

0 导语
性能优化是一条既充满挑战又充满魔力的道路,非常幸运如今基于 X86 的性能优化方法及工具已经比较成熟,在 TGW 产品架构即将变革之际,我们结合 X86 常用的性能优化方法与工具,深入分析 DPDK 版本 TGW 转发架构与流程将 TGW 转发性能从 13Mpps 优化到 50Mpps;本文带你穿越下一代 TGW 性能优化之旅,快上车吧。
1 前言
目前腾讯突破“双百”里程碑(服务器超过 100W 台,带宽峰值超过 100T)其所承载的业务规模、流量已迈入全球第一梯队。
为满足日益增长的客户需求,TGW 先后经历了从 10G 到 40G 再到 100G,从内核版本到 DPDK 版本的重磅演进。另外针对当前 TGW 产品架构存在的一些问题,下一代 TGW 大体方案已基本敲定:EIP 无状态化提升到 Region 级统一接入公网流量,对转发性能有更高的要求与挑战。
着眼于即将到来的 TGW 产品架构变革与不断攀升的流量带宽,未雨绸缪 TGW 今年上半年已经支持 100G 网卡,并随后针对 100G 转发性能进行了专门优化,如题本文重点分享 TGW 转发性能优化相关经验:下一代 TGW 从 13Mpps 到 50Mpps 性能优化之旅。
2 名词解释
TGW:Tencent Gateway;腾讯公网流量统一入口,承担了腾讯所有核心业务接入如:微信、王者、吃鸡、腾讯视频等
RTC:run-to-completion 指从开始处理报文起到报文发出去在一个核上终结。
Pipeline:指将报文处理要经过多个核,典型的两段式:分发核 RX+转发核 TX;每 RX 一个接收队列,每 TX 一个发送队列;
PPS:每秒钟转发的报文数 Packets/Per Seconds
M:1M = 1000*1000
100G 线速:64 字节转发性能 148.8Mpps
3 优化目标
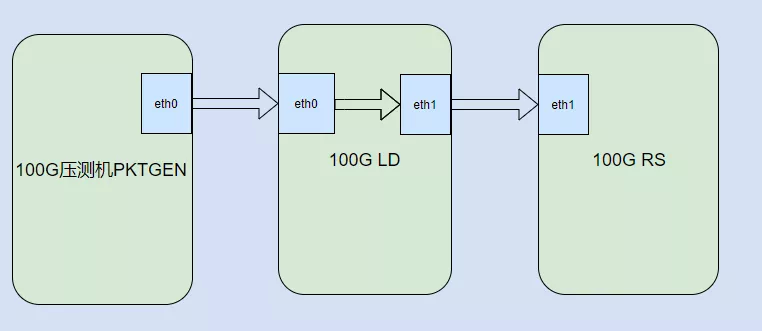
图一 压测拓扑
性能压测网络拓扑如图一所示其中 100GLD 采用高性能 100G 服务器。
零丢包转发性能定义:压测数据流从 100G LD eth0 口入匹配转发表加封装后从 eth1 口发出,每转发核表项 1M,持续打流 60 秒能够零丢包转发的 PPS 数。优化目标定为保四争五:最低优化到 40Mpps,力争 50Mpps。
4 优化之旅
前面约定好了性能优化的目标与场景,剩下的挑战就是深入到 TGW 当前的转发架构与转发流程中持续分析性能瓶颈点,并找出优化方法将之逐个击破,总览如下图所示,最终我们将零丢包转发性能优化到 50Mpps,极限性能 60Mpps。

4.1 转发架构优化
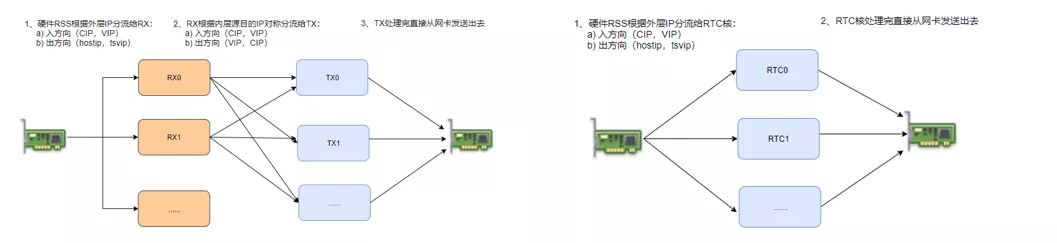
图二 优化前后架构对比(左图为优化前,右图为优化后)
优化前后的架构对比如图二所示,当前转发采用两段式架构依靠 CPU 分发数据包(16RX 核+16TX 核),转发性能为 13Mpps,极限性能 20Mpps。
下一代 EIP 不再支持 ALG 等依赖五元组状态的功能,可以只根据 VIP 做无状态转发可直接由网卡分流给转发核,因此可以将 RX 核优化掉。实现了 RTC 架构原型后,另外解决一处因转发线程数增多而凸显的伪共享问题再加上一些代码级优化,零丢包转发性能优化到 25Mpps,性能将近翻倍。

4.2 增加转发核
硬件替代 CPU 做 RSS 分流本质是利用更多的 CPU 来做转发,那么从 32 个转发线程扩展到 64 个性能可以继续翻倍嚒?
所使用的 100G 服务器开启超线程的情况下可以用到 96 个线程,除掉已经使用的 50 多个线程外,可以再增加 32 个做转发线程。然而实际测试结果却令人意外:

瓶颈点分析:为何核数增多一倍,性能距离提升一倍还很遥远?
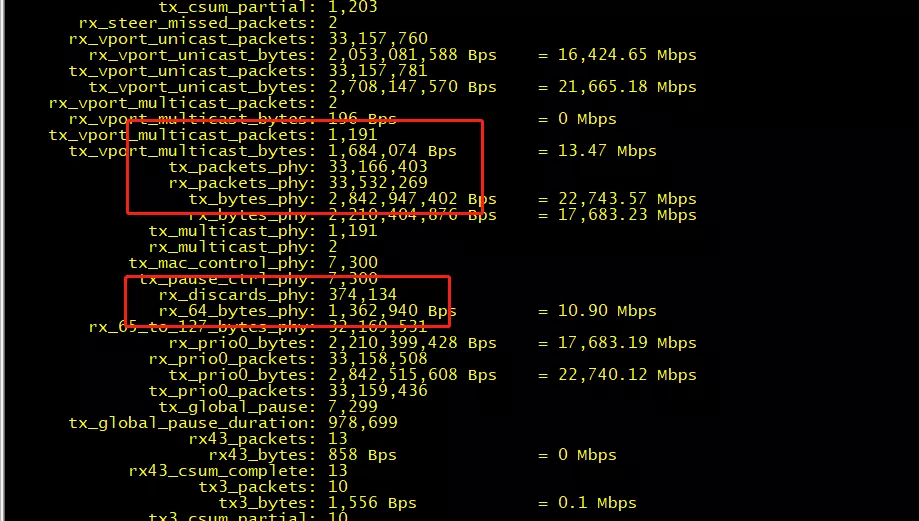
图三 收包瓶颈
反复分析发现:此时已接近网卡收包性能瓶颈,超过 33Mpps 后开始出现网卡丢包统计 rx_discards_phy(注:图三为使用单网卡测试结果)。
经 Mellanox 研发确认,出现该统计说明达到网卡收包性能瓶颈,原因如下:网卡队列数增多,转发线程数增多,CPU 与网卡同时竞争内存控制器竞争恶化后导致网卡性能下降,建议减少使用的网卡队列数。进一步测试结果如下表所示:
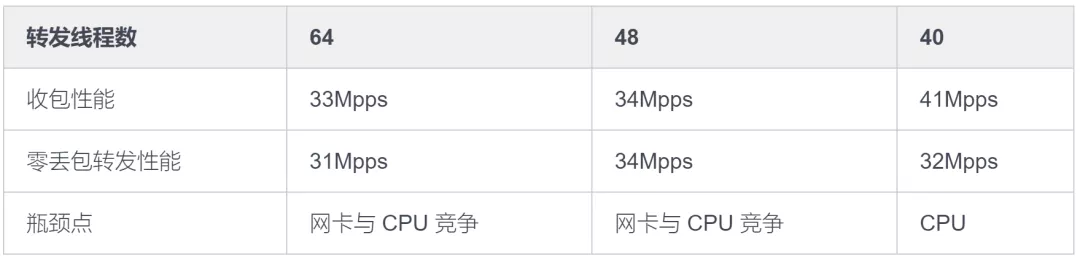
当转发线程减少到 40 个时,收包性能可以达到 41Mpps,但零丢包转发性能只有 32Mpps,瓶颈在 CPU 侧,那么基于 40 个转发线程优化能否达到原定的目标值 40Mpps 呢?
4.3 开启超线程时优化至 40Mpps
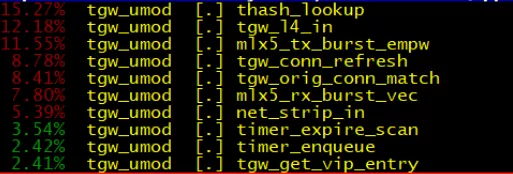
图四 Perf 热点分析
根据图四 Perf 热点统计结果进一步分析后,想到以下两个优化点:
去掉不必要的操作:tgw_conn_refresh 在下一代无状态 EIP 场景是不需要的;
单包发送改为批量发送,发送函数 CPU 占用率从 11.55%降低到 7.35%;虽然 CPU 利用率只下降 4%,但将零丢包转发性能提升了近 10%以上;
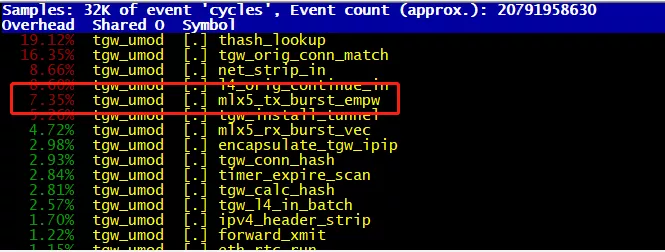
图五 优化后的 perf 热点
优化上述两点后开启超线程时使用 40 个转发线程转发性能提升至 40Mpps,此时收包瓶颈点为 41Mpps,开启超线程时再继续优化几乎没有空间,因此考虑关闭超线程后使用更少的网卡队列数进一步优化。
4.4 关闭超线程时优化至 50Mpps
关闭超线程后分别测试 20 个转发核与 30 个转发核性能如下:

增加更多的核来达到更高的性能?
关闭超线程后可用的核仅有 48 个,除了做转发外还需一些核做其它用处比如管理核、限速核、KNI 核,日志核等,另外还要预留一些给系统;
再增加核数,零丢包性能并不能线性增加,投入产出不成正比;
前车之鉴:CPU 增多后与网卡对于内存控制器的竞争会变得恶化;
因此基于 30 个转发核继续优化。
下一个优化点在哪里?回到图五 perf 热点,显然此时 TOP1 的热点在于 Hash 查找:thash_lookup 与 tgw_orig_conn_match 加起来占到了 35%的 CPU 利用率。实际性能测试时打 1M 并发流量是均匀分布的(符合现网高并发特点),Hash 查找时每包产生 CacheMiss 进而成为 TOP1 的热点不足为怪,那么如何优化呢?
对 Hash 表数据结构深入剖析后得出一个可行的优化方案:显式预取 Hash
查表时的第一个 bucket 内存到 CPU 缓存;原理如图六所示。但 bucket 中存储的各个表项地址依赖于 bucket 先加载到 CPU 才能得知,这部分内存无法预取。
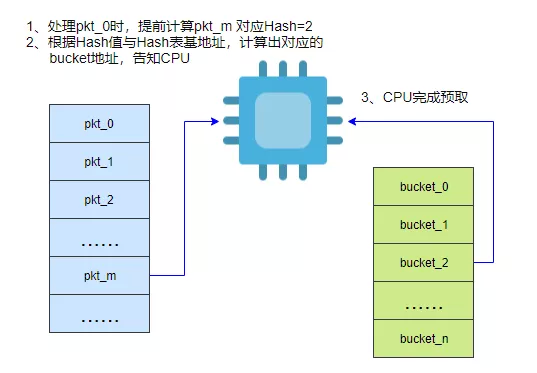
图六 预取原理
优化后的性能数据如下表所示:

CPU 利用率以及 Cache 命中率对比如下:
CPU 利用率优化前后如图七所示,thash_lookup 利用率从 19%降到 5%以内;
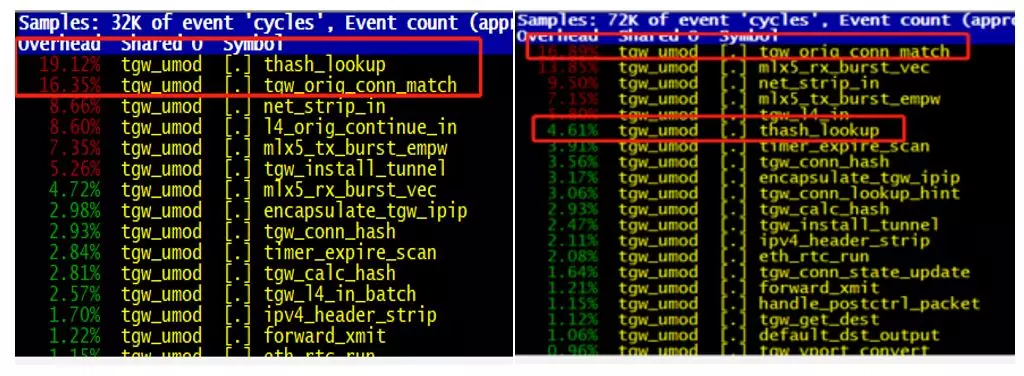
图七 优化前后 CPU 利用率对比
L3 与 L2 Cache 命中率分别提升 8%,如图八所示 L3 Cache 命中率从 13%提升到 21%;L2 命中率从 53%提升到 61%;
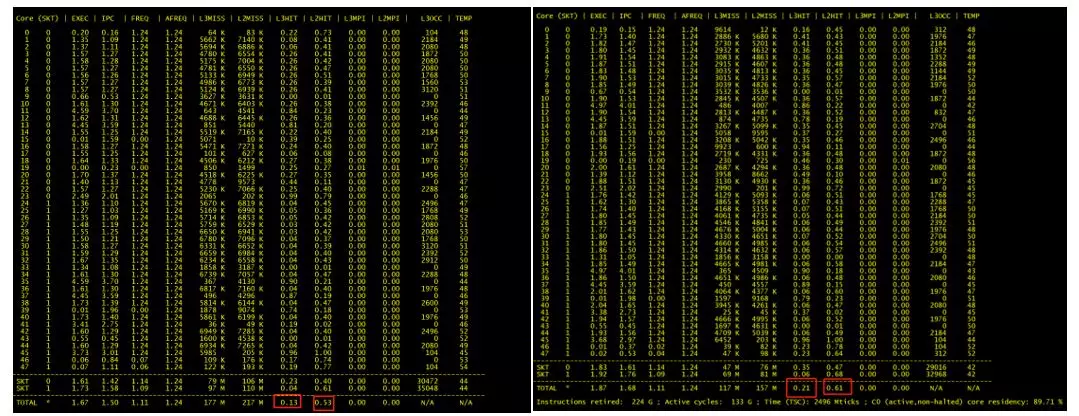
图八 优化前后使用 PCM 工具查看 Cache 命中率对比
5 总结
5.1 优化点总结
最终我们将转发性能优化到 50Mpps,极限性能 60Mpps,所用到的优化方法总结如下:
转发架构优化:PipeLine 优化为 RTC;
关闭超线程:增强单核转发能力;
批量发送:显著提升零丢包性能;
解除伪共享;充分发挥 CPU 并发能力;
批量处理:降低每包平均花费的 CPU 指令数;
内存预取:降低 Cachemiss 及跨 NUMA 带来的影响;
去除无关逻辑;
5.2 问题总结
超线程开启还是关闭好?关闭超线程单核转发能力更高,一般在单线程的 2 倍左右,应对微突发能力更强,所以从这个角度看关闭超线程更优;
网卡的 DDIO 当跨 NUMA 时会不会失效?会失效 DDIO 只能将数据包的内存直接放到与网卡同 NUMA 的 Cache 里,当数据包需要在另一个 NUMA 的 CPU 上做处理时,这个技术就失效了;
prefetch 指令有没有开销?prefetch 指令只是暗示 CPU 即将访问到的内存地址,实际是从 CPU 的 Cache 中分配了一条缓冲行,将内存地址填入就返回;但我们优化时遇到了一个有意思的现象如图九所示 prefetch 指令本身成为了 TOP3 的热点函数;其原理如下:prefetch(a->ptr);a 指向的内存并没有在 CPU 的 cache 里,prefetch 需要等待 a 指向的内存进入了 CPU Cache 才能返回;
CPU 数越多,网卡队列数越多,性能越高?答案是否定的,网卡与 CPU 在操作内存时存在竞争;
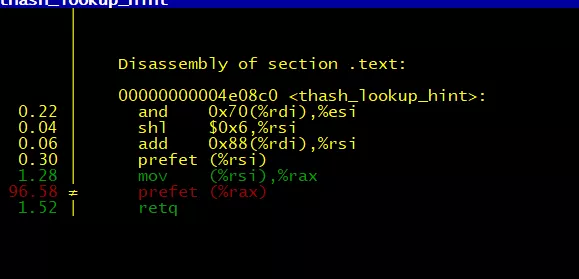
图九 prefetch 指令成为热点
作者介绍:
和广强,腾讯 TEG 后台开发工程师
本文转载自公众号腾讯技术工程(ID:Tencent_TEG)。
原文链接:
https://mp.weixin.qq.com/s/AK8M2KiN4tFW44PjJOaEuQ

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论