

导语 大规模的强化学习需要海量的异构计算资源,批量快速启停训练任务,高频更新模型参数,跨机跨进程共享模型数据等。传统的手工管理模式操作繁琐,面临诸多不确定性,带来的各种挑战无法支撑大规模强化学习的场景。本文介绍了腾讯内部某业务基于 TKE 构建大规模强化学习解决方案,以及与传统手工模式对比该方案带来的优势。
一、项目挑战
大规模的强化学习需要海量的异构计算资源,批量快速启停训练任务,高频更新模型参数,跨机跨进程共享模型数据等。在传统的手工管理模式下,大规模的强化学习面临诸多问题:
1. 经费预算受限
单次全量实验需要多达数万个 CPU 核心和数百个 GPU 卡。
单次全量实验持续一周到两周。连续两次全量实验间隔从几天到几周不定。从整体上看资源使用率很低,实验间隔期资源浪费,经费有限,无法支撑长期持有如此大规模数量的物理机机器资源。
2. 大规模机器的管理复杂性
手动管理和运维几千台机器(折合几万核心),包括 IP,账号、密码,GPU 驱动安装,训练环境管理等,复杂性和难度极高。代码更新后,发布困难,一致性难以保证。随着训练规模的进一步增大,管理复杂的问题更加突出。
3. 效率问题
分布式训练代码架构,要求快速批量启停数万规模的角色进程。
通过脚本 SSH 的方式实现多个跨机器进程的启动和停止效率低下,可靠性不足。
4. 进程的容错性
训练需要运行海量的进程,运行过程中异常退出缺少监控和自动拉起,容错性低。
5. 训练任务运行时弹性伸缩
训练时如果生产速度不够,需要手动调整 actor 数量,无法弹性伸缩,提高吞吐量。
6. 代码的版本管理
项目有多个模块,部署不同版本的代码繁琐、易出错,不利于问题定位和保障现网一致性。
二、训练架构
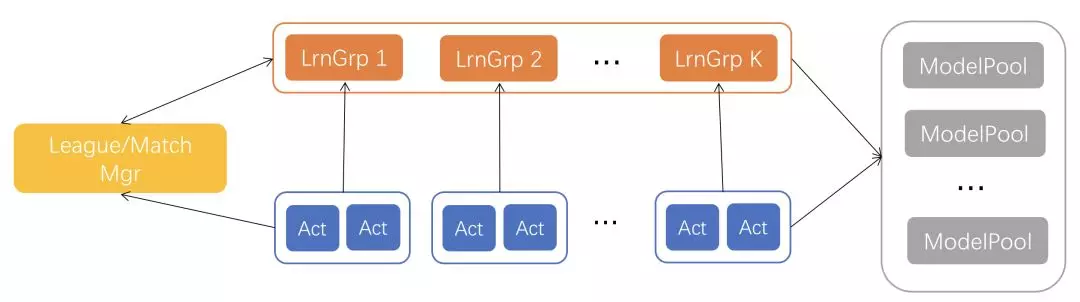
使用基于 Actor-Learner 架构[1, 2]的分布式强化学习训练,包括以下几种角色的进程:
Actor: 负责产生一系列观测数据(trajectory unroll)
Learner: 从 Actor 拿到观察数据,使用梯度下降更新神经网络模型
ModelPool: 神经网络模型中转。Learner 会定期把神经网络模型推入;Actor 会定期从这儿拉取最新神经网络模型
Manager: 训练管理,包括自对弈比赛的安排,超参数的变异,模型的 checkpoint 保存等
Actor 通常部署在较便宜的 CPU 机器上,每个 Actor 需要 3 到 4 个 CPU cores;Learner 部署在 GPU 机器上,每个 learner 需要 1 个 GPU 卡;ModelPool 和 Manager 部署在网卡带宽较大(>=25Gbps)的机器。
一次实验中,各个角色的进程的典型数量通常是:
Actor: 几十个到上万个
Learner: 几个到几百个
ModelPool: 一个到十个
Manager: 一个
整个训练框架的结构图如下:
三、业务需求
使用上需要具备以下能力:
多个不同角色进程的批量启动、批量停止
无需手动管理集群机器的 IP,账号,密码;只需关注每个进程需要多少 CPU,内存,GPU 卡等计算资源
数据生产者进程的容错性(出现不可恢复的底层错误进程能自动重启)和进程个数的横向伸缩(以此来调节数据生产速度)
训练(training)角色和评测(evaluation)角色之间共享网盘存储,方便交换神经网络模型数据
成熟的日志解决方案,包括无侵入的日志采集、快速的日志检索/搜索,仪表盘式的集群资源监控等,方便调试、评估训练代码
能通过浏览器访问,基于 web 的训练、评测结果呈现
能够弹性使用资源,仅在使用时计费,控制研发成本
四、基于 TKE 大规模分布式强化学习解决方案
1. TKE 整体架构
TKE 的整体架构如下图所示。
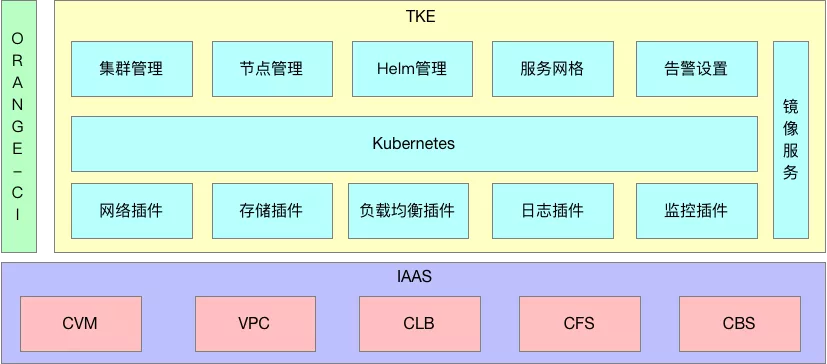
该解决方案通过 TKE 整合云上 CVM 资源,提供强化学习需要的 CPU 和 GPU 资源;通过 CLB 创建 LoadBalance 类型 Service,暴露训练代码的 tensorboard 和评测代码的 AI 胜率曲线绘图;通过 Web 查看训练结果;通过 CFS 创建共享卷,方便在训练、评测时各个 pod 之间共享神经网络模型、评测准确率、AI 对战胜率等数据。
同时,借助工蜂提供的 Webhook 功能,与 Orange-CI 结合实现代码提交自动构建镜像,并推送到 TKE 镜像仓库,提升研发效率。
此外,还支持通过 jinjia 模板调整参数并快速生成 yaml,一键部署到 K8S 集群实现快速启动训练任务。代码有更新时,无需逐台机器手动发布,只需修改镜像 tag 就能实现快速更新。训练任务结束后,一键删除即可实现快速停止训练任务。
2. 使用方式
使用上,接近“云原生”的方式。
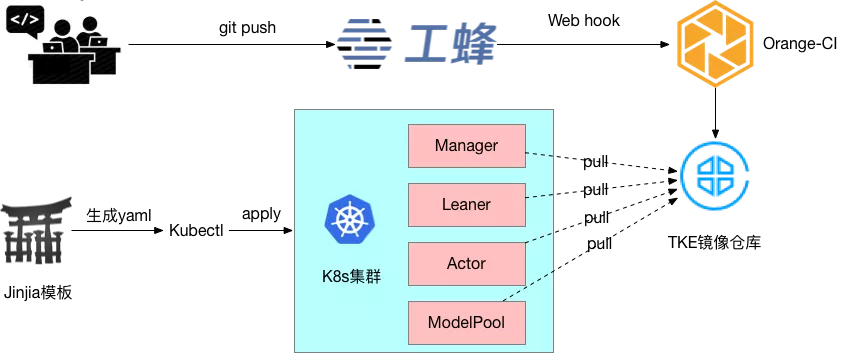
使用 Orange-CI,结合工蜂提供的 webhook 功能,代码提交后自动构建镜像,并推送到腾讯云的镜像仓库,使用镜像的 tag 有效管理代码版本
通过 jinjia 模板快速生成部署 yaml 。每次训练仅需要修改模板文件的参数,例如几个 learner,几个 actor,每个 learner 要几块 GPU,每个 actor 要几个 CPUcores,以及机器学习训练相关(例如 learning rate, regularizer coefficient)的参数配置,即可快速生成 K8S 集群的部署 yaml
使用 kubectl 命令提交 yaml 文件实现批量启动、停止。比如,使用 kubectl apply 快速批量启动训练任务,使用 kubectl delete 快速批量停止实验任务,使用 kubectl edit 可以快速更新训练任务
Actors 使用 ReplicaSet 管理,提升稳定性。当某个 Actor 中的《星际争霸 II》 game core 出现无法恢复的底层错误(原因未知,也许是 game core 的缺陷),所在进程会挂掉,但相应的 pod 会被自动重启,不影响数据的继续生产;当观察到生产速度不够,可以直接使用“kubectl edit”命令编辑相应的 ReplicaSet,将期望的 actor 数量调多,达到更大的生产速度。
使用腾讯云的 CFS 作为网络的共享云盘。一方面,我们将其配置为 K8S 的 PV(Persistent Volume) 和 PVC(Persistent Volume Claim),方便在训练、评测时各个 Pod 之间共享神经网络模型、评测准确率、AI 对战胜率等数据;另一方面,我们也将其 mount 到某台母机上,方便离线查看想看相关数据。
我们使用 TKE 提供的 LoadBalancer 或者 kubectl proxy 的方案,暴露训练代码的 tensorboard 和评测代码的 AI 胜率曲线绘图(自有代码),在办公机的浏览器上查看结果。
为 K8S 集群配置好伸缩组,弹性使用机器资源、按需计费。当向 K8S 集群提交任务,发现现有的集群中有 pod pending,伸缩组会自动买入机器,当集群资源过剩,自动退还机器,节省资源,减少人工干预。该策略避免了因资源预估不准而买入过多资源造成资源浪费。
五、创新性
基于 K8S 云原生的使用方式进行大规模分布式强化学习的训练,主要创新点:
以资源需求为中心(也即,每个角色需要多少 CPU,多少内存,多少 GPU 卡),管理和调度一次实验所需的集群机器,简化编程模型
弹性使用资源,自动伸缩集群中的机器,按需、按时计费,压缩研发成本
部分进程的容错性(出现不可恢复错误时自动重启)和横向扩容
依托腾讯云,使用附加产品避免重复造轮子,如日志服务,监控仪表,网盘,镜像服务器等
六、使用 TKE 带来的价值
1. 大幅提升实验效率
不再需要手动管理和运维大批量机器,节省了大量机器环境初始化,密码管理和进程部署的时间。
与传统购买物理机耗时几个月相比,借助腾讯云提供的海量资源和快速创建能力,可以在短时间内满足大规模强化学习所需要的大批量资源。
2. 提升发布效率
传统模式下,代码更新后需要手动逐台通过 rsync/scp 的方式更新程序。容器化以后,仅需要一条命令一键更新容器镜像,集群就会自动滚动更新,从小时级别缩短到分钟级别。
3. 节约成本
与传统模式相比,不再需要长期持有大批量的 CPU 和 GPU 设备。
训练任务开始,根据预估的规模购买 CPU 和 GPU 设备。
训练结束后,退还所有设备,设备可以提供给其他公有云客户使用,极大地缩减资源成本。综合考虑使用周期和使用规模、GPU 机器折旧等因素,使用 TKE 的弹性资源方案预计可以节省 2/3 的成本。
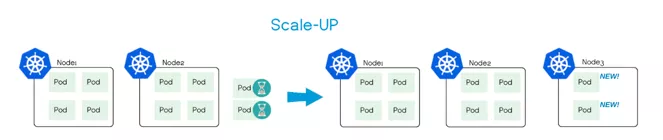
4. 集群弹性伸缩
集群自动扩缩容(Cluster Autoscaler),可以动态地调整集群的节点数量来满足需求。当集群中出现由于资源不足而无法调度的 Pod 时自动触发扩容,从而减少人力成本。当满足节点空闲等缩容条件时自动触发缩容,为您节约资源成本。
5. 面向资源,简化管理
训练从面向机器变成面向资源,只需声明不同角色需要的资源,无需关心具体运行在那一台机器。
6. 动态调度,提升资源利用率
支持最基本的资源调度,如 CPU、内存、GPU 资源等。
声明训练任务所需要的资源后,K8S 的调度器负责自动调度,通过预选和优选二级调度算法选择合适的节点运行训练任务。
K8S 还支持亲和性调度。比如,给节点打上 GPU、CPU、网络等不同类型的标签,可以实现 ModelPool 和 Manager 调度到网络型节点,Actor 部署到 CPU 节点,Learner 部署到 GPU 节点。
节点发生故障时,会重新调度到健康的节点,保障训练任务正常运行。
7. 容器化保证环境一致性
把训练所依赖的环境打包到镜像中,Docker 容器可以在不同的开发与产品发布生命周期中确保一致性,进而标准化环境。
除此之外,Docker 容器还可以像 git 仓库一样,镜像标签管理不同的代码版本。通过修改镜像标签,可以非常方便地完成代码发布和回滚。
8. 接入 CI,提升研发效率
通过接入 CI 平台,实现持续集成,代码 push 到工蜂,并通过 webhook 通知 CI,自动完成镜像编译并推送到镜像仓库,提升研发效率
9. 发布高效,回滚简单
通过简单地修改训练任务的 Docker 镜像标签,即可快速完成发布和回滚。
与传统方式手动发布相比,更叫高效和可靠。通过镜像回滚也避免了传统方式备份带来的额外运维成本。
10. 持久化存储,方便数据共享和保存训练结果
TKE 支持云上的 CFS、CBS 存储卷,通过创建 PV/PVC,可以非常方便地在训练、评测时在各个 Pod 之间共享神经网络模型、评测准确率、AI 对战胜率等数据,以及实现训练结果的持久化保存。
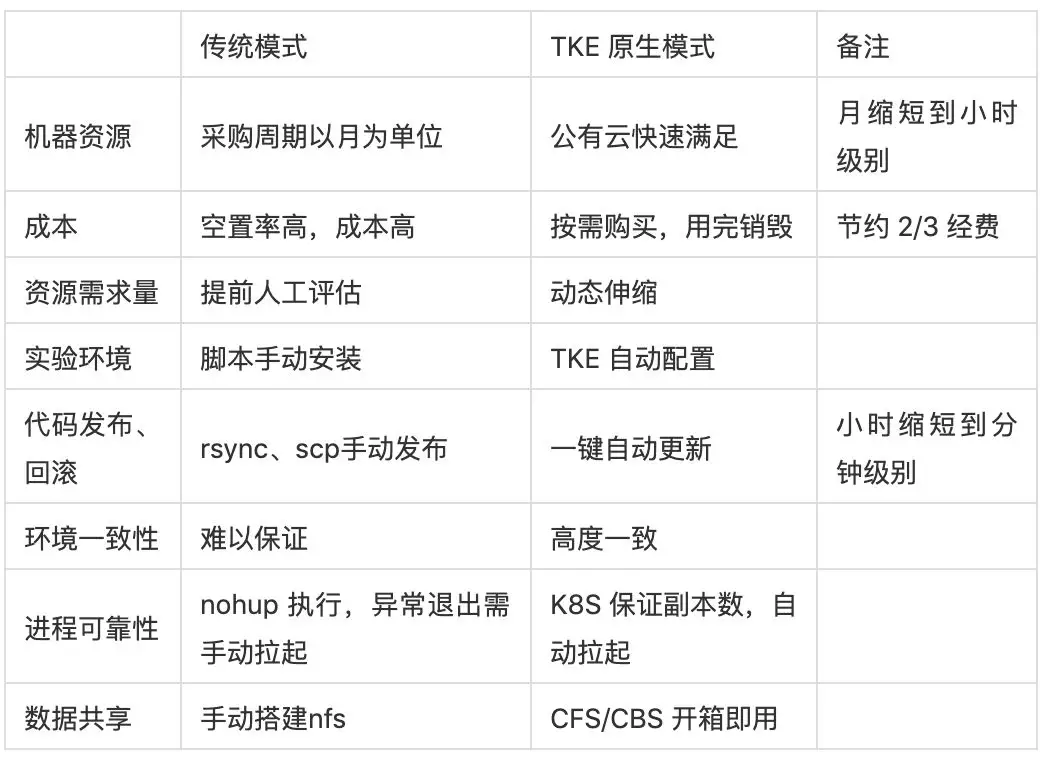
总结如下:
七、遇到的问题
由于训练集群规模较大,使用过程中也遇到以下一些问题。
1. etcd 性能瓶颈
由于训练需要多达数万个 CPU 核心和数百个 GPU 卡,折合几千台服务器。接近 K8S 官方单集群理论上支持 5k 节点。集群节点数量较多,对集群的 etcd 性能要求很高。TKE 目前已支持根据以下指标自动扩容 etcd
集群的节点梳理
集群 apiserver 的时延
指定的 AppId 和集群 ID
2. 镜像仓库并发
集群数万 Pod 并发拉取镜像,对镜像仓库造成较大压力,可以通过镜像预拉取和分批拉取满足数万 Pod 并发创建需求。
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:
https://mp.weixin.qq.com/s/cYwEioqchp8hSl7m34PqvA

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论