

1 文本挖掘的基本流程及常见方法
一、文本数据源的获取
通常数据源按照所得方式可以分为现成数据集、网页信息等。前者数据集通常可自行下载并大大节约数据获取时间,例如在实际分析中可使用专利、论文等专业数据库以发现研究热点或寻求技术空白点,后者主要通过编写爬虫程序或利用现成爬虫工具。
二、数据预处理
预处理任务包括所有用来为文本挖掘系统的核心知识发现操作所准备数据的程序、过程和方法,主要包括分词、数字处理、日期处理、词嵌套、词性标注、词形还原、基于特定领域的词典构建以及去除停用词等。笔者在过往经历中通常处理专利文献等专业文本,故需要针对固定领域构建专业词典,并依据领域通用性词汇等扩充停用词表,为后续文本特征抽取做铺垫。
三、特征提取和特征选择
在预处理过后仍然会存在较多无意义特征,TF-IDF(词频-逆文档频率)是通常进行权值处理的方法,分别体现了特征词在文本中的分布情况和在整个文本集中的分布情况。该算法认为在某文本中出现频次较高,但在整个文本集中出现频次很低的词语,可作为本文的关键词。通过协方差、互信息、信息增益、期望交叉熵、遗传算法、word2vec、CountVectorizer 等方法均可实现特征提取。本人曾经做过的一个案例为利用 gensim 包中提供的 doc2vec 算法,将专利转化为文档向量,并后续通过余弦相似度等计算方法,实现文本相似性对比以避免侵权。
四、算法挖掘
文本挖掘最常见的目的为文本分类,传统的机器学习分类模型通常通过词袋模型等抽取文本特征,然后使用逻辑回归、朴素贝叶斯以及 SVM 等方法进行训练;现在较为流行的是基于深度学习的文本分类,主要包括 textCNN、Bi-LSTM、RNN 等模型。由于之前多次尝试利用 word2vec、doc2vec 等进行实例分析,故对 Facebook 在 16 年开源的 fasttext 较为感兴趣,即快速文本分类,由于是完全线性结构,故极大的增加了训练速度。其与 wordvec 模型类似,两者的相似之处都是通过采用 embedding 向量的形式得到词语的隐向量表达并使用 herarchical softmax 进行优化;但是存在 word2vec 为无监督算法,输出结果为中间词;而 fasttext 是一个有监督算法,输出结果为类别标签,以及 fasttext 不同于 word2vec 仅仅输入上下文,其输入的是句中的每个词以及句子的 n-gram 特征等不同之处。
五、模型评估
类似于通常的模型评估,可使用准确率、精准度、错误率等指标进行模型的评估。
2 文本挖掘案例——文本挖掘在情感分析中的应用
一、案例背景
该案例的实际目的为分析在网购中蕴含的情感和态度,以了解用户对该商品的满意程度,并帮平台更好的筛选优质商家或为品牌商家的产品改进提供参考方向。
二、模型思路
应用文本挖掘方法以探究文本挖掘在评论情感分析中的应用,结合情感分析和 LDA 主题建模两种方法,具体步骤分为数据采集,数据处理,LDA 主题建模以及结果输出,分析流程详见图 1。
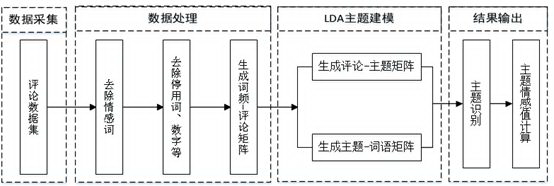
图 1 评论文本情感分析流程
1、数据采集:从数据中随机筛选 100 条正向情感评论及 100 条负向情感评论构成本次分析实例数据集。
2、数据处理:
针对领域特点,扩充情感词汇表,并进行情感词过滤;
去除标点符号、去除数字、停用词过滤、文本分词等数据预处理;
根据各评论所含词汇,构建词频-评论矩阵。
3、LDA 主题建模:采用 LDA 主题分析方法,生成评论-主题矩阵与主题-词语矩阵;
4、结果输出:根据评论于主题下出现的概率以及各个主题代表词汇,识别主题并计算主题情感值。
三、方法介绍
1、LDA 主题模型
LDA(Latent Dirichlet Allocation)是一种常见的文本挖掘模型,用于挖掘和识别目标文档主题。主题模型是一种无监督的学习方法,大多数无监督方法主要基于先前输入的概率模型。所采用的 LDA 方法基于狄利克雷分布的贝叶斯统计原理,通过提取文档的隐含语义结构以对文档做出合理性解释,其基本思想为生成文档-主题矩阵以及主题-词语矩阵,即基于各文档在主题上的概率分布以及词语在主题上的概率分布来阐述文档的主要含义。
在 LDA 模型中,确定最佳主题数是最为关键的一步,本文使用 Gibbs 采样方法推断 LDA 模型中所涉及的多个分布,将输出主题数目初步确定为某一区间,并进一步通过困惑度分析,使用不同数量的主题分别建模。
2、文本情感分析方法
构建情感词库。首先,需要读者自己建立或者下载较为标准的情感词库,比如以“很好”、“美丽”等为代表的正向情感词库以及以“差”、“讨厌”为代表的负向情感词库。
主题词情感计算。在这里需要明确一个概念,即 PMI(互信息),所谓互信息描述的是两个事件 A 和 B 在概率分布上的近似程度,如下述公式所示,
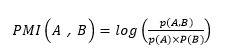
其中,代表词语 A 的出现频率,其测度方式是所有评论中包含词语 A 的语句数量除以所有语句总数,同理,代表词语 B 的出现频率,而 p(A,B)则代表词语 A 与 B 同时出现的频率,其测度方式是所有评论中同时包含两个词语的语句数量除以所有语句总数。且若 A 与 B 为独立分布,则 p(A,B)=p(A)*p(B),,否则,此时 A 与 B 的相关性越强,则其共现概率越大。
利用 LDA 主题建模获得各主题及所属主题词,在此基础上,计算每一主题词与初始评论中正负情感词的情感值。最后,将主题词集 A 中的第 i 个词与正向情感词集及负向情感词集分别相乘,得其情感值,最终将二者做差即可得到词 i 在每个主题下的情感得分,以及各主题总情感得分,如下述公式所示。
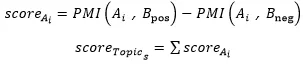
其中 s=1,2,3……k,k 为最佳主题书目。
3、评论情感得分权值计算
利用 LDA 主题建模的另一结果矩阵——评论-主题矩阵,该矩阵代表各评论条目分属于各主题下的概率分布,本步骤将以此作为权重进行每条评论的情感得分,即当评论集 view 中的第 i 条评论在第 s 个主题上分布的概率为,该条评论的情感得分可用进行表示,由下述公式计算得出:
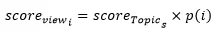
四、结果输出与评价
最初将主题数目设定在 3 至 10 的范围之内,采用十折交叉验证方法,将数据集随机平均分为 10 等份,每次选择 9 份数据进行训练,1 份数据进行测试,通过每个主题数目的困惑度分析,得到困惑度最小时对应的主题数目,并将其作为最终 LDA 主题建模的主题数目,即 k=5,并分别生成主题词分布结果,评论-主题分布矩阵以及主题-词语分布矩阵。根据主题词结果,分别计算各主题所属词语的正、负向情感值,进而加总求得整个主题的情感值。得到的主题结果及情感值如下表所示:

由以上主题词分布结果,从中筛选出具有代表性的 7 个主题词,并根据主题词释义,识别出“内部服务设施”、“吃、住、洗浴状况”、“酒店特色”、“周围环境”以及“地理位置”五大主题,并由评论主题情感值计算结果可进一步得到如下分析结论,主题 1“内部服务设施”和主题 2“吃、住、洗浴状况”以及主题 4“周围环境”情感值得分均为负值,意味着酒店在这三个方面表现不佳,尚不能令消费者满意;而主题 3“酒店特色”所属词语情感值得分均为正值,说明此主题能够充分体现酒店经营的优势,并得到消费者的广泛认可;主题 5“地理位置”总体情感值得分为正,说明酒店选址较为合理,交通较为便利。综上,酒店应在发挥原有优势的基础上,更加注重自身服务品质及基础设施建设。
3 小结
本篇短文通过步骤简介以及结合 LDA 主题模型和情感分析方法进行实例分享的方式与大家浅谈文本挖掘的应用。上述分享为笔者在学习生活中所经历的步骤或方法,诸多不足还请大家多多指教,期待之后与大家分享更多有关深度学习的实例。
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论