随机森林是常用的机器学习算法,既可以用于分类问题,也可用于回归问题。本文对 scikit-learn、Spark MLlib、DolphinDB、XGBoost 四个平台的随机森林算法实现进行对比测试。评价指标包括内存占用、运行速度和分类准确性。本次测试使用模拟生成的数据作为输入进行二分类训练,并用生成的模型对模拟数据进行预测。
1.测试软件
本次测试使用的各平台版本如下:
scikit-learn:Python 3.7.1,scikit-learn 0.20.2
Spark MLlib:Spark 2.0.2,Hadoop 2.7.2
DolphinDB:0.82
XGBoost:Python package,0.81
2.环境配置
CPU:Intel® Xeon® CPU E5-2650 v4 2.20GHz(共 24 核 48 线程)
RAM:512GB
操作系统:CentOS Linux release 7.5.1804
在各平台上进行测试时,都会把数据加载到内存中再进行计算,因此随机森林算法的性能与磁盘无关。
3.数据生成
本次测试使用 DolphinDB 脚本产生模拟数据,并导出为 CSV 文件。训练集平均分成两类,每个类别的特征列分别服从两个中心不同,标准差相同,且两两独立的多元正态分布 N(0, 1)和 N(2/sqrt(20), 1)。训练集中没有空值。
假设训练集的大小为 n 行 p 列。本次测试中 n 的取值为 10,000、100,000、1,000,000,p 的取值为 50。
由于测试集和训练集独立同分布,测试集的大小对模型准确性评估没有显著影响。本次测试对于所有不同大小的训练集都采用 1000 行的模拟数据作为测试集。
产生模拟数据的 DolphinDB 脚本见附录 1。
4.模型参数
在各个平台中都采用以下参数进行随机森林模型训练:
树的棵数:500
最大深度:分别在 4 个平台中测试了最大深度为 10 和 30 两种情况
划分节点时选取的特征数:总特征数的平方根,即 integer(sqrt(50))=7
划分节点时的不纯度(Impurity)指标:基尼指数(Gini index),该参数仅对 Python scikit-learn、Spark MLlib 和 DolphinDB 有效
采样的桶数:32,该参数仅对 Spark MLlib 和 DolphinDB 有效
并发任务数:CPU 线程数,Python scikit-learn、Spark MLlib 和 DolphinDB 取 48,XGBoost 取 24。
在测试 XGBoost 时,尝试了参数 nthread(表示运行时的并发线程数)的不同取值。但当该参数取值为本次测试环境的线程数(48)时,性能并不理想。进一步观察到,在线程数小于 10 时,性能与取值成正相关。在线程数大于 10 小于 24 时,不同取值的性能差异不明显,此后,线程数增加时性能反而下降。该现象在 XGBoost 社区中也有人讨论过。因此,本次测试在 XGBoost 中最终使用的线程数为 24。
5.测试结果
测试脚本见附录 2~5。
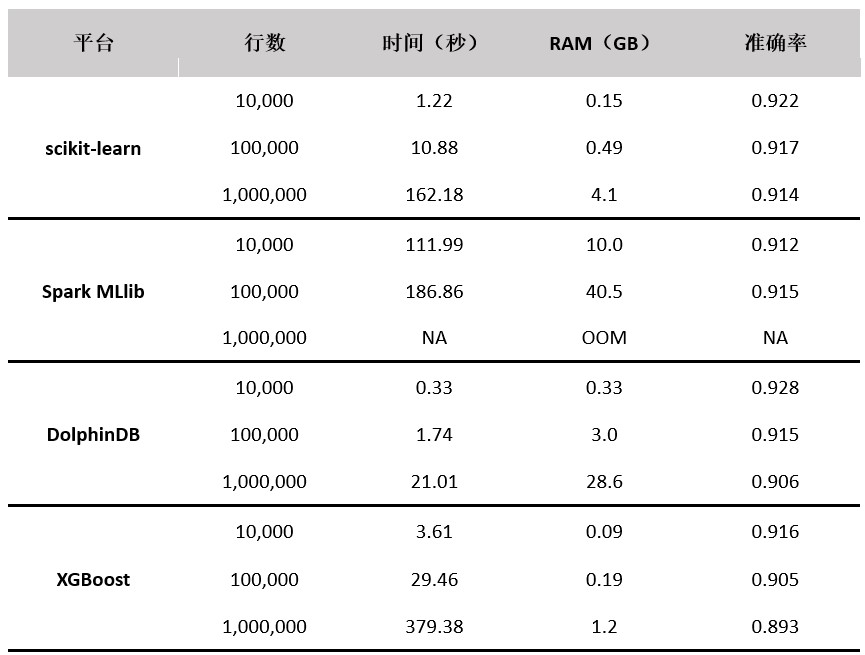
当树的数量为 500,最大深度为 10 时,测试结果如下表所示:
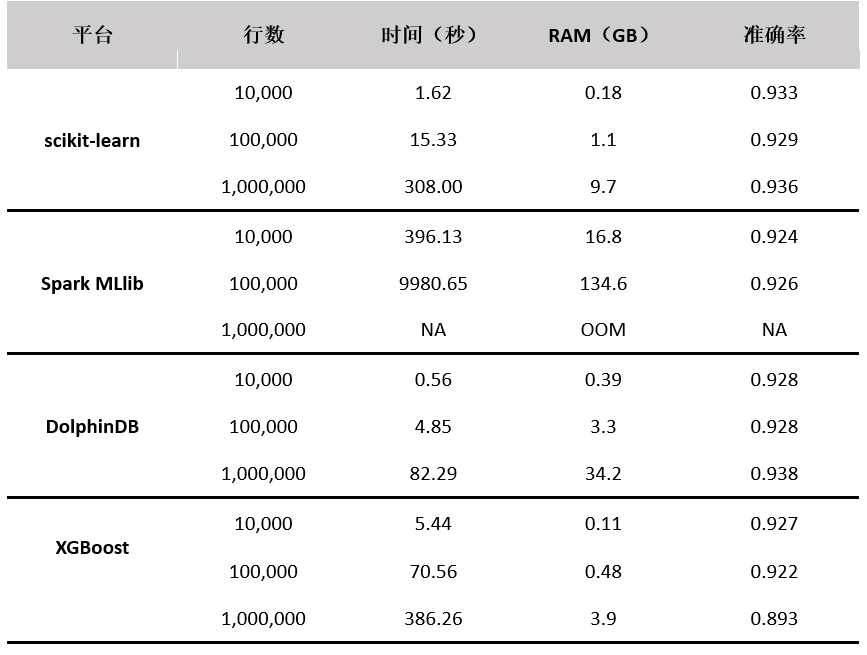
当树的数量为 500,最大深度为 30 时,测试结果如下表所示:
从准确率上看,Python scikit-learn、Spark MLlib 和 DolphinDB 的准确率比较相近,略高于 XGBoost 的实现;从性能上看,从高到低依次为 DolphinDB、Python scikit-learn、XGBoost、Spark MLlib。
在本次测试中,Python scikit-learn 的实现使用了所有 CPU 核。
Spark MLlib 的实现没有充分使用所有 CPU 核,内存占用最高,当数据量为 10,000 时,CPU 峰值占用率约 8%,当数据量为 100,000 时,CPU 峰值占用率约为 25%,当数据量为 1,000,000 时,它会因为内存不足而中断执行。
DolphinDB 的实现使用了所有 CPU 核,并且它是所有实现中速度最快的,但内存占用是 scikit-learn 的 2-7 倍,是 XGBoost 的 3-9 倍。DolphinDB 的随机森林算法实现提供了 numJobs 参数,可以通过调整该参数来降低并行度,从而减少内存占用。详情请参考DolphinDB用户手册。
XGBoost 常用于 boosted trees 的训练,也能进行随机森林算法。它是算法迭代次数为 1 时的特例。XGBoost 实际上在 24 线程左右时性能最高,其对 CPU 线程的利用率不如 Python 和 DolphinDB,速度也不及两者。其优势在于内存占用最少。另外,XGBoost 的具体实现也和其他平台的实现有所差异。例如,没有 bootstrap 这一过程,对数据使用无放回抽样而不是有放回抽样。这可以解释为何它的准确率略低于其它平台。
6.总结
Python scikit-learn 的随机森林算法实现在性能、内存开销和准确率上的表现比较均衡,Spark MLlib 的实现在性能和内存开销上的表现远远不如其他平台。DolphinDB 的随机森林算法实现性能最优,并且 DolphinDB 的随机森林算法和数据库是无缝集成的,用户可以直接对数据库中的数据进行训练和预测,并且提供了 numJobs 参数,实现内存和速度之间的平衡。而 XGBoost 的随机森林只是迭代次数为 1 时的特例,具体实现和其他平台差异较大,最佳的应用场景为 boosted tree。
附录
1.模拟生成数据的 DolphinDB 脚本
def genNormVec(cls, a, stdev, n) { return norm(cls * a, stdev, n)}
def genNormData(dataSize, colSize, clsNum, scale, stdev) { t = table(dataSize:0, `cls join ("col" + string(0..(colSize-1))), INT join take(DOUBLE,colSize)) classStat = groupby(count,1..dataSize, rand(clsNum, dataSize)) for(row in classStat){ cls = row.groupingKey classSize = row.count cols = [take(cls, classSize)] for (i in 0:colSize) cols.append!(genNormVec(cls, scale, stdev, classSize)) tmp = table(dataSize:0, `cls join ("col" + string(0..(colSize-1))), INT join take(DOUBLE,colSize)) insert into t values (cols) cols = NULL tmp = NULL } return t}
colSize = 50clsNum = 2t1m = genNormData(10000, colSize, clsNum, 2 / sqrt(20), 1.0)saveText(t1m, "t10k.csv")t10m = genNormData(100000, colSize, clsNum, 2 / sqrt(20), 1.0)saveText(t10m, "t100k.csv")t100m = genNormData(1000000, colSize, clsNum, 2 / sqrt(20), 1.0)saveText(t100m, "t1m.csv")t1000 = genNormData(1000, colSize, clsNum, 2 / sqrt(20), 1.0)saveText(t1000, "t1000.csv")
复制代码
2.Python scikit-learn 的训练和预测脚本
import pandas as pdimport numpy as npfrom sklearn.ensemble import RandomForestClassifier, RandomForestRegressorfrom time import *
test_df = pd.read_csv("t1000.csv")
def evaluate(path, model_name, num_trees=500, depth=30, num_jobs=1): df = pd.read_csv(path) y = df.values[:,0] x = df.values[:,1:]
test_y = test_df.values[:,0] test_x = test_df.values[:,1:]
rf = RandomForestClassifier(n_estimators=num_trees, max_depth=depth, n_jobs=num_jobs) start = time() rf.fit(x, y) end = time() elapsed = end - start print("Time to train model %s: %.9f seconds" % (model_name, elapsed))
acc = np.mean(test_y == rf.predict(test_x)) print("Model %s accuracy: %.3f" % (model_name, acc))
evaluate("t10k.csv", "10k", 500, 10, 48) # choose your own parameter
复制代码
3.Spark MLlib 的训练和预测代码
import org.apache.spark.mllib.tree.configuration.FeatureType.Continuousimport org.apache.spark.mllib.tree.model.{DecisionTreeModel, Node}
object Rf { def main(args: Array[String]) = { evaluate("/t100k.csv", 500, 10) // choose your own parameter }
def processCsv(row: Row) = { val label = row.getString(0).toDouble val featureArray = (for (i <- 1 to (row.size-1)) yield row.getString(i).toDouble).toArray val features = Vectors.dense(featureArray) LabeledPoint(label, features) }
def evaluate(path: String, numTrees: Int, maxDepth: Int) = { val spark = SparkSession.builder.appName("Rf").getOrCreate() import spark.implicits._
val numClasses = 2 val categoricalFeaturesInfo = Map<a href="">Int, Int val featureSubsetStrategy = "sqrt" val impurity = "gini"val maxBins = 32
val d_test = spark.read.format("CSV").option("header","true").load("/t1000.csv").map(processCsv).rdd d_test.cache()
println("Loading table (1M * 50)") val d_train = spark.read.format("CSV").option("header","true").load(path).map(processCsv).rdd d_train.cache() println("Training table (1M * 50)") val now = System.nanoTime val model = RandomForest.trainClassifier(d_train, numClasses, categoricalFeaturesInfo, numTrees, featureSubsetStrategy, impurity, maxDepth, maxBins) println(( System.nanoTime - now )/1e9)
val scoreAndLabels = d_test.map { point => val score = model.trees.map(tree => softPredict2(tree, point.features)).sum if (score * 2 > model.numTrees) (1.0, point.label) else (0.0, point.label) } val metrics = new MulticlassMetrics(scoreAndLabels) println(metrics.accuracy) }
def softPredict(node: Node, features: Vector): Double = { if (node.isLeaf) { //if (node.predict.predict == 1.0) node.predict.prob else 1.0 - node.predict.prob node.predict.predict } else { if (node.split.get.featureType == Continuous) { if (features(node.split.get.feature) <= node.split.get.threshold) { softPredict(node.leftNode.get, features) } else { softPredict(node.rightNode.get, features) } } else { if (node.split.get.categories.contains(features(node.split.get.feature))) { softPredict(node.leftNode.get, features) } else { softPredict(node.rightNode.get, features) } } } } def softPredict2(dt: DecisionTreeModel, features: Vector): Double = { softPredict(dt.topNode, features) }}</a href="">
复制代码
4.DolphinDB 的训练和预测脚本
def createInMemorySEQTable(t, seqSize) { db = database("", SEQ, seqSize) dataSize = t.size() ts = () for (i in 0:seqSize) { ts.append!(t[(i * (dataSize/seqSize)):((i+1)*(dataSize/seqSize))]) } return db.createPartitionedTable(ts, `tb)}
def accuracy(v1, v2) { return (v1 == v2).sum() \ v2.size()}
def evaluateUnparitioned(filePath, numTrees, maxDepth, numJobs) { test = loadText("t1000.csv") t = loadText(filePath); clsNum = 2; colSize = 50 timer res = randomForestClassifier(sqlDS(<select * from t>), `cls, `col + string(0..(colSize-1)), clsNum, sqrt(colSize).int(), numTrees, 32, maxDepth, 0.0, numJobs) print("Unpartitioned table accuracy = " + accuracy(res.predict(test), test.cls).string())}
evaluateUnpartitioned("t10k.csv", 500, 10, 48) // choose your own parameter
复制代码
5.XGBoost 的训练和预测脚本
import pandas as pdimport numpy as npimport XGBoost as xgbfrom time import *
def load_csv(path): df = pd.read_csv(path) target = df['cls'] df = df.drop(['cls'], axis=1) return xgb.DMatrix(df.values, label=target.values)
dtest = load_csv('/hdd/hdd1/twonormData/t1000.csv')
def evaluate(path, num_trees, max_depth, num_jobs): dtrain = load_csv(path) param = {'num_parallel_tree':num_trees, 'max_depth':max_depth, 'objective':'binary:logistic', 'nthread':num_jobs, 'colsample_bylevel':1/np.sqrt(50)} start = time() model = xgb.train(param, dtrain, 1) end = time() elapsed = end - start print("Time to train model: %.9f seconds" % elapsed) prediction = model.predict(dtest) > 0.5 print("Accuracy = %.3f" % np.mean(prediction == dtest.get_label()))
evaluate('t10k.csv', 500, 10, 24) // choose your own parameter
复制代码
作者介绍
王一能,浙江智臾科技有限公司,重点关注大数据、时序数据库领域。
更多内容,请关注 AI 前线












评论 3 条评论