

现代数据湖依靠提取、转换和加载 (ETL) 操作将大量信息转换为可用数据。本文将指导您实施 ETL 编排流程,该流程使用 AWS Step Functions、 AWS Lambda 和 AWS Batch 实现松散耦合,以便创建 Amazon Redshift 集群。由于 Amazon Redshift 使用-列式存储,因此非常适合使用便捷的 ANSI SQL 查询来快速获得分析洞察。只需几分钟便可快速扩展/缩减您的 Amazon Redshift 集群,以实现以下两项要求严苛的工作负载:最终用户报告和及时刷新数据仓库中的数据。借助 AWS Step Functions,可轻松开发和使用扩展性良好的可重复工作流程。Step Functions 基于单独的 Lambda 函数构建自动化工作流程。每个函数执行各自的任务,可让您快速地、平滑地开发、测试和修改工作流程组件。
ETL 流程会刷新源系统中的数据仓库,将原始数据整理成更易使用的格式。大多数组织将 ETL 作为批处理操作或实时抽取流程的一部分来运行,以确保数据仓库处于最新状态并提供及时分析。完全自动化且高度可扩展的 ETL 流程,有助于最大程度减少管理常规 ETL 管道所需执行的操作。此外,还可确保及时准确地刷新数据仓库。您可以通过定制此流程,来刷新任何数据仓库或数据湖中的数据。
本文还提供了一个 AWS CloudFormation 模板,借助该模板,可一键启动整个示例 ETL 流程,以刷新 TPC-DS 数据集。如需该模板的链接,请查看使用 AWS CloudFormation 设置整个工作流程部分。
架构概览
下图简要说明了 ETL 工作流程编排过程中涉及到的不同组件的架构。该工作流程使用 Step Functions 从 Amazon S3 获取源数据,以刷新 Amazon Redshift 数据仓库。
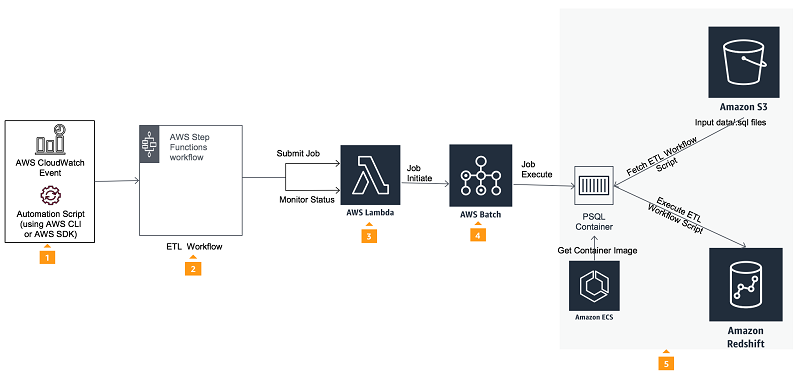
以下是该工作流程的核心组件:
Amazon CloudWatch 通过 AWS CLI 或集成了不同 AWS SDK 的 Lambda 函数,根据计划触发 ETL 流程。
ETL 工作流程使用 Step Functions 实现多步骤 ETL 处理,并将 AWS 服务作为无服务器工作流程的一部分进行管理。您可以使用基于 JSON 的模板进行构建并轻松迭代。例如,典型的 ETL 流程可能首先刷新维度表,然后再刷新事实表。您可以使用 Step Functions 状态机定义操作顺序。
Lambda 函数可让您构建微服务以协调作业提交和监控,而无需为工作流程逻辑、并行处理、错误处理、超时或重试编写代码。
AWS Batch 运行多个 ETL 作业,例如转换和加载到 Amazon Redshift。AWS Batch 为您管理所有基础设施,帮您避免了复杂的预置、管理、监控和扩展批量计算作业。此外,它还可让您等待作业完成。
Amazon S3 中的源数据通过 PL/SQL 容器刷新 Amazon Redshift 数据仓库。为指定 ETL 逻辑,我将使用 .sql 文件,其中包含特定步骤的 SQL 代码。例如,一个典型的、用于维度表刷新的 .sql 文件将包含将数据从 * Amazon S3 加载到临时暂存表以及插入/更新目标表的步骤。开始之前,请先查看示例维度表 .sql 文件。
可以使用状态机执行工作流程并进行监控。您可以根据时间计划或通过事件触发 ETL(例如,所有数据文件都到达 S3 后立即触发)。
先决条件
开始之前,请创建一个可以执行 .sql 文件的 Docker 映像。AWS Batch 使用此 Docker 映像创建用于执行 ETL 步骤的资源。要创建 Docker 映像,您需要:
运行 Amazon Linux 且装有 Docker 的 Amazon EC2 实例
AWS 命令行界面
如果这是您首次使用 AWS Batch,请参阅 AWS Batch 入门。创建一个环境以构建并注册 Docker 映像。在本文中,我们将在 Amazon ECR 存储库中注册此映像。默认情况下,这是一个私有存储库,对于 AWS Batch 作业非常有用。
构建 Docker 映像用于 “fetch and run psql”
要构建 Docker 映像,请按照博文 Creating a Simple “Fetch & Run” AWS Batch Job 中介绍的步骤操作。
使用以下 Docker 配置和获取和 “fetch and run psql” 脚本来构建映像。
DockerFetchRunPsqlUbundu
fetch_and_run_psql.sh
按照该博文中的步骤将 Docker 映像导入 ECR 容器注册表。完成前面的步骤后,Docker 映像就可以为 Amazon Redshift 集群触发 .sql 执行了。
示例:使用 TPC-DS 数据集的 ETL 流程
本示例使用 TPC-DS 数据集的子集演示典型的维度模型刷新。下面是用于此 ETL 应用程序的 TPC-DS 数据模型的实体关系图:
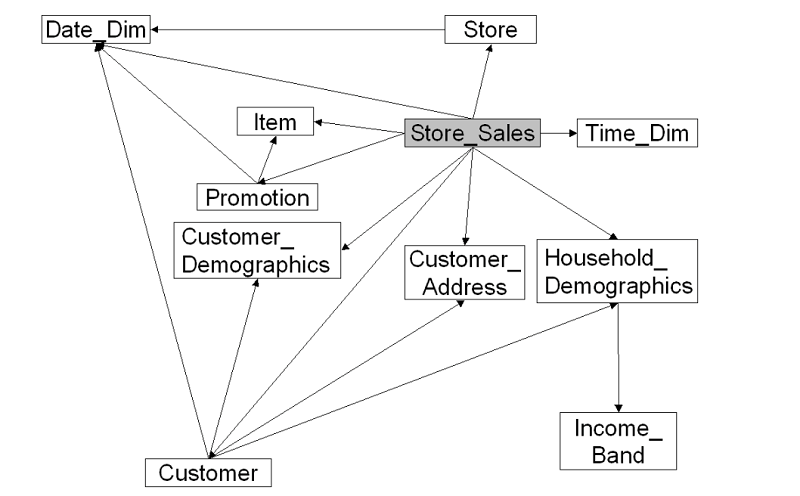
ETL 流程将对某个特定数据集日期的 Store_Sales 事实表、Customer_Address 和 Item 维度表的表数据进行刷新。
使用 Step Functions 设置 ETL 工作流程
Step Functions 简化了复杂的工作流程。可以使用基于 JSON 的模板设置依赖项管理和故障处理。工作流程就是一系列的步骤,一个步骤的输出是下一步骤的输入。
在该示例中,我们会在触发事实表加载之前,完成各种维度表转换和加载。此外,一个工作流程还可以根据需要分成多个并行步骤。您可以在执行过程中监控每个步骤,这意味着您可以快速发现并解决问题。
下图概述了通过 Step Functions 设置的示例 ETL 流程:
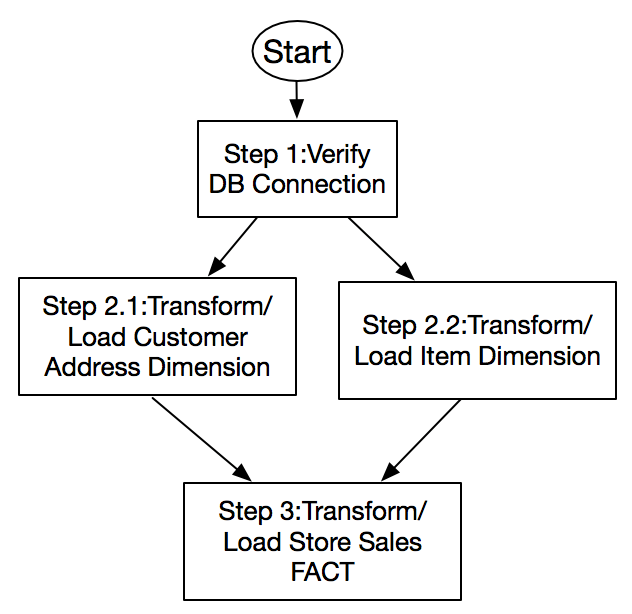
有关更多信息,请参阅详细的工作流程图。
在以上工作流程中,ETL 流程首先检查数据库连接(步骤 1),并触发 Customer_Address(步骤 2.1)和 Item_dimension(步骤 2.2)步骤,这两个步骤并行执行。Store_Sales(步骤 3)事实表会等待维度表处理的完成。每个 ETL 步骤都自主执行,以便您可以在任何阶段监控并应对失败。
现在我们详细地分析下 Store_Sales 步骤(步骤 3)。其他步骤的模式与之类似。
下面是 Store_Sales 步骤(步骤 3)的状态实施:
加载所有维度表的 Parallel 进程通过 Next 属性为后续的 Store Sales 事实表转换/加载 SalesFACTInit 设置了一个依赖。SalesFACTInit 步骤使用 SubmitStoreSalesFACTJob 触发 AWS Batch 转换操作,AWS Batch 则是由 AWS Lambda 作业 JobStatusPol-SubmitJobFunction 触发的。GetStoreSalesFACTJobStatus 通过 AWS Lambda JobStatusPoll-CheckJobFunction 每 30 秒轮询一次,检查任务完成情况。CheckStoreSalesFACTJobStatus 验证状态并根据返回的状态确定流程是成功还是失败。
下面是为步骤 3 执行状态机作业的输入片段:
输入定义了每个步骤调用的 .sql 文件,以及刷新日期。您可以 JSON 工作流程的形式表示任何复杂的 ETL 工作流程,使其易于管理。此外,它还解耦了每个步骤要调用的输入。
执行 ETL 工作流程
执行状态机调用 AWS Batch,通过执行每个 .sql 脚本 (store_sales.sql),对特定日期的销售数据进行增量刷新。
下面是 store_sales.sql 的加载和转换实施:
此 ETL 实施执行以下步骤:
COPY 命令快速将 S3 中的数据批量加载到暂存表 stg_store_sales。
“Begin…end transactions”封装转换和加载过程中的多个步骤。此方式最终会减少提交操作,从而降低处理成本。
ETL 实施为幂等形式。如果失败,您可以重试作业,而无需进行任何清理操作。例如,它每次都会重新创建 stg_store_sales,然后每次都会删除目标表 store_sales 中特定日期的数据,这些数据的日期与待刷新数据日期相同。
有关上述实施中使用的最佳实践,请参阅 Top 8 Best Practices for High-Performance ETL Processing Using Amazon Redshift 博文。
此外,Customer_Address 也展示了典型维度模型中的类型 1 实现,而 Item 遵循类型 2 实现。
使用 AWS CloudFormation 设置整个工作流程
AWS CloudFormation 模板包含此解决方案的所有步骤。该模板会创建所有必需的 AWS 资源,并调用初始数据设置和特定日期的数据刷新。下面列出了它在 CloudFormation 堆栈中创建的所有资源:
VPC 以及关联的子网、安全组和路由
IAM 角色
Amazon Redshift 集群
AWS Batch 作业定义和计算环境
用于提交和轮询 AWS Batch 作业的 Lambda 函数
用于编排 ETL 工作流程并刷新 Amazon Redshift 集群中数据的 Step Functions 状态机
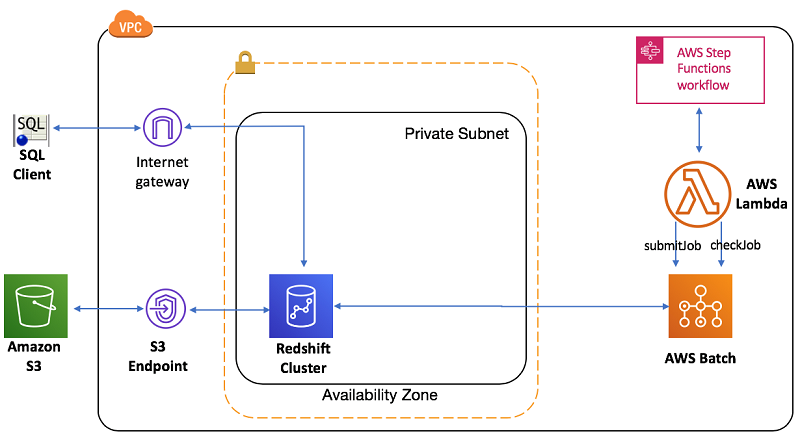
以下是此设置的架构,其中显示了 VPC 中的 Amazon Redshift 设置和使用 Step Functions 编排的 ETL 流程:
第 1 步:使用 AWS CloudFormation 创建堆栈
要在 AWS 账户中部署此应用程序,请先启动此 CloudFormation 堆栈:

此堆栈使用密码 Password#123。请尽快更改密码。应至少使用八个字符,至少一个大写字母、一个小写字母、一个数字和一个特殊字符。
其他所有参数使用默认值。
堆栈启动大约需要 10 分钟。等待堆栈启动完成,直至状态更改为 CREATE_COMPLETE。
记下堆栈 Output 部分中的 ExecutionInput 值。JSON 将如以下代码示例所示:
记下堆栈 Resources 部分中 JobDefinition 和 JobQueue 的实体 ID。
第 2 步:在 Amazon Redshift 中设置 TPC-DS 1GB 初始数据
以下步骤会将初始的 1GB TPCDS 数据加载到 Amazon Redshift 集群:
在 AWS Batch 控制台中,选择作业,选择前面记录的作业队列,然后选择提交作业。
设置新的作业名称,例如 TPCDSdataload,然后选择前面记录的 JobDefinition 值。选择提交作业。等待作业将初始的 1GB TPCDS 数据完全加载到 Amazon Redshift 集群中。
在 AWS Batch 控制面板中,监控 TPCDS 数据加载的完成情况。此操作大约需要 10 分钟才能完成。
第 3 步:在 Setup Functions 中执行 ETL 工作流程
ETL 流程是一个多步骤工作流程,可用 2010-10-10 的数据刷新 TPCDS 维度模型。
在 Step Functions 控制台中,选择 JobStatusPollerStateMachine-*。
选择开始执行并提供一个可选的执行名称,例如 ETLWorkflowDataRefreshfor2003-01-02。在执行输入中,输入前面记录的 ExecutionInput 值。这将启动 ETL 流程。状态机使用 Lambda 轮询器提交和监控 ETL 作业的每个步骤。每次输入都会调用 ETL 工作流程。您可以通过刷新浏览器来监控 ETL 流程。
第 4 步:在 Amazon Redshift 集群中验证 ETL 数据刷新
在 Amazon Redshift 控制台中,选择查询编辑器。输入以下凭证:
数据库:dev。
数据库用户:awsuser。
密码:需要输入在第 1 步中创建的密码(默认密码为 Password#123)。
登录公共 schema 后,执行以下查询,检查 2010-10-10 加载的数据:
该查询应显示 ETL 流程加载的 2010-10-10 的 TPC-DS 数据集。
第 5 步:清理
完成此解决方案的测试后,请记得清理使用 AWS CloudFormation 创建的所有 AWS 资源。使用 AWS CloudFormation 控制台或 AWS CLI 删除前面指定的堆栈。
小结
在本文中,我介绍了如何在 AWS 中使用解耦的服务来实施 ETL 工作流程,以及如何设置高度可扩展的编排以便刷新 Amazon Redshift 集群中的数据。
您可以轻松扩展从本文学到的内容。下面提供了一些选项,您可以借助这些选项扩展此解决方案以满足其他分析服务的需求,也可以强化并稳定该解决方案,使其可用于生产:
此示例使用 Step Functions 手动调用状态机。您可以改为使用 CloudWatch 事件或 S3 事件自动触发状态机,例如当新文件到达源存储桶时触发。您还可以通过计划来推动 ETL 调用。有关自动执行 ETL 工作流程的实用信息,请参阅 Schedule a Serverless Workflow。
您可以添加在失败时发出警报的机制。为此,可创建这样一个 Lambda 函数:根据 Step Functions 工作流程中每个步骤的状态向您发送电子邮件。
状态机的每个步骤均自主执行,可以使用 Lambda 函数调用任何服务。您可以将任何分析服务集成到您的工作流程中。例如,您可以创建一个单独的 Lambda 函数来调用 AWS Glue 并在使用 Amazon Redshift 转换数据之前清理一些数据。在这种情况下,可以将 AWS Glue 作业作为依赖项添加到维度加载之前的步骤中。
使用这个基于 Step Functions 的工作流程,您可以使用任何分析服务解耦 ETL 编排的不同步骤。正因如此,该解决方案适应性强,可与各种应用程序互换使用。
如果您有任何问题或建议,请在下方留言。
作者介绍:
Thiyagarajan Arumugam 是 Amazon Web Services 的一名大数据解决方案架构师,负责帮助客户设计大规模处理数据的架构。在加入 AWS 之前,他为 Amazon.com 构建了各种数据仓库解决方案。在闲暇时间,他喜欢所有户外运动,喜欢练习弹奏印度古典鼓 – 魔力单根鼓。
本文转载自 AWS 博客。
原文链接:


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论