

计算机视觉领域的 AI 顶会 CVPR 2020 刚刚落下帷幕,与往年更专注图片识别不同,学术界和工业界的研究方向逐渐转向了更难的视频分割和三维视觉等领域。本次,阿里巴巴拿下了四项比赛的世界冠军,其中就包括 CVPR 2020 的 DAVIS 视频目标分割比赛,本文将详细解读这项冠军技术背后的原理。
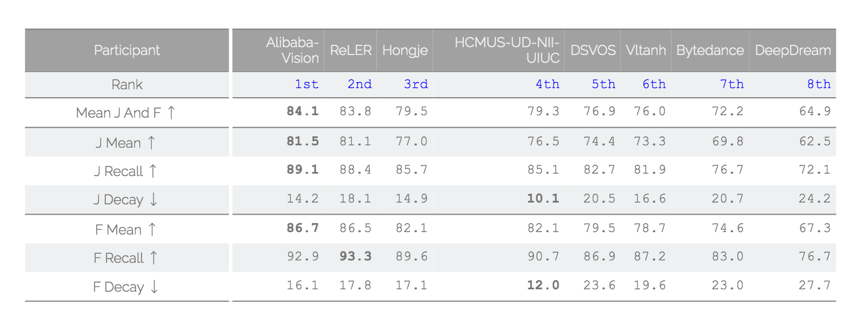
与图像识别不同,AI 分析理解视频的技术门槛较高。长期以来,业界在视频 AI 技术的研究上鲜有重大突破。以 CVPR 会议难度最高的比赛之一 DAVIS( Densely Annotated Video Segmentation)为例,该比赛需要参赛团队精准处理复杂视频中物体快速运动、外观变化、遮挡等信息,过去几年,全球顶级科技在该比赛中的成绩从未突破 80 分,而达摩院的模型最终在 test-challenge 上取得了 84.1 的成绩。

DAVIS 的数据集经过精心挑选和标注,视频分割中比较难的点都有体现,比如:快速运动、遮挡、消失与重现、形变等。DAVIS 的数据分为 train(60 个视频序列), val(30 个视频序列),test-dev(30 个视频序列),test-challenge(30 个视频序列)。 其中 train 和 val 是可以下载的,且提供了每一帧的标注信息。对于半监督任务, test-dev 和 test-challenge,每一帧的 RGB 图片可以下载,且第一帧的标注信息也提供了。算法需要根据第一帧的标注 mask,来对后续帧进行分割。分割本身是 instance 级别的。
阿里达摩院:像素级视频分割
阿里达摩院提供了一种全新的空间约束方法,打破了传统 STM 方法缺乏时序性的瓶颈,可以让系统基于视频前一帧的画面预测目标物体下一帧的位置;此外,阿里还引入了语义分割中的精细化分割微调模块,大幅提高了分割的精细程度。最终,精准识别动态目标的轮廓边界,并且与背景进行分离,实现像素级目标分割。
基本框架
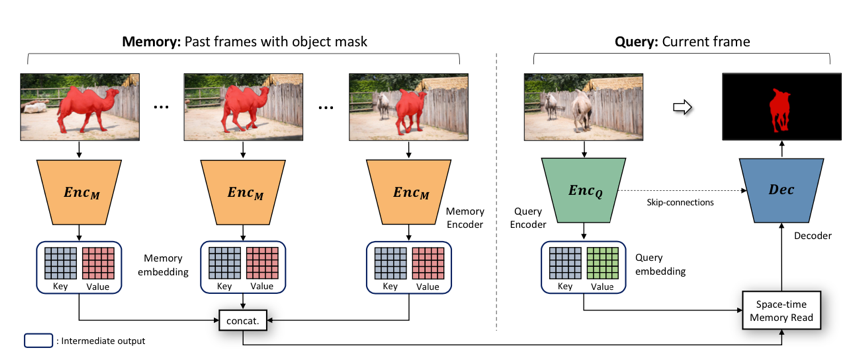
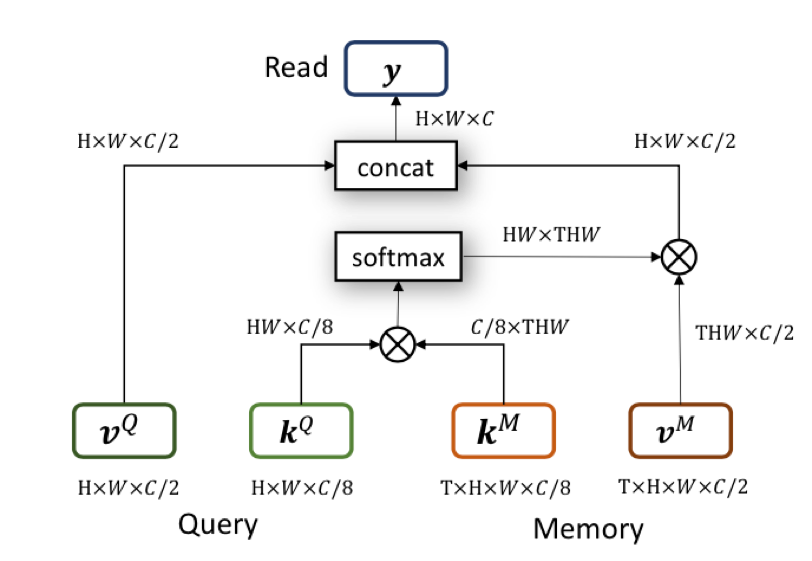
达摩院的算法基于去年 CVPR 的 STM 做了进一步改进。STM 的主要思想在于,对于历史帧,每一帧都编码为 key-value 形式的 feature。预测当前帧的时候,以当前帧的 key 去和历史帧的 key 做匹配。匹配的方式是 non-local 的。这种 non-local 的匹配,可以看做将当前 key,每个坐标上的 C 维特征,和历史每一帧在这个坐标上的 C 维特征做匹配。 匹配得到的结果,作为一个 soft 的 index,去读取历史 value 的信息。读取的特征和当前帧的 value 拼接起来,用于后续的预测。
三大技术创新
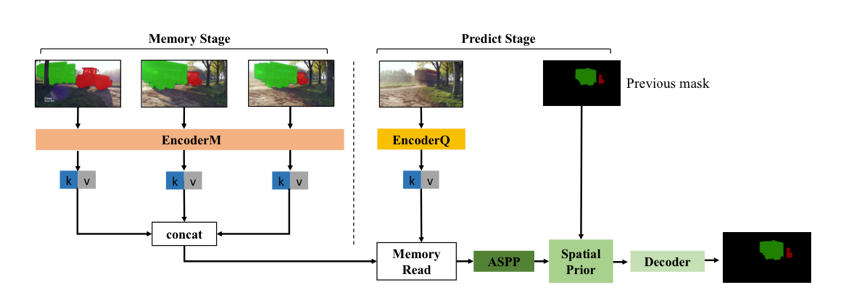
1. 空间约束
STM 的特征匹配方式,提供了一种空间上的长依赖, 类似于 Transformer 中,通过 self-attention 来做序列关联。这种机制,能够很好地处理物体运动、外观变化、遮挡等。但也有一个问题,就是缺乏时序性,缺少短时依赖。当某一帧突然出现和目标相似的物体时,容易产生误召回。在视频场景中,很多情况下,当前帧临近的几帧,对当前帧的影响要大于更早的帧。基于这一点,达摩院提出依靠前一帧结果,计算 attention 来约束当前帧目标预测的位置,相当于对短期依赖的建模。
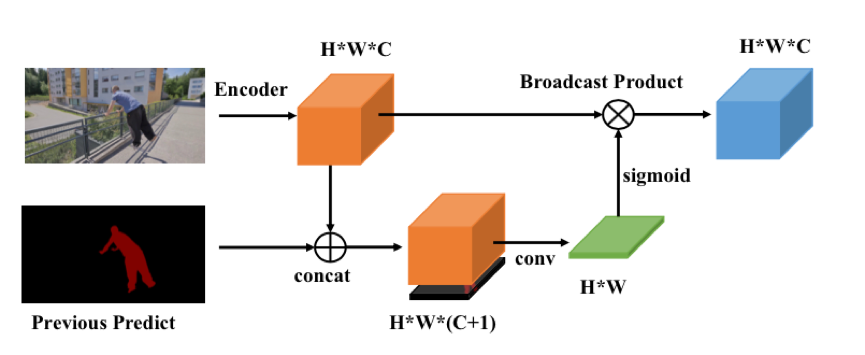
具体的方法如下图所示:
当前帧的特征和前一帧的预测 mask 在 channel 维度上做 concat,得到 HxWx(c+1) 的特征;
通过卷积将特征压缩为 HxW;
用 sigmoid 函数将 HxW 的特征,压缩范围,作为空间 attention;
把 attention 乘到原特征上,作为空间约束。
下图为空间 attention 的可视化结果,可以看到大致对应了前景的位置。

2. 增强 decoder
达摩院引入了语义分割中的感受野增强技术 ASPP 和精细化分割的微调(refinement)模块。ASPP 作用于 memory 读取后的特征,用于融合不同感受野的信息,提升对不同尺度物体的处理能力。
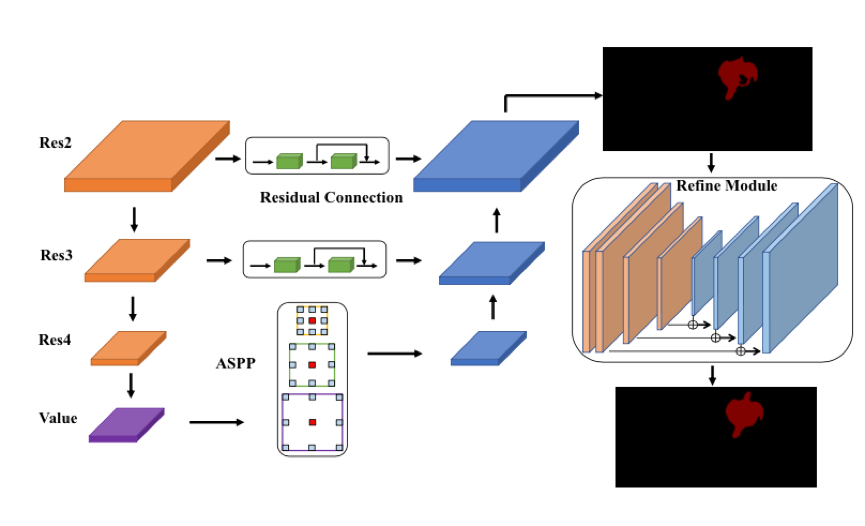
3. 训练策略
达摩院提出了一个简单但是有效的训练策略,减少了训练阶段和测试阶段存在的差异,提升了最终效果。
原始 STM 训练时,会随机从视频中采样 3 帧。这三帧之间的跳帧间隔,随着训练逐渐增大,目的是增强模型鲁棒性。但达摩院发现,这样会导致训练时和测试时不一致,因为测试时,是逐帧处理的。为此,在训练的最后阶段,达摩院将跳帧间隔重新减小,以保证和测试时一致。
其他
backbone: 达摩院使用了 ResNeST 这个比较新的 backbone,它可以无痛替换掉原 STM 的 resnet。在结果上有比较明显提升。
测试策略: 达摩院使用了多尺度测试和 model ensemble。不同尺度和不同 model 的结果,在最终预测的 map 上,做了简单的等权重平均。
显存优化: 达摩院做了一些显存优化方面的工作,使得 STM 在多目标模式下,可以支持大尺度的训练、测试,以及支持较大的 memory 容量。
数据: 训练数据上,达摩院使用了 DAVIS、Youtube-VOS,以及 STM 原文用到的静态图像数据库。没有其他数据。
结果
达摩院的模型,最终在 test-challenge 上取得了 84.1 的成绩。
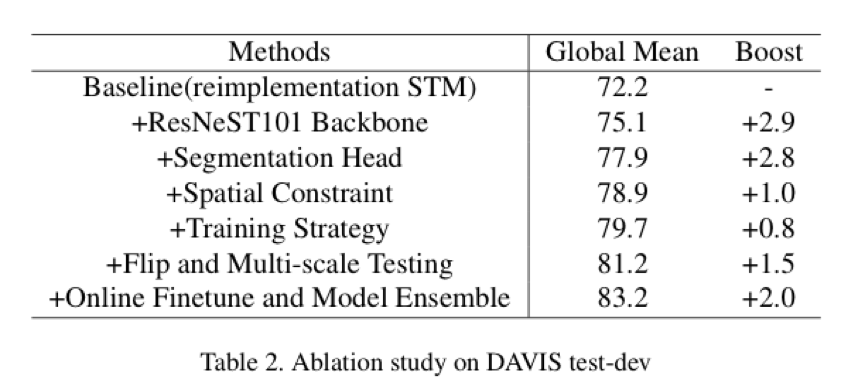
在 test-dev 上的消融实验。达摩院复现的 STM 达到了和原文一致的结果。在各种 trick 的加持下, 得到了 11 个点的提升。
随着互联网技术、5G 技术等的发展,短视频、视频会议、直播的场景越来越多,视频分割技术也将成为不可或缺的一环。比如,在视频会议中,视频分割可以精确区分前背景,从而对背景进行虚化或替换;在直播中,用户只需要站在绿幕前,算法就实时替换背景,实现一秒钟换新直播间; 在视频编辑领域,可以辅助进行后期制作。
Reference:
Oh SW, Lee JY, Xu N, Kim SJ. Video object segmentation using space-time memory networks. InProceedings of the IEEE International Conference on Computer Vision 2019
Wang X, Girshick R, Gupta A, He K. Non-local neural networks. InProceedings of the IEEE conference on computer vision and pattern recognition 2018
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论