
SharePoint 对象模型(Object Model)允许外部应用程序或托管的 WebPart 来查询、编辑和创建存储在 SharePoint 内容数据库(Content Database)中的内容。有很多博客文章、知识库文章和最佳实践中,都谈到如何在不同的用例场景中使用对象模型。
大部分常见用例场景都是关于显示和编辑 SharePoint 列表的——可惜,这也是我们看到很多性能问题出现的地方,这是因为 SharePoint 对象模型并不总是以性能优化的方式被使用。
用例 1:在 SharePoint 列表中,存储了多少项目?
有多种方式来回答这个问题。我曾经看到很多次的一个例子是下面这样:
int noOfItems = SPContext.Current.List.Items.Count;
这句代码告诉我们在列表中数据项的数目,为了得到这个结果不得不从内容数据库中获取列表的所有项目。下面的截图显示了,当上面代码在访问 Count 属性的时候,对象模型内部的执行过程:

对于小型列表,这不会有问题,查询还是比较迅速。不过当列表增长数倍,或自定义代码从未在实际数据上测试过的话,这将成为一个问题。
对于这种情况,微软为 SPList 提供了另外一个属性,名为 ItemCount。正确的代码应该是:
int noOfItems = SPContext.Current.List.ItemCount;
在这种情况下,SharePoint 只用在内容数据库中查询 Lists 数据表的单个记录。在列表中数据项的数量会被冗余地存储在这,以便无需查询整个 AllUserData 数据表(所有的 SharePoint 列表项目都保存在这里)就可获得这个信息。
用例 2:使用 SPList 显示列表中的项目?
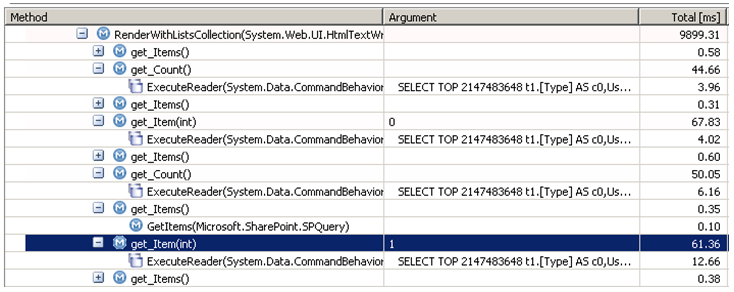
通过 SharePoint 对象模型,有多种方法可以遍历 SharePoint 列表的数据项。我曾经在一个实际运行的 SharePoint 应用程序中见到的这样一个方式——在开发人员机器上或在非常小的列表上可能会工作正常,但是一旦在超过几百条数据项的列表上执行,这种方式就会出现致命的性能问题。让我们看一下代码片段,它被用于一个 WebPart 中,从当前上下文的 SharePoint 列表中获取前 100 个数据项:
<p>SPList activeList = SPContext.Current.List;</p><p>for(int i=0;i<100 && i</p><p>SPListItem listItem = activeList.Items[i];</p><p>htmlWriter.Write(listItem["Title"]);</p><p>}</p>假定在这个列表中至少有 100 条数据项——这段代码为了获取前 100 个 SharePoint 列表数据项的 100 个 Title 值,会往返访问数据库多少次?你也许会很惊讶。经过对上述代码的执行过程的分析,在你看到来着数据库的视图的时候,一共对数据库进行了 200 次调用:

原因在于,在每次循环中,当访问 Items 属性的时候,我们都请求了一个新的 SPListItemCollection 对象。Items 属性未被缓存,因此总是从数据库中反复不断地请求所有数据项。下面是第一个循环迭代的情况:
正确的方法
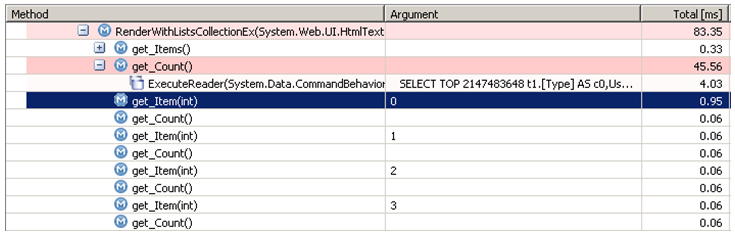
正确的方法当然是把 Items 属性的返回值存储在一个 SPListItemCollection 变量中。这样,数据库就只会查询一次,并且我们接下来也可以遍历存储在集合对象里面的结果集。下面是修改后的示例代码:
<p>SPListItemCollection items = SPContext.Current.List.Items;</p><p>for(int i=0;i<100 && i</p><p>SPListItem listItem = items[i];</p><p>htmlWriter.Write(listItem["Title"]);</p><p>}</p>你也能使用 foreach 循环语句,它会被编译为类似的代码,其充分利用了 Items 集合的 IEnumerable 接口。下面是新的循环在内部如何被处理的过程:
用例 3:使用 SPQuery 和 SPView 只请求你真正需要的数据
在必须处理来自数据库的数据的任何类型应用程序中,我们都能见到的一个主要性能问题是,有太多数据要访问。请求比当前用例所需的数据量更多的信息,会导致额外的:
- 在数据库上的查询开销,以便收集请求信息
- 在数据库和应用程序之间的通讯开销
- 在数据库和应用程序上的内存开销
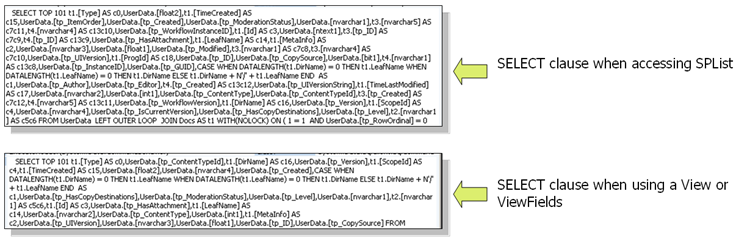
回头看一下前面 2 个用例,你会发现被执行的 SQL Statement 总是从请求的 SharePoint 列表中选取了所有数据项。你可以说你看到 SELECT 子句是这样书写:SELECT TOP 2147483648……
限制返回行的数量
在访问 SharePoint 列表中的数据项的时候,万一你只想得到有限数量的结果集,那么你可以利用 SPQuery.RowLimit 属性。
下面是一个例子:
<p>SPQuery query = new SPQuery();</p><p>query.RowLimit = 100;</p><p>SPListItemCollection items = SPContext.Current.List.GetItems(query);</p><p>for (int itemIx=0;itemIx</p><p>SPListItem listItem = items[itemIx];</p><p>}</p>在 SPList.GetItems 方法中使用 SPQuery 对象,将生成包含如下 SELECT 子句的结果。

在之前的例子中,我们已经限制了想要获取的数据项数目。然而,我们依旧还是请求了定义在 SharePoint 列表中的所有列。对于真正需要把所有列都显示给最终用户,或者需要所有列来完成某些计算的情况,这样做毫无问题。然而,在大部分情况下,我们只需要几个而不是全部的列。
限制检索列
有两种方法来限制哪些列要从数据库检索:
- 使用 SharePoint 视图:SPView
- 使用 SPQuery.ViewFields 属性
因此上面的示例代码可以用如下两种方式进行修改:
SPQuery query = new SPQuery(SPContext.Current.CurrentView.View);
或
<p>SPQuery query = new SPQuery();</p><p>query.ViewFields = "<fieldref name="ID"></fieldref><fieldref name="Text Field"></fieldref><fieldref name="XYZ"></fieldref>";</p>在两种场景中,SELECT 子句都只包含那些定义在 SharePoint 视图中的字段,这些字段各自在 ViewFields 属性中被引用:
用例 4:通过 SPQuery 来对 SharePoint 列表数据项进行分页
SharePoint 列表能包含成千上万的数据项。我们都听说,为了获得较好的列表性能,不应该超过2000 条的限度。当超过这个限度后,确实存在性能影响。有一些方法可以克服这个限度,就是使用索引列和视图。
在访问列表中的数据时,除了考虑这些因素外,还有一个方面比较重要。在之前的用例中已经解释过——只访问你需要的数据可以大大降低 SharePoint 内容数据库的压力。另外, SharePoint 对象模型也提供了一些额外的特性来加强访问列表数据项的能力。
数据分页就是其中一个技术,就是我们在富客户端应用程序或 Web 应用程序中已经熟知的,使用数据网格类似的方式。分页让最终用户便捷地导航数据,并且——如果正确地实现的话——可以减少低层数据库的负载。
SPQuery 对象提供了属性 ListItemCollectionPosition,通过它你能够设定查询页的起始位置。RowLimit 让你设定每页要获取多少数据项。让我们来看一些示例代码:
<p>SPQuery query = new SPQuery();</p><p>query.RowLimit = 10; // that is our page size</p><p>do</p><p>{</p><p>SPListItemCollection items = SPContext.Current.List.GetItems(query);</p><p>// do something with the page result</p><p>// set the position cursor for the next iteration</p><p>query.ListItemCollectionPosition = items.ListItemCollectionPosition;</p><p>} while (query.ListItemCollectionPosition != null)</p>SPList.GetItems 执行了这个查询,每次调用 GetItems 只返回 10 条数据项。SPListItemCollection 提供的 ListItemCollectionPosition 属性就像 SharePoint 列表上的一个指针。这个属性能用于任何页面遍历,以定义下一页的起始点。下面的插图显示了数据库的活动:
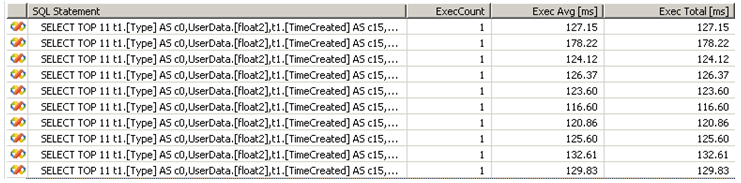
仔细看一下展现给我们的这个 SQL Statement,它混合了 SELECT TOP 和 WHERE 子句,用于获取某个页的数据项:

用例 5:更新大量的 SharePoint 列表数据项
之前的用例关注于存储在 SharePoint 列表中的数据项的读取访问。现在来讨论一下如何更好地更新或添加新数据项了。由于 SharePoint 对象模型提供了丰富的接口,所以我们又可以在多种方式中进行选择了。
在 SharePoint 列表中添加和更新数据项的第一个显而易见的方式是,SPListItem.Update。要获得一个列表数据项,既能通过查询一个现存数据项,又可以用 SPListItemCollection.Add 来添加一个新的。
让我们看一下如下的例子:
<p>for (int itemIx=0;itemIx<100;itemIx++) {</p><p>SPListItem newItem = items.Add();</p><p>// fill all the individual fields with values</p><p>newItem.Update();</p><p>}</p>对这段代码进行分析,我们看到对 Update 方法的每次调用实际上都调用了内部方法 SPListItem.AddOrUpdateItem,它事实上是调用了一个存储过程来完成这个任务:
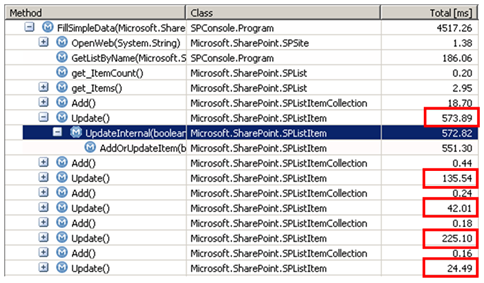
我们看到,添加 100 条数据项到我的列表中,花费了 4.5 秒的时间。
使用批量更新代替单个更新
如果你必须更新大量的数据项,强烈建议你不要在每个数据项上独立使用 Update 方法。而是,使用 SPWeb 提供的批量更新函数 ProcessBatchData。
ProcessBatchData 执行以XML 格式定义的批量方法。这里有一篇很好的文章解释了如何使用批量更新。通过利用批量更新,可以把上面的例子实现为这样:
<p>StringBuilder query = new StringBuilder();</p><p>for (int itemIx=0;itemIx<100;itemIx++) {</p><p>query.AppendFormat("<method id="\"{0}\"">" +</method></p><p>"<setlist>{1}</setlist>" +</p><p>"<setvar name="\"ID\"">New</setvar>" +</p><p>"<setvar name="\"Cmd\"">Save</setvar>" +</p><p>"<setvar name="\"{3}Title\"">{2}</setvar>" +</p><p>"", itemIx, listGuid, someValue, "urn:schemas-microsoft-com:office:office#");</p><p>}</p><p>SPContext.Current.Web.ProcessBatchData(</p><p>"" +</p><p>"<batch onerror="\"Return\"">{0}</batch>", query.ToString())</p>通过 ProcessBatchData 添加同样的 100 条数据项,通过分析内部机理,我们知道在更新过程中花费了多少时间:
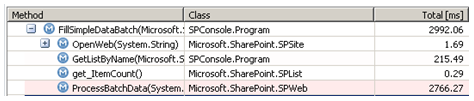
两种更新方式的对比表明,我们可以通过批量更新来获得巨大的性能提升:

注意
批量更新实际上只在执行大量更新的时候才被推荐。不过,请思考一下创建批量更新 XML 的花销:
- 确保使用 StringBuilder,而不是把一些独立字符串对象连接在一起。
- 分割批量更新调用,以保持生成的 XML 足够小,不会出现内存溢出异常。在执行上述包含了 50000 个批量更新的例子的时候,我就遇到了 OOM(内存溢出)。
用例 6:哪一个是我最慢的列表,它们如何被使用以及为什么会慢?
我们知道,SharePoint 列表性能随着存储在其中的数据项的数量增加而降低,并且也和显示的时候,列表如何进行过滤有关。你可以找到谈及每个列表 2000 条数据项限度的很多文章和博客帖子。
为了做正确的事获得良好的性能,首先需要了解当前的使用情况并分析性能问题。
有几种方式可以算出你的SharePoint 应用程序的当前访问统计量。你可以分析 IIS 日志文件,或者使用 SharePoint 使用率报告特性( SharePoint Usage Reporting Feature )。
监测列表性能最简单的方式就是分析各个 SharePoint List 和 SharePoint View 的 URL 的 HTTP 响应次数。SharePoint URL 的格式类似这样: http://servername/site/{LISTNAME}/{VIEWNAME}.aspx。
为了分析它,我们可以基于这两个标记来对请求进行分组。我使用 dynaTrace 的 Business Transaction 特性依照正则表达式来分组捕获到的 PurePath’s 。
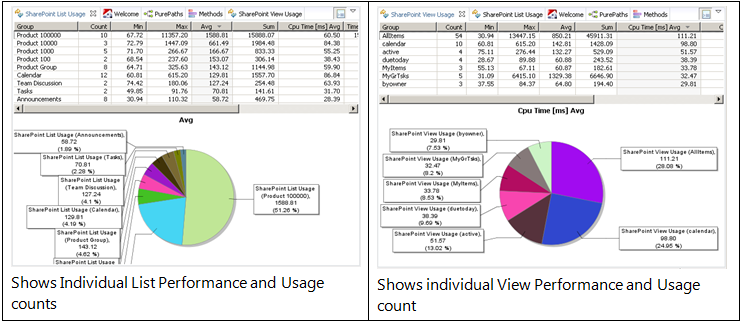
这样的结果让我们明白,哪些列表和视图使用最频繁,它们表现如何。
此外,对 HTTP 请求进行分析——它只为那些显示特定列表或视图的页面提供准确的数据——这样,我们就能分析自定义 Web 部件或自定义页面的列表使用率,它们往往比单个列表或视图被访问得更多,也比那些以特定过滤方式来访问列表的情况多。
我们也能分析与 SharePoint 对象模型交互的情况,比如被用于呈现列表和视图的 SPRequest.RenderViewAsHtml 的使用情况,对 SPList 和 SPView 的访问情况。下面的插图显示了对 SPRequest 方法调用的使用率和性能指标:
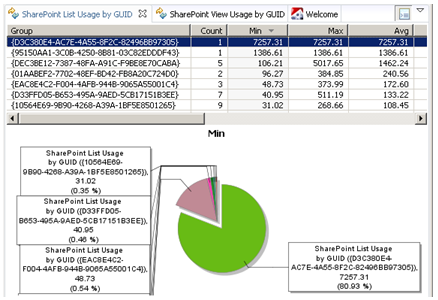
上面的插图给我们展现了,列表的内部 GUID。每个列表和视图都通过 GUID 来唯一标识。这是查找真实列表名称的另外一种方式:你可以吧 GUID 粘贴进 URL 中,以编辑列表和视图的设置。下面是一个例子:
http://servername/_layouts/listedit.aspx?List={GUID} (GUID must be URL-Encoded).
这为我们提供了另外一种打开内容数据库和查询 AllLists 数据表的方式。这个数据表包含着 GUID 和 List 名称。
列表为什么慢?
现在,由于我们已经知道哪些列表和视图被频繁访问,我们就能重点关注那些让性能下降的地方。为了改善最终用户体验,我们应该集中在最频繁访问的列表上,而不是那些偶尔访问一下的列表。
列表表现缓慢,存在有多种原因:
- 有太多的数据项显示在列表视图中
- 有太多的数据项保存于没有过滤和索引列的列表中
- 自定义 Web 部件进行了无效率的数据访问
Conclusion
SharePoint 对象模型提供了一种轻松的灵活的方式来扩展 SharePoint 应用程序。这个框架提供了不同的机制来访问和编辑存储在 SharePoint 列表中的数据。然而,不是每种可能的方式对于每个用例场景都是可取的。了解 SharePoint 对象模型的内部原理可以让我们创建的 SharePoint 应用程序运行得更好,性能更易伸缩。
关于作者
Andreas Grabner 作为一个技术战略决策者,工作于 dynaTrace Software。他的角色归属 R&D 部门,影响着 dynaTrace 产品决策,并和关键客户紧密协作,为整个应用程序生命周期实现了性能管理解决方案。Andreas Grabner 在 Java 和.NET 领域拥有 10 年的构架和开发经验。
关于作者的雇主:dynaTrace software
dynaTrace 是为执行关键业务的 Java 和.NET 应用程序的整个生命周期,提供持续应用程序性能管理解决方案的领导者。dynaTrace 为所有关键利益相关人(开发、测试和产品)提供通用的、集成的性能管理平台的最佳解决方案。诸如UBS、LInkedIn、EnerNOC、Fidelity 和Thomson Reuters 这样的行业领袖,都是使用dynaTrace 正在申请专利的技术,以期获得对应用程序性能完全的掌控、尽早地识别问题,并极大地减少了平均修复时间(减少了90%)。这些和其他一些领导厂商依赖于dynaTrace 的技术,积极防止突发的性能问题,并在出现的时候快速解决它们——节省了时间、金钱和资源。
查看英文原文: SharePoint Object Model Performance Considerations 。
给 InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。

暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论