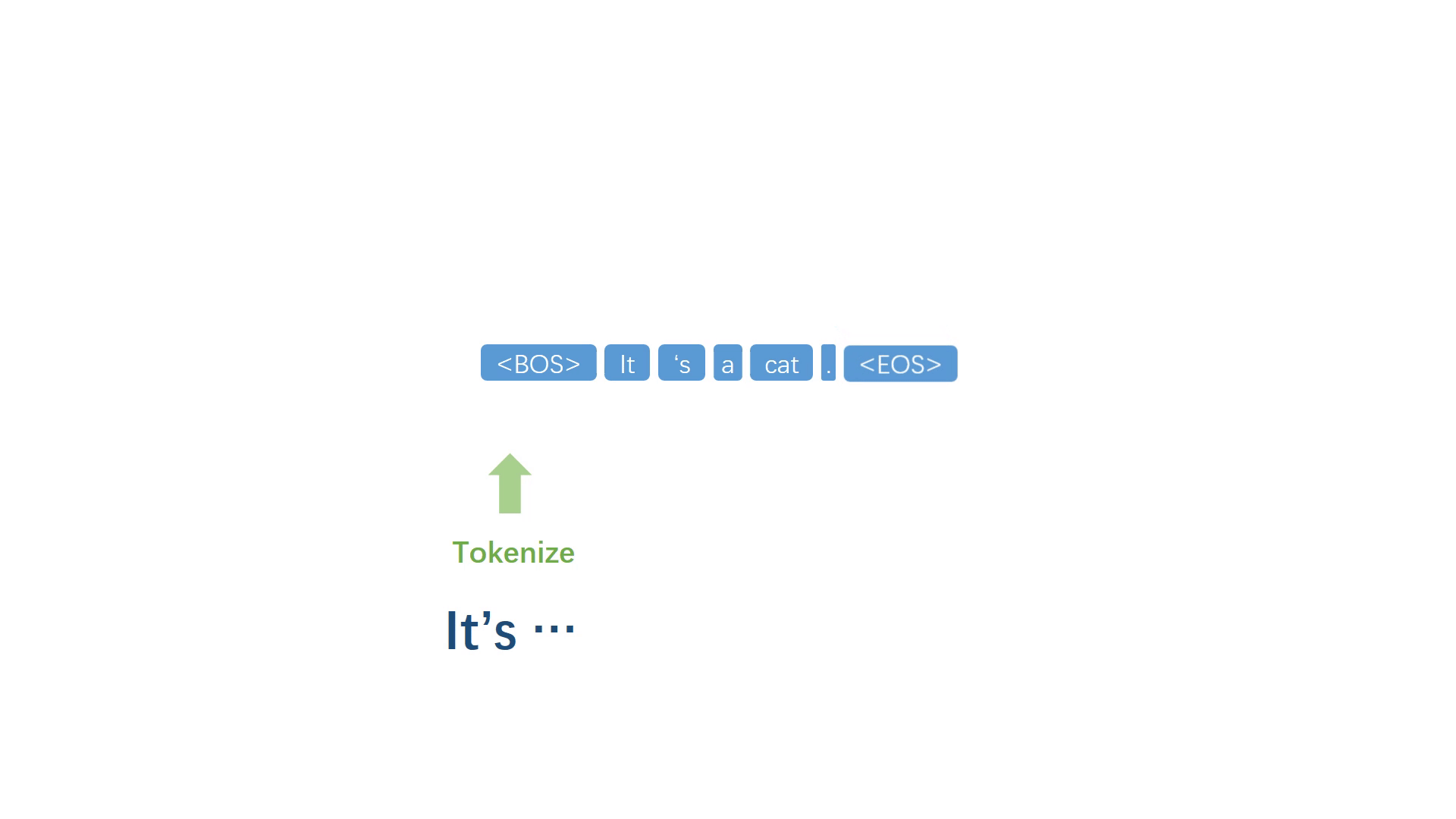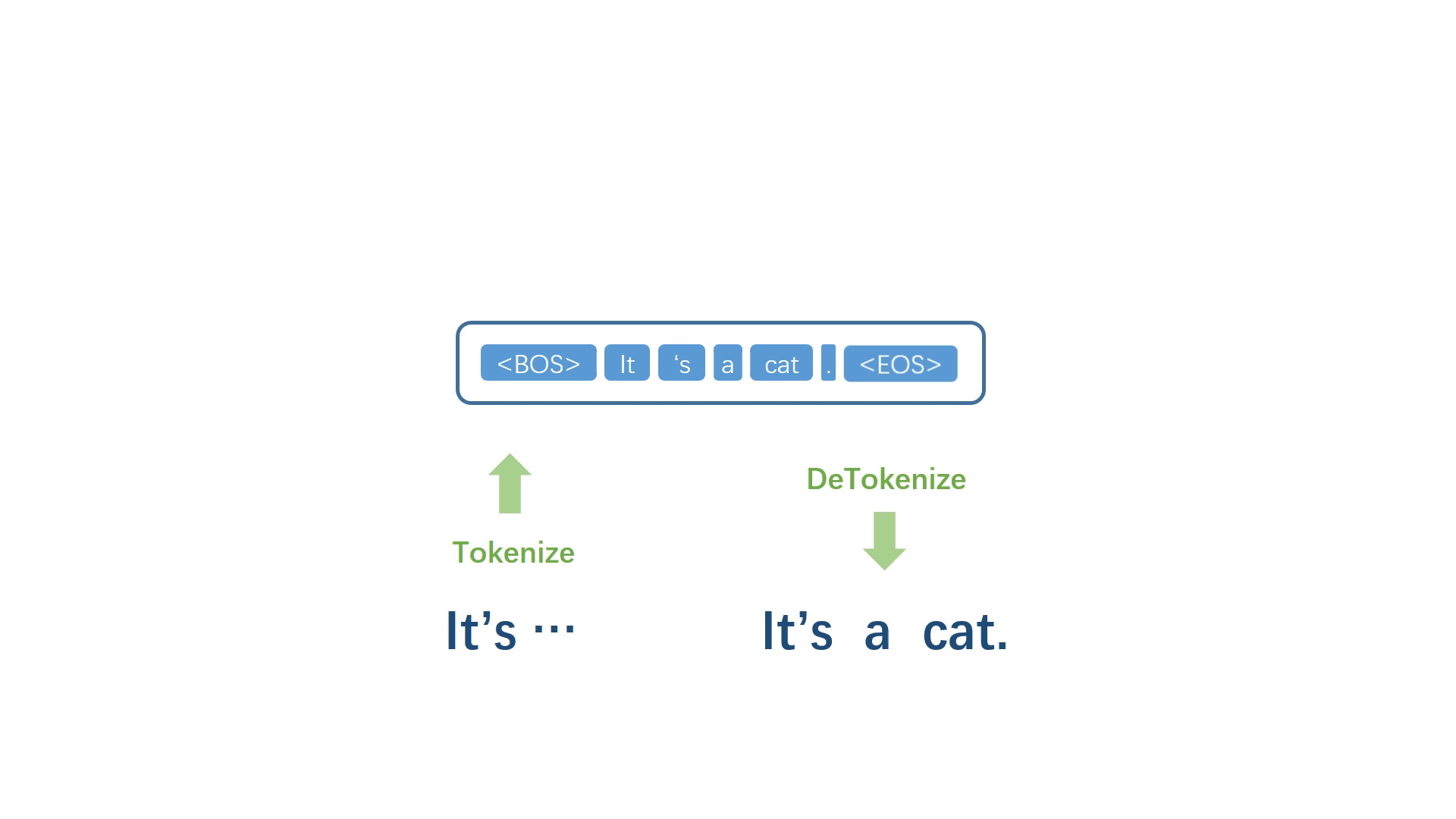
当代表句子终止的符号被模型选择出来之后,停止迭代过程,并进行反符号化处理,得到自然语句。
将人工神经网络引入语言模型,连续的向量可以相对平滑的概率替代粗糙的频率。
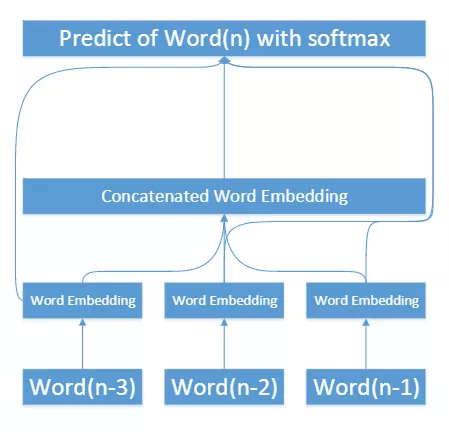
神经语言模型相比传统统计模型更能处理好常见词和罕见词的表示。

语言模型的变体:条件+语言模型=翻译模型

不同于语言模型生成器,一般的翻译模型拥有完整的源语言句子,我们将整个源文本进行符号化处理,并以一个固定的特殊标记作为翻译模型的开始符号。之后同样地,对这两个序列进行联合建模,得到概率最大的下一个译词。
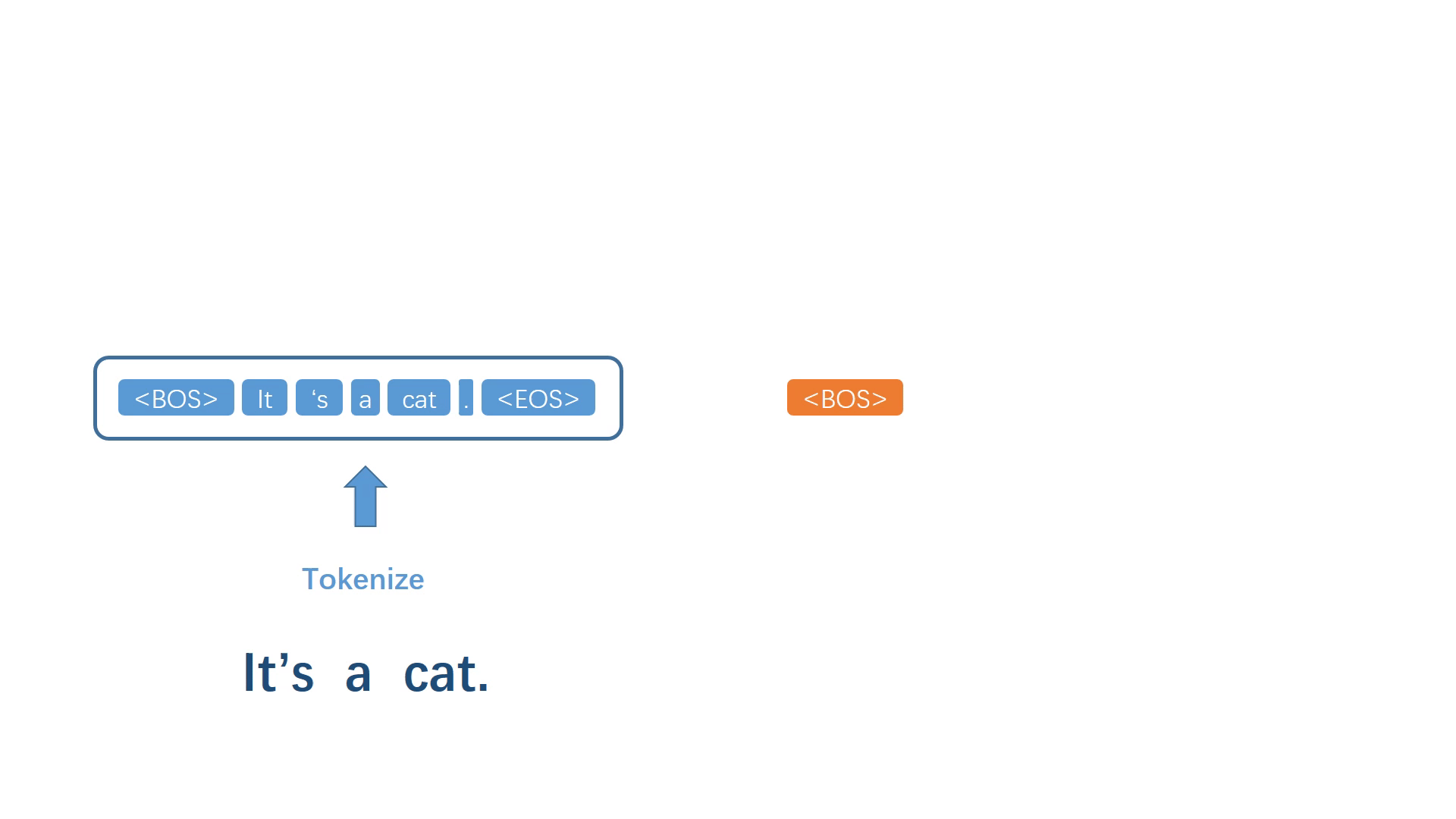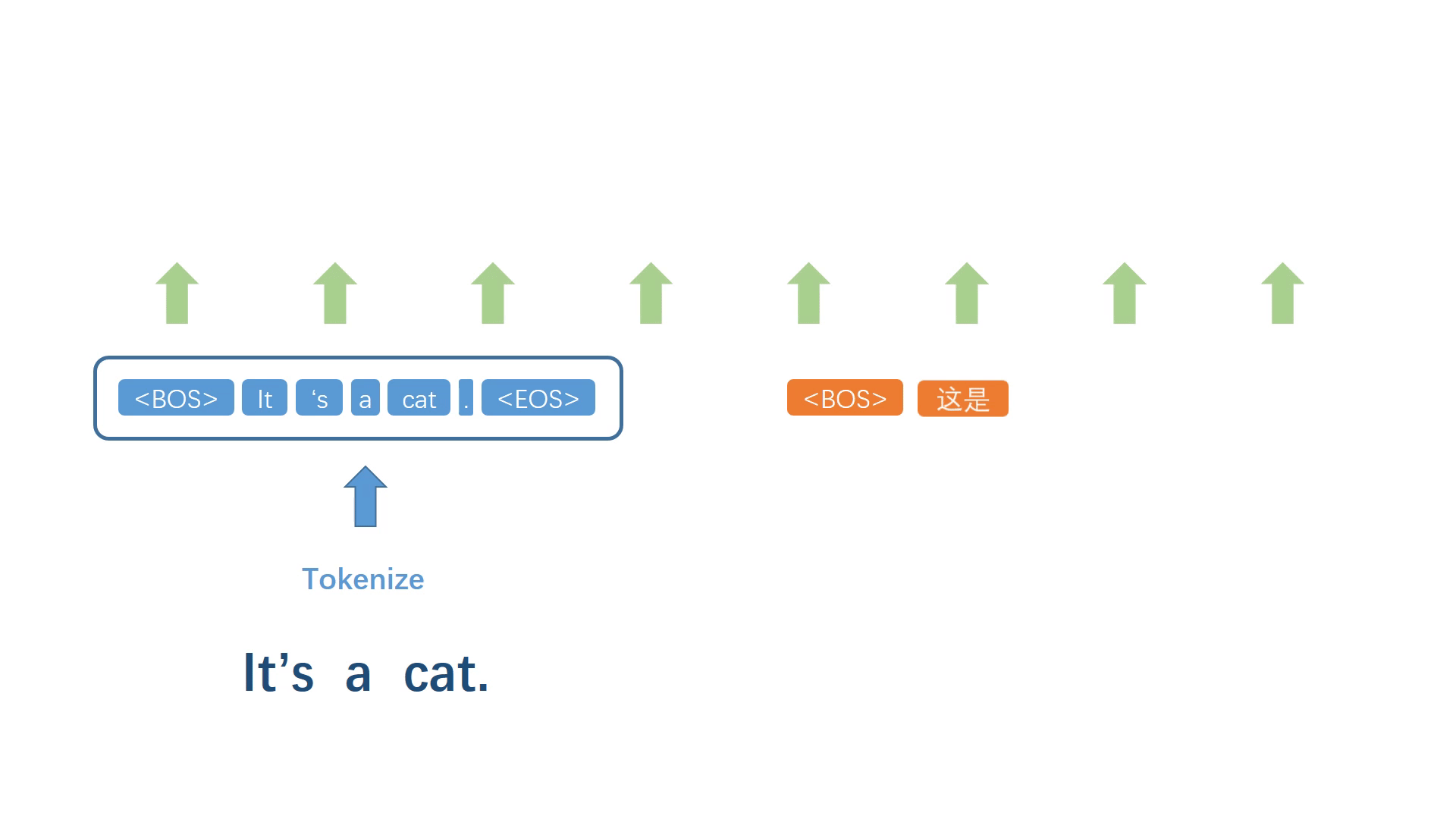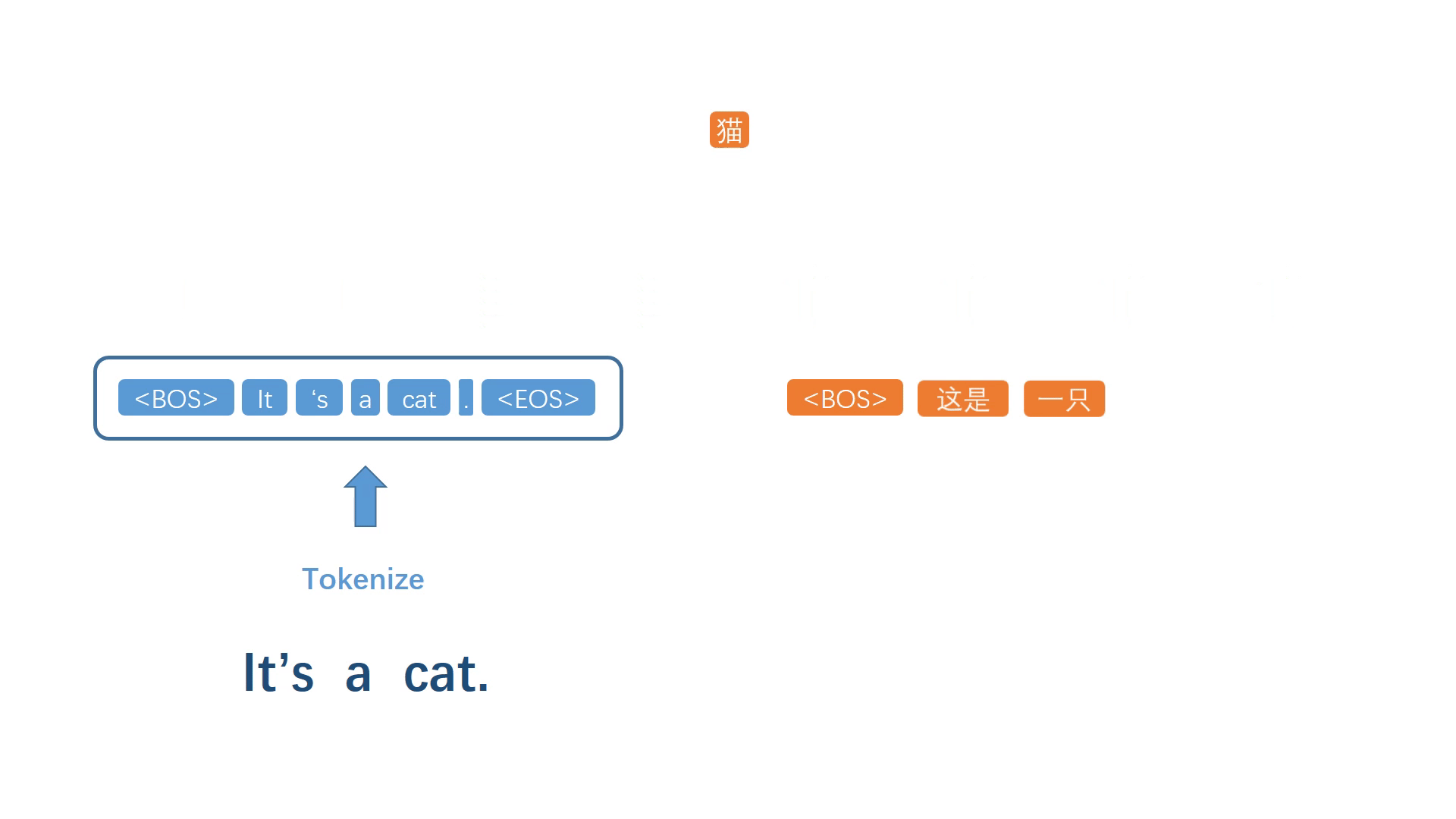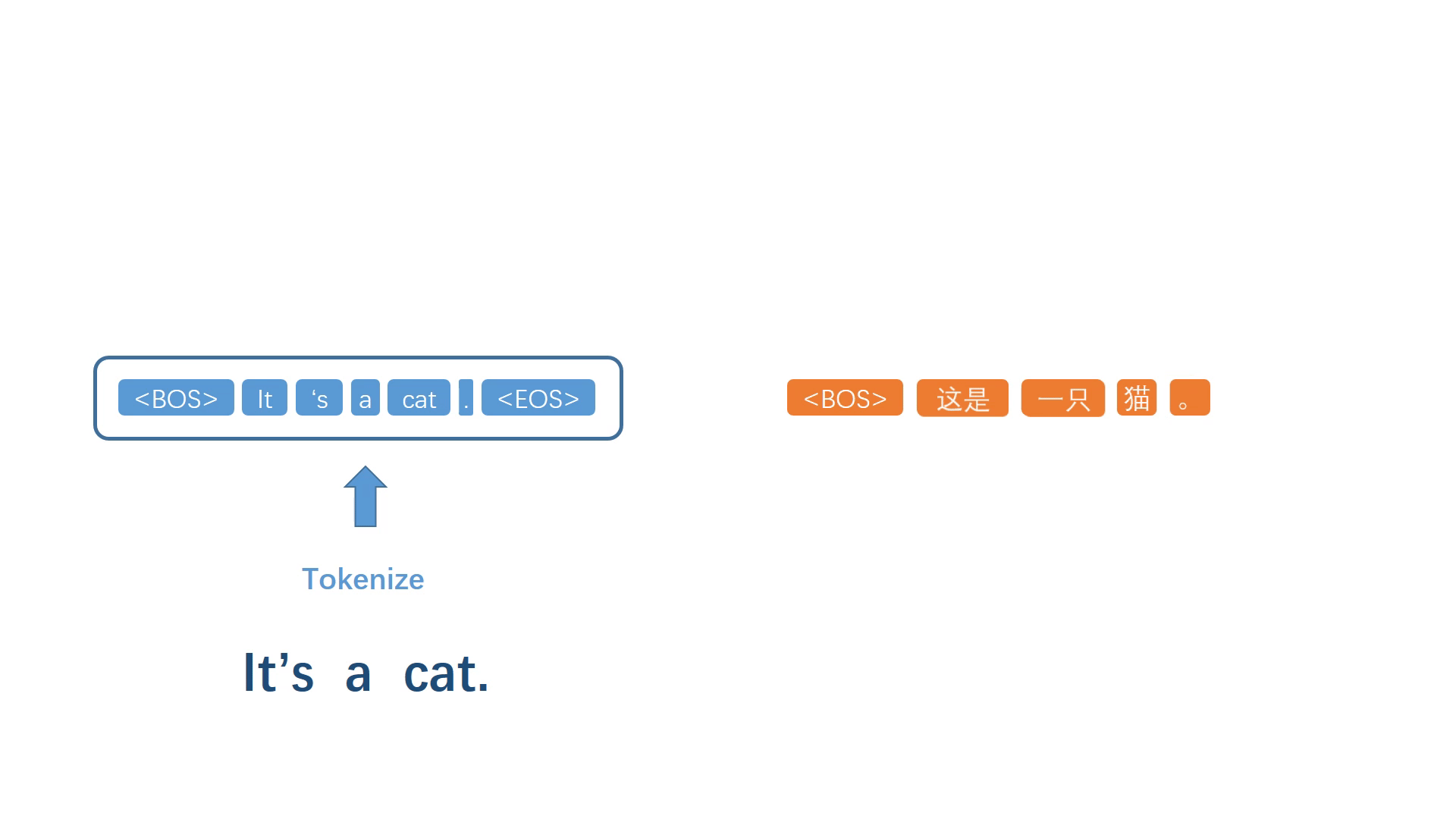
同样地,将生成的词加入译文序列,然后重复上述步骤反复迭代,不断生成之后的每一个译词。
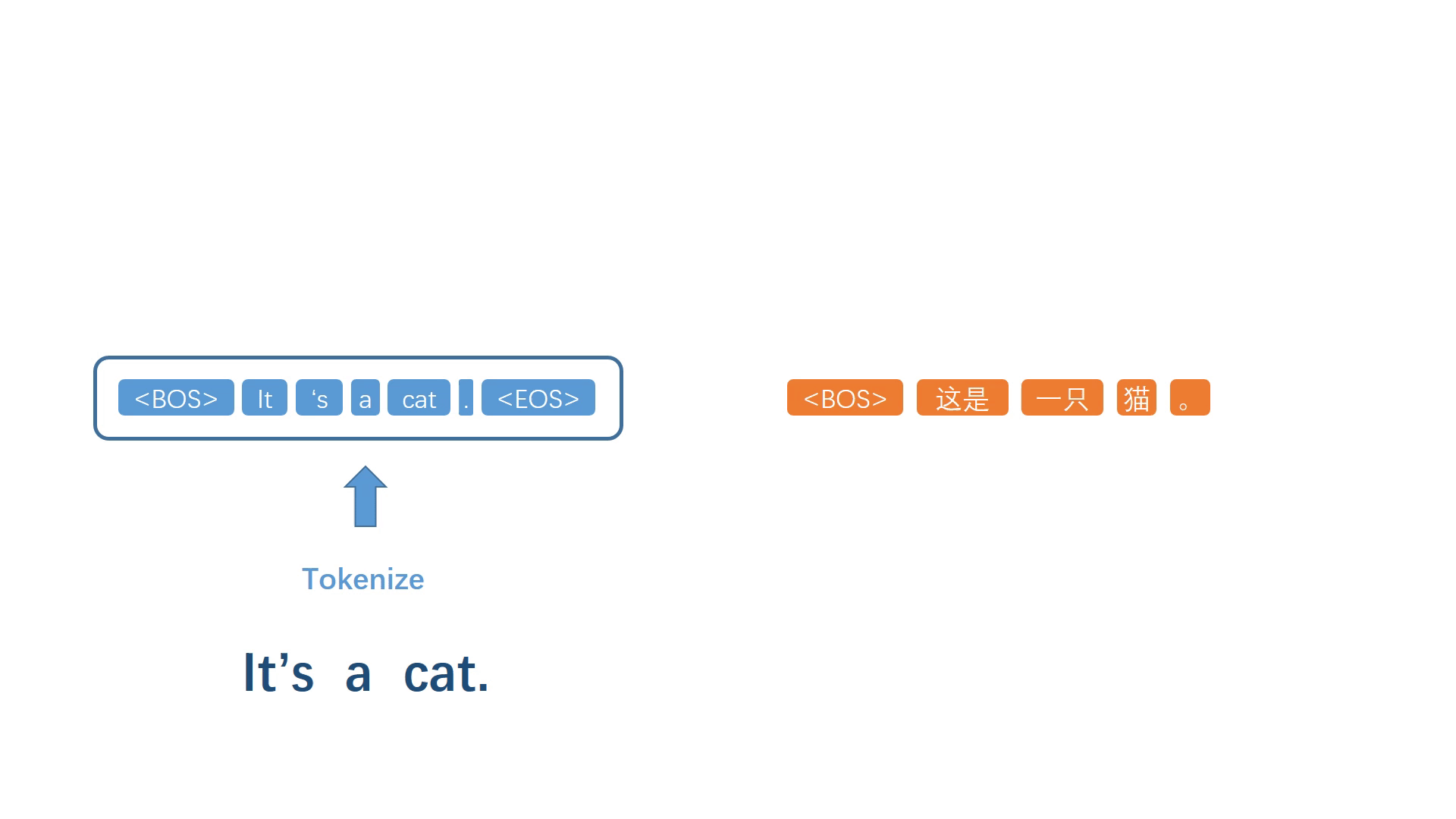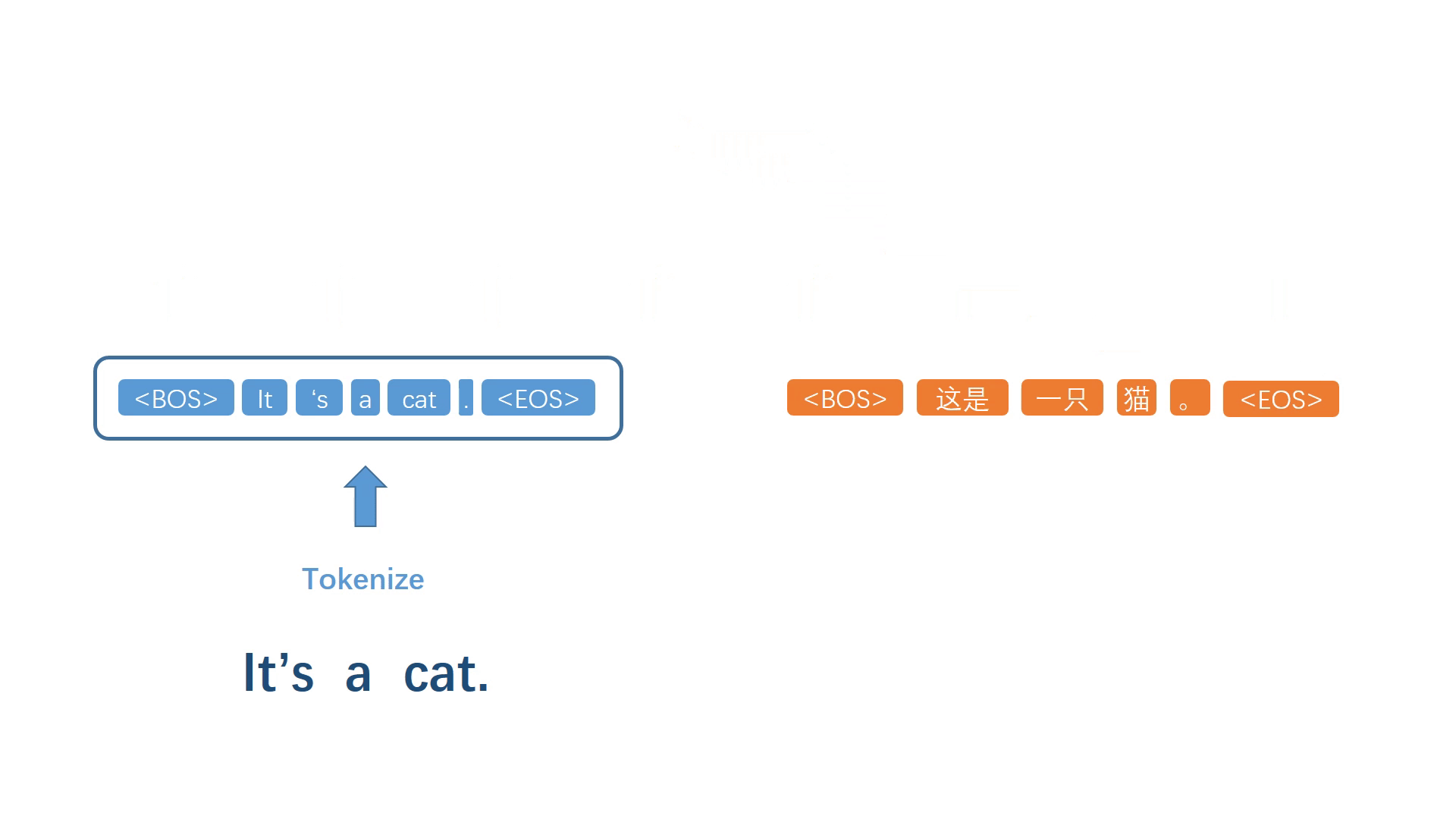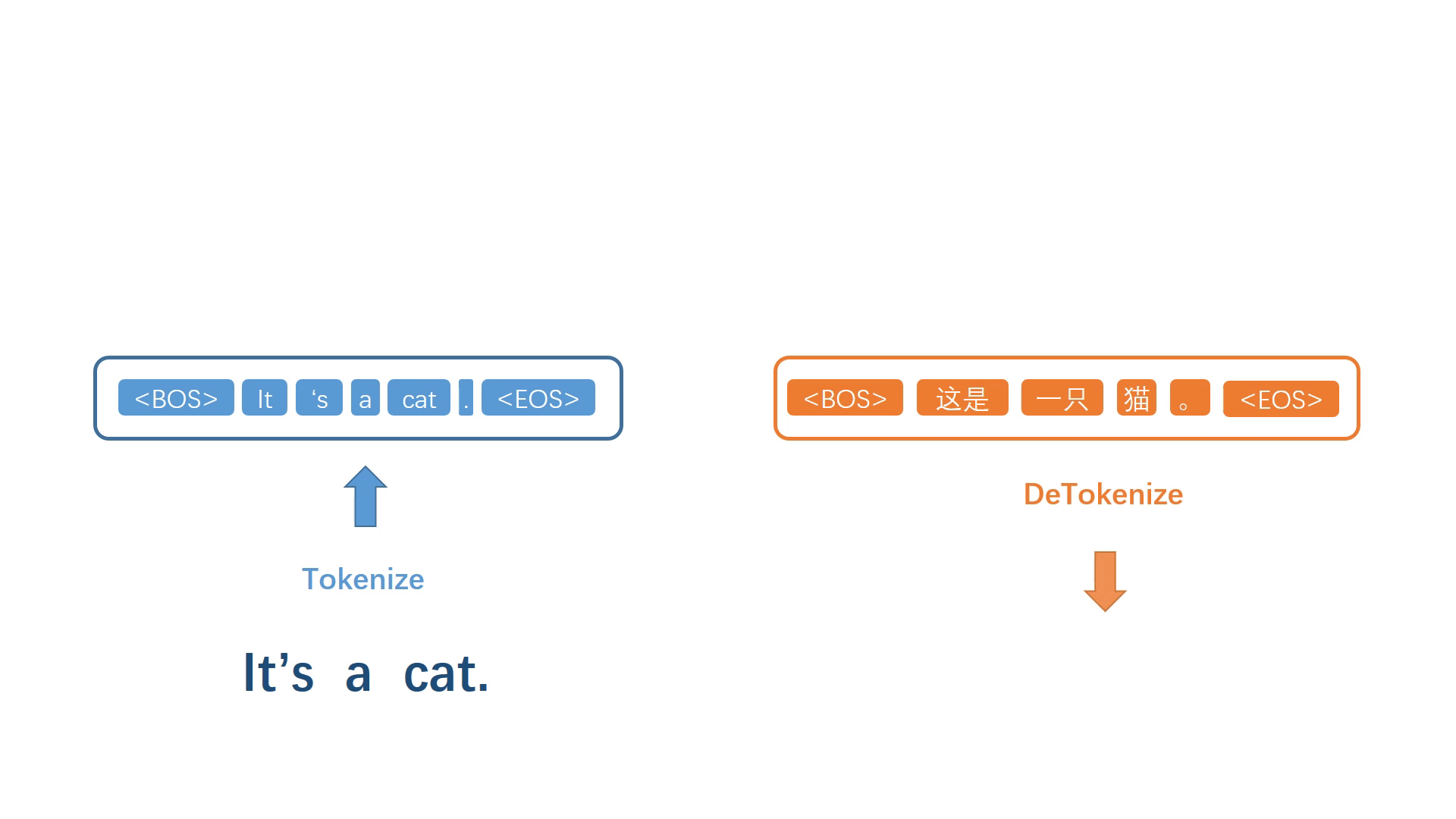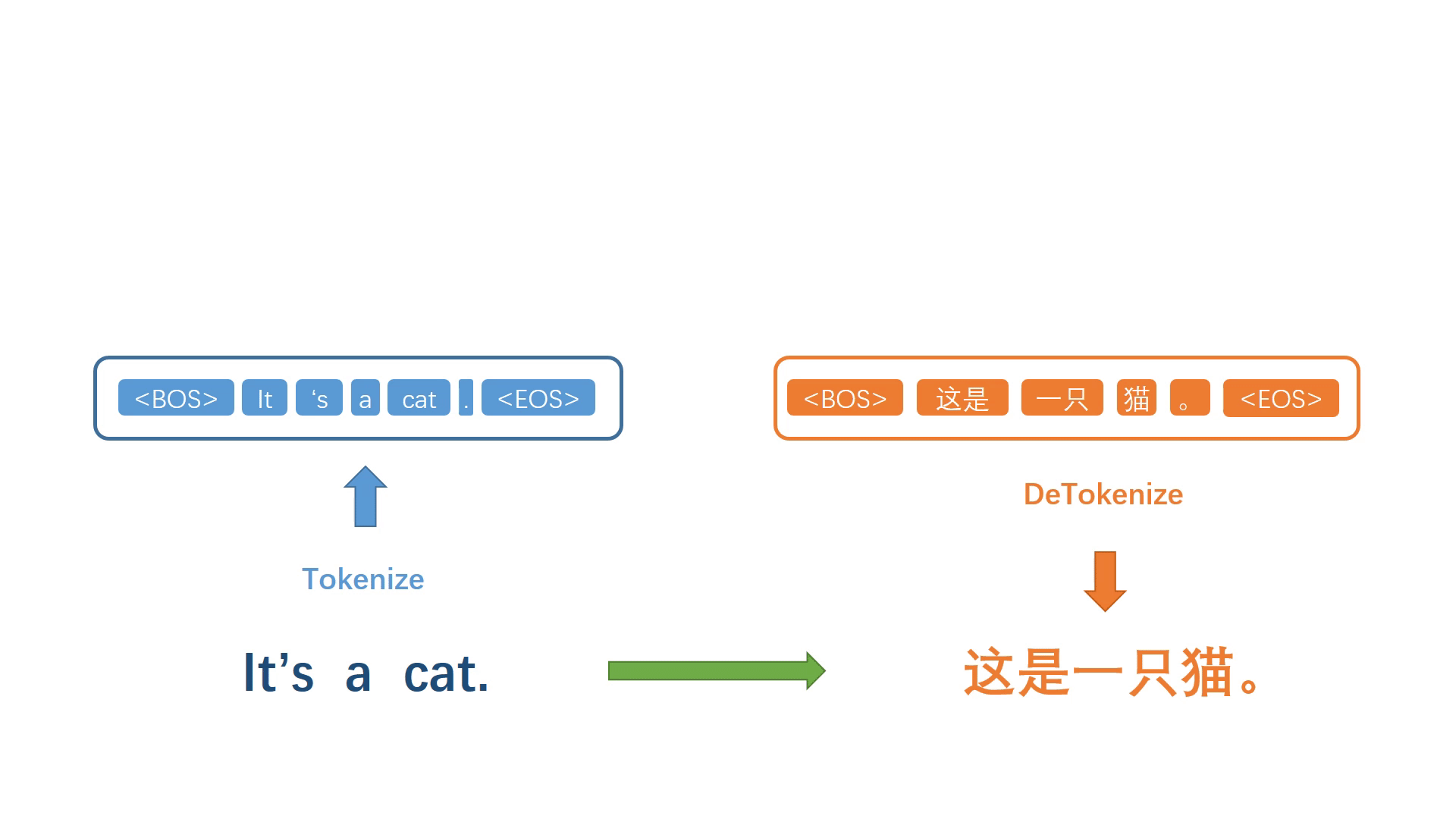
当代表句子终止的符号被模型选择出来之后,停止迭代过程,并进行反符号化处理,得到自然语句译文。
三、前沿进展
3.1 人工神经网络处理时序信息
循环神经语言模型可以适应任意长度的句子,模型的推导时间和句子长度正相关。
把句子中的词语想象为不连续的信号,随着信号的不断输入,网络会作出递归式的处理:不断累积信息并形成有价值的上下文记忆。
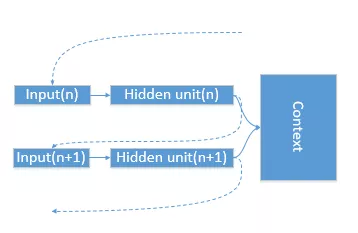
循环网络作为序列到序列预测模型内部的向量化机制。

左(单个 GRU 单元)、中(复用 GRU 单元在时序上建模)、右(端到端的翻译框架)
3.2 加入注意力机制
注意力机制源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他可见的信息。
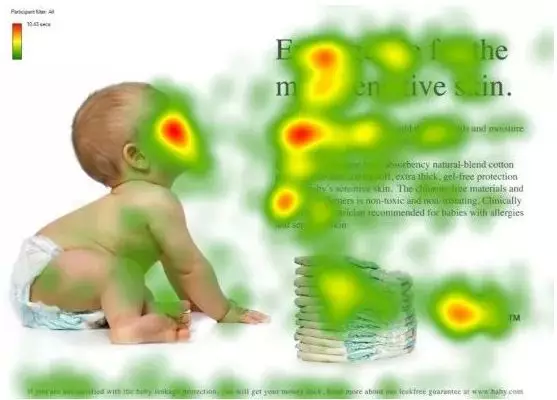
上图形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标,很明显对于上图所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
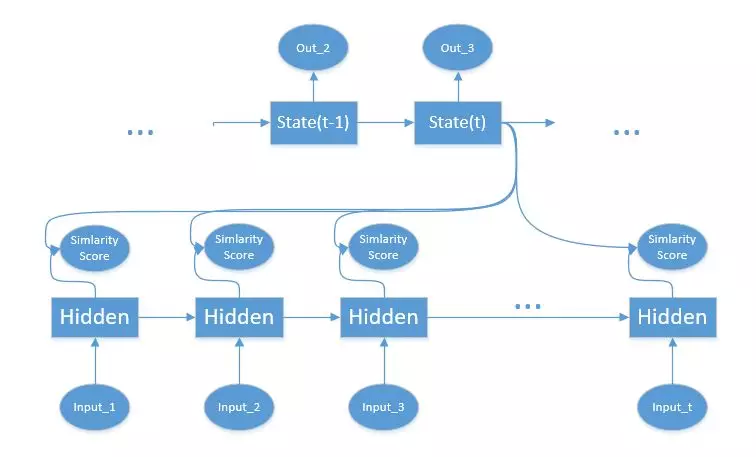
获取每个编码器隐藏状态的分数
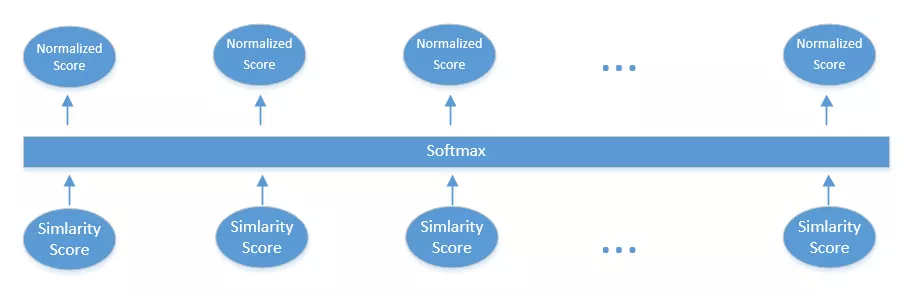
通过 softmax 层归一化所有分数
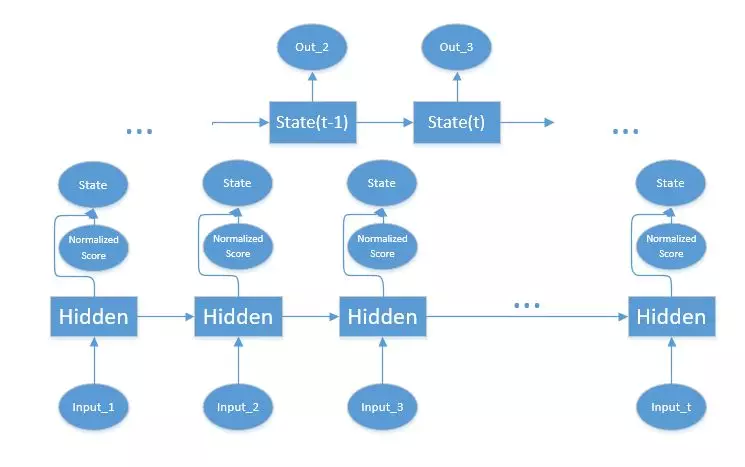
将每个编码器隐藏状态乘以其 softmax 归一化权重
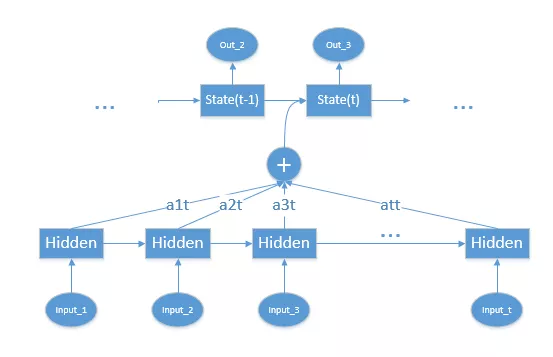
总结对齐向量作为上下文向量送到解码器,生成下一个词
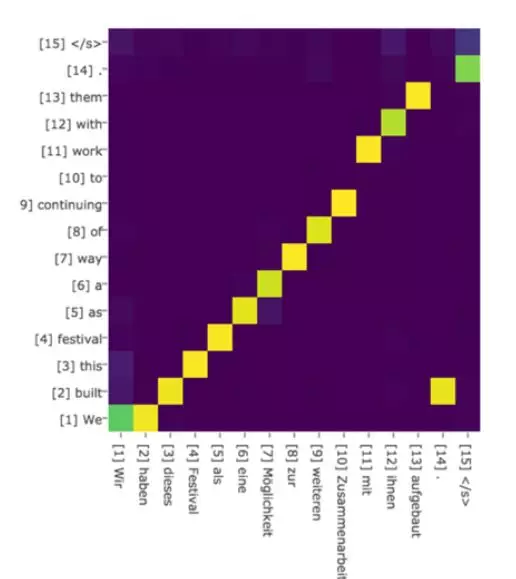
下图可视化地展示了在英语-德语翻译系统中加入 Attention 机制后,Source 和 Target 两个句子每个单词对应的注意力分配概率分布。
3.3 注意力机制的推广
Transformer 使得注意力机制应用在更广泛的模型上,并在翻译质量上取得了 State of the Art 的效果。

Self-attention 机制使得源序列或目标序列中的每一个 token 可以和自己所在序列的其他 token 计算相似度并提取必要的关联特征,整个过程是可以在句子维度上并行的。

四、实践经验
Transforer 性能优化
在模型推理阶段,目前主流的自回归翻译模型都是 Step by Step 预测的。每一个 Step 都需要前一个,数个或全部人工神经元状态。Transformer 的解码器的每一步运算都需要在之前的状态上做大量重复计算。
保留部分已计算的状态,在内存开销和计算开销中做 TradeOff,实现加速
Tensor2Tensor 给出了谷歌官方最初的 Transformer 开源实现,其中 vanilla-transformer 的推理 Cache 加速便是沿用了上述思想在长句推理上获得了将近 2 倍的提速。
是否使用 Cache 对 Transforer 性能的影响(数据来自 Tensor2Tensor 相关 Issue,考量了 BatchSize、SentenceLength、BeamSize 三个维度)
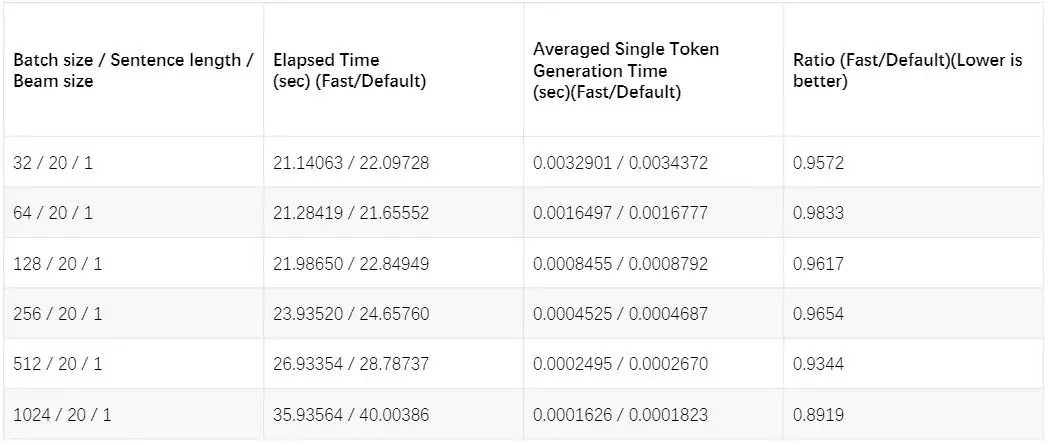
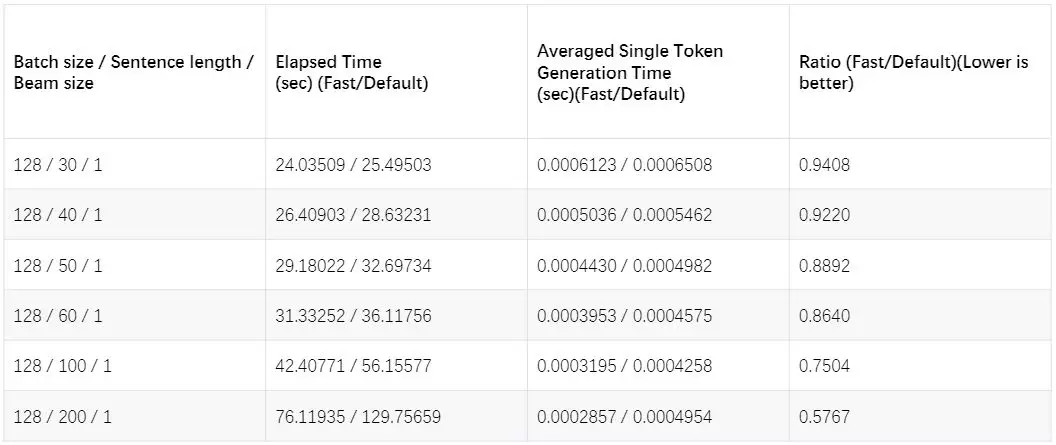
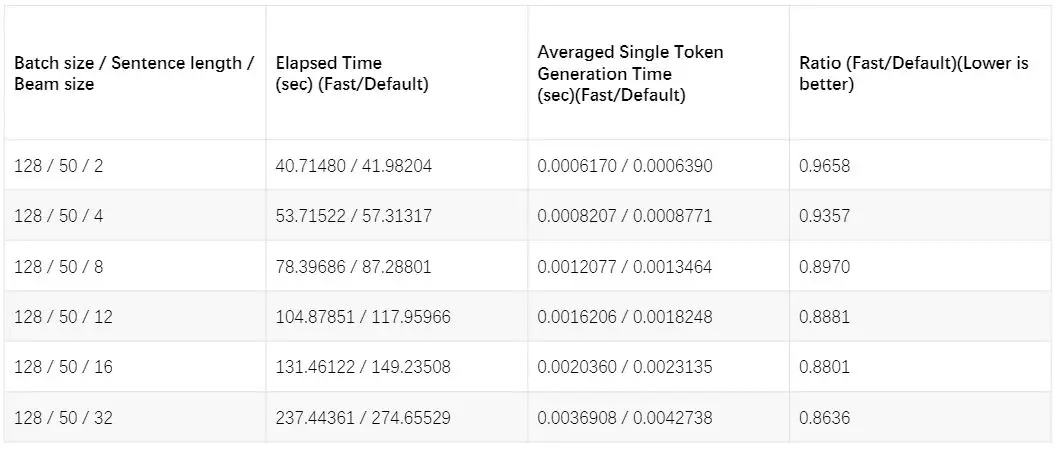
但是随着 Transformer 的改进版的出现,Cache 加速的 Trick 并没有及时推广到各个变种模型中去。实验发现,相对位置编码对于机器翻译的质量有一定提升作用,所以针对相对位置编码的变种 Transformer 实现 Cache 加速对于最终的模型迭代落地非常重要,在确保模型精度不变的前提下,线上的平均推理延迟经验证可降至 50%左右,相关的 PR 以及可视化方案已被合并入 Tensor2Tensor 的主分支。
五、不足与改进
目前的机器翻译技术尚不成熟,无论是文本翻译还是口语翻译,机器翻译的质量远没有达到令人满意的水平。
错翻,漏翻和重复翻译的情况在名称缩写、格式不统一、口语化表达等翻译场景时出现频率高,难以统一处理。
实现篇章级别的指代消解困难,如“美伊两国”可能会被模型识别为美国和伊拉克。
缺乏足够的在线优化能力,无法通过用户的有限反馈解决同一类问题,数据闭环效率低下。
但是,机器翻译依然能够替代那些任务重复性较大,翻译难度较低的任务,如:天气预报查询,旅馆预订服务,交通信息咨询等翻译。
为解决机器翻译过程中关键信息(如日期时间人名邮箱等)的准确翻译问题,我们在基本的机器翻译流程之上设计了外层 Pipeline。
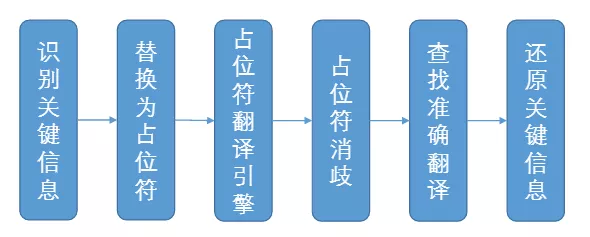
利用翻译模型注意力机制产生的中间结果设计了一套辅助指针网络来实现占位符翻译引擎,将关键信息按照词性分类替换后输入模型得到的译文极大地减少了这类信息的漏译和错译率。
随着技术框架的不断成熟,如何更高效得利用资源成为了学术和工业界新的挑战,包括低资源的学习、高并发或实时模型的设计、多语种大规模系统的建立等。同时,机器翻译技术的快速迭代也引发、带动了更多的思考与研究,包括上游模型的支持、下游应用的拓展、先验常识或领域知识的融合等,形成的一系列方法论不断地推动着人工智能在自然语言处理任务上的加速落地与完善。
作者介绍:
俞谦,携程度假大数据研发部算法工程师,主要负责机器翻译的研究与应用,目前专注于自然语言处理在垂域下的成熟解决方案。
本文转载自公众号携程技术(ID:ctriptech)。
原文链接:
https://mp.weixin.qq.com/s/AaaLSmIflM1wWy3bQ2ZDdw
公众号推荐:
2024 年 1 月,InfoQ 研究中心重磅发布《大语言模型综合能力测评报告 2024》,揭示了 10 个大模型在语义理解、文学创作、知识问答等领域的卓越表现。ChatGPT-4、文心一言等领先模型在编程、逻辑推理等方面展现出惊人的进步,预示着大模型将在 2024 年迎来更广泛的应用和创新。关注公众号「AI 前线」,回复「大模型报告」免费获取电子版研究报告。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论