

在许多学习问题中,由于深度神经网络的成功通常依赖于大量的有标记数据,而这些数据的收集成本很高,因此小数据挑战逐渐走近了人们的视野。为了解决这一问题,人们提出了许多无监督和半监督的方法,在小数据上训练复杂模型。
本文是 AI 前线的第 76 篇论文导读,今天要解读的这篇论文来自华为美研所。在这篇论文中,作者对无监督和半监督这两大类方法的最新进展做了详细解读,包括训练变换等变、非耦合、自监督和半监督表示的标准,以及无监督和半监督生成模型的实例。在介绍无监督和半监督方法的同时,文章还对目前出现的新兴主题进行介绍,从无监督和半监督领域的适应,到变换等变性和不变性在训练深度网络中的基本作用。本文的目的是探索这一领域的主要思想、原则和方法,以揭示在大数据时代解决小数据挑战的旅途上我们的前进方向。

介 绍
深度学习的成功往往取决于大量的标注数据,在标注数据上训练的模型往往能取得与人类水平相当,甚至超越人类水平的表现。然而在许多情况下,很难收集到足够的有标注数据,这也促使研究人员开始探索标注数据之外的无监督信息,以在小数据的情况下在各类学习任务上训练出鲁棒的模型。
无标注数据
有标注数据的数量通常很小,而无标注数据的数量却是很大的。无标注数据的分布情况往往是学习泛化性较强的特征表示的线索。无监督和半监督方法的区别在于有没有额外的标注数据样本用于训练模型。无标注数据能帮助模型缩小不同任务之间的域间差,这也推进了大量无监督和半监督域适应方法的发展。
辅助任务
辅助任务也可作为附加信息的重要来源,用于解决小数据的问题。一个相关任务可以是在与目标任务无关的概念上进行的学习问题。这种情况可以归为零样本学习(Zero-Shot Learning,ZSL)或小样本学习(Few-Shot Learning,FSL)。零样本学习(ZSL)问题是指目标任务中没有标注数据的无监督学习问题,而小样本学习是只有少量标注数据的半监督学习问题。这两个方法的目的都是将源任务学习到的知识迁移到目标任务。
根据对各种信息源的不同利用方式,形成了从不同角度解决小数据问题的多种学习方法。图 1 对这些方法进行了总结和分类,让我们能更好的理解目前小数据问题的研究现状。
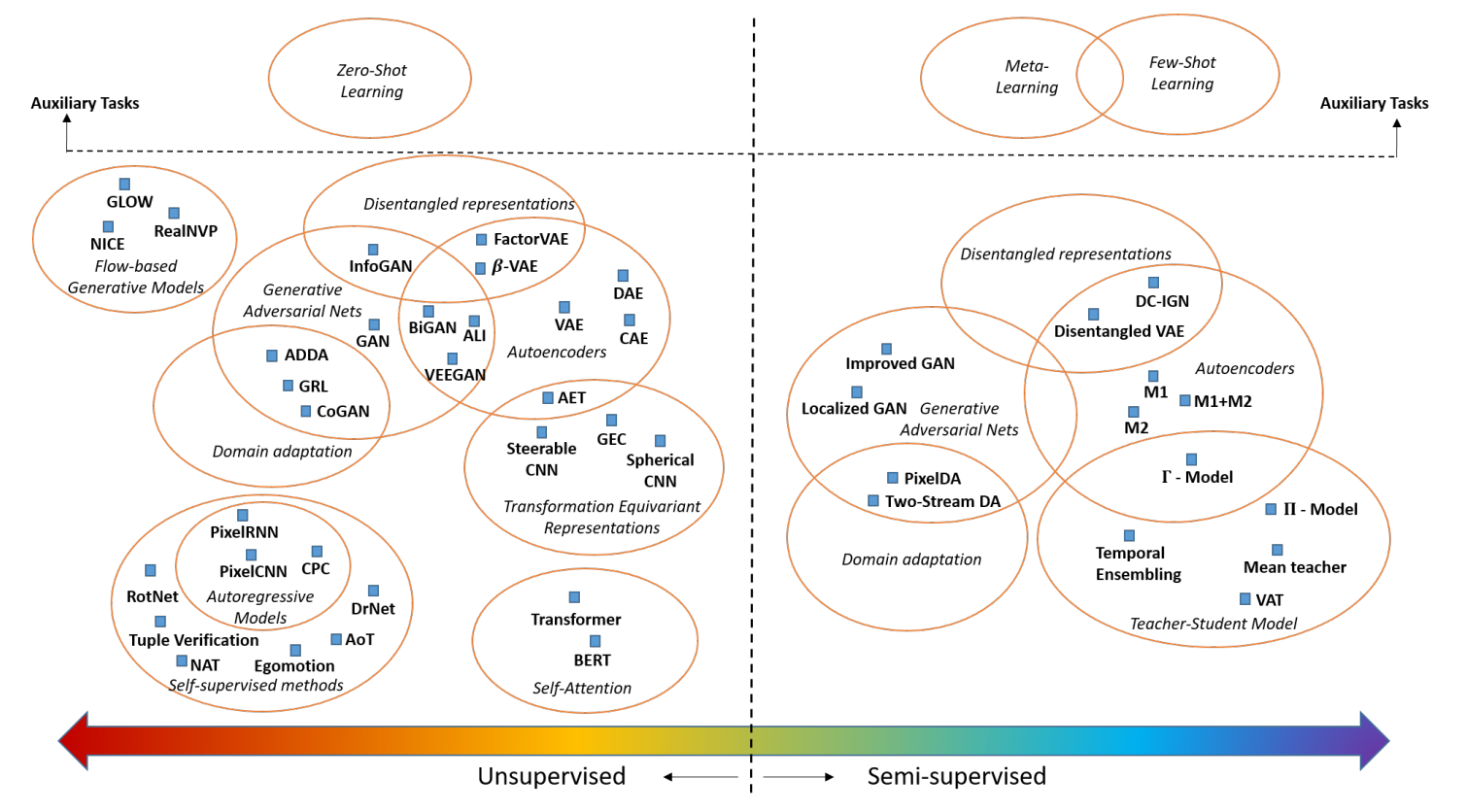
图 1 的左端代表用无标注数据训练的无监督方法。无监督方法旨在学习到能够泛化到不同任务的特征表示。通常用这些特征在分类任务中的表现作为特征的评价指标。图 1 的右端表示半监督方法,既利用标注数据,也利用无标注数据来训练模型。其想法在于未标注数据提供了数据在空间中的分布,并且可以通过探索这种分布来训练一个鲁棒的模型。

无监督方法
从无标注数据中训练无监督表示的目的是让特征可以泛化到新的任务中。我们将从几个方面对无监督学习进行介绍。我们首先介绍变换等变表示(TER)这一新兴方法。随后介绍生成网络模型及其非耦合表示。最后,我们会介绍图像和视频表示的自监督训练方法。
无监督表示学习
无监督表示学习的研究可以分为以下三类:
变换等变表示
生成模型
自监督方法
变换等变表示(Transformation-Equivariant Representations,TER)
在开始之前,我们首先思考一下一个好的表示需要具有什么特性。研究人员认为图像转换中的等价关系(equivalence)和不变性(invariance)是 CNN 取得的成功的重要原因,尤其是有监督分类任务。典型的 CNN 网络由两部分组成:输入图像经过多个卷积层后的输出特征图,和全连接层分类器。
尽管特征图的变换应该与对输入图像的变换相同,全连接层分类器在预测类标时不应该受到图像变换的影响。在学习变换等变表示的概念提出之前,研究人员更多是通过图像变换来增强标注数据,然后最小化分类误差来训练有监督模型,以增强模型对图像变换的鲁棒性。然而对于无监督表示来说,直接应用变换不变性是不现实的,如果没有类标的监督,就会导致学习到的特征没有价值,对所有样本都是不变的。
因此,以变换等变性(transformation equivariance)作为标准来训练无监督表示是最恰当的选择,这样学习到的无监督表示在理想情况下可以泛化到未知任务上,而不需要类标信息。变换等变性是指通过卷积层后的特征图与图像的变换情况相同,这样可以学习到一个好的表示,对与图像等变的本质视觉结构进行编码。
基于这样的思想,研究人员提出了群等变卷积(Group-Equivariant Convolutions,GEC),通过直接训练特征图作为不同变换群的函数。实验结果证明特征图与被分配的变换完全等变。然而,群等变卷积的形式是严格定义的,限制了特征表示在许多应用中的灵活性。一种更灵活的方法是通过最大化特征表示和所选择变换之间的依赖性,增强变换等变性,这便是自编码变换(Auto-Encoding Transformation,AET)的思想。与 GEC 相比,AET 并不完全服从变换等变的标准,而是追求无监督表示的灵活性。
群等变卷积(Group-Equivariant Convolutions)
参考论文:T. Cohen and M. Welling, “Group equivariant convolutional networks,” in International conference on machine learning, 2016, pp. 2990–2999.
假设一组由多种变换的组合构成的群组 G,包括旋转、转换、或镜面变换。而群等变卷积的目标是生成与群组中所有变换等同的特征图。变换等变的概念是指经过变换后输入图像的卷积等同于对原始输入的卷积进行变换。
为了保证变换等变性,GEC 中,特征图定义为变换群 G 的函数,则对输入图像 f 的群卷积为:
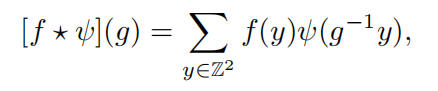
生成了定义在 G 上的群卷积特征图[f*φ]。因此,输入图像得到的特征图都是 G 的函数,而该特征图 f 与滤波器φ的群卷积定义为:
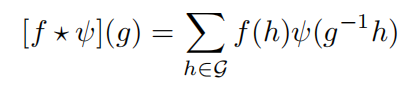
对于上述群卷积,可以证明其变换等变性:
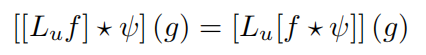
这也表明了变换后的输入的卷积,与输入的卷积进行变换相同,即变换等变性。
自编码变换(Auto-Encoding Transformations)
参考论文: L. Zhang, G.-J. Qi, L. Wang, and J. Luo, “Aet vs. aed: Unsupervised representation learning by auto-encoding transformations rather than data,” arXiv preprint arXiv:1901.04596, 2019.
尽管群卷积从数学上保证了变换等变性,他们对特征图的形式有严格要求,即特征图必须是变换群组的函数。但是在许多应用中,我们通常希望特征表示的形式更灵活,可以通过探索无标注数据的分布实现无监督训练。
传统的自编码数据(Auto-Encoding Data,AED)通过重构数据来学习表示,而 AET 通过从原始的特征表示和变换图像的特征表示中解码变换方式(transformation)来训练无监督模型。它的假设是:如果变换可以重构,那么学习到的表示就应该包含图像变换前后的视觉结构的所有信息,那么该表示就是变换等变(equivariant)的。并且,由于对表示的形式没有严格的限制,也增强了选择表示形式的灵活性。
自编码变换的问题可以归结为表示编码器 E 和变换解码器 D 的联合训练。可以通过最小化变换 t 和估测值 t’之间的重构误差 l(t,t’)来训练 AET:
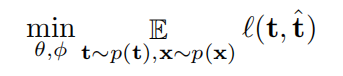
自编码变分变换(Auto-encoding Variational Transformations,AVT)
参考论文:G.-J. Qi and et al., “Avt: Unsupervised learning of transformation equivariant representations by autoencoding variational transformations,” 2019.
研究人员从信息论的角度提出了自编码变分变换模型,通过最大化变换和表示之间的互信息,揭示了二者的联系。AVT 的假设是:一个好的变换等变表示(TER)应该最大化其对于图像变换的概率依赖,这样,当图像的视觉结构进行外部变换时,TER 就可以包含用于解码变换的内在信息。
生成模型
生成对抗网络、自编码器以及他们的变体是目前从无标注数据中提取表示的有力工具。这些生成模型之间是紧密联系的。例如,GAN 依赖于解码器从数据中提取表示,减少模型坍塌,而自编码器可以通过对抗训练增强,从隐向量中生成更好的重建数据。基于这些生成模型,可以学习得到多种非耦合表示(representation disentanglement),开启了提取、非耦合和从表示中推理生成因素的研究之门。
自编码器(Auto-Encoder)
自编码器是生成模型的一种,通过联合训练编码器和解码器重构输入数据。这里我们主要介绍变分自编码器(Variational Auto-Encoder,VAE)、去噪自编码器(Denoising Auto-Encoders,DAE)和收缩自编码器(Contractive Auto-Encoders,CAE)。
变分自编码器(Variational Auto-Encoder,VAE)
参考论文:D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
变分自编码器通过训练自编码模型,最大化参数模型 pθ的边缘数据概率 pθ(x)的变分下界。利用变分编码器 qφ(z|x)来近似后验概率 pθ(z|x),得到边缘似然度的下界不等式:
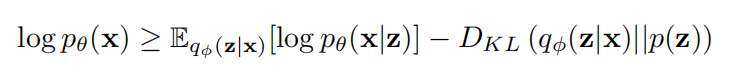
p(z)是表示的先验概率,pθ(x|z)是解码器。
VAE 中引入了 reparameterization trick,该方法使模型参数φ从随机噪声中分离出来,而误差能够通过网络反向传播来训练 VAE。VAE 为研究和实现表示非耦合提供了有力的工具。
鲁棒自编码器
参考论文:P. Vincent, H. Larochelle, Y. Bengio, and P.-A. Manzagol, “Extracting and composing robust features with denoising autoencoders,” in Proceedings of the 25th international conference on Machine learning. ACM, 2008, pp. 1096–1103.
S. Rifai, P. Vincent, X. Muller, X. Glorot, and Y. Bengio, “Contractive auto-encoders: Explicit invariance during feature extraction,” in Proceedings of the 28th International Conference on International Conference on Machine Learning. Omnipress, 2011, pp. 833–840.
去噪自编码器 DAE 和收缩自编码器 CAE 的目标都是得到对输入数据噪声鲁棒的特征表示。
与典型的自编码器不同,DAE 的输入是被噪声破坏的样本,而要从中重建出原始数据。神经网络学习到的鲁棒特征可以用于恢复未被破坏的数据。
CAE 以另一种方式学习鲁棒表示。输入数据出现小的扰动时,CAE 直接惩罚学习到的表示的变化。
基于 GAN 的表示
在 GAN 模型中,数据从噪声中生成,输入生成器,因此这些噪声可以视为生成器生成数据的自然表示。然而 GAN 存在的挑战是,给定真实样本,我们需要反转生成器来获取与样本对应的噪声表示。因此,GAN 中需要一个解码器,能直接输出可以从中生成对应样本并且被表示的噪声。
BiGAN 和 ALI:对抗表示学习
参考论文:J. Donahue, P. Krahenb ¨ uhl, and T. Darrell, “Adversarial feature learning,” arXiv preprint arXiv:1605.09782, 2016.
V. Dumoulin, I. Belghazi, B. Poole, O. Mastropietro, A. Lamb, M. Arjovsky, and A. Courville, “Adversarially learned inference,” arXiv preprint arXiv:1606.00704, 2016.
这些方法的目标是从 GAN 模型中学习到三个结构:1)生成器 G:Z->X,将输入噪声 Z 的分布 p(z)映射到生成样本 X 的分布 p(x);2)编码器 E:X->Z,将 X 中的一个样本 x 映射回噪声 z,理想状态下 G(z)=x,即 E 是 G 的反转网络;3)判别器 D:XÍZ->[0,1],给出区分真实样本对(x,E(x))和假样本对(G(z),z)的概率。
这三个结构可以通过 minimax 目标函数联合训练:
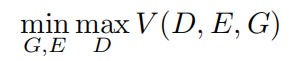
其中
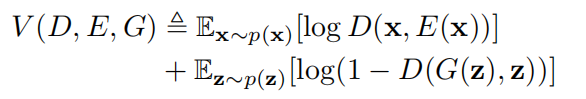
p(x)是真实数据分布。这个 minimax 问题可以通过迭代优化方法进行求解。
非耦合表示(Disentangled Representations)
非耦合表示通过提供可解释的显著属性来描述数据,以帮助下游分类任务。
假设一组有意义的属性,例如人脸表情、姿态、眼睛颜色、性别甚至身份,都可以用于分类人脸图像,而且他们在解决未来的识别问题中会有很大的作用。这意味着好的特征表示应该能尽可能的非耦合,从而为描述数据提供更丰富的属性。
InfoGAN:非耦合基于 GAN 的表示
参考论文:X. Chen, Y. Duan, R. Houthooft, J. Schulman, I. Sutskever, and P. Abbeel, “Infogan: Interpretable representation learning by information maximizing generative adversarial nets,” in Advances in neural information processing systems, 2016, pp. 2172–2180.
InfoGAN 训练生成模型,从非耦合表示中生成数据。InfoGAN 假设有两种噪声变量输入生成器:1)不可压缩噪声 z,不能分解为任何语义表示,能够以传统 GAN 中耦合的方式输入生成器;2)隐编码 c,代表关于生成样本 x 的显著非耦合信息,在生成过程中不会丢失,
因此,InfoGAN 的假设是通过结合这两类噪声,最大化隐编码 c 和生成样本 G(z, c)的互信息。能够防止生成器忽略对隐编码的依赖性,隐编码中往往包含生成样本的显著性信息。采用传统 GAN 的最小最大目标来训练 InfoGAN,最大化互信息 I(c, G(z, c))。
β-VAE:非耦合 VAE 表示
参考论文: I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner, “beta-vae: Learning basic visual concepts with a constrained variational framework,” 2016.
非耦合表示的思想也扩展到了其他无监督模型上。β-VAE 通过加上与各向同性高斯分布 p(z)=N(0, 1)的匹配约束,以分解推断后验概率 q(z|x)。这一约束不仅促进了更有效地数据表示,也能够将特征表示根据各向同性的先验分解成独立的因子。
训练 VAE 需要最大化目标函数:
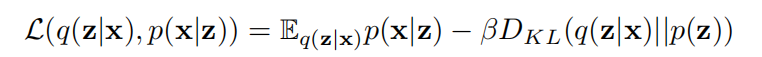
当β=1 时,上式退化为普通 VAE 模型,随β增加,对隐信息的约束就更强。β值较高时,会影响β-VAE 的重构保真度和特征表示的非耦合程度之间的平衡。
非耦合指标
为了评价学习到的特征的非耦合程度,研究人员提出了非耦合指标分数。通过固定表示中的一个生成因子,随机采样其他生成因子。然后利用普通的线性分类器对该因子进行分类,分类准确率即为非耦合指标分数。如果非耦合表示的独立性和可解释性存在,那么固定的因子就会有很小的方差,因此分类器鉴别该因子的准确率会很高,从而非耦合的分数也很高。
自监督方法
自回归模型
一类自监督模型的训练是通过预测上下文、缺失的或未来的数据来完成的,我们通常称之为自回归模型。自回归模型包括 PixelRNN,PixelCNN 和 Transformer。这些模型可以生成有用的无监督表示,模型依靠隐表示预测数据的未知部分。
PixelRNN
参考论文:A. v. d. Oord, N. Kalchbrenner, and K. Kavukcuoglu, “Pixel recurrent neural networks,” arXiv preprint arXiv:1601.06759, 2016.
在 PixelRNN 中,图像被分为规则的小方块,通过循环结构根据当前块的背景预测其特征。PixelRNN 有三种变体:Row LSTM,Diagonal BiLSTM,和 Multi-Scale PixelRNN。
Row LSTM 中,图像从上到下按行生成,每个块的背景是图像块上面的三角形。Diagonal BiLSTM 按对角线从顶角到底角扫描图像,获得一个对角线型的图像背景。Multi-Scale PixelRNN 由一个无条件的 PixelRNN 和一层或更多层的 PixelRNN 组成。无条件的 PixelRNN 首先生成较小的采样图像,然后有条件的 PixelRNN 层将较小的图像作为输入,生成原始的较大的图像。多个有条件的 PixelRNN 层可以堆积,逐渐的从低分辨率到高分辨率生成原始图像。
PixelCNN
参考论文:A. Van den Oord, N. Kalchbrenner, L. Espeholt, O. Vinyals, A. Graves et al., “Conditional image generation with pixelcnn decoders,” in Advances in Neural Information Processing Systems, 2016, pp. 4790–4798.
Row LSTM 和 Diagonal BiLSTM 的缺点在于每个图像块都需要按序列计算,所以计算量较大。这一缺点可以通过卷积结构同时计算所有块的特征来避免。与 PixelRNN 相比,PixelCNN 将每个块的背景限制到固定的感受野。另一方面,通过引入门限激活(Gated activation),研究人员提出了 Gated PixelCNN,能够对不同块之间的复杂依赖性建模。
对比预测编码(Contrastive Predictive Coding,CPC)
参考论文:A. v. d. Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” arXiv preprint arXiv:1807.03748, 2018.
自回归模型通常作为自编码网络的解码器,需要输出有力的表示来预测测试图像块。这样就可以在数据无标注的情况下,以自回归的方式训练学习特征表示。
对比预测编码在训练自回归模型上取得了显著成功。它的目标是最大化背景 c 的隐表示和未来样本 x 的互信息 I(c, x),并且通过最大化序列的共享信息,能够得到更准确的预测。
图像表示
除了自回归模型,自监督方法也探索了其他形式的自监督信号来训练深度神经网络。这些自监督信号可以从数据中直接得到,而不需要人工标注。
图像上下文(Context)
图像上色(Colorization)
代理类别、目标和聚类(Surrogate classes, targets and clustering)
计数、运动和旋转(Counting, motion and rotations)
视频表示
自监督的思想在视频特征表示学习中也得到了应用。例如,利用 Arrow of Time 作为监督信号来学习视频的高级语义表示和低级物理表示。
帧序列的顺序也可以作为视频表示学习的自监督信号,捕捉空时信息。研究人员提出 Tuple verification 方法训练 CNN 模型,提取独立帧的表示,并且决定随机采样的一组帧是否处于正确的顺序,以消除视频片段中的方向混淆。
图像的非耦合表示也被提出利用视频帧之间的时间相关性。DrNet 模型结合对抗损失,将每个帧分解成一个静态的内容表示和时变的姿态表示。DrNet 可以学习到强大的内容和姿态表示,二者结合可以用于生成新的视频帧。
评价方法
对无监督模型的评价通常由两个阶段组成。第一个阶段是用无标注样本进行无监督训练学习表示。第二个阶段是利用学习到的特征训练有监督分类器,评价他们对新的分类任务的泛化能力。
评价准则
我们将以 ImageNet 数据集上的评价方法为例,以 AlexNet 作为主干网络,由五个卷积层和三个全连接层(包含一个 softmax 层,有 1000 个单元)组成。用分类任务测试无监督模型的主要几种设置如下:
非线性分类器
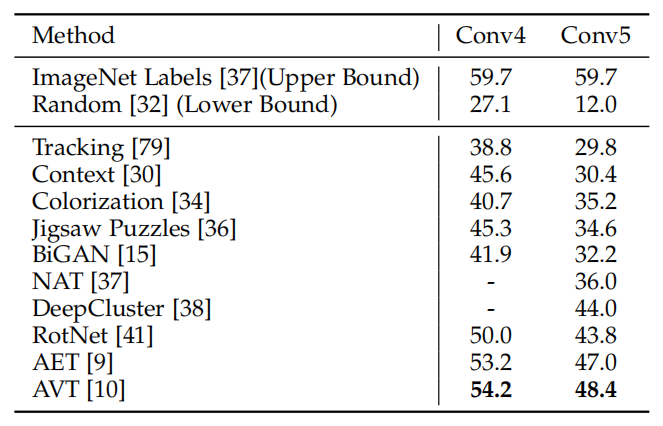
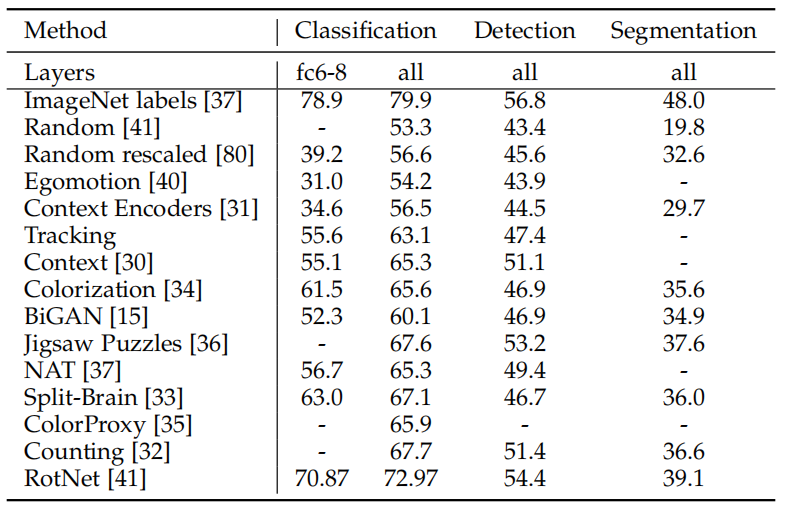
在这种设置下,无监督训练后,固定 Conv4 或 Conv5 前的卷积层。在评测阶段,固定层后的卷积层和全连接层用标注数据进行有监督训练。即利用无监督表示训练非线性分类器。表 1 给出了不同无监督模型的对比。全监督模型(ImageNet 标注数据训练)和随机模型代表了分类表现的上界和下界。
线性分类器
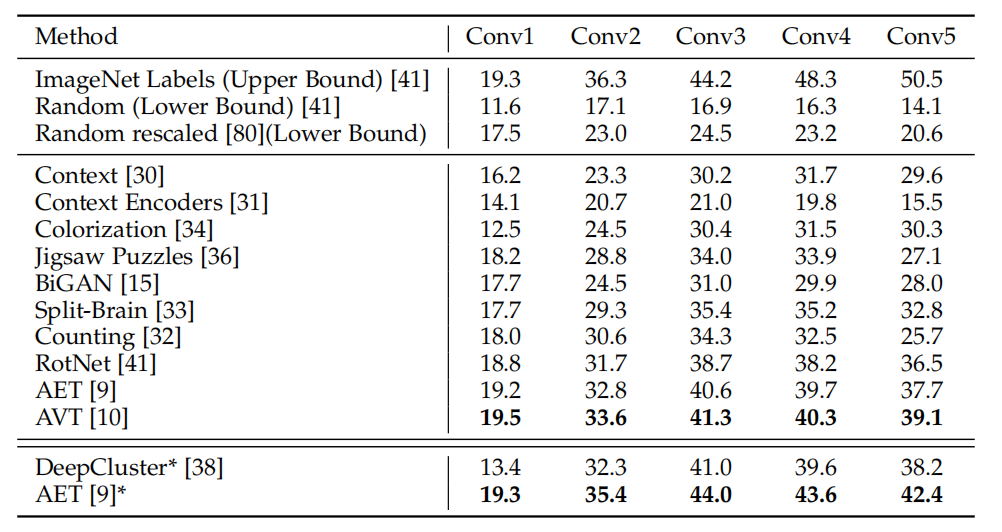
可以在无监督表示的后面添加一个全连接层,作为弱线性分类器。表 2 给出了线性分类器利用不同卷积层的特征进行训练的结果。线性分类器训练效率较高,结果显示,用合适的无监督表示训练线性分类器,训练效率和测试准确率之间可以达到较好的平衡。
跨数据库任务
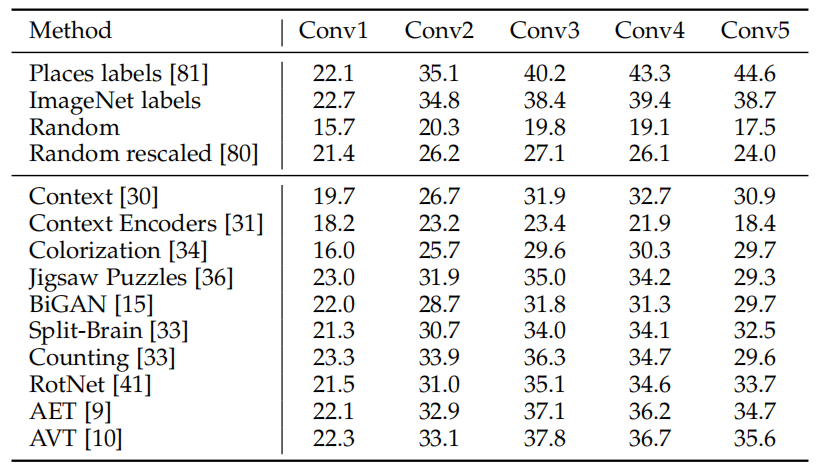
跨数据库任务也被用于比较无监督表示在新数据集任务上的可泛化性。如表 3 所示,通过在 ImageNet 数据集上预训练来评价无监督模型。然后在不同卷积层特征上添加单层的逻辑回归分类器,用 Places 数据集的类标训练。表 4 给出了 PASCAL VOC 数据集上分类、目标检测和语义分割的结果,模型依然是在 ImageNet 上进行无监督预训练。
半监督方法
半监督生成模型
半监督自编码器
参考论文: D. P. Kingma, S. Mohamed, D. J. Rezende, and M. Welling, “Semi-supervised learning with deep generative models,” in Advances in neural information processing systems, 2014, pp. 3581–3589.
作者将无监督变分自编码器拓展为两种形式的半监督模型。第一个是隐特征判别模型(M1)。在 VAE 模型对样本 x 的隐表示 z 上,训练分类器预测类标。VAE 是在有类标和无类标的数据上训练的,分类器是用有类标的样本训练的。第二个生成半监督模型(M2)更复杂一些。除了隐表示 z,x 会通过另一个类别变量 y 生成。
通过使用从 M1 模型中学习到的表示 z1 训练 M2,将 M1 和 M2 结合起来。M2 模型生成自己的隐表示 z2 和类标变量 y。这样就可以得到一个两层的深度生成模型,从(z2,y)中生成 z1,再从 z1 中生成 x:pθ(x, y, z1, z2) = p(y)p(z2)pθ(z1|y, z2)pθ(x|z1).
半监督 GAN
K+1 分类器
参考论文: T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, and X. Chen, “Improved techniques for training gans,” in Advances in Neural Information Processing Systems, 2016, pp. 2234–2242
Saliman 等人提出用 K+1 分类器训练半监督 GAN。用真实样本和生成样本一起训练分类器,分类器需要将样本分为 K 个真实的类和一个虚假类。所有真实的样本被分到 K 个真实的类中的一个,所有的生成样本都分为虚假类。模型采用无监督 GAN 损失和定义在类标数据上的传统的分类损失训练。
此外,作者采用“特征匹配”的技巧来训练生成器。在这里,生成器的训练目标不再是最大化生成样本被分到 K 个真实类的概率,而是最小化真实样本和生成样本在分类器中间层特征之间的差异。这个技巧对提升半监督 GAN 的效果起到了重要作用。
局部 GAN 的类标不变性
参考论文: G.-J. Qi, L. Zhang, H. Hu, M. Edraki, J. Wang, and X.-S. Hua, “Global versus localized generative adversarial nets,” in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
图拉普拉斯矩阵被广泛用于刻画图中相连样本的类标变化。最小化图拉普拉斯矩阵可以对相连的相近类标做出类似的预测。尽管图常常用于近似未知数据流形,图拉普拉斯矩阵实际上是 Laplace-Beltrami 算子在数据流形上的近似。
在论文中,作者提出了局部 GAN,围绕每个样本 x 和隐表示 z 定义了局部生成器 G(x, z)。围绕每个样本 x,可以建立局部坐标系,x 是原点,即 G(x, 0)=x。这样整个数据流形就可以被一簇局部坐标覆盖。可以在流形上定义分类函数的梯度:
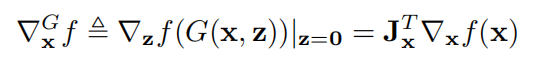
流形上的函数梯度与 Laplace-Beltrami 算子紧密相关:
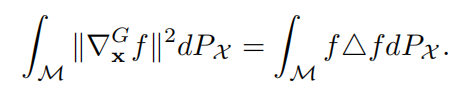
因此,可以直接计算 Laplace-Beltrami 算子,而不需要近似基于图的拉普拉斯矩阵。
然后通过最小化半监督 GAN 损失函数和以下函数:
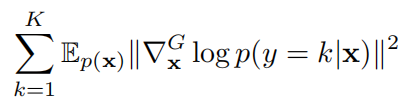
训练半监督分类器 p(y|x),保持数据流形的类标不变性。
半监督非耦合表示
反向图形网络(Inverse Graphics Networks)
参考论文:T. D. Kulkarni, W. F. Whitney, P. Kohli, and J. Tenenbaum, “Deep convolutional inverse graphics network,” in Advances in neural information processing systems, 2015, pp. 2539–2547
深度卷积反向图形网络(DC-IGN)通过设计视觉模型作为反向图形,实现了一个半监督变分自编码模型。它的目标是学习到图形节点集合,通过这些图形节点可以对图像进行变换和渲染。这些图形节点可以视为图像的非耦合表示。
DC-IGN 是在 VAE 模型上建立的,但是训练方式是半监督方式。学习到的表示可以分解为几个外部变量,如光源的方位角、仰角和方向,以及一些内部变量,描述个体、形状、表情和表面纹理的内部变量。在一个 mini-batch 中,只有一个因子是变化的,而其他因子是固定的,因此生成的图像只有一种活跃的 transformation,对应于所选择的沿网络前馈的因子。
非耦合半监督 VAE
参考论文:S. Narayanaswamy, T. B. Paige, J.-W. Van de Meent, A. Desmaison, N. Goodman, P. Kohli, F. Wood, and P. Torr, “Learning disentangled representations with semi-supervised deep generative models,” in Advances in Neural Information Processing Systems, 2017, pp. 5925–5935
论文中,作者提出了半监督 VAE 的一种泛化形式,能够从隐表示中分解出可解释的变量。作者利用神经网络设计了一个图模型,对观测到的和未观测到的隐变量的普遍依赖性建模,并利用随机计算图对生成模型进行推理和训练。
教师-学生模型
教师-学生模型半监督学习背后的思想是获取一个教师模型或教师模型的组合,然后利用他们对无标注样本的预测作为目标,来训练学生模型。通过最大化教师和学生之间的一致性来提升学生模型的表现,和无标注样本分类的稳定性。
噪声教师模型:Γ和Ⅱ模型
参考论文:A. Rasmus, M. Berglund, M. Honkala, H. Valpola, and T. Raiko, “Semi-supervised learning with ladder networks,” in Advances in Neural Information Processing Systems, 2015, pp. 3546–3554
在教师-学生模型中,通过给破坏的模型输入噪声样本可以得到噪声教师,然后通过最小化预测偏置来训练教师和学生之间的模型(Γ模型),或两个破坏复制模型之间的模型(Ⅱ模型)。
Γ和Ⅱ模型的设计思想是:鲁棒的模型应该在数据出现任意变换,或模型有任何扰动的情况下都能进行稳定的预测。
Γ模型通过最小化预测隐表示和干净隐表示之间的误差来训练干净的学生模型。Π-model 模型通过最小化噪声输出之间的误差训练模型。然而,这两种模型都依赖随机噪声来探索它们对噪声输入和扰动模型的适应性,这对于寻找一个合格的教师模型来说效率较低。因此,研究人员提出跟踪一个教师模型的集合,以形成一个更有能力的教师模型,从而产生了时间集合方法和平均教师方法。
教师模型组合:时间组合和平均教师
参考论文:S. Laine and T. Aila, “Temporal ensembling for semi-supervised learning,” arXiv preprint arXiv:1610.02242, 2016
A. Tarvainen and H. Valpola, “Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results,” in Advances in neural information processing systems, 2017, pp. 1195–1204
时间组合和平均教师的相似之处在于随时间组合模型,以得到更好的模型,他们的区别在于时间组合采用预测的指数滑动平均,平均教师采用参数的指数滑动平均。
对于时间组合,在每个训练阶段,对给定样本 x 的目标预测以指数滑动平均(Exponential
Moving Average,EMA)的方式更新:
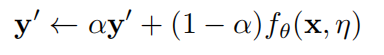
随后得到的 EMA 预测经过进一步正则化作为模型的训练目标 y,模型通过最小化如下函数进行训练:
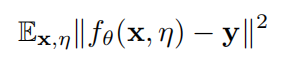
与时间组合相反,平均教师方法对模型参数进行 EMA:
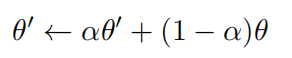
θ是当前学生模型的参数。然后通过最小化以下函数更新学生模型:
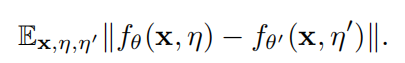
虽然时间组合和平均教师都跟踪之前的模型集来预测教师模型的目标,以监督训练过程,但他们仍然依赖于添加随机噪声来训练具有一致预测的稳定模型。研究表明,如果不知道面对对抗噪声时模型有什么弱点,用随机采样的噪声训练模型,无法获得样本周围的局部各向同性输出分布。这启发了另一种方法,即利用对抗教师来监督训练过程。
对抗教师:虚拟对抗训练
参考论文: T. Miyato, S.-i. Maeda, S. Ishii, and M. Koyama, “Virtual adversarial training: a regularization method for supervised and semi-supervised learning,” IEEE transactions on pattern analysis and machine intelligence, 2018
对抗训练用于约束模型,使其在面对对抗样本时具有强大的鲁棒性。具体来说,该模型经过训练,可以沿着输入样本的对抗方向进行平滑预测。这种方法经过扩展成为虚拟对抗训练(VAT),在虚拟对抗训练中,可以围绕未标记的数据寻找对抗方向,该方向上的模型会发生最大的变化。这样就可以通过半监督的方式训练模型。
假设一个标注或未标注样本 x,和参数化模型,输出类标的条件化分布是 pθ(y|x)。VAT 找到 x 的对抗方向:
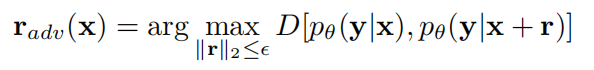
然后通过最小化对抗损失和分类损失训练模型:
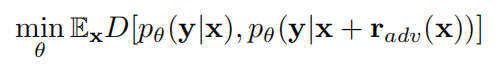
评价方法
数据库
我们首先介绍一下评价半监督方法常用的两个数据库
CIFAR-10 数据库。该数据集包含 50000 张训练图像和 10000 张测试图像,图像类别为 10 种。在实验中,分别用 100 个和 400 个标记样本,和其余的无标注样本训练半监督 LGAN 模型。
SVHN 数据库。该数据库包含大小为 32x32 的街道门牌号图像。训练集和测试集分别包含 73257 和 26032 个门牌号。在实验中,分别用 50 和 100 个标注样本训练模型,剩余的无标注样本作为附加数据。
CIFAR-10 和 SVHN 都是常用的衡量半监督模型表现的数据库,通过用所有的无标注训练图像和不同数量的标注样本训练模型。然后在不同的测试集上测试误差率。
实验结果
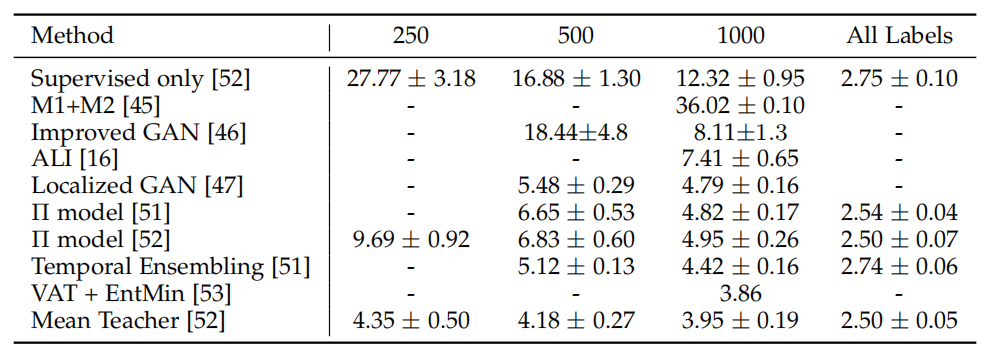
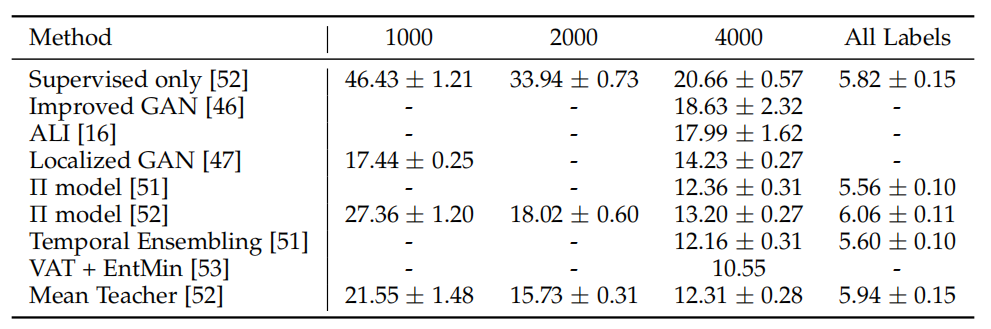
表 5 和表 6 对比了在 SVHN 和 CIFAR-10 数据库上的结果,从中我们可以看出老师-学生模型的表现超过了其他方法。VAT 在这些对比模型中达到了最优表现。
相关和未来研究方向
域适应
无监督域适应
对于无监督域适应,首先从源域的分布 ps 中采样得到一组有标注的源样本 S,再从目标域的分布 pt 中采样得到另一组无标注的样本 T。无监督域适应的目标是得到一个在目标域上也有一定准确性的分类器 f。
在设计无监督域适应算法时,有三种选择:1)共享权重:权重是否在源域和目标域的表示模型中共享;2)基本模型:判别模型或生成模型是否适应从源域到目标域的转换;3)用对抗目标训练模型。
对抗判别域适应
参考论文:E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell, “Adversarial discriminative domain adaptation,” in Computer Vision and Pattern Recognition (CVPR), vol. 1, no. 2, 2017, p. 4
对抗判别域适应(ADDA)中源域和目标域的表示模型的权重是分开的。该算法学习两个不同的模型 Ms 和 Mt,分别将源样本和目标样本映射到对应的表示空间。首先,利用 Ms 的表示和源域的标注样本训练分类器 f:
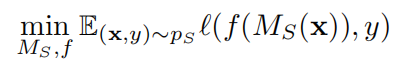
然后固定 Ms,训练目标表示模型 Mt,使两个模型的输出一致分布。基于 GAN 的思想,训练一个域判别器 D,以区分源表示和目标表示:
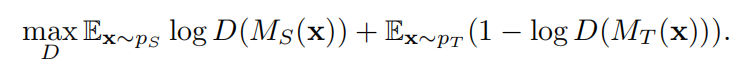
同时通过最小化对抗损失训练目标表示 Mt,尽可能使 Mt 骗过域判别器:
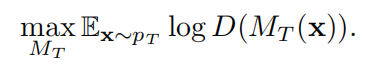
判别器 D 和目标表示 Mt 迭代优化直至收敛。然后,基于在目标域上训练的分类器 f,测试样本可以用基于 f 和目标模型 Mt 的分类器 f(Mt(x))进行分类。
梯度反向层(Gradient Reversal Layer,GRL)
参考论文:Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. Marchand, and V. Lempitsky, “Domain adversarial training of neural networks,” The Journal of Machine Learning Research, vol. 17, no. 1, pp. 2096–2030, 2016
与 ADDA 不同,梯度反向层模型共享源域和目标域表示模型的权重(Ms=Mt=M)。分类器 f,共享表示 M 以及域判别器 D 联合训练。首先对共享模型 M 和域判别器 D 进行约束:
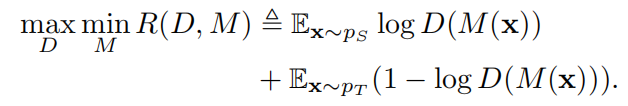
换言之,共享表示 M 将无论是源域还是目标域的样本映射到相同的空间,让 D 无法区分它们。
该约束和分类损失一起训练模型,转化为以下联和优化问题:
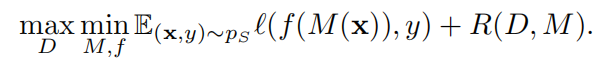
半监督域适应
像素级域适应(Pixel-Level Domain Adaptation,PixelDA)
参考论文:K. Bousmalis, N. Silberman, D. Dohan, D. Erhan, and D. Krishnan, “Unsupervised pixel-level domain adaptation with generative adversarial networks,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol. 1, no. 2, 2017, p. 7
PixelDA 选择直接用 GAN 的生成器 G(x, z)将源图像 x~pS 转换为目标图像,让采样噪声 z 匹配目标分布 pT。然后,通过结合有标注的生成图像{(G(x, z), y)|(x, y)~pS}和有标注的目标图像{(x, y)|(x, y)~pT},以半监督的方式训练分类器。
参考论文:A. Rozantsev, M. Salzmann, and P. Fua, “Beyond sharing weights for deep domain adaptation,” IEEE transactions on pattern analysis and machine intelligence, 2018
此外,研究人员提出了一个双流结构,同时为源域和目标域训练两个网络。它并不直接将域不变性作为条件,因为具有域不变特性(domain invariant)的特征会破坏分类器的鉴别能力。相反,它通过对源数据和目标数据之间的相似性和差异进行建模,来直接学习从源域到目标域的改变。
域聚合(Domain Confusion)
参考论文:E. Tzeng, J. Hoffman, T. Darrell, and K. Saenko, “Simultaneous deep transfer across domains and tasks,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 4068– 4076
域聚合提出一个目标函数,通过将两个域看作是相同的,将两个独立的表示映射到一个均匀分布上训练模型。
CoGAN
参考论文:M.-Y. Liu and O. Tuzel, “Coupled generative adversarial networks,” in Advances in neural information processing systems, 2016, pp. 469–477
CoGAN 训练两个 GAN,分别生成源图像和目标图像。通过将两个 GAN 的高层参数共享,实现了域不变性,然后基于判别器的输出训练分类器。
变换等变性 VS 变换不变性
一个更偏向理论的课题在于揭示表示学习中变换等变性与不变性之间的内在关系。一方面,变换等变表示(TER)被认为是实现无监督学习最先进表现的关键标准之一。另一方面,变换不变性对有监督任务的训练,如图像和目标的识别也是十分重要和必要的。
这两个标准似乎是矛盾的,但实际上它们在卷积神经网络中能够很好地共存:卷积特征与图像变换等变,而输出预测在不同的变换下应该是不变的。
事实上,无监督表示学习更多地关注对新任务的可泛化性,而有监督任务对给定任务的分类能力更感兴趣。如何将变换等变和不变性的追求适当地结合起来,使泛化和分类之间达到更好的平衡?我们是否应该像 CNN 中那样,将变换等变表示的无监督学习从变换不变的分类器的监督训练中分离出来?我们相信,对这些问题的回答可能会带来更具变革性和高效的结合这两项原则的方法,以应对新任务中的小数据挑战。这是我们未来要回答的一个基本问题。
论文原文链接:
https://arxiv.org/pdf/1903.11260.pdf


暂无签名

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论