

2019 年以来,Lindorm 已经服务了包括淘宝、天猫、蚂蚁、菜鸟、妈妈、优酷、高德、大文娱等数十个 BU,在今年的双十一中,Lindorm 峰值请求达到了 7.5 亿次每秒,天吞吐 22.9 万亿次,平均响应时间低于 3ms,整体存储的数据量达到了数百 PB。
这些数字的背后,凝聚了 HBase&Lindorm 团队多年以来的汗水和心血。Lindorm 脱胎于 HBase,是团队多年以来承载数百 PB 数据,亿级请求量,上千个业务后,在面对规模成本压力,以及 HBase 自身缺陷下,全面重构和引擎升级的全新产品。相比 HBase,Lindorm 无论是性能,功能还是可用性上,都有了巨大飞跃。本文将从功能、可用性、性能成本、服务生态等维度介绍 Lindorm 的核心能力与业务表现,最后分享部分我们正在进行中的一些项目。
极致优化,超强性能
Lindorm 比 HBase 在 RPC、内存管理,缓存、日志写入等方面做了深度的优化,引入了众多新技术,大幅提升了读写性能,在相同硬件的情况下,吞吐可达到 HBase 的 5 倍以上,毛刺更是可以达到 HBase 的 1/10。这些性能数据,并不是在实验室条件下产生的,而是在不改动任何参数的前提下,使用开源测试工具 YCSB 跑出来的成绩。我们把测试的工具和场景都公布在阿里云的帮助文件中,任何人都可以依照指南自己跑出一样的结果。
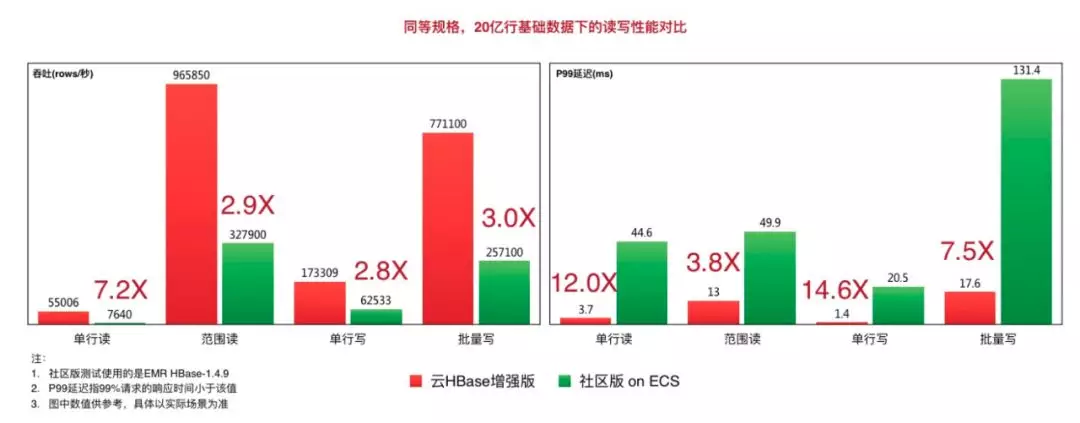
取得这么优异的性能的背后,是 Lindorm 中积攒多年的“黑科技”,下面,我们简单介绍下 Lindorm 内核中使用到的部分“黑科技”。
Trie Index
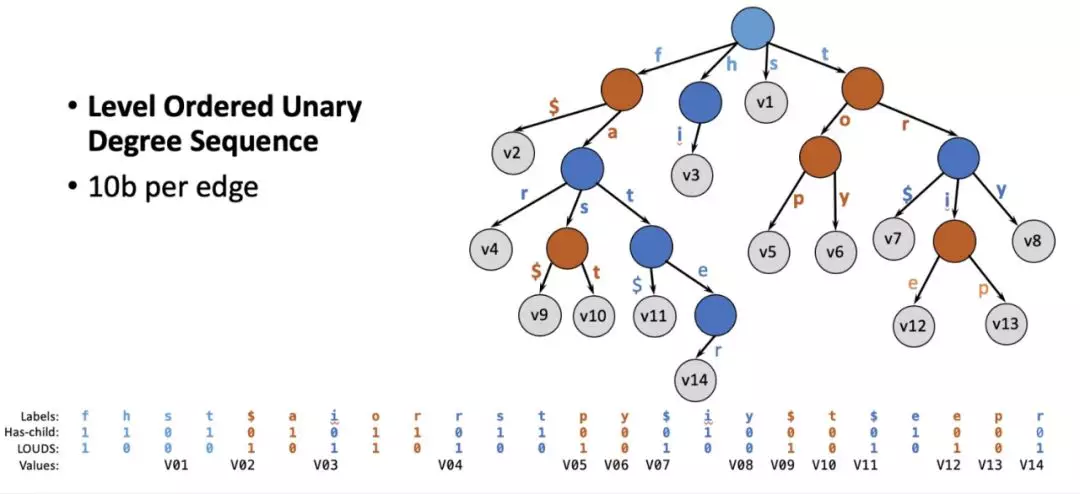
Lindorm 的文件 LDFile(类似 HBase 中的 HFile)是只读 B+ 树结构,其中文件索引是至关重要的数据结构。在 block cache 中有高优先级,需要尽量常驻内存。如果能降低文件索引所占空间大小,我们可以节省 block cache 中索引所需要的宝贵内存空间。或者在索引空间不变的情况下,增加索引密度,降低 data block 的大小,从而提高性能。而 HBase 中的索引 block 中存的是全量的 Rowkey,而在一个已经排序好的文件中,很多 Rowkey 都是有共同前缀的。
数据结构中的 Trie (前缀树) 结构能够让共同前缀只存一份,避免重复存储带来的浪费。但是传统前缀树结构中,从一个节点到下一个节点的指针占用空间太多,整体而言得不偿失。这一情况有望用 Succinct Prefix Tree 来解决。SIGMOD2018 年的最佳论文 Surf 中提出了一种用 Succinct Prefix Tree 来取代 bloom filter,并同时提供 range filtering 的功能。我们从这篇文章得到启发,用 Succinct Trie 来做 file block index。
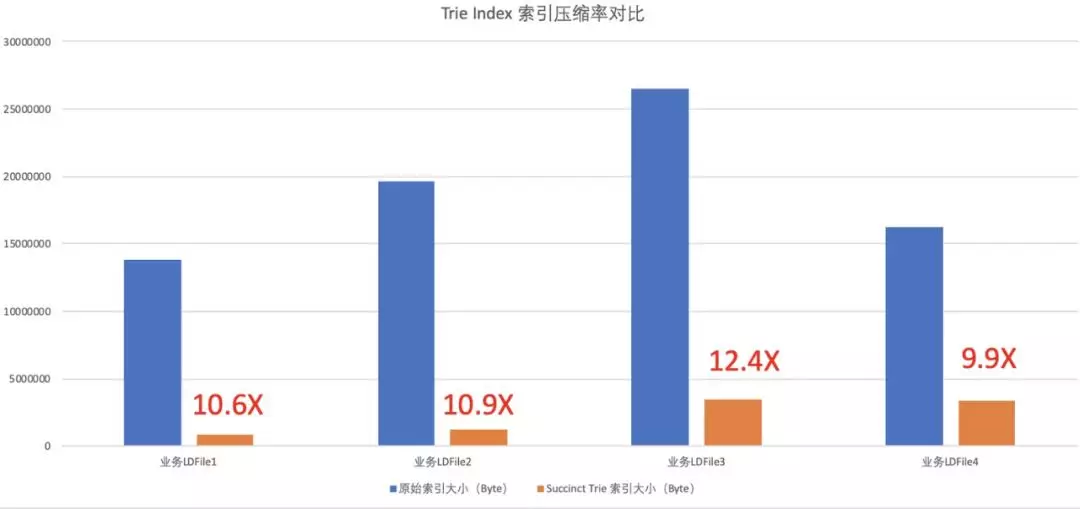
我们在线上的多个业务中使用了 Trie index 实现的索引结构。结果发现,各个场景中,Trie index 可以大大缩小索引的体积,最多可以压缩 12 倍的索引空间!节省的这些宝贵空间让内存 Cache 中能够存放更多的索引和数据文件,大大提高了请求的性能。
ZGC 加持,百 GB 堆平均 5ms 暂停
ZGC(Powerd by Dragonwell JDK)是下一代 Pauseless GC 算法的代表之一,其核心思想是 Mutator 利用内存读屏障(Read Barrier)识别指针变化,使得大部分的标记(Mark)与合并(Relocate)工作可以放在并发阶段执行。
这样一项实验性技术,在 Lindorm 团队与 AJDK 团队的紧密合作下,进行了大量的改进与改造工作。使得 ZGC 在 Lindorm 这个场景上实现了生产级可用,主要工作包括:
Lindorm 内存自管理技术,数量级减少对象数与内存分配速率。(比如说阿里 HBase 团队贡献给社区的 CCSMap)。
AJDK ZGC Page 缓存机制优化(锁、Page 缓存策略)。
AJDK ZGC 触发时机优化,ZGC 无并发失败。AJDK ZGC 在 Lindorm 上稳定运行两个月,并顺利通过双十一大考。其 JVM 暂停时间稳定在 5ms 左右,最大暂停时间不超过 8ms。ZGC 大大改善了线上运行集群的 RT 与毛刺指标,平均 RT 优化 15%~20%,P999 RT 减少一倍。在今年双十一蚂蚁风控集群中,在 ZGC 的加持下,P999 时间从 12ms 降低到了 5ms。
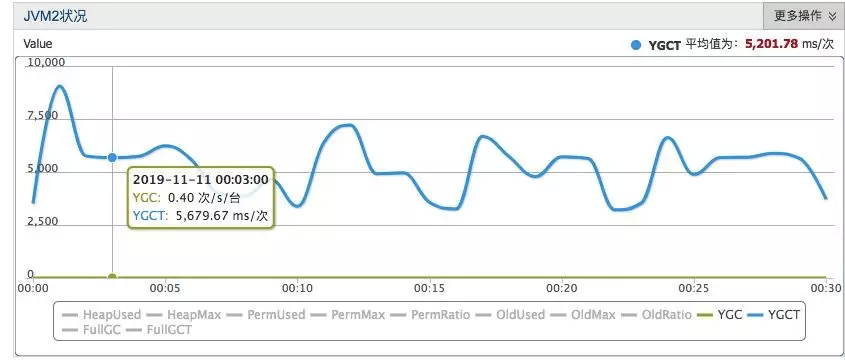
注:图中的单位应该为 us,平均 GC 在 5ms
LindormBlockingQueue
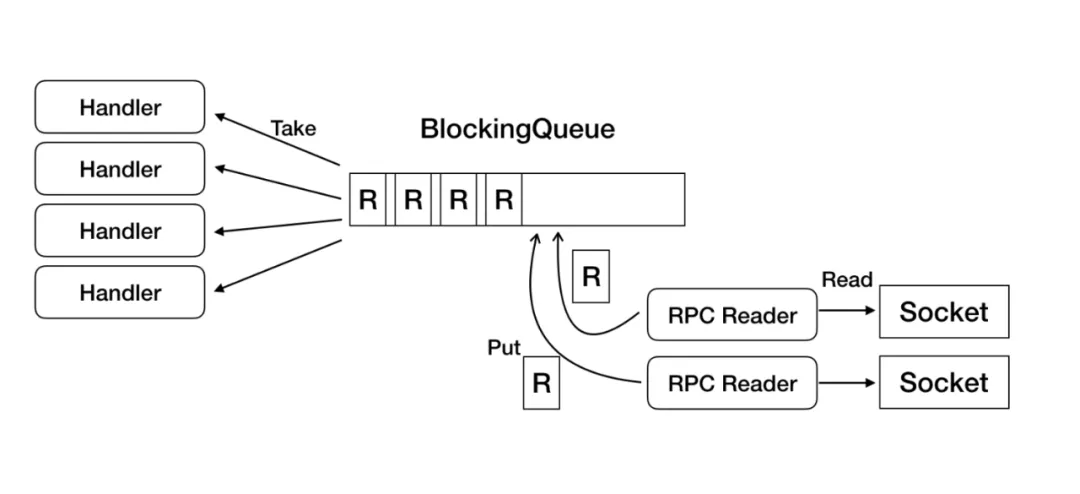
上图是 HBase 中的 RegionServer 从网络上读取 RPC 请求并分发到各个 Handler 上执行的流程。HBase 中的 RPC Reader 从 Socket 上读取 RPC 请求放入 BlockingQueue,Handler 订阅这个 Queue 并执行请求。而这个 BlockingQueue,HBase 使用的是 Java 原生的 JDK 自带的 LinkedBlockingQueue。
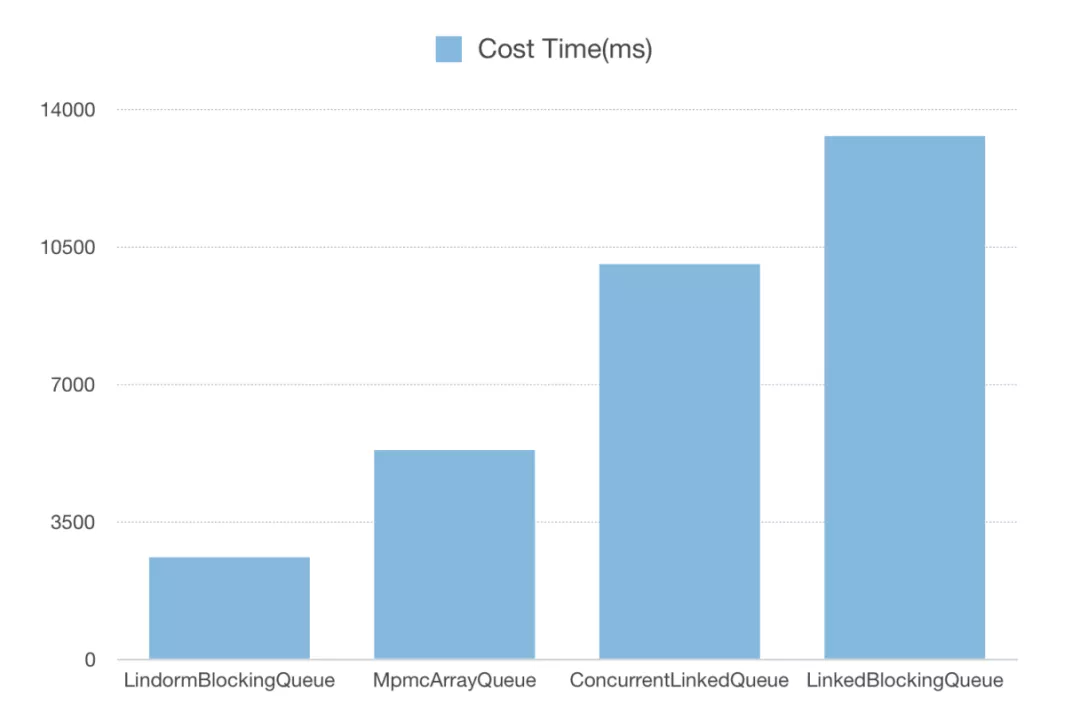
LinkedBlockingQueue 利用 Lock 与 Condition 保证线程安全与线程之间的同步,虽然经典易懂,但当吞吐增大时,这个 queue 会造成严重的性能瓶颈。因此在 Lindorm 中全新设计了 LindormBlockingQueue,将元素维护在 Slot 数组中。维护 head 与 tail 指针,通过 CAS 操作对进队列进行读写操作,消除了临界区。并使用 Cache Line Padding 与脏读缓存加速,同时可定制多种等待策略(Spin/Yield/Block),避免队列为空或为满时,频繁进入 Park 状态。LindormBlockingQueue 的性能非常突出,相比于原先的 LinkedBlockingQueue 性能提升 4 倍以上。
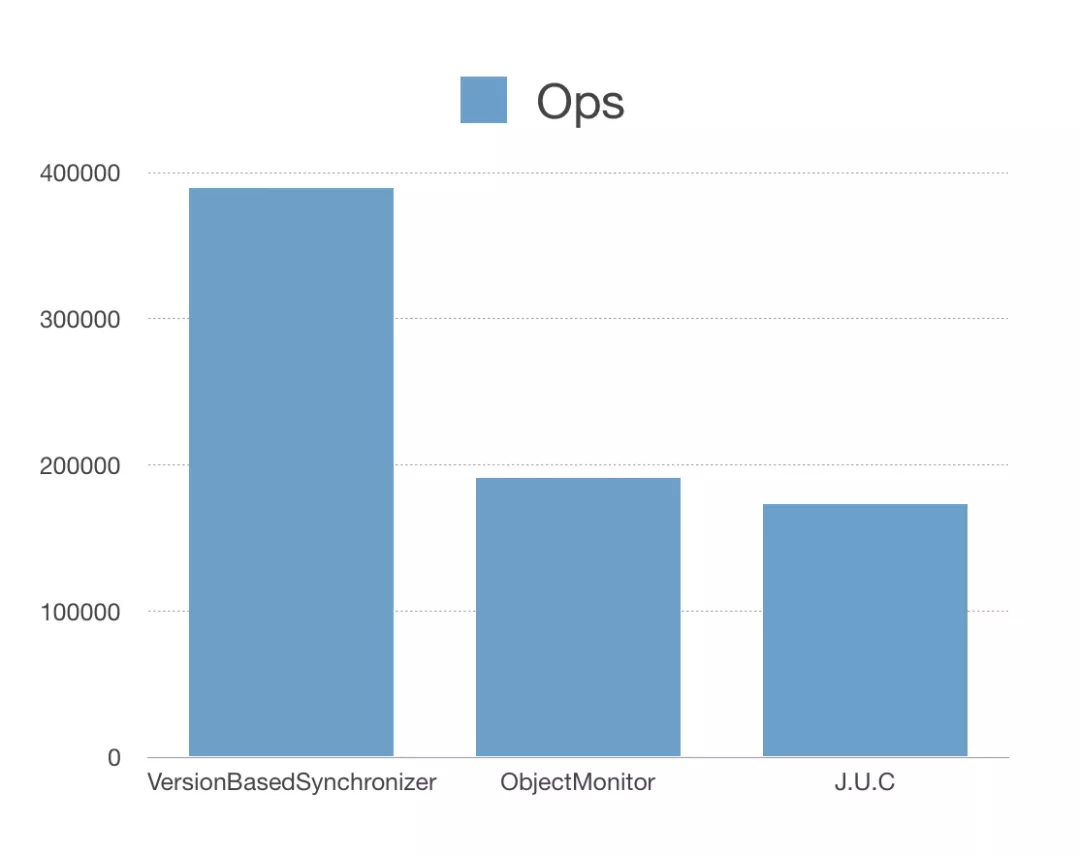
VersionBasedSynchronizer
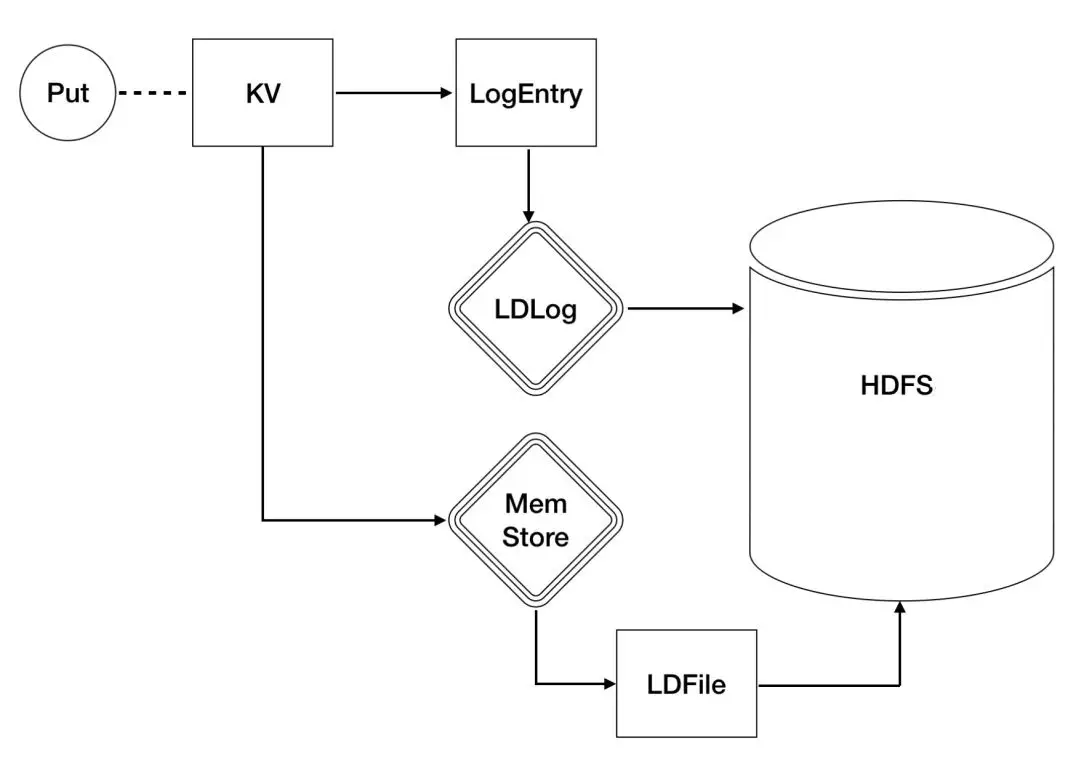
LDLog 是 Lindorm 中用于系统 failover 时进行数据恢复时的日志,以保障数据的原子性和可靠性。在每次数据写入时,都必须先写入 LDLog。LDLog 写入成功之后,才可以进行后续的写入 memstore 等操作。因此 Lindorm 中的 Handler 都必须等待 WAL 写入完成后再被唤醒以进行下一步操作,在高压条件下,无用唤醒会造成大量的 CPU Context Switch 造成性能下降。针对这个问题,Lindorm 研发了基于版本的高并发多路线程同步机制(VersionBasedSynchronizer)来大幅优化上下文切换。
VersionBasedSynchronizer 的主要思路是让 Handler 的等待条件被 Notifier 感知,减少 Notifier 的唤醒压力。经过模块测试 VersionBasedSynchronizer 的效率是 JDK 自带的 ObjectMonitor 和 J.U.C(java util concurrent 包)的两倍以上。
全面无锁化
HBase 内核在关键路径上有大量的锁,在高并发场景下,这些锁都会造成线程争抢和性能下降。Lindorm 内核对关键链路上的锁都做了无锁化处理,如 MVCC,WAL 模块中的锁。另外,HBase 在运行过程中会产生的各种指标,如 qps,rt,cache 命中率等等。而在记录这些 Metrics 的“不起眼”操作中,也会有大量的锁。面对这样的问题,Lindorm 借鉴了 tcmalloc 的思想,开发了 LindormThreadCacheCounter,来解决 Metrics 的性能问题。
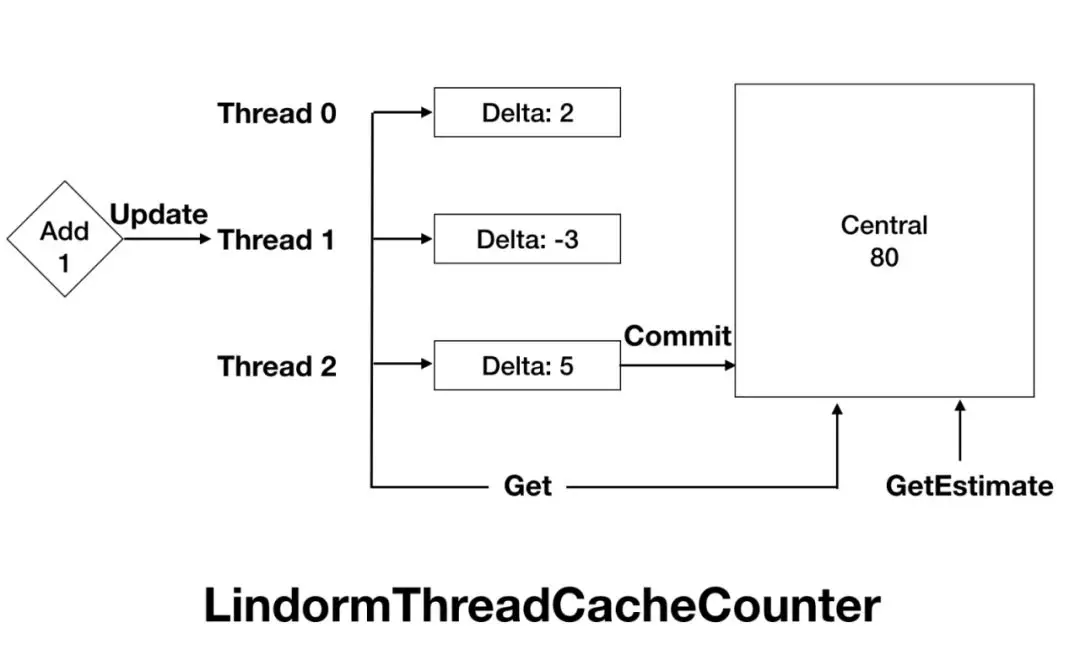
Handler 协程化
在高并发应用中,一个 RPC 请求的实现往往包含多个子模块,涉及到若干次 IO。这些子模块的相互协作,系统的 ContextSwitch 相当频繁。ContextSwitch 的优化是高并发系统绕不开的话题,各位高手都各显神通,业界有非常多的思想与实践。其中 coroutine(协程)和 SEDA(分阶段事件驱动)方案是我们着重考察的方案。基于工程代价,可维护性,代码可读性三个角度考虑,Lindorm 选择了协程的方式进行异步化优化。我们利用了阿里 JVM 团队提供的 Dragonwell JDK 内置的 Wisp2.0 功能实现了 HBase Handler 的协程化,Wisp2.0 开箱即用,有效地减少了系统的资源消耗,优化效果比较客观。
全新 Encoding 算法
从性能角度考虑,HBase 通常需要将 Meta 信息装载进 block cache。如果将 block 大小较小,Meta 信息较多,会出现 Meta 无法完全装入 Cache 的情况, 性能下降。如果 block 大小较大,经过 Encoding 的 block 的顺序查询的性能会成为随机读的性能瓶颈。针对这一情况,Lindorm 全新开发了 Indexable Delta Encoding,在 block 内部也可以通过索引进行快速查询,seek 性能有了较大提高。Indexable Delta Encoding 原理如图所示:
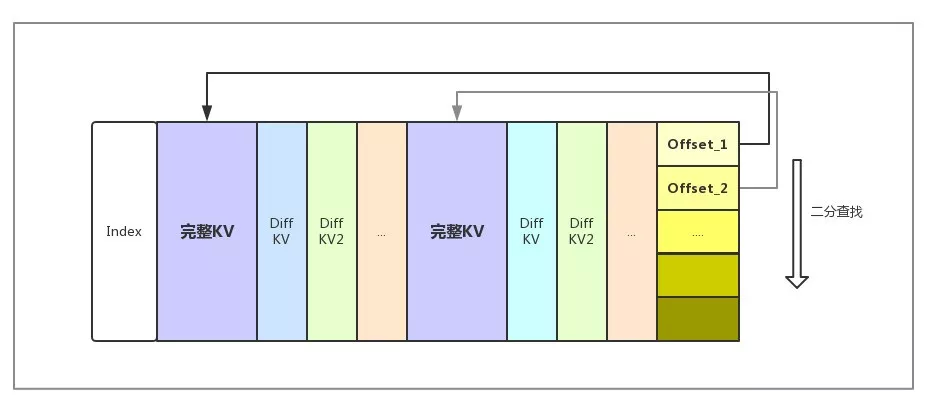
通过 Indexable Delta Encoding, HFile 的随机 seek 性能相对于使用之前翻了一倍,以 64K block 为例,随机 seek 性能基本与不做 encoding 相近(其他 encoding 算法会有一定性能损失)。在全 cache 命中的随机 Get 场景下,相对于 Diff encoding RT 下降 50%
其他
相比社区版 HBase,Lindorm 还有多达几十项的性能优化和重构,引入了众多新技术,由于篇幅有限,这里只能列举一部分,其他的核心技术,比如:
CCSMap
自动规避故障节点的并发三副本日志协议 (Quorum-based write)
高效的批量组提交(Group Commit)
无碎片的高性能缓存—Shared BucketCache
Memstore Bloomfilter
面向读写的高效数据结构
GC-Invisible 内存管理
在线计算与离线作业架构分离
JDK/操作系统深度优化
FPGA offloading Compaction
用户态 TCP 加速
……
丰富的查询模型,降低开发门槛
原生的 HBase 只支持 KV 结构的查询,虽然简单,但是在面对各项业务的复杂需求时,显的有点力不从心。因此,在 Lindorm 中,我们针对不同业务的特点,研发了多种查询模型,通过更靠近场景的 API 和索引设计,降低开发门槛。
WideColumn 模型(原生 HBase API)
WideColumn 是一种与 HBase 完全一致的访问模型和数据结构,从而使得 Lindrom 能 100%兼容 HBase 的 API。用户可以通过 Lindorm 提供的高性能原生客户端中的 WideColumn API 访问 Lindorm,也可以通过 alihbase-connector 这个插件,使用 HBase 客户端及 API(无需任何代码改造)直接访问 Lindorm。同时,Lindorm 使用了轻客户端的设计,将大量数据路由、批量分发、超时、重试等逻辑下沉到服务端,并在网络传输层做了大量的优化,使得应用端的 CPU 消耗可以大大节省。像下表中,相比于 HBase,使用 Lindorm 后的应用侧 CPU 使用效率提升 60%,网络带宽效率提升 25%。

注:表中的客户端 CPU 代表 HBase/Lindorm 客户端消耗的 CPU 资源,越小越好。
在 HBase 原生 API 上,我们还独家支持了高性能二级索引,用户可以使用 HBase 原生 API 写入数据过程中,索引数据透明地写入索引表。在查询过程中,把可能全表扫的 Scan + Filter 大查询,变成可以先去查询索引表,大大提高了查询性能。关于高性能原生二级索引,大家可以参考:
https://help.aliyun.com/document_detail/144577.html
TableService 模型(SQL、二级索引)
HBase 中只支持 Rowkey 这一种索引方式,对于多字段查询时,通常效率低下。为此,用户需要维护多个表来满足不同场景的查询需求,这在一定程度上既增加了应用的开发复杂性,也不能很完美地保证数据一致性和写入效率。并且 HBase 中只提供了 KV API,只能做 Put、Get、Scan 等简单 API 操作,也没有数据类型,所有的数据都必须用户自己转换和储存。对于习惯了 SQL 语言的开发者来说,入门的门槛非常高,而且容易出错。
为了解决这一痛点,降低用户使用门槛,提高开发效率,在 Lindorm 中我们增加了 TableService 模型,其提供丰富的数据类型、结构化查询表达 API,并原生支持 SQL 访问和全局二级索引,解决了众多的技术挑战,大幅降低普通用户的开发门槛。通过 SQL 和 SQL like 的 API,用户可以方便地像使用关系数据库那样使用 Lindorm。下面是一个 Lindorm SQL 的简单示例。
相比于关系数据库的 SQL,Lindorm 不具备多行事务和复杂分析(如 Join、Groupby)的能力,这也是两者之间的定位差异。
相比于 HBase 上 Phoenix 组件提供的二级索引,Lindorm 的二级索引在功能、性能、稳定性上远远超过 Phoenix,下图是一个简单的性能对比。
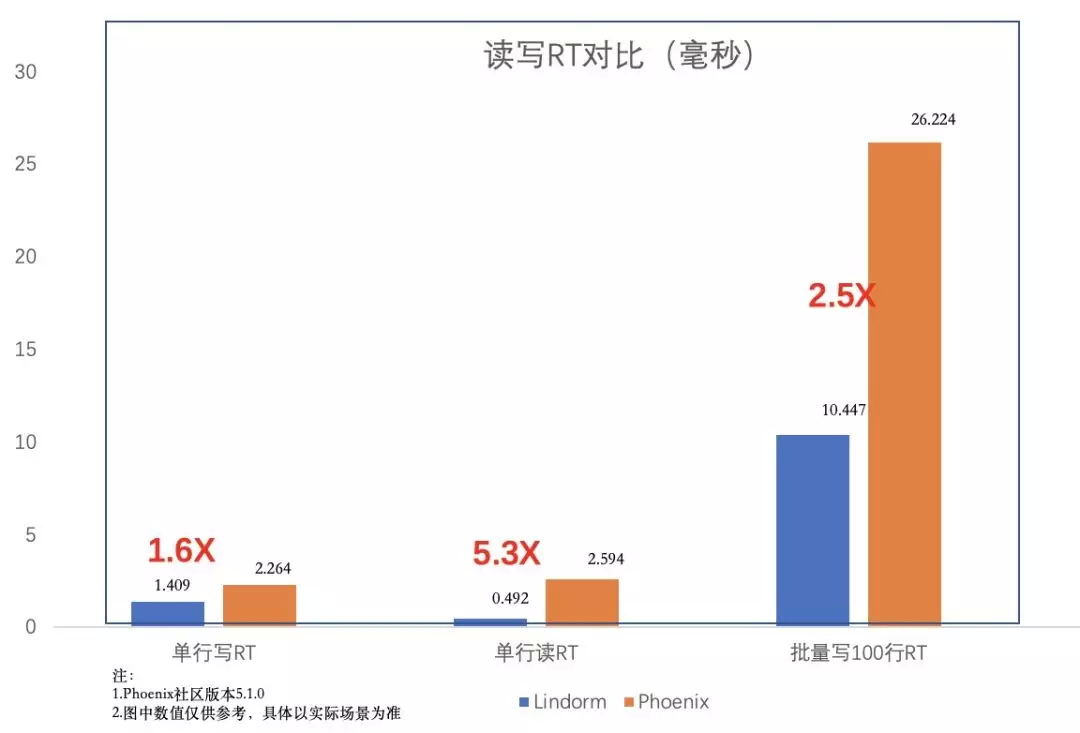
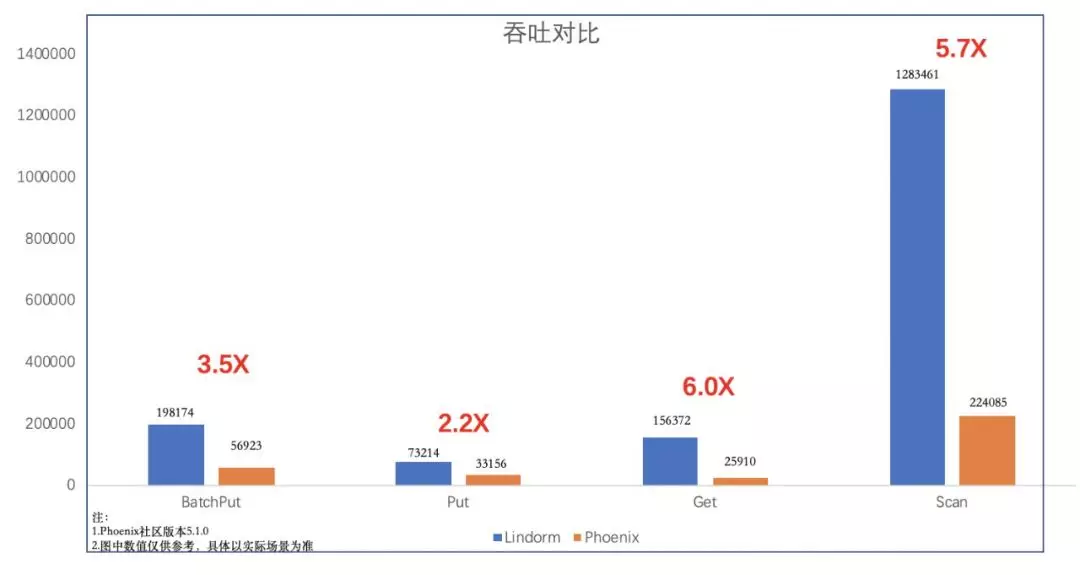
注:该模型已经在阿里云 HBase 增强版上内测,感兴趣的用户可以联系云 HBase 答疑钉钉号或者在阿里云上发起工单咨询。
FeedStream 模型
现代互联网架构中,消息队列承担了非常重要的职责,可以极大的提升核心系统的性能和稳定性。其典型的应用场景有包括系统解耦,削峰限流,日志采集,最终一致保证,分发推送等等。
常见的消息队列包括 RabbitMq,Kafka 以及 RocketMq 等等。这些数据库尽管从架构和使用方式和性能上略有不同,但其基本使用场景都相对接近。然而,传统的消息队列并非完美,其在消息推送,feed 流等场景存在以下问题:
存储:不适合长期保存数据,通常过期时间都在天级
删除能力:不支持删除指定数据 entry
查询能力:不支持较为复杂的查询和过滤条件
一致性和性能难以同时保证:类似于 Kafka 之类的数据库更重吞吐,为了提高性能存在了某些状况下丢数据的可能,而事务处理能力较好的消息队列吞吐又较为受限。
Partition 快速拓展能力:通常一个 Topc 下的 partition 数目都是固定,不支持快速扩展。
物理队列/逻辑队列:通常只支持少量物理队列(如每个 partition 可以看成一个队列),而业务需要的在物理队列的基础上模拟出逻辑队列,如 IM 系统中为每个用户维护一个逻辑上的消息队列,用户往往需要很多额外的开发工作。
针对上述需求,Lindorm 推出了队列模型 FeedStreamService,能够解决海量用户下的消息同步,设备通知,自增 ID 分配等问题。
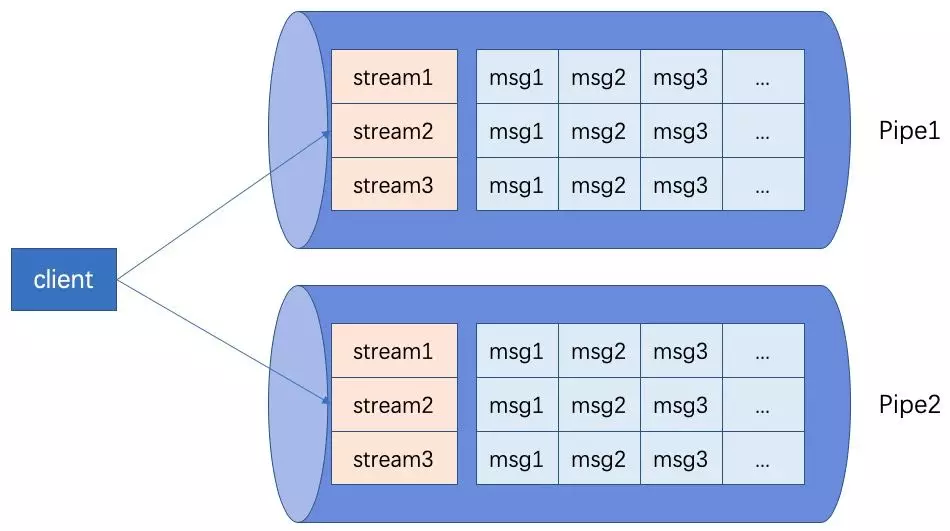
FeedStream 模型在今年手机淘宝消息系统中扮演了重要角色,解决了手机淘宝消息推送保序,幂等等难题。在今年双十一中,手淘的盖楼和回血大红包推送都有 Lindorm 的身影。手淘消息的推送中,峰值超过了 100w/s,做到了分钟级推送全网用户。
注:该模型已经在阿里云 HBase 增强版上内测,感兴趣的用户可以联系云 HBase 答疑钉钉号或者在阿里云上发起工单咨询。
全文索引模型
虽然 Lindorm 中的 TableService 模型提供了数据类型和二级索引。但是,在面对各种复杂条件查询和全文索引的需求下,还是显得力不从心,而 Solr 和 ES 是优秀的全文搜索引擎。使用 Lindorm+Solr/ES,可以最大限度发挥 Lindorm 和 Solr/ES 各自的优点,从而使得我们可以构建复杂的大数据存储和检索服务。Lindorm 内置了外部索引同步组件,能够自动地将写入 Lindorm 的数据同步到外部索引组件如 Solr 或者 ES 中。这种模型非常适合需要保存大量数据,而查询条件的字段数据仅占原数据的一小部分,并且需要各种条件组合查询的业务,例如:
常见物流业务场景,需要存储大量轨迹物流信息,并需根据多个字段任意组合查询条件
交通监控业务场景,保存大量过车记录,同时会根据车辆信息任意条件组合检索出感兴趣的记录
各种网站会员、商品信息检索场景,一般保存大量的商品/会员信息,并需要根据少量条件进行复杂且任意的查询,以满足网站用户任意搜索需求等。
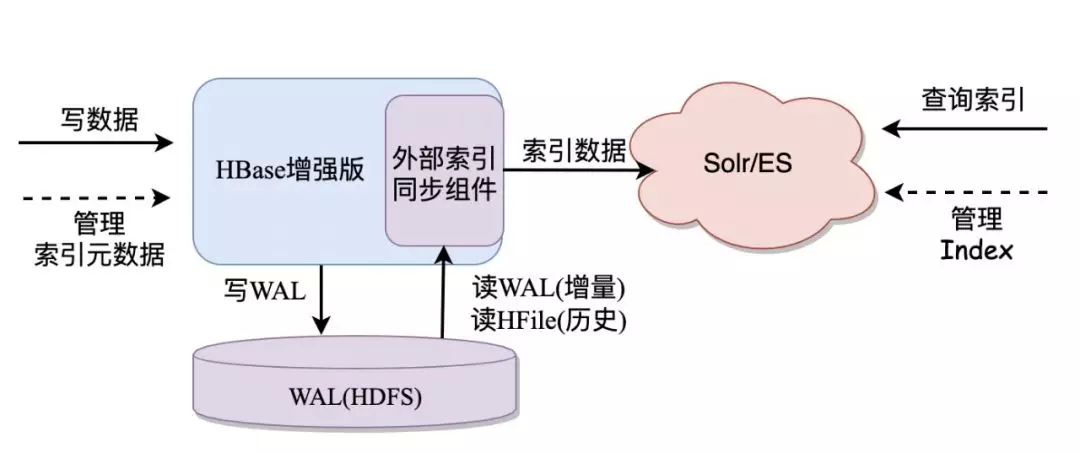
全文索引模型已经在阿里云上线,支持 Solr/ES 外部索引。目前,索引的查询用户还需要直接查询 Solr/ES 再来反查 Lindorm,后续我们会用 TableService 的语法把查询外部索引的过程包装起来,用户全程只需要和 Lindorm 交互,即可获得全文索引的能力。
更多模型在路上
除了上述这些模型,我们还会根据业务的需求和痛点,开发更多简单易用的模型,方便用户使用,降低使用门槛。像时序模型,图模型等,都已经在路上,敬请期待。
零干预、秒恢复的高可用能力
从一个婴儿成长为青年,阿里 HBase 摔过很多次,甚至头破血流,我们在客户的信任之下幸运的成长。在 9 年的阿里应用过程中,我们积累了大量的高可用技术,而这些技术,都应用到了 HBase 增强版中。
MTTR 优化
HBase 是参照 Gooogle 著名论文 BigTable 的开源实现,其中最核心特点是数据持久化存储于底层的分布式文件系统 HDFS,通过 HDFS 对数据的多副本维护来保障整个系统的高可靠性,而 HBase 自身不需要去关心数据的多副本及其一致性,这有助于整体工程的简化,但也引入了"服务单点"的缺陷,即对于确定的数据的读写服务只有发生固定的某个节点服务器,这意味着当一个节点宕机后,数据需要通过重放 Log 恢复内存状态,并且重新派发给新的节点加载后,才能恢复服务。
当集群规模较大时,HBase 单点故障后恢复时间可能会达到 10-20 分钟,大规模集群宕机的恢复时间可能需要好几个小时!而在 Lindorm 内核中,我们对 MTTR(平均故障恢复时间)做了一系列的优化,包括故障恢复时先上线 region、并行 replay、减少小文件产生等众多技术。将故障恢复速度提升 10 倍以上!基本上接近了 HBase 设计的理论值。
可调的多一致性
在原来的 HBase 架构中,每个 region 只能在一个 RegionServer 中上线,如果这个 region server 宕机,region 需要经历 Re-assgin,WAL 按 region 切分,WAL 数据回放等步骤后,才能恢复读写。这个恢复时间可能需要数分钟,对于某些高要求的业务来说,这是一个无法解决的痛点。另外,虽然 HBase 中有主备同步,但故障下只能集群粒度的手动切换,并且主和备的数据只能做到最终一致性,而有一些业务只能接受强一致,HBase 在这点上望尘莫及。
Lindorm 内部实现了一种基于 Shared Log 的一致性协议,通过分区多副本机制达到故障下的服务自动快速恢复的能力,完美适配了存储分离的架构, 利用同一套体系即可支持强一致语义,又可以选择在牺牲一致性的前提换取更佳的性能和可用性,实现多活,高可用等多种能力。
在这套架构下,Lindorm 拥有了以下几个一致性级别,用户可以根据自己的业务自由选择一致性级别:

注:该功能暂时未在阿里云 HBase 增强版上对外开放
客户端高可用切换
虽然说目前 HBase 可以组成主备,但是目前市面上没有一个高效地客户端切换访问方案。HBase 的客户端只能访问固定地址的 HBase 集群。如果主集群发生故障,用户需要停止 HBase 客户端,修改 HBase 的配置后重启,才能连接备集群访问。或者用户在业务侧必须设计一套复杂地访问逻辑来实现主备集群的访问。阿里 HBase 改造了 HBase 客户端,流量的切换发生在客户端内部,通过高可用的通道将切换命令发送给客户端,客户端会关闭旧的链接,打开与备集群的链接,然后重试请求。
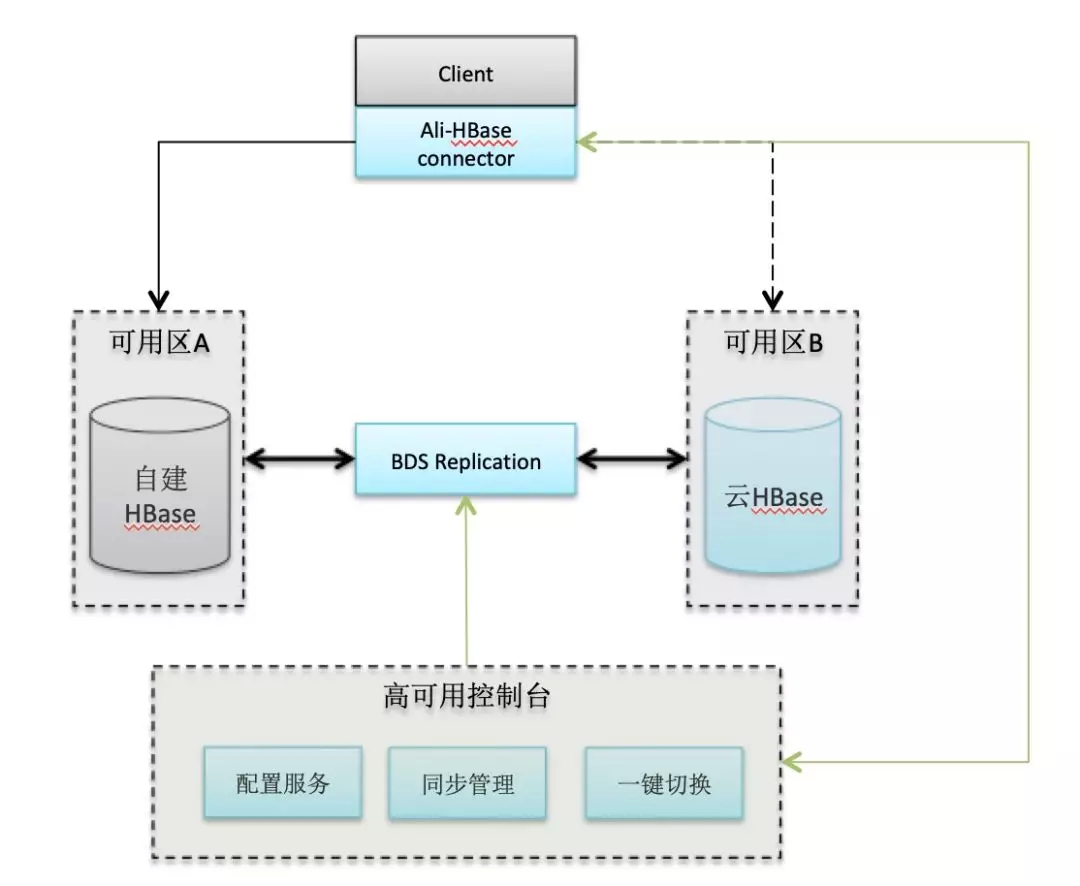
如果需要使用此项功能,请参考高可用帮助文档:https://help.aliyun.com/document_detail/140940.html
云原生,更低使用成本
Lindorm 从立项之初就考虑到上云,各种设计也能尽量复用云上基础设施,为云的环境专门优化。比如在云上,我们除了支持云盘之外,我们还支持将数据存储在 OSS 这种低成本的对象存储中减少成本。我们还针对 ECS 部署做了不少优化,适配小内存规格机型,加强部署弹性,一切为了云原生,为了节省客户成本。
ECS+云盘的极致弹性
目前 Lindorm 在云上的版本 HBase 增强版均采用 ECS+云盘部署(部分大客户可能采用本地盘),ECS+云盘部署的形态给 Lindorm 带来了极致的弹性。

最开始的时候,HBase 在集团的部署均采用物理机的形式。每个业务上线前,都必须先规划好机器数量和磁盘大小。在物理机部署下,往往会遇到几个难以解决的问题:
业务弹性难以满足:当遇到业务突发流量高峰或者异常请求时,很难在短时间内找到新的物理机扩容。
存储和计算绑定,灵活性差:物理机上 CPU 和磁盘的比例都是一定的,但是每个业务的特点都不一样,采用一样的物理机,有一些业务计算资源不够,但存储过剩,而有些业务计算资源过剩,而存储瓶颈。特别是在 HBase 引入混合存储后,HDD 和 SSD 的比例非常难确定,有些高要求的业务常常会把 SSD 用满而 HDD 有剩余,而一些海量的离线型业务 SSD 盘又无法利用上。
运维压力大:使用物理机时,运维需要时刻注意物理机是否过保,是否有磁盘坏,网卡坏等硬件故障需要处理,物理机的报修是一个漫长的过程,同时需要停机,运维压力巨大。对于 HBase 这种海量存储业务来说,每天坏几块磁盘是非常正常的事情。而当 Lindorm 采用了 ECS+云盘部署后,这些问题都迎刃而解。
ECS 提供了一个近似无限的资源池。当面对业务的紧急扩容时,我们只需在资源池中申请新的 ECS 拉起后,即可加入集群,时间在分钟级别之内,无惧业务流量高峰。配合云盘这样的存储计算分离架构。我们可以灵活地为各种业务分配不同的磁盘空间。当空间不够时,可以直接在线扩缩容磁盘。同时,运维再也不用考虑硬件故障,当 ECS 有故障时,ECS 可以在另外一台宿主机上拉起,而云盘完全对上层屏蔽了坏盘的处理。极致的弹性同样带来了成本的优化。我们不需要为业务预留太多的资源,同时当业务的大促结束后,能够快速地缩容降低成本。
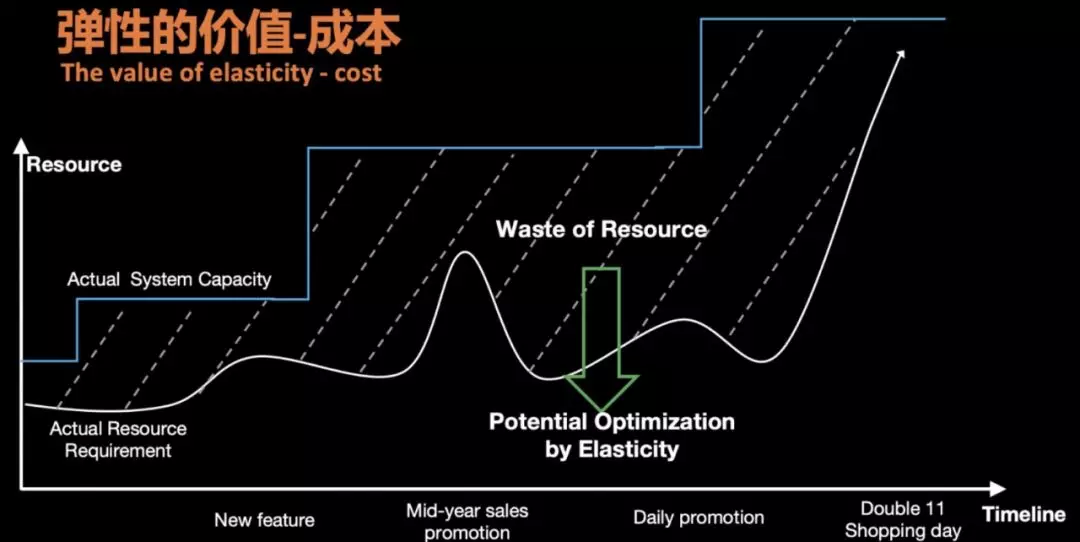
一体化冷热分离
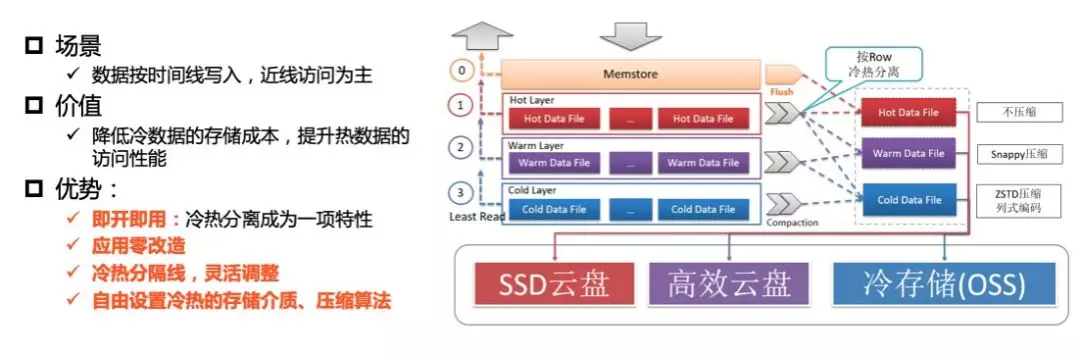
在海量大数据场景下,一张表中的部分业务数据随着时间的推移仅作为归档数据或者访问频率很低,同时这部分历史数据体量非常大,比如订单数据或者监控数据,降低这部分数据的存储成本将会极大的节省企业的成本。如何以极简的运维配置成本就能为企业极大降低存储成本,Lindorm 冷热分离功能应运而生。Lindorm 为冷数据提供新的存储介质,新的存储介质存储成本仅为高效云盘的 1/3。
Lindorm 在同一张表里实现了数据的冷热分离,系统会自动根据用户设置的冷热分界线自动将表中的冷数据归档到冷存储中。在用户的访问方式上和普通表几乎没有任何差异,在查询的过程中,用户只需配置查询 Hint 或者 TimeRange,系统根据条件自动地判断查询应该落在热数据区还是冷数据区。对用户而言始终是一张表,对用户几乎做到完全的透明。详细介绍请参考:
https://yq.aliyun.com/articles/718395
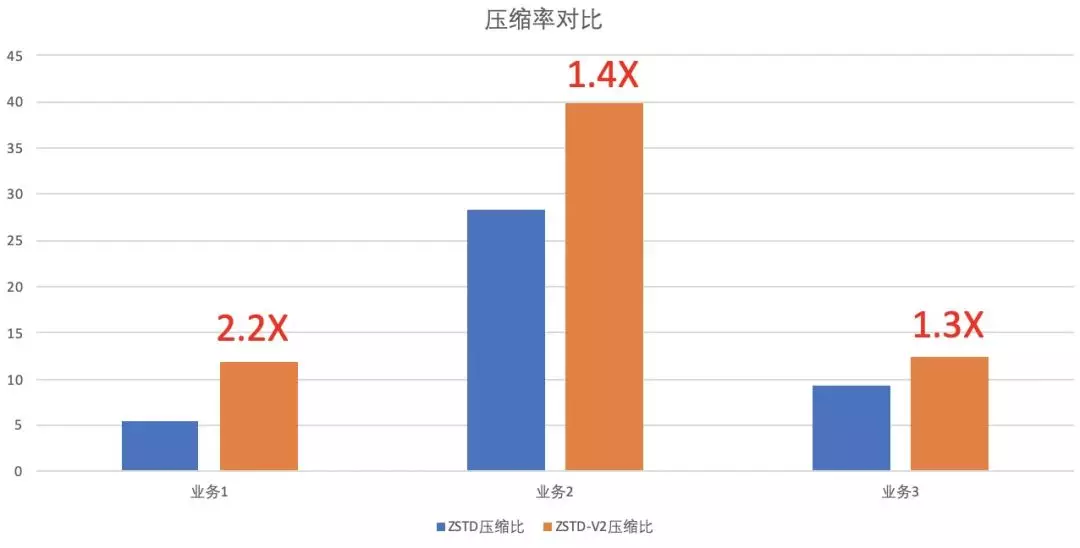
ZSTD-V2,压缩比再提升 100%
早在两年前,我们就把集团内的存储压缩算法替换成了 ZSTD,相比原来的 SNAPPY 算法,获得了额外 25%的压缩收益。今年我们对此进一步优化,开发实现了新的 ZSTD-v2 算法,其对于小块数据的压缩,提出了使用预先采样数据进行训练字典,然后用字典进行加速的方法。我们利用了这一新的功能,在 Lindorm 构建 LDFile 的时候,先对数据进行采样训练,构建字典,然后在进行压缩。在不同业务的数据测试中,我们最高获得了超过原生 ZSTD 算法 100%的压缩比,这意味着我们可以为客户再节省 50%的存储费用。
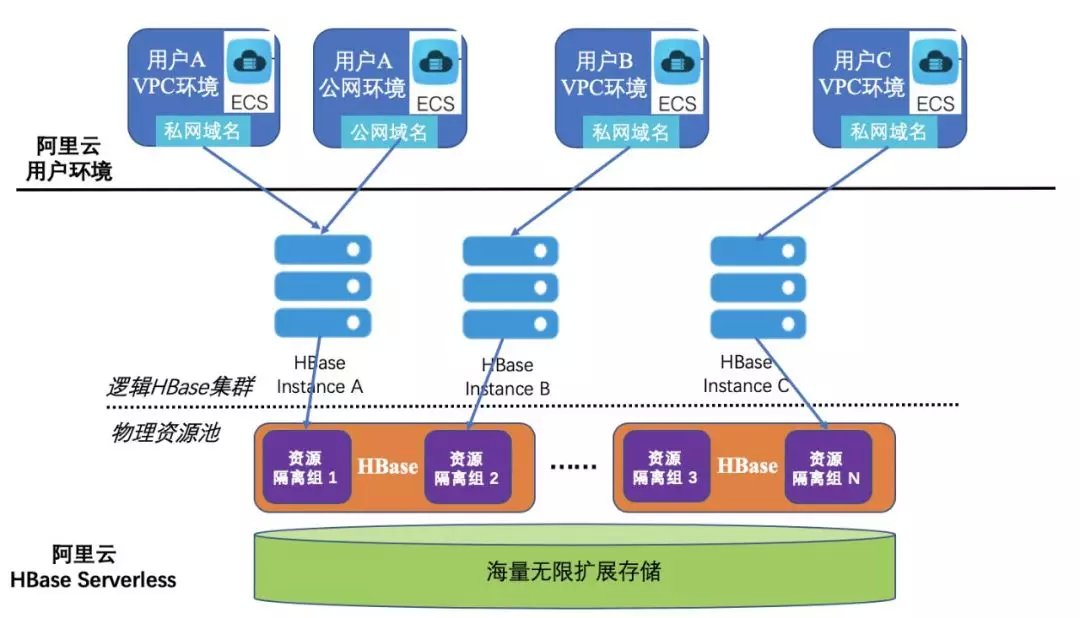
HBase Serverless 版,入门首选
阿里云 HBase Serverless 版是基于 Lindorm 内核,使用 Serverless 架构构建的一套新型的 HBase 服务。阿里云 HBase Serverless 版真正把 HBase 变成了一个服务,用户无需提前规划资源,选择 CPU,内存资源数量,购买集群。在应对业务高峰,业务空间增长时,也无需进行扩容等复杂运维操作,在业务低谷时,也无需浪费闲置资源。
在使用过程中,用户可以完全根据当前业务量,按需购买请求量和空间资源即可。使用阿里云 HBase Serverless 版本,用户就好像在使用一个无限资源的 HBase 集群,随时满足业务流量突然的变化,而同时只需要支付自己真正使用的那一部分资源的钱。
关于 HBase Serverless 的介绍和使用,可以参考:https://developer.aliyun.com/article/719206
面向大客户的安全和多租户能力
Lindorm 引擎内置了完整的用户名密码体系,提供多种级别的权限控制,并对每一次请求鉴权,防止未授权的数据访问,确保用户数据的访问安全。同时,针对企业级大客户的诉求,Lindorm 内置了 Group,Quota 限制等多租户隔离功能,保证企业中各个业务在使用同一个 HBase 集群时不会被相互影响,安全高效地共享同一个大数据平台。
用户和 ACL 体系
Lindorm 内核提供一套简单易用的用户认证和 ACL 体系。用户的认证只需要在配置中简单的填写用户名密码即可。用户的密码在服务器端非明文存储,并且在认证过程中不会明文传输密码,即使验证过程的密文被拦截,用以认证的通信内容不可重复使用,无法被伪造。
Lindorm 中有三个权限层级。Global,Namespace 和 Table。这三者是相互覆盖的关系。比如给 user1 赋予了 Global 的读写权限,则他就拥有了所有 namespace 下所有 Table 的读写权限。如果给 user2 赋予了 Namespace1 的读写权限,那么他会自动拥有 Namespace1 中所有表的读写权限。
Group 隔离
当多个用户或者业务在使用同一个 HBase 集群时,往往会存在资源争抢的问题。一些重要的在线业务的读写,可能会被离线业务批量读写所影响。而 Group 功能,则是 HBase 增强版(Lindorm)提供的用来解决多租户隔离问题的功能。
通过把 RegionServer 划分到不同的 Group 分组,每个分组上 host 不同的表,从而达到资源隔离的目的。
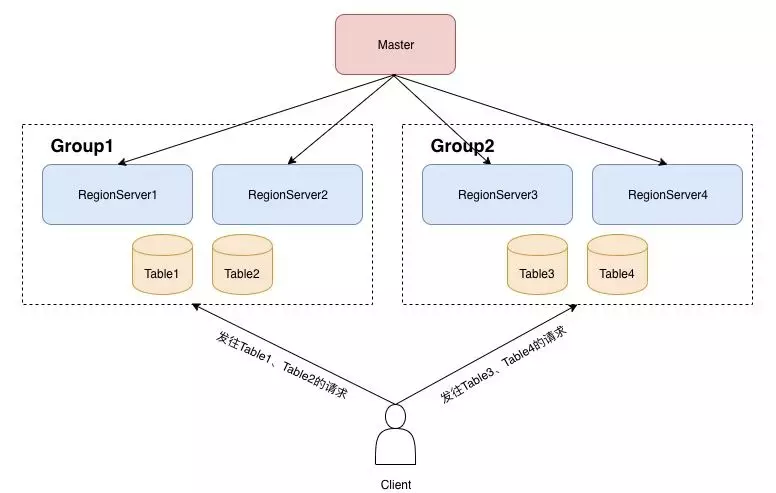
例如,在上图中,我们创建了一个 Group1,把 RegionServer1 和 RegionServer2 划分到 Group1 中,创建了一个 Group2,把 RegionServer3 和 RegionServer4 划分到 Group2。同时,我们把 Table1 和 Table2 也移动到 Group1 分组。这样的话,Table1 和 Table2 的所有 region,都只会分配到 Group1 中的 RegionServer1 和 RegionServer2 这两台机器上。
同样,属于 Group2 的 Table3 和 Table4 的 Region 在分配和 balance 过程中,也只会落在 RegionServer3 和 RegionServer4 上。因此,用户在请求这些表时,发往 Table1、Table2 的请求,只会由 RegionServer1 和 RegionServer2 服务,而发往 Table3 和 Table4 的请求,只会由 RegionServer3 和 RegionServer4 服务,从而达到资源隔离的目的。
Quota 限流
Lindorm 内核中内置了一套完整的 Quota 体系,来对各个用户的资源使用做限制。对于每一个请求,Lindorm 内核都有精确的计算所消耗的 CU(Capacity Unit),CU 会以实际消耗的资源来计算。比如用户一个 Scan 请求,由于 filter 的存在,虽然返回的数据很少,但可能已经在 RegionServer 已经消耗大量的 CPU 和 IO 资源来过滤数据,这些真实资源的消耗,都会计算在 CU 里。在把 Lindorm 当做一个大数据平台使用时,企业管理员可以先给不同业务分配不同的用户,然后通过 Quota 系统限制某个用户每秒的读 CU 不能超过多少,或者总的 CU 不能超过多少,从而限制用户占用过多的资源,影响其他用户。同时,Quota 限流也支持 Namesapce 级别和表级别限制。
最后
全新一代 NoSQL 数据库 Lindorm 是阿里巴巴 HBase&Lindorm 团队 9 年以来技术积累的结晶,Lindorm 在面向海量数据场景提供世界领先的高性能、可跨域、多一致、多模型的混合存储处理能力。对焦于同时解决大数据(无限扩展、高吞吐)、在线服务(低延时、高可用)、多功能查询的诉求,为用户提供无缝扩展、高吞吐、持续可用、毫秒级稳定响应、强弱一致可调、低存储成本、丰富索引的数据实时混合存取能力。
本文转载自公众号阿里技术(ID:ali_tech)。
原文链接:
https://mp.weixin.qq.com/s/I3FnP1JtY5QZCY2D3QioyQ

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论