

当前世界形势千变万化,各种技术创新层出不穷,新兴业务模式也是波谲云诡,企业的信息化建设如何紧跟业务,适应业务乃至驱动业务转型是各级管理者的头等题目。对于底层执行者,如何能够快速满足企业的要求,如何紧跟当前业界技术发展趋势,对其也提出了明确且紧张的学习要点。
对于企业业务发展所适配技术而言,根据时间发展,技术更新络绎不绝,涌现了多种经典组合。
早期是单台设备(PC Server)加上操作系统(Linux、Windows 等)直接运行,没有什么高可用的概念,数据直接存放到服务器磁盘上,数据保护方式和技术更是简陋。
在企业发展中期,技术便涌现了许多选择,更因为单台硬件设备能容纳的资源越来越多(最恰当得解释便是摩尔定律),出现了各种虚拟化技术,包括 UNIX 虚拟化技术,例如 PowerVM、vPar 等,非常好用;基于 Linux 的虚拟化技术 KVM、XEN、ESXI 等;基于 Windows 的虚拟化技术 Hyper-v 等,存储更是诞生了各种集中存储技术(IBM DS、EMC VMAX、HP EVA 等),这些技术为企业业务的发展保驾护航,无后顾之忧。
后期,企业业务发展不甚明了,各种成本的投入产出比(ROI)要求更加严格,此时,急切需要“物美价廉”的技术为发展“添砖加瓦”。
基于 IaaS 的云计算产品组合 OpenStack+Ceph,基于 PaaS 的云计算产品组合 Docker+Kubernetes+Ceph(GlusterFS 等)都构成了某些层级的事实性标准,这些组合为业务发展循环不断贡献力量。从技术角度分类,其中包含两个方面,计算和存储,计算是解决运行时的问题,把业务形式进行串联,使其运转更加高效。存储是解决状态保持的问题,需把业务语言翻译成计算机语言,然后进行加工并保存,分析使其产生巨大价值,甚者更是可以驱动业务。今天我们要讨论的就是如何利用这个价值,价值是如何接入的,又是如何反馈的。
在经过多种类(Ceph、GlusterFS 和 HDFS)和多维度选型之后,我们选择以 Ceph 为基础进行云存储建设。在分析了业务特点和使用场景后,也确定了要自开发的功能。愿景是将云存储建设成为一站式服务平台,所有与数据相关得服务均可在该平台完成,也包括存储空间的生命周期流转,实现有求即有,来之即用,用完即走。如下:
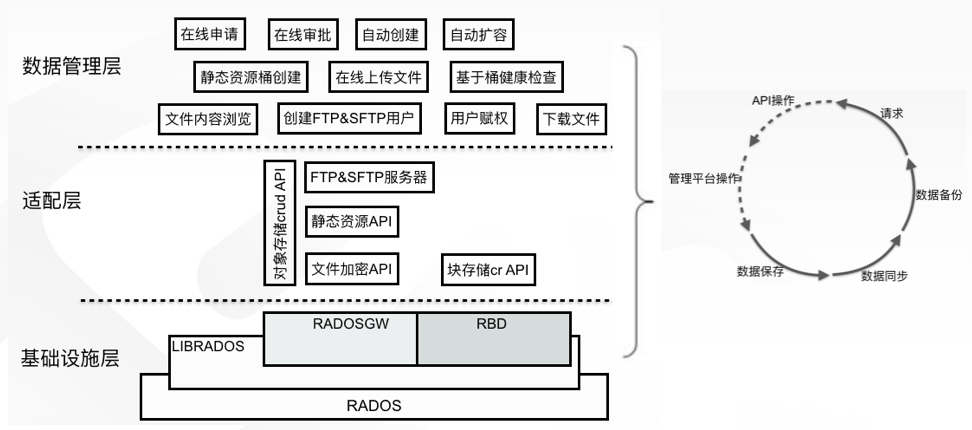
从基础设施层面,我们首先对存储集群节点之间的连通性进行优化。
从存储节点的物理分布上,要尽可能分散在不同的机柜中,避免因为单机柜掉电,影响存储对外提供服务.
其次,存储节点应连接到同一层级的交换机上,链路越长,经过节点越多,出问题可能性越高,性能也越差。同时,要充分考虑存储的主要应用场景和平台,尽量将它们与存储放在同一 C 段,保证最优。
第三,连接管道要足够粗,存储节点和交换机全部做成聚合,存储节点不同网卡不同端口捆绑成 bond4 模式,保证出现问题时不影响服务。交换机与之相连端口也需要做成捆绑,否则会形成回路,造成网络风暴。如果希望增大存储吞吐量,还需要设置网络包的巨型帧。
项目可能出现的所有问题一定要扼杀在摇篮里,否则墨菲定律会被一次又一次被证明。例如,网络连接为什么要用 bond4 模式,而没用 bond1 呢?
在网络连接出现问题时,bond1 模式在节点空载情况下,是不丢包的,但是在高负载情况下,一般会丢 1-2 个包,再加上软件系统出错进行纠正的时间,即使有应用系统的重试机制,SLO 也是无法满足的,所以 bond1 是不够的。
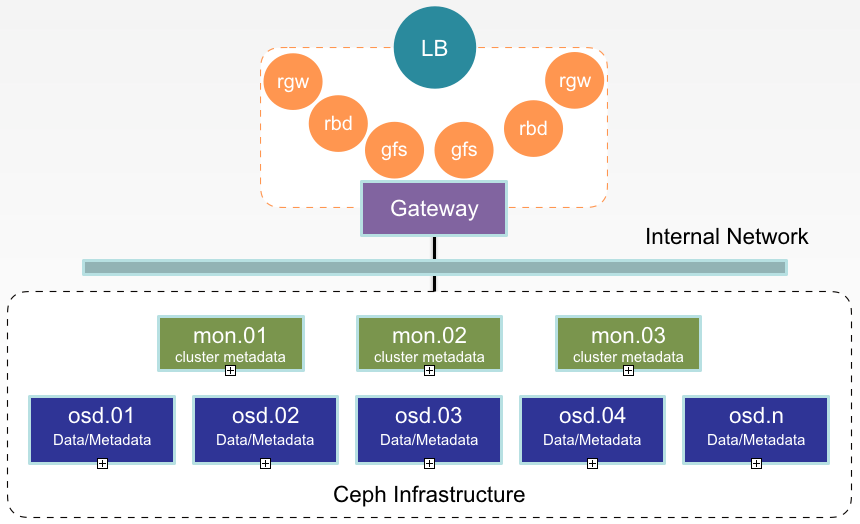
在存储物理架构上,存储集群实现了 3(monitor)+N(OSD)+2(client)的建设形式,实现角色隔离,功能分离,互不影响。3 个 monitor 节点配置有 monitor 和 mgr 服务,作为存储的大脑和监控使用。在 N(数量可以线性扩展,所以未明确)个 OSD 节点上进行了一些优化,首先是磁盘的 IO 调度策略上。
SSD 磁盘采用 NOOP IO 调度策略,NOOP 遵循先入先出(FIFO)原则,对请求进行了简单的队列处理,NOOP 对 bio 进行了后向合并,最大程度保证相邻 bio 进行合并处理,提高了效率。SAS 磁盘采用默认的 DeadLine IO 调度策略,Deadline 调度策略对读和写进行区分,执行 FIFO 策略,每个请求会被分配一个时间戳,在读优先的情况下,可以知道哪个写请求已经长时间没有被调度,进行优先调度,避免了写饿死的情况发生。
其次,基于存储的读写策略设置,我们进行了 OSD 硬盘类型的混插,SSD 硬盘和 SAS 硬盘按照 1:2 的比例配置,保证每次读操作都落在性能较好的 SSD 硬盘上,同时每次写操作也会相应提高效率。
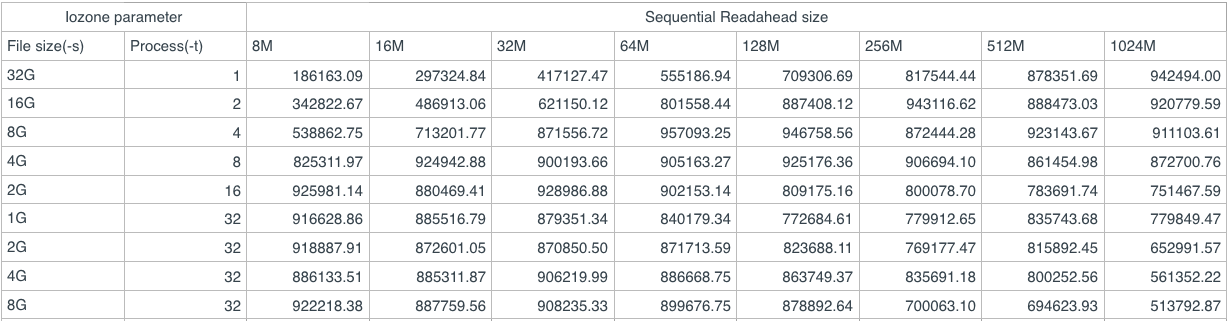
第三,我们对读、写缓存和 bluestore 缓存进行了优化,增加了预读缓存、写缓存和 bluestore 缓存的大小,对整体性能表现提高很多。以下是预读缓存大小的一个性能测试:
第四,我们对 Bucket index 进行了重新配置,修改 crushmap,将其全部放置在 ssd 高速磁盘上。单个桶索引大概是 200 bytes,当单个桶存放大量对象数据时,索引不进行单独分离或存放在高速磁盘上,会造成性能下降。因此,我们对 crushmap 进行导出,反编译,修改、重新编译,注入操作,使索引全部放置到 ssd 磁盘上,减少延迟,提高性能。
最后,我们为存储设计了一个网关,由两个节点组成,将我们的使用场景和存储本身完全解耦,即使存在配置失误或损坏,完全不会影响整个存储的健壮性和数据完整性。在网关节点上安装了 Ceph rgw、Nginx 和 Pacemaker。由于业务对全局共享文件系统读写得需求,需利用高可用软件管理文件系统并对外暴露,供多个容器对同一文件系统进行挂载,读写数据。所以我们选择 Pacemaker 高可用软件对外提供唯一 IP 地址,保证服务唯一可访问性。
众所周知,rgw 单实例在可用性、扩展性和性能上存在低效问题,所以我们利用 Nginx 负载均衡改善效果。我们对外提供三种类型的基础存储服务,即对象存储、块存储、全局共享存储。
在存储性能优化设计方面,我们大概做了以上五点。当然,还有一些小的优化在这里就不详细介绍了,比如 TCMalloc 参数调整,ulimit 参数调整,kernel pid_max 参数调整等。
在存储数据保护方面,我们应用了 Ceph 原生的 multisite 数据同步技术。在同城另一个机房建立一套分布式存储,作为主机房分布式存储的备份。两机房间通过 10GB 数据专线进行连接,保证数据传输带宽。在设计和实施上没有进行特别优化,基本根据社区要求进行。这里我想重点说一下 multisite 的后期运行和维护问题。在上线后 multisite 的运行中,我们发现大部分桶中的数据是实时进行同步的,在主从存储中基本一致,但是少部分桶数据不是实时同步的,而且有可能会相差很大。为此,我们在运维平台上专门设计了一个功能,用以实现文件同步状态的检查,并且当单桶对象文件数量在主从存储端差异量>10 时,会自动触发数据同步,从而保证了数据的安全性和完整性。
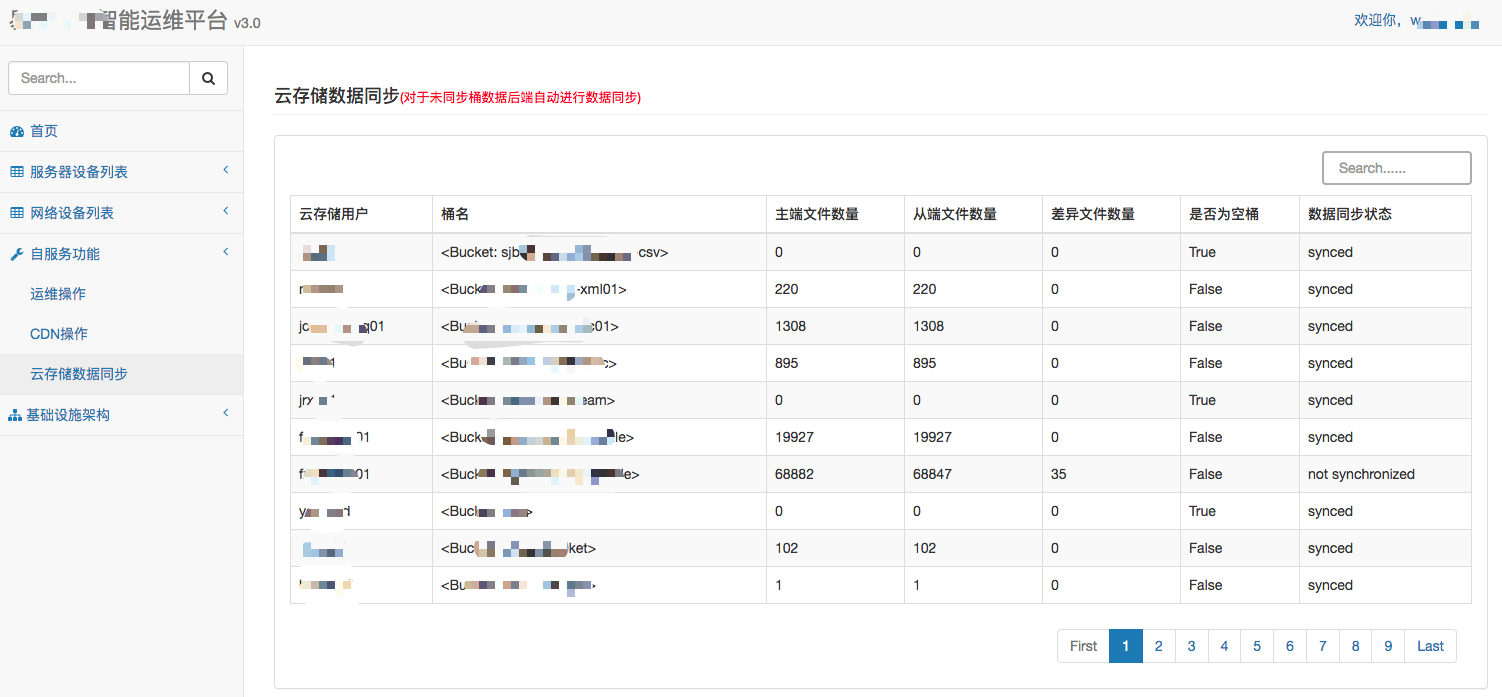
从存储适配方面,我们根据 S3 API 开发了一整套完整功能的、适用我们的 crud API 和 SDK,包括对象存储和块存储。其中对象存储 API 直接开放给开发人员使用,支持文件以目录形式进行存储。块存储 API 开放给容器云平台,在容器云平台可以直接操作云存储块设备,进行创建、查看和删除等操作。

同时,针对金融行业的特点,我们自研了文件加密功能与上传下载(FTP 和 SFTP)功能。
对于文件加密功能,金融行业涉及很多资质文件、身份证和银行卡信息,所以为了符合监管要求,必须要进行加密。在开发加密功能的过程中,我们调研了两种方法,一种是开启 https 进行加密,rgw_crypt_require_ssl值默认设置为 true,利用 openssl 生成 crt 和 key 证书,然后加载到ceph.conf的rgw_frontends选项中,同时需要在 API 加载该私钥证书予以生效。第二种方法是关闭rgw_crypt_require_ssl,不启用 https 加密,而是在 http 下采用 Server-side Encryption,官方文档有明确说明,根据 Amazon SSE-C 规范在 S3 中实现。在调研了两种方法之后,我们选择了第二种方式实现。

因为业务场景要求,我们利用开源的 Apache Commons VFS 和 Ftp Server 自研了 FTP 和 SFTP Server 功能,连接对象存储和文件系统。在访问入口处部署了路由功能,让广大商户有选择的从存储某区域上传下载文件,最终达到控制用户使用哪种协议(FTP 或 SFTP)在哪些区域(文件系统或桶)进行指定操作(上传或下载)的目的。

在管理便捷性方面,我们开发了云存储管理平台,在该平台上可以很便捷的为用户创建 FTP&SFTP 服务,登录用户赋权(上传或下载)。支持在线浏览文件内容,下载文件。开发了静态资源托管的功能,在创建静态资源桶的时候,会利用我们开发的 API 自动将桶设置为公共读,然后使用 API 或云存储管理平台上传 HTML、CSS、JS 等文件,支持单个文件和 zip 包上传。
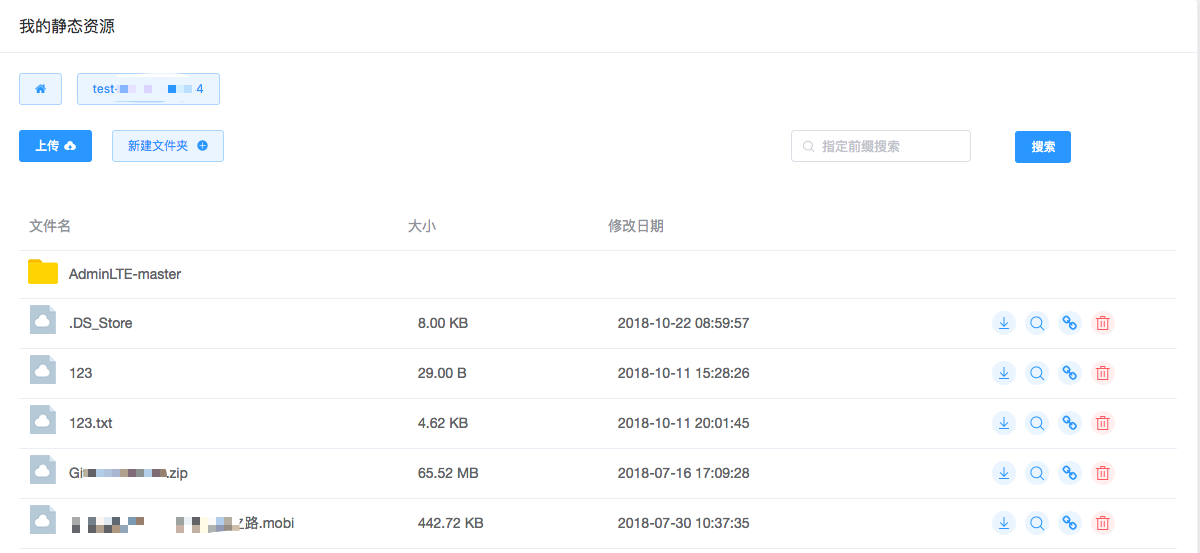
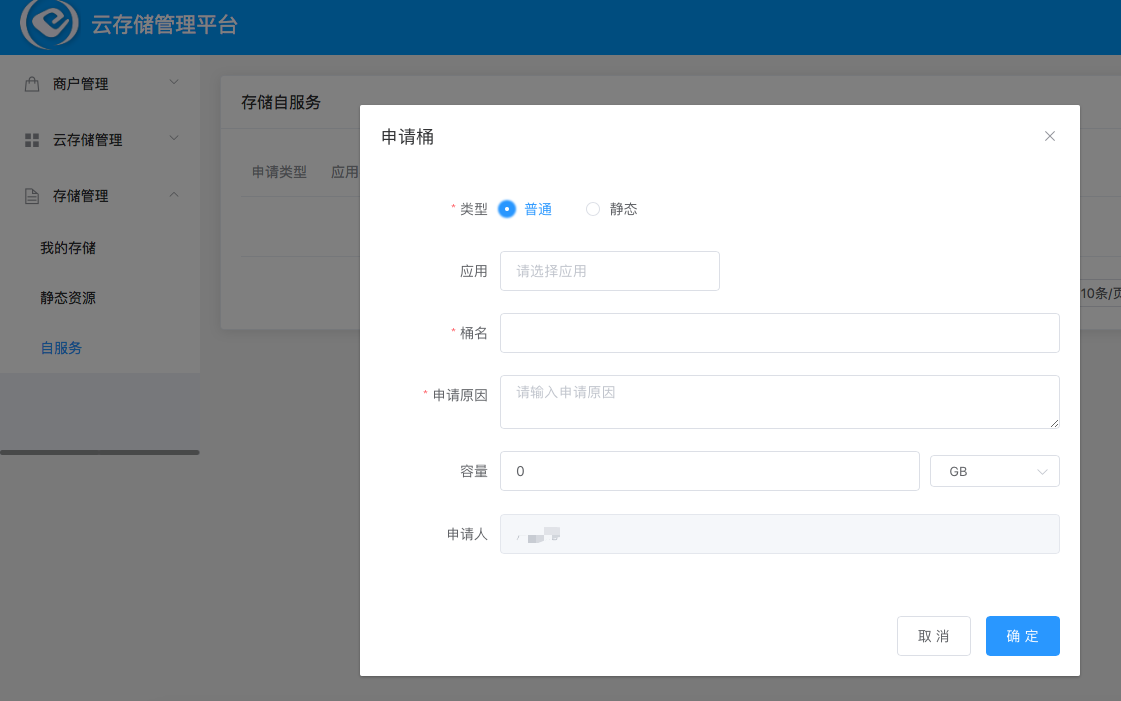
存储桶具备健康检查功能,方便开发人员自测。支持 Ceph 用户属性查看和配置,支持桶属性和配额的在线查看和配置。另外一个最重要功能是自服务功能。众所周知,云计算的要义是在线横向扩展,功能全面,自服务。我们的自服务支持存储的申请,自动创建,自动扩容等,配置存储形成的工单可以显示审批状态(审批中、完成、被驳回),创建和扩容存储支持按用户要求设置 quota,根据需求扩展。
以上介绍了我们建设云存储的一点技术历程,下面对我们建设云存储的一些心路历程进行一些总结。
首先,做这个的基础建设需要上级的支持。其包括人员和资源的支持,也包括项目进度与范围的控制审视,这些都是非常重要的。例如,良好完备的人员配置。我们的项目由一个项目负责人(总体负责把控项目进度和需求),两个开发人员(负责程序前后端开发),两个运维人员(负责基础设施运维、需求收集和功能测试),一个项目管理师(负责辅助项目的进度安排)构成,其中角色包括开发、运维、需求、项目管理、测试,一一齐全,这让项目能够顺利有序开展如虎添翼。
其次,项目成员的团结协作。在 Google SRE 的书里,形容运维和开发之间的关系是”regid boundaries are couterproductive”,但在我们项目里,开发同事从来没有因为害怕增加工作量而不推卸功能实现,相反而是积极提出并实现某些新功能,每个人都尽职尽责,多做一丝。项目管理师在其他部门参加会议时,听到关于可能会使用云存储的需求时,会主动推荐云存储并跟踪需求,最终使其数据全部上云。这样即帮助兄弟部门又很好的推介云存储,一举两得。
第三,用户的支持。用户是产品的最终使用者,是一个产品好坏的定论者,是一个产品成功推广使用的推介者。我们需要将产品推广给尽可能多的用户使用,发现其中的问题,进行修改补充,再发布,从而形成一个良性循环。在公司内部发动所有人通过各种渠道和会议不断的宣传云存储是什么,它的优势,它的特点。用户支持才是战胜波特五力的根本。
第四,详细完备的解决方案。在进行产品推广时,需要有一个完善的解决方案,使其形成闭环生态。对于我们云存储而言,需要提供数据接入接口、数据高效运行平台、数据安全存放技术、数据灾难备份方案等,使客户不为业务外的任何事情担心。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 1 条评论