

9 月 7 日,云+社区(腾讯云官方开发者社区)主办的技术沙龙——AI 技术原理与实践,在上海成功举行。现场的 5 位腾讯云技术专家,在现场与开发者们面对面交流,并深度讲解了腾讯云云智天枢人工智能服务平台、OCR、NLP、机器学习、智能对话平台等多个技术领域背后架构设计理念与实践方法。本文内容整理自腾讯云资深技术专家黄文才,从云智天枢平台的整体架构出发,揭秘 AI 在 K8S 中的实践经验,为大家带来“云智天枢 AI 中台架构及 AI 在 K8S 中的实践”的分享。
本文主要分三大块:
第一,云智天枢平台架构。
第二,各核心窗口的架构设计。
第三,AI 在 K8S 中的实践经验。
云智天枢平台架构
云智天枢平台是支持快速接入各种算法、数据和智能设备,并提供可视化的编排工具进行服务和资源的管理和调度。进一步通过 AI 服务组件持续集成和标准化接口开放,帮助开发者快速构建 AI 应用。

总的来说,平台的定位是全栈式人工智能服务平台,实现与应用、算法、设备等合作伙伴共赢,合作伙伴只需要实现应用层逻辑。
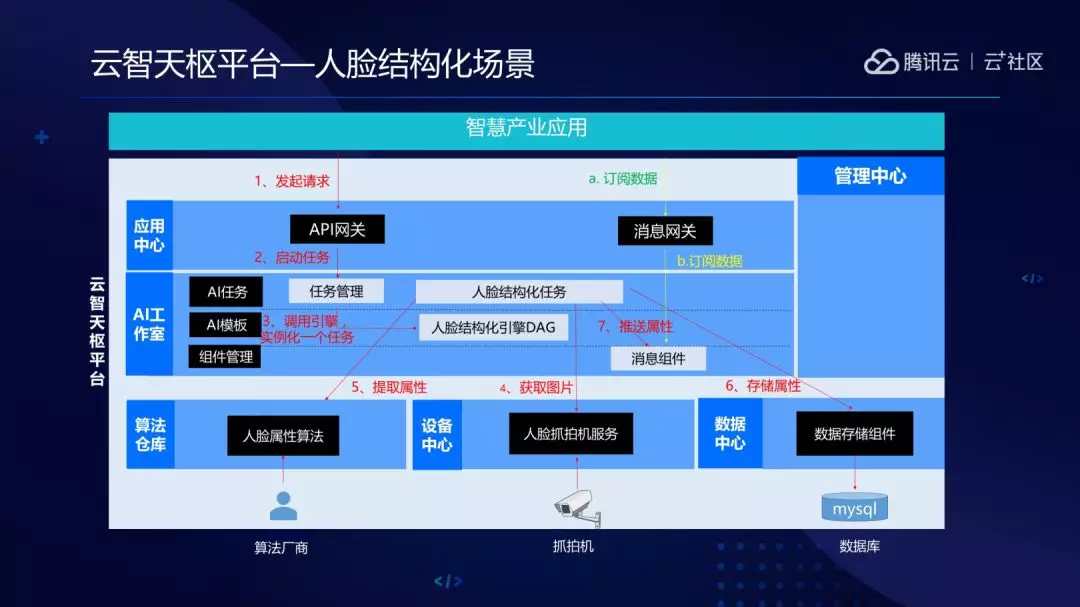
以人脸结构化场景的例子,讲述一下云智天枢平台的大概功能。应用会通过 API 网关调用任务管理,任务管理服务创建和启动任务。任务管理器根据负载均衡等策略,根据人脸结构化引擎,去实例化一个人脸结构化任务。人脸结构化任务首先会通过设备中心的人脸抓拍机服务获取图片,然后调用人脸属性服务提属性,同时会把结构化数据通过数据中心落地,并把结构化数据推送到消息组件。应用可以通过消息网关去订阅这些任务跑起来后源源不断的结构化数据。
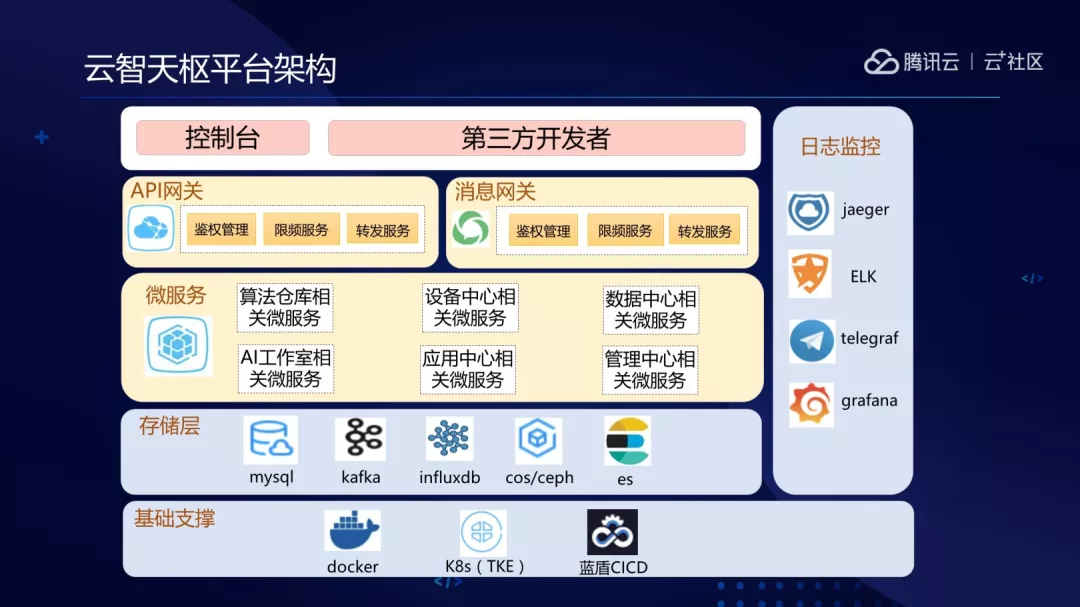
我们平台其实是典型的三层架构。
从下往上看,基础设施是基于 Docker、 K8s、 蓝盾 CICD。
最下层是存储层,用到了一些组件 MySQL、Kafka、influxdb、cos/ceph、es 等。因为目前主要是做私有化,公司组件或者云上组件都没法用,所以会用开源的组件搭建起来。
中间层是微服务,分为 6 大块:
(1)算法仓库:主要提供自助接入、自助打镜像的能力,可快速把可执行程序的安装包、模型文件等容器化为算法服务。目前接入算法种类 50+,涵盖人脸,车辆,语音,文字,语义等。
(2)设备中心:做了设备自助接入平台,主要对接各个厂商的各个型号的设备,比如普通摄像机、抓拍机、AI 相机等等。设备是平台比较重要的数据来源。
(3)数据中心:主要负责平台数据接入、推送、转换、存储等,同时负责屏蔽私有化项目的结构化与非结构化数据存储介质的差异。
(4)AI 工作室:主要实现了任务调度,流程与服务的编排能力。已经沉淀行业应用 12+,通用组件 30+;
(5)应用中心:主要是创建应用、密钥、订阅管理,视图库等能力;
(6)管理中心:主要是账号系统、角色权限、镜像仓库、操作日志等能力。各个窗口之间是有联动的,通过消息队列 Kafka 来解耦。
最上层是网关,网关分两块:
(1)API 网关,采用的是腾讯云 API3.0 的标准。网关主要做鉴权、限频、转发等功能。
(2)消息网关,支持 GRPC 和 HTTP 推送能力。监控系统用了 Telegraf、influxdb 和 grafana,日记系统用了 ELK。
各核心窗口的架构设计
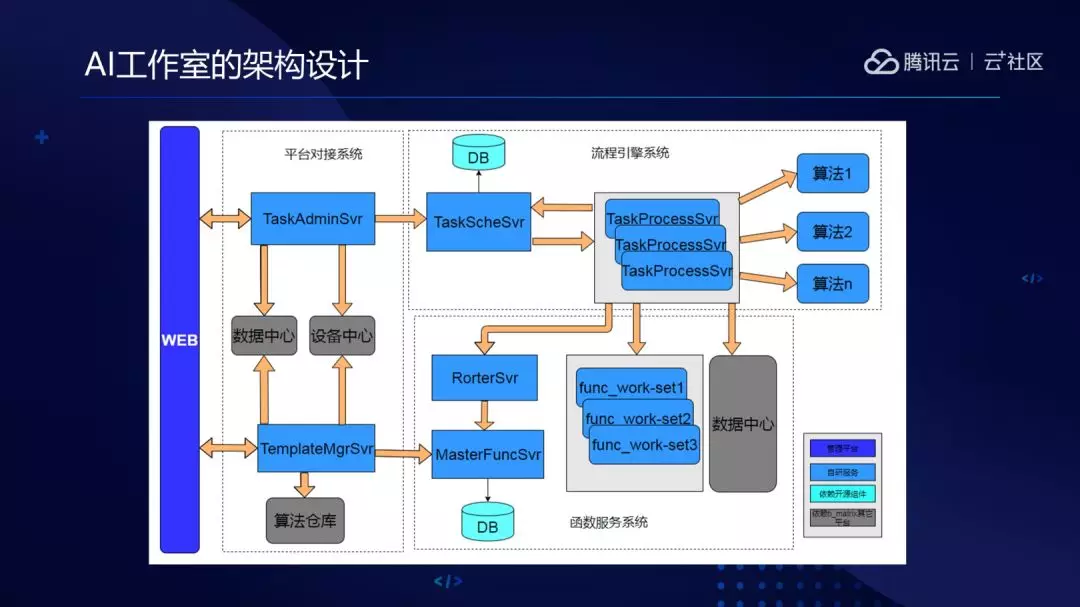
1.AI 工作室主要由三大块组成:
(1)平台对接系统;
(2)流程引擎系统;
(3)函数服务系统。
这里实现了流程与服务的编排能力。平台系统主要是打通和平台的各个窗口能力,比如说数据中心、设备中心等窗口的联动。函数服务用 Python 写了函数服务,负责执行 Python 代码段。因为流程服务编排的过程中 A 服务的输出不一定满足下一个节点 B 服务的输入,所以要做数据转换,这一块儿交给了函数服务来做。
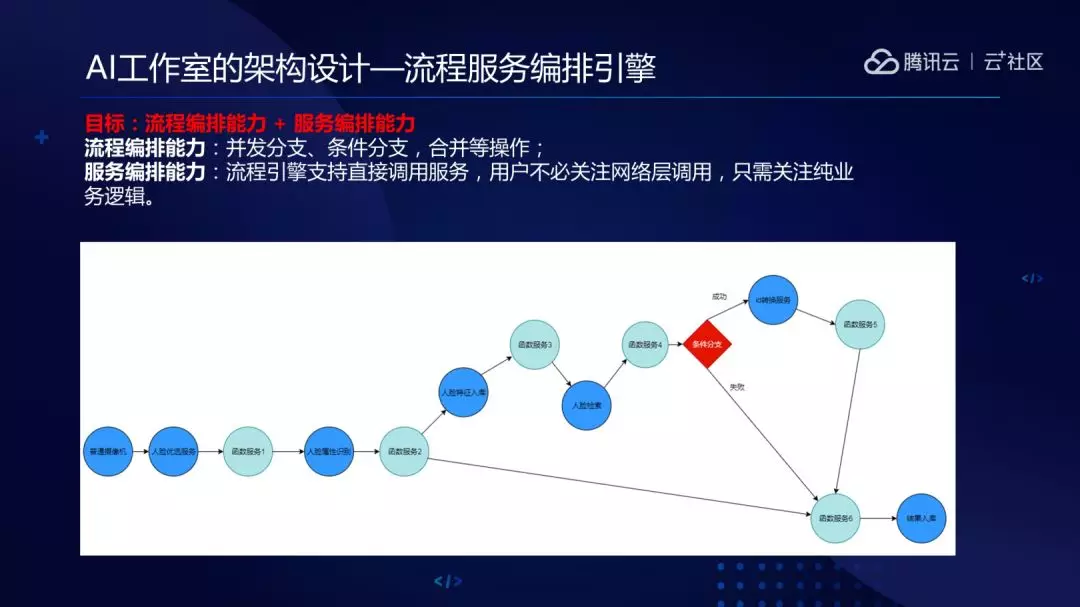
平常我们在开发业务功能过程中会经常写一些相似的代码逻辑,比如调用 A 服务,A 服务回来之后会做数据处理,处理完以后会并发掉 BC 服务,之后等 BC 服务回包后再做数据处理,这一块儿有很多相似的业务逻辑,我们进行了抽象并实现了流程和服务的编排能力。
流程编排能力实现了并发分支、条件分支、合并分支等功能。服务编排方面支持直接调用服务,可以不用关心网络层的调用,只需要写 A 服务和 B 服务之间数据转换 Python 几行代码转换就好。
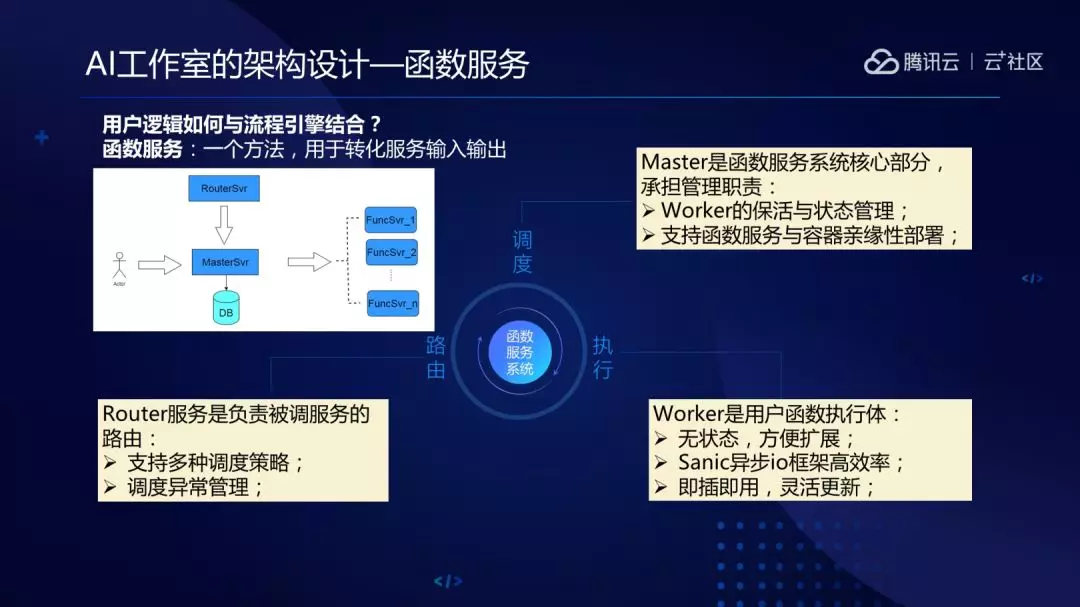
函数服务是为了解决 A 服务的输出和下游 B 服务的输入不太满足,所以可能会做一些数据转换,也是抽象出来让用户合作伙伴可以写几行 Python 代码,就可以把流程打通。函数也做了安全措施,比如说 Python 的 sys、commands 等 package 会不让用,我们可以静态动态扫描。
2.算法接入过程中通常会遇到一些问题,算法种类可能比较多,对接厂商比较多、协议比较多,对接成本高。
制作镜像对于算法开发者来说会有一些门槛,比如说熟悉 Docker 命令等,所以有比较高的接入成本,我们做了接入平台统一镜像接入,通过页面操作可以让不懂 Docker 的人也能轻松地制作算法的微服务。
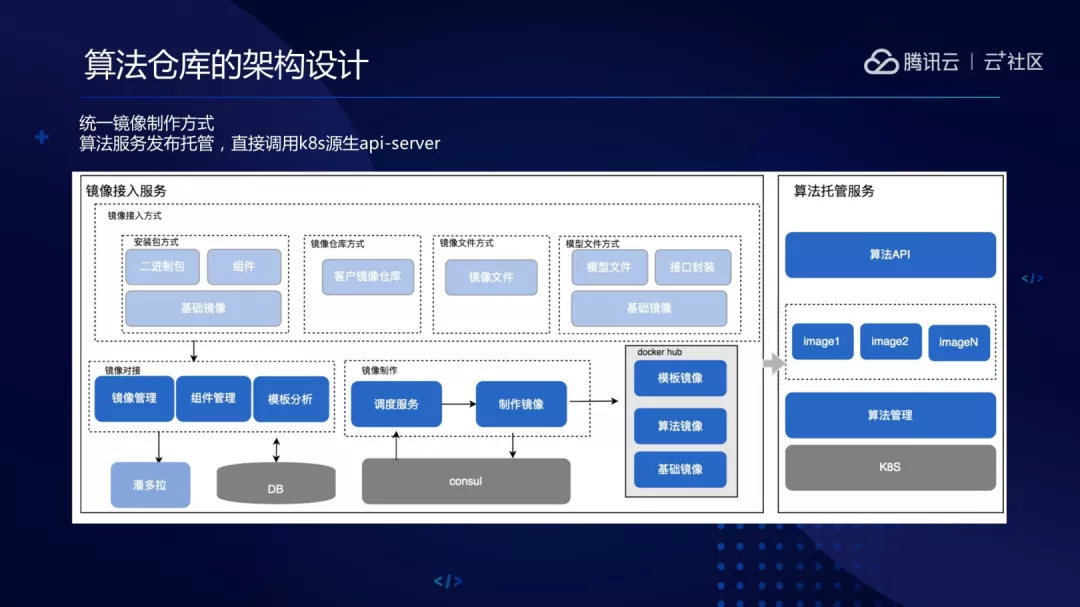
目前已经支持了安装包的方式、镜像仓库、镜像文件、模型文件的接入能力。右边有个模型镜像,会把基础镜像里安装的常用组件打出来成立成模型镜像,这样以后安装类似组件场景的话可以快速复用,缩短制作镜像的时间。
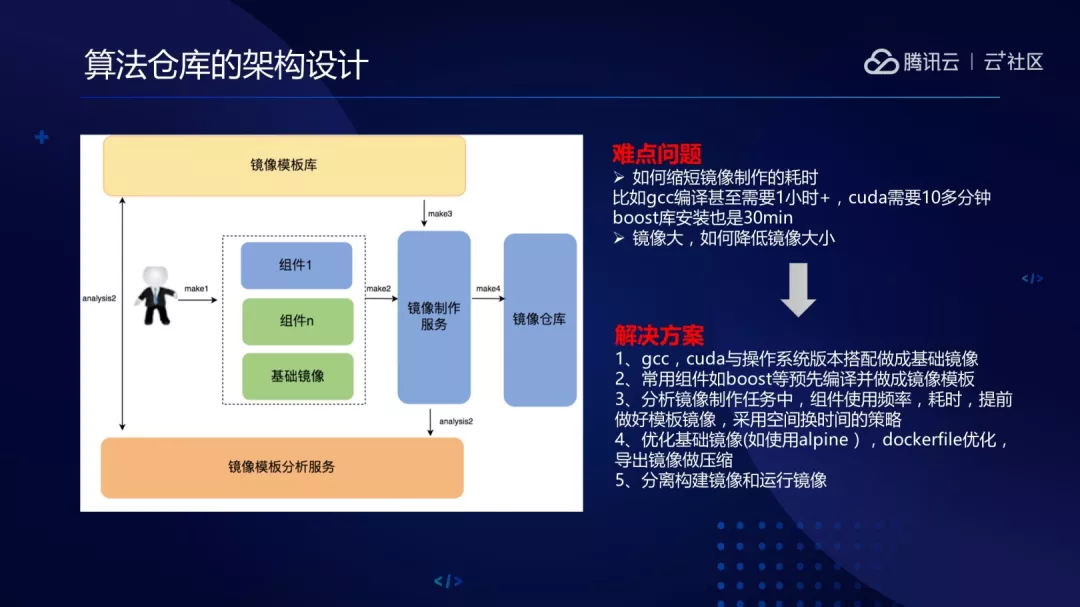
镜像仓库有两个难点:缩小镜像制作过程中的耗时,比如说 gcc 编译或者 Cuda 以及 Boost 库编译都比较耗时。其次是镜像大,怎么降低镜像大小?
会把常用的 gcc 版本、Cuda 与操作系统版本做成基础镜像直接提供用。常用的组件会预先编译好做成模板镜像。会动态分析镜像制作任务,把组件使用的频率、耗时大的通过空间换时间的思想提前沉淀下来。优化镜像大小用了 Alpine 操作系统,这样只有几兆。通过一般的操作系统镜像会很大,可能会有 1 到 2G。Dockerfile 里把 RUN 命令写成一行,会减少镜像的层数,也分离了构建镜像和运行镜像。
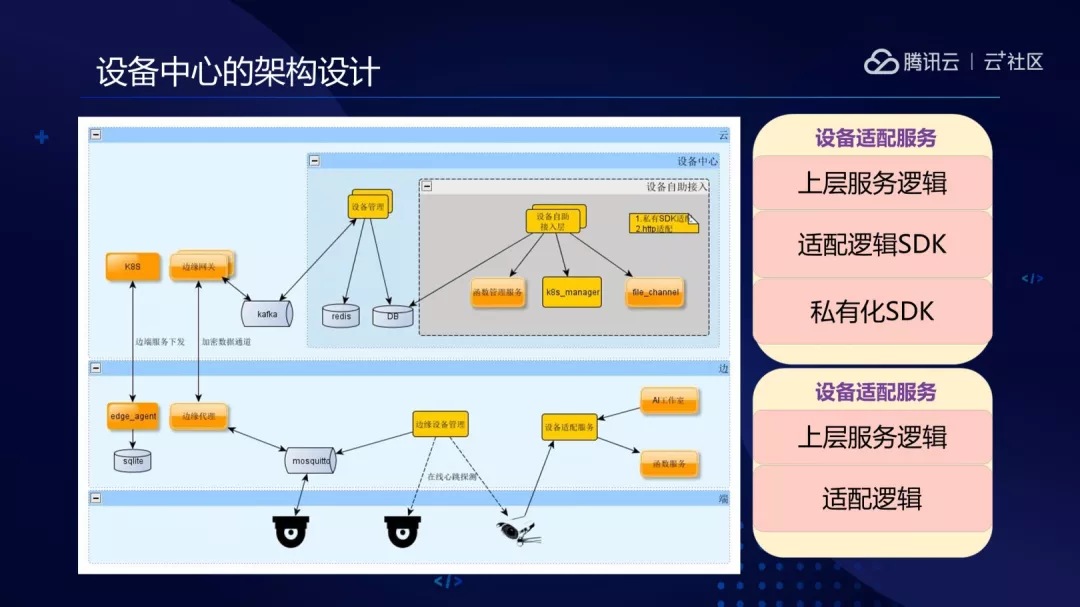
3.设备中心的功能主要是设备自助接入能力,各个厂商以及厂商里各个型号的协议都会有差异,很难统一。
比如业界有 ONVIF、ISAPI、GB28181、私有化 SDK 等,没有统一,其实私有化 SDK 基本上每个厂商都有自己的一套。
对于私有化 SDK,我们会分成三层微服务:
(1)上层服务逻辑(做成基础镜像);
(2)适配逻辑 SDK(so 插件);
(3)私有化 SDK(so 插件)。各个类型设备会通过设备层适配层 so 插件把私有化协议转化成内部统一协议。我们会把上层做成基础镜像,设备厂商自主接入的时候只要实现适配插件,就能快速把设备接入进来。
对于 HTTP 接口,可能每一个厂商的地址不太一样,还有一种是接口能力也不一样,输出输入也不一样,这里复用了在 AI 工作室里沉淀的函数服务能力,来支持动态指定 HTTP 接口名和输入输出参数的转换。
也实现了云边端混合部署的能力,主要解决边端的算力不足、带宽、延时等问题。如把算法解码或者优选算法服务部署在边端进行处理,处理之后会把图片、结构化数据通过加密数据通道到云端做后续处理。同时也实现了从云端的 K8S 延伸到边端的部署更新微服务的能力。
4.数据中心窗口,负责实现平台数据的接入、外部推送、转换、存储、屏蔽读写存储介质等能力。
包括本地的上传、分片断点续传等能力。通过消息队列 Kafka 来解耦窗口间的耦合,比如要给 AI 工作室任务的话,会把元数据写到消息队列里,任务调度器会消费元数据通道,调度拉起任务,执行编排好的流程引擎来做对应任务。
数据中心会拉取一些文件,通过把地址写到数据通道里,任务执行器会不断地从数据通道里消费数据做逻辑。我们在部署过程中也会遇到比较大的挑战,比如私有化落地时存储介质不一样,有些用 ceph,cos、NAS 等,我们把数据中心抽象了 FileAgent 容器提供给每个窗口用,屏蔽所有底层的存储介质,部署的时候以 sidecar 模式跟业务容器同时部署在一起 pod 上跑。
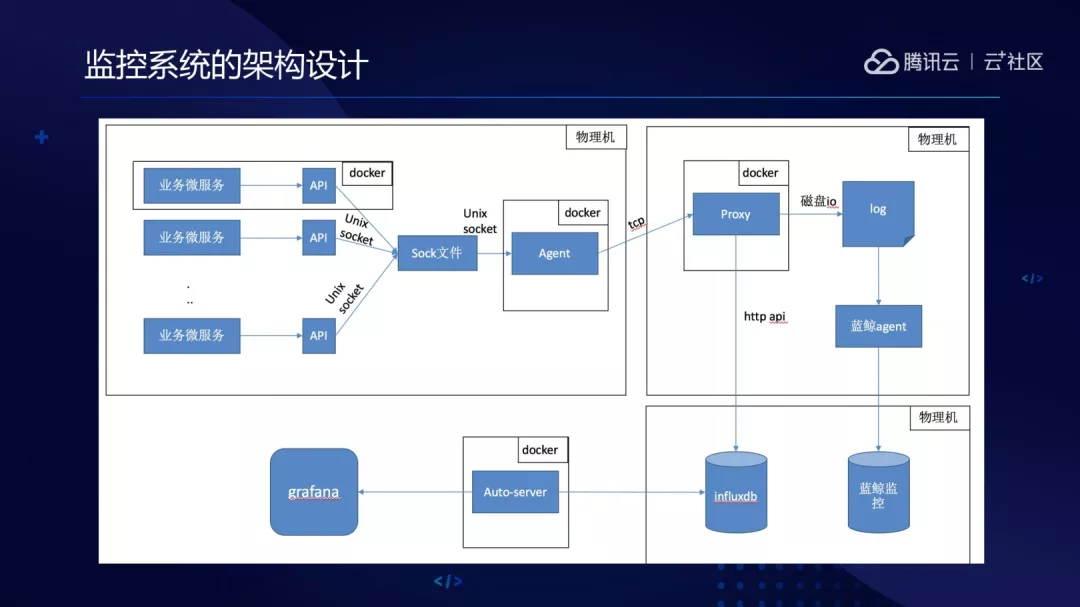
5.监控系统通过开源组件:telegraf + influxdb + grafana 搭建起来的。
每个 node 节点会部署一个 daemonset 的容器 monitor_agent。业务容器通过 unix socket 与 monitor_agent 通讯。monitor_agent 每分钟汇总上报数据到 influxdb 存储,grafana 通过读取 influxdb 进行视图展示和告警设置等。
当然业界也有其他的解决方案,比如说 Prometheus(普罗米修斯),我们做了选型的对比:
(1)它的采集器是以 exporter 的方式去运行的,每一个要监控的组件都有要装一个 exporter,promethus 再从多个 exporter 里面拉数据。
(2)promethus 自带的展示界面比较挫,即使采用 promethus,也要配合 grafana 才能用
(3)promethus 是拉模式来搜集数据的,业务要上报数据的话要安装它的一个代理 pushgateway,数据先 push 到代理,然后再等 promethus 去拉,实时性和性能都比推模式略差一点
我们采用的类似侵入式的方式,更适合我们这个平台。另外 telegraf 有很多扩展插件,用起来会很方便。
传统上,GPU 只负责图形渲染,而大部分的处理都交给了 CPU。自二十世纪九十年代开始,GPU 的发展迅速。由于 GPU 具有强大的并行计算能力,加之其可编程能力的不断提高,GPU 也用于通用计算,为科学计算的应用提供了新的选择。
AI 在 K8S 中的实践经验
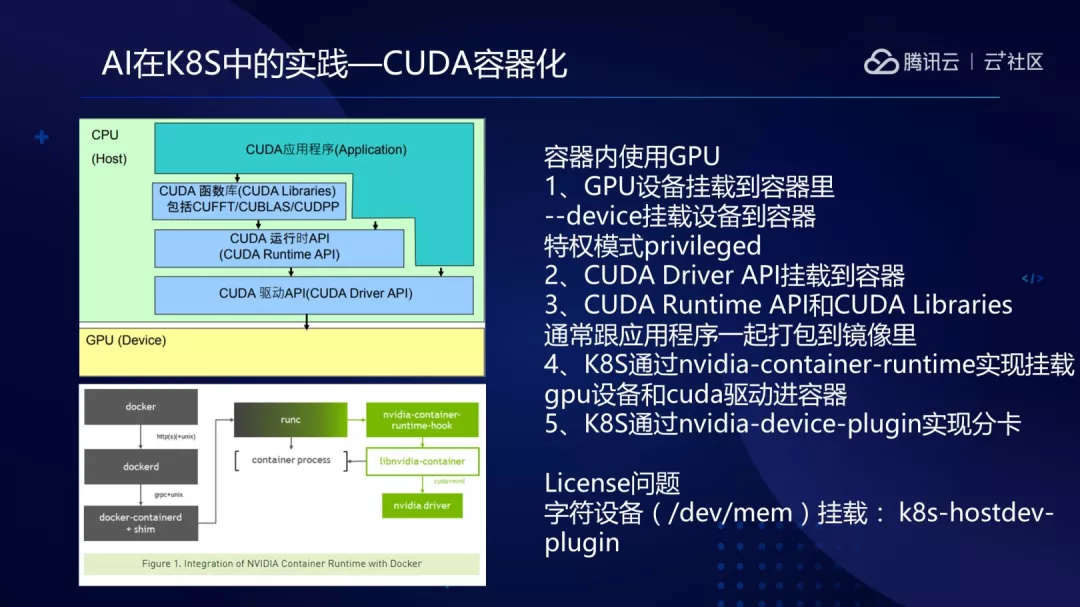
2007 年 6 月,NVIDIA 公司推出了 CUDA (Compute Unified Device Architecture),CUDA 不需要借助图形学 API,而是采用了类 C 语言进行开发。
从左边图来看,CUDA 软件体系分为三层:
(1)CUDA 函数库;
(2)CUDA 运行时 API;
(3)CUDA 驱动 API。
所以应用程序和 CUDA Libraries 以及 CUDA Runtime 间不会有什么问题?
主要问题在 CUDA Runtime 和 CUDA Driver 之间。CUDA Driver 库是在创建容器时从宿主机挂载到容器中,很容易出现版本问题,需要保证 CUDA Driver 的版本不低于 CUDA Runtime 版本。
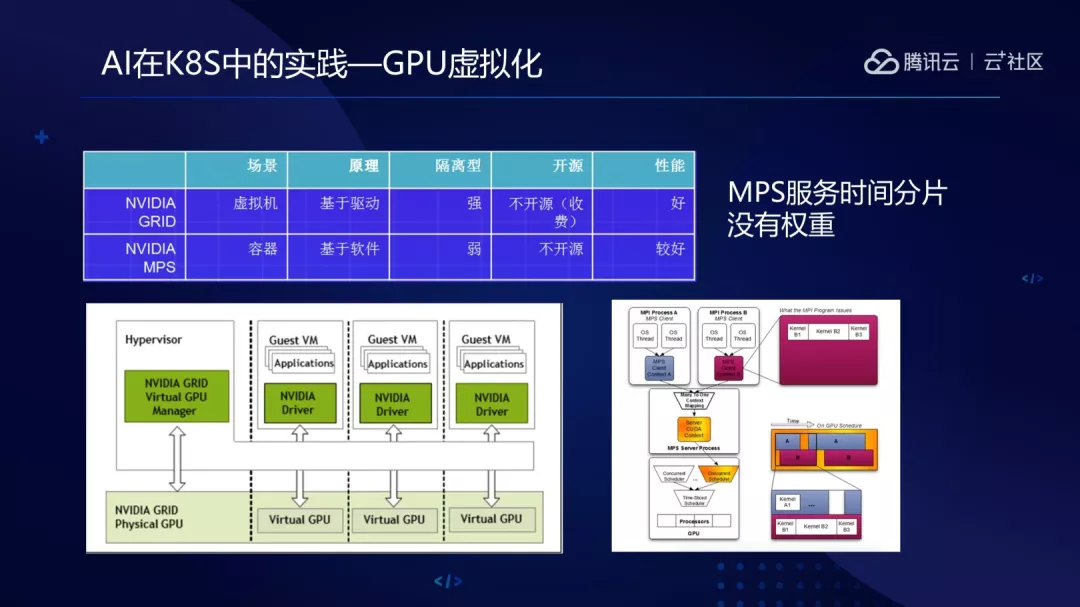
1.容器内使用 GPU:
(1)GPU 设备挂载到容器里
–device 挂载设备到容器
特权模式 privileged
(2)CUDA Driver API 挂载到容器
(3)CUDA Runtime API 和 CUDA Libraries
通常跟应用程序一起打包到镜像里
(4)K8S 通过 nvidia-container-runtime 实现挂载 gpu 设备和 cuda 驱动进容器
(5)K8S 通过 nvidia-device-plugin 实现分卡。扩展资源 ,使 gpu 能像 cpu 那样分配。
GPU 虚拟化是为了解决 GPU 资源合理分配问题,业界提出 GPU 虚拟化技术 。
2.nvidia 有两种 GPU 虚拟化的解决方案:
(1)GRID;
(2)MPS。
第一种模式更多用于虚拟机场景,基于驱动,隔离型会做的比较强,但不开源,性能比较好。MPS 是应用到容器场景的,基于软件的方式,隔离性比较弱,但也不开源。
MPS 服务时间分片没有权重,所以分卡能力做不到 0.1 卡或者 0.01 卡的粒度,只能做到二分之一、四分之一,八分之一等。
GPU 的调度是时间分片的,GPU 的利用率是按照 sm(Streaming Multiprocessors)的占用率来展示的。
我们公司有另外一个团队实现了 GPU 半虚拟化的能力,基于驱动函数实现,也是改变了函数显存申请、释放和线程的发起函数。
从左边下图来看分为 0.3 和 0.7,从执行时间来看缩短很多,比如说 0.7GPU 的话 nvidia 是 87 秒,用了 GPU 虚拟化方案 66 秒就把网络模型给训练好。目前来说能做到 0.01 的粒度,有 100%的方式,更多是最小配到 0.1 的粒度,因为配到很小 0.01 的话, 这种对自身程序影响很大,经常容易被挂起空转。太小了用处不大,因为你显存本身不会占用 1%这么小。
在 K8S 使用过程中组件像 MySQL、Kafka 最近也在做容器化,之前没有做容器化。在物理机部署的时候会遇到问题,容器内访问非容器化部署的组件是怎么做的?
比如如果每个环境通过 IP 部署起来的话成本太高,加上 MySQL 集群发生主从切换引起 ip 变化,这里我们引入了 consul 的 dns 能力,在容器里解析的时候会通过 kube-dns 发现是 consul.service 结尾域名,可以通过转发到 consul dns 解析。
调用链是基于 Jaeger,Jaeger 是基于 Google 的 Dapper 论文实现的,我们把 traceid、spanid 传递能力集成到框架里(Python、go),包括 grpc、HTTP 调用下层服务,使写业务逻辑的时候就不用关心这一块儿。
下一代调用链是基于 istio OpenTracing 标准业务无侵入。
在 K8S 里可能还会遇到些挑战,比如说弹性收缩: GGPU 资源自动扩缩容、基于 qps 自动伸缩;
负载均衡:有状态路由,K8S DNS 是用轮询的方式负载均衡,但在实践过程中可能会有场景,比如说用到一致性哈希的路由场景。
存储容器化:组件容器化(如 MySQL、es、Kafka 等)
容器安全因为没有像虚拟机一样隔开,是共享内核的,所以 Docker 还是存在共享内核导致的安全,以及镜像安全和函数服务安全。
作者介绍:
黄文才, 2010 年加入腾讯,先后参与了 QQ 群、群空间、WebQQ、Q+、腾讯游戏、QQ 全民闯关等项目的架构设计与开发,在海量服务、分布式系统方面有一定的经验,目前担任云智天枢平台的技术架构师,负责平台架构设计。
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:
https://mp.weixin.qq.com/s/Lt2QlDZueMhV1GeDjZsVFw
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论