

本文最初发表于 Towards Data Science 博客,经原作者 Rade Nježić 授权,InfoQ 中文站翻译并分享。
近十年来,随着深度学习的发现,图像分类领域经历了复兴。传统的机器学习方法已被更新的、更强大的深度学习算法所取代,例如卷积神经网络。然而,要真正理解并欣赏深度学习,我们必须知道为什么其他方法失败了,而深度学习却成功了。在本文中,我将试图通过对 Fashion MNIST 数据集应用不同的分类算法来回答其中一些问题。
数据集信息
Fashion MNIST 是由 Zalando Fashion 研究室于 2017 年 8 月推出的。随着 MNIST 变得过于容易和过度使用,Fashion MNIST 的目标是成为测试机器学习算法的新基准。MNIST 是由手写的数字组成的,而 Fashion MNIST 是由 10 个不同服装对象的图像组成的。每个图像都具有以下属性:
它的大小为 28 × 28 像素。
相应地旋转并以灰度表示,整数值范围为 0~255。
空白空间用黑色表示,值为 0。
在数据集中,我们区分以下服装对象:
T 恤/上衣
长裤
套衫
连衣裙
大衣
凉鞋
衬衫
运动鞋
手提包
短靴
探索性数据分析
由于数据集作为 Keras 库的一部分可用,并且图像已经经过处理,因此我们无需进行太多的预处理。我们所做的唯一更改是将图像从二维数组转换为一维数组,因为这样可以使它们更容易处理。
该数据集由 70000 幅图像组成,其中 60000 幅为训练集,10000 幅为测试集。与原始 MNIST 数据集一样,项目也是分布均匀的(每个训练集 6000 幅,测试集 1000 幅)。

不同服装项目的图片示例
然而,一张图片仍然有 784 个维度,因此我们转向主成分分析(Principal component analysis,PCA),看看哪些像素是最重要的。我们设定了累积方差的 80% 的传统基准,而该图告诉我们,只有大约 25 个主成分(占主成分总数的 3%)才有可能实现这一目标。然而,这并不奇怪,因为,我们可以在上面的图片中看到,在每幅图像中都有很多共享的未使用空间,并且不同类别的服装有不同的图像部分是黑色的。后者可能与以下事实有关:大约 70% 的累积方差仅由 8 个主成分解释。
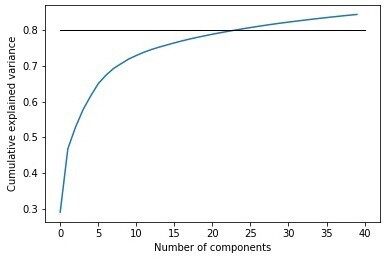
可解释的累积方差百分比
我们将在逻辑回归、随机森林和支持向量机中应用主成分。
图像分类问题只是分类问题的一个小子集。最常用的图像分类方法是深度学习算法,卷积神经网络就是其中之一。其余采用的方法将是一小部分常用分类方法的集合。由于分类标签是均匀分布的,没有错误分类的惩罚,故我们将使用正确率来评估算法。
卷积神经网络
我们采用的第一种方法是卷积神经网络。由于图像是灰度图像,因此我们仅应用一个通道。我们选择了以下架构:
两个卷积层,具有 32 和 64 个过滤器(Filter),3 × 3 内核大小,以及 ReLU 激活函数。
选择轮询层对大小为 2 × 2 的块进行操作,并从中选择最大的元素。
两组密集层,其中第一层选择 128 个特征,具有 ReLU 或 Softmax 激活函数。
这种架构并没有什么特别之处。事实上,它是我们可以用于卷积神经网络的最简单的架构之一。这向我们展示了这类方法的真正威力:使用基准结构可以获得很好的结果。
对于损失函数,我们选择了分类交叉熵(Categorical cross-entropy)。为避免出现过拟合,我们从训练集中选择了 9400 幅图像作为参数的验证集。我们使用了新颖的优化器 ADAM,它比标准的梯度下降法有所改进,并且对每个参数使用不同的学习率,批大小为 64。该模型训练了 50 个轮数。我们在下图中给出了正确率和损失值。
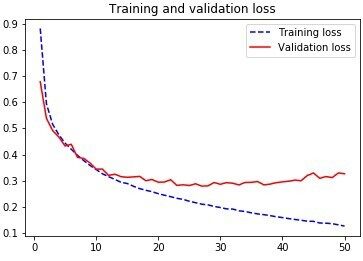
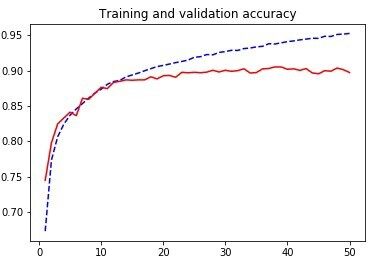
我们可以看到,该算法训练 15 个轮数后出现收敛,但并没有过度训练,所以我们对其进行了测试。得到的测试正确率为 89%,这是所有方法中得到的最好的结果!
在继续其他方法之前,让我们先解释一下卷积层是做什么的。直观的解释是,第一层捕获直线,第二层捕获曲线。在这两个层上,我们都应用了最大池化(Max pooling),即在内核中选择最大的值,将服装部分与空白空间分开。如此一来,我们就抓住了数据的代表性。在其他方面,神经网络自己进行特征选择。经过最后一个池化层,我们就得到了一个人工神经网络。因为我们要处理的是分类问题,因此最后一层使用 Softmax 激活来获得类别概率。当类别概率遵循一定的分布时,交叉熵表示与网络首选分布的距离。
多分类逻辑回归
由于像素值是分类变量,因此我们可以应用多分类逻辑回归(Multinomial Logistic Regression)。我们以一对余的方式应用它,训练 10 个二元逻辑回归分类器,我们将使用这些分类器来选择项目。为避免过度训练,我们使用了 L2 正则化。结果我们得到了 80% 的正确率,比卷积神经网络的正确率低 9%。但是,我们必须考虑到,该算法适用于灰度图像,这些图像是居中且正常旋转的,有很多空白的地方,因此它可能对更为复杂的图像不起作用。
近邻算法和质心算法
我们使用了两种不同的最近距离算法:
K-最近邻算法
近质心近邻算法
近质心近邻算法找出每个类别的元素的平均值,并将测试元素分配给最近质心指定的类别。这两种算法都是相对于 L1 和 L2 距离实现的。K-最近邻算法的正确率为 85%,近质心近邻算法的正确率为 67%。这些结果是在 K=12 时得到的。K-最近邻算法的高正确率告诉我们,属于同一类别的图像往往占据相似的位置,也有类似的像素密度。虽然最近邻算法获得了很好的结果,但它们的表现仍然比卷积神经网络要差,因为它们不在每个特定特征邻近工作;而质心算法失败了,因为它们并不能区分相似的对象(例如套衫与 T 恤/上衣)。
随机森林
为了选择最佳的参数进行估计,我们使用平方根(Bagging)和特征的全部数量、Gini 和熵准则,以及树的最大深度为 5 和 6 进行网格搜索。网格搜索建议使用熵准则的特征平方根数(均适用于分类任务)。然而,得到的正确率仅为 77%,这意味着随机森林方法也不是什么特别好的方法。它失败的原因是主成分并不能代表图像可以具有的矩形分区,而随机森林就是在该矩形分区上操作的。同样的道理也适用于全尺寸图像,因为树会太深,可解释性将会失去。
支持向量机
我们使用径向核和多项式核的支持向量机。径向核的正确率为 77%,而多项式核的正确率仅为 46%。虽然图像分类并不是它们的强项,但对于其他二值分类任务仍然非常有用。它们最大的警告是,它们需要特征选择,而这会降低正确率;但如果没有特征选择,它们的计算成本可能会很高。此外,它们以一对余的方式应用多类分类,这使得更难有效地创建分离超平面(Separating hyperplane),因此在处理非二元分类任务时失去价值。
总结
我们在本文中,针对一个图像分类问题,采用了多种分类方法。我们已经解释了为什么卷积神经网络是我们可以采用的最好的方法,而其他方法为什么会失败。卷积神经网络是最为实用且通常最为正确的方法的一些原因如下:
它们可以通过层传递学习,保存推理并在后续层上创建新的推理。
在使用该算法之前,无需进行特征提取,而是在训练过程中完成的。
它可以识别重要的特征。
但是,它们也有自己的警告。目前已知它们在旋转和缩放方式不同的图像上会失效,但这里的情况并非如此,因为数据已经经过预处理。而且,尽管其他方法在这个数据集上未能提供良好的结果,但它们仍然可以用于其他与图像处理相关的任务(如锐化、平滑等等)。
代码:
https://github.com/radenjezic153/Stat_ML/blob/master/project.ipynb
原文链接:
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


InfoQ高级技术编辑

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论