

1.YARN 简介
1.1 YARN 生态圈
YARN (Yet Another Resource Negotiator) 是 Hadoop 集群的资源管理系统,是 Hadoop 生态中非常重要的成员项目。
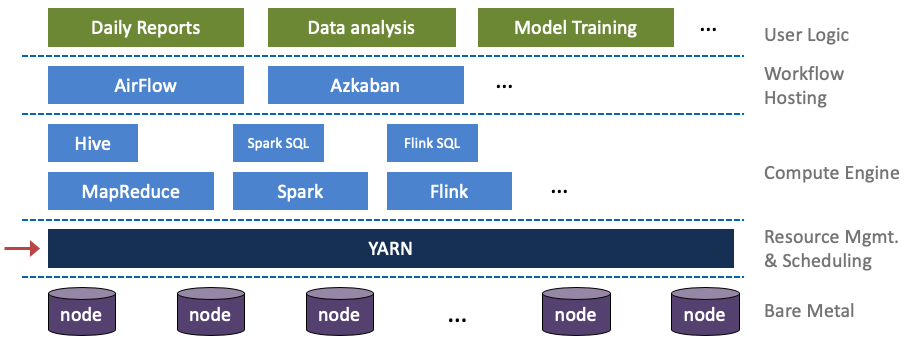
一般来说,离线生态可以分为五层:
最底层是裸金属层, 由众多物理节点组成,每个节点上运行着通用的操作系统。
次底层是集群资源管理层, YARN 就处在这一层中。
再往上是分布式计算引擎层, MR/Spark/Flink 等计算引擎处于这层,为了能让业务同学更加低成本的写计算任务, 各个引擎都支持 SQL 功能。
再往上是作业托管层,用来提交 ad-hoc 的作业,管理周期性的批处理作业,管理长时间运行的流式作业。
最上层是用户逻辑层,如数据日报,数据分析,模型训练等.
1.2 YARN 架构
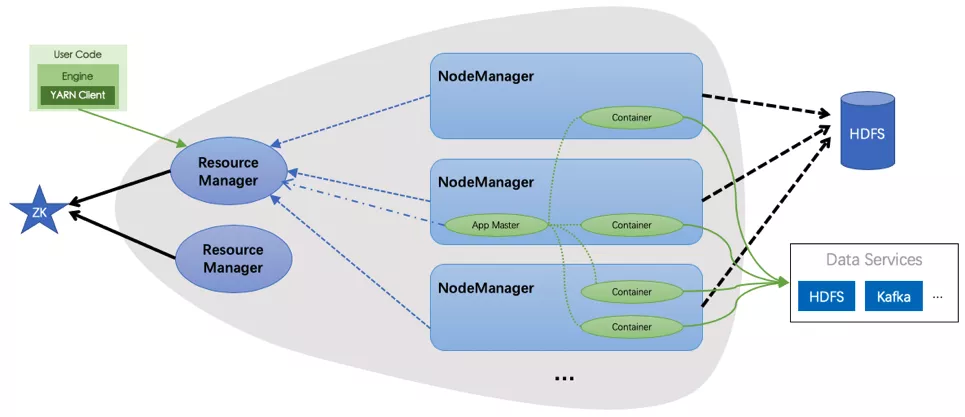
上图中灰色背景区域是 YARN 的主要架构, 主要包含两种角色:
ResourceManager
整个集群的大脑,负责为应用调度资源,管理应用生命周期。
对用户提供接口,包括命令行接口,API, WebUI 接口。
可以同时存在多个 RM,但同一时间只有一个在工作,RM 之间通过 ZK 选主。
NodeManager
为整个集群提供资源,接受 Container 运行。
管理 Contianer 的运行时生命周期,包括 Localization,资源隔离,日志聚合等。
YARN 上运行的作业:
在运行时会访问外部的数据服务,常见的如 HDFS,Kafka 等
会在运行结束后由 YARN 负责将日志上传到 HDFS 中
2.字节跳动对 YARN 的定制
字节跳动的 YARN 是在 16 年从社区当时最新的 2.6.0 版本中 fork 出来的,主要承载着公司内的离线作业/流式作业/模型训练三大场景。由于公司内的 YARN 服务规模巨大、场景复杂,遇到了各种问题,在社区版本没有提供解决方案之前,内部研发同学定制了许多内容来解决具体问题,经过 4 年来上千次的修改,公司内的版本已经跟社区的版本相差较大。
今天给大家介绍一些比较关键的定制,希望能给大家带来一些启发。这些关键定制主要包括四个方面:
利用率提升: 包括分配率提升和物理使用率提升。
多种负载场景优化: 包括批处理 / 流式 / 模型训练 三种场景下的体验提升。
稳定性提升: 包括摆脱对 HDFS 强依赖, Container 分级与驱逐, 非受控 Container 管理。
异地多活: 包括统一的 YARN Client 和 UI 等内容。
2.1 利用率提升
2.1.1 多线程版本的 Fair Scheduler
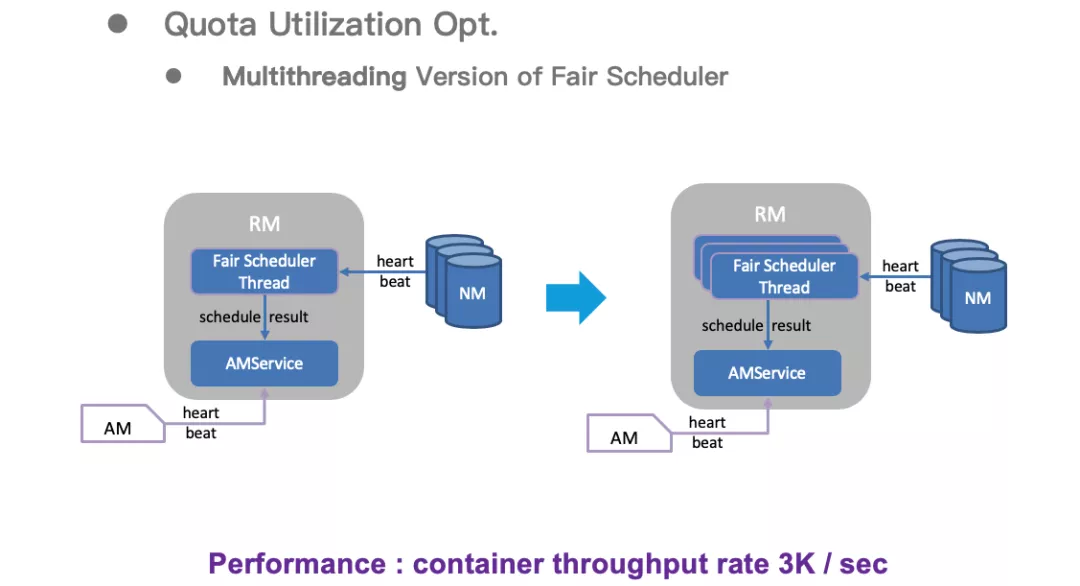
社区原生版本的 FairScheduler 是单线程的,在节点数量较多时,是整体集群最大的瓶颈。
我们通过将 FairScheduler 改造为并发的多线程版本,并将调度器内部的锁拆分为更加细粒度的读锁和写锁,将调度吞吐提升 7 倍以上,在生产环境中达到每秒 3K 个 Container 的速度(未触及性能瓶颈)。
2.1.2 考虑节点 DRF 的调度
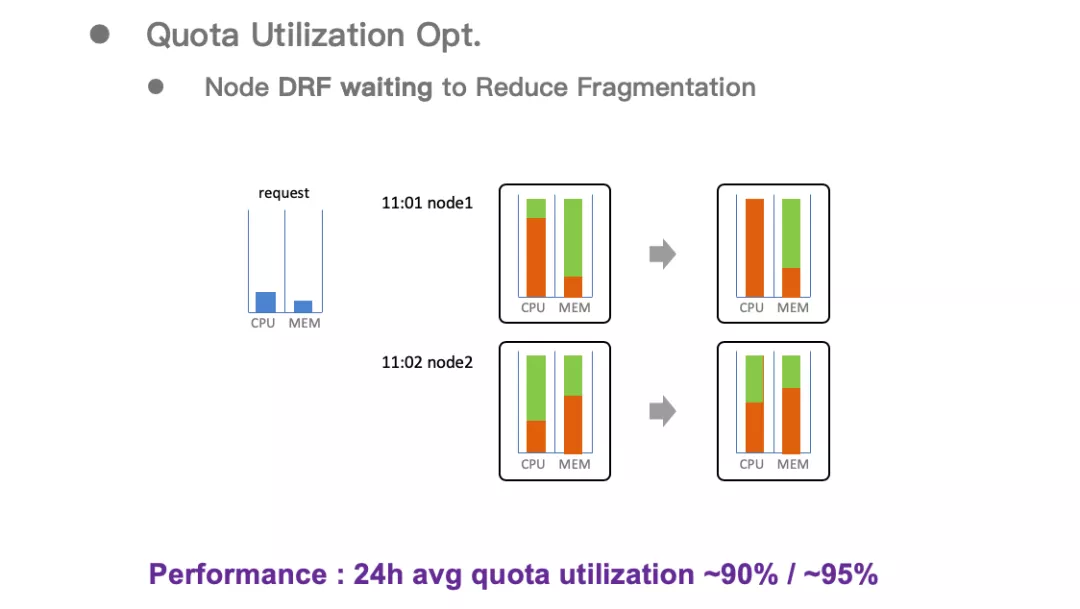
原生的 YARN 在调度时只考虑资源是否满足,经常会出现一个节点 CPU 被打满,但是内存还有剩余的情况。
我们引入节点 DRF(Dominant Resource Fairness)机制,计算每个节点的剩余资源的主资源,当调度的 Task 的主资源与节点的主资源不匹配时,先延迟此次调度,直到一定次数后再放松约束。
通过引入这个机制,集群资源的碎片化问题大幅降低,生产环境中可以达到 CPU 和内存的 24 小时平均利用率都在 90%以上。
2.1.3 提升单集群规模

单个集群的规模越大,就可以有更多的用户和作业使用这个集群,这个集群的利用率也会更高。但是原生的 YARN 在达到 5K 节点规模时开始出现各种问题,比如说一次简单的切主可能会导致整个集群雪崩。
我们为提升单集群规模做了一系列的优化。
首先,通过对 YARN 内部事件梳理调整,精准的修改了一些事件处理逻辑。
然后,将 NodeManager 节点的心跳机制改为根据 ResourceManager 的压力动态调整。
之后,修改内存单位(int->long)突破单个集群 21 亿 MB 的限制
再之后,通过对切主过程进行深度优化, 将切主时间控制在秒级
当然还有很多其它的细节优化不再一一列举,最终的效果是让单个生产集群达到了 2 万节点的规模。
2.1.4 与流式 &在线服务混部
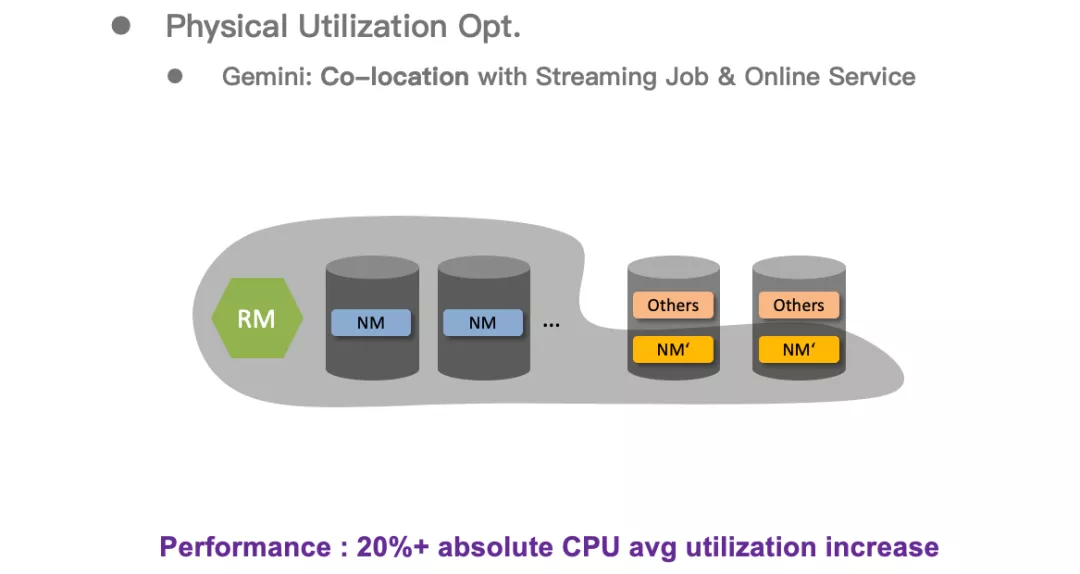
公司内离线的资源全天都比较紧张,而流式作业和在线服务的资源使用量随着用户的行为,在时间上有明显的波峰波谷,在凌晨时通过混部的方式将流式和在线富余的资源提供给离线可以全面的提升利用率。
我们通过将 NodeManager 改造为可以根据宿主机的富余资源动态的调整的 NM’,来达到与流式作业和在线服务的混部,为离线提供更多资源的目的。
目前生产环境中已有数万台节点进行了混部,混部后将原机器的 CPU 利用率绝对值提升了 20%以上。
2.1.5 Smart Resource : 在运行时/重启时调整资源
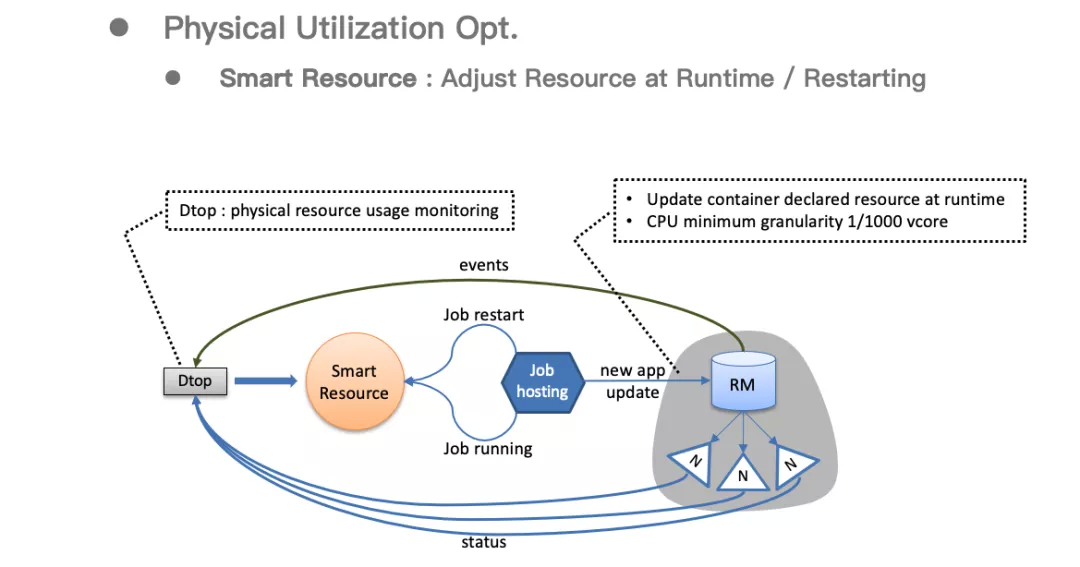
原生的 YARN 中,用户申请的资源和实际使用的资源经常会出现比较大的偏差, 导致出现大量的资源浪费的情况,为此我们开发了一整套的资源动态调整方案,可以将申请的资源调整到接近于实际使用资源的数值。
并且,在实际使用中发现,如果资源调整必须以一个核为最小粒度的话,还是会出现很严重的浪费,比如用户真实的需求可能是 0.001 个核*1000,原生的 YARN 只能分配 1000 个核,就白白浪费了 999 个核。我们开发了以千分之一核为最小粒度的功能,可以有效的减少资源的浪费。并且千分之一核与资源动态调整结合,可以更加精细化的调整资源。
2.2 多种负载场景优化
字节跳动的 YARN 承载了公司内的 批处理 / 流式 / 模型训练 三大场景,由于 YARN 天生是为批处理而设计的,很多地方与流式 / 模型训练场景并不匹配,为了给这些场景更好的体验,需要做一些定制工作。
2.2.1 YARN Gang Scheduler 调度器

流式作业和训练作业的调度需求与批处理有很大的不同:批处理强调的是高吞吐,而流式/训练类型的作业更加强调低延迟和全局视角。为了弥补原生 YARN 在低延迟和全局视角上的缺陷,我们开发了一个全新的调度器 Gang Scheduler。
Gang Scheduler 提供了一个 All-or-Nothing (一次全交付或不交付)的语义,如作业申请 1000 个 container,那么要么直接返回 1000 个 container,要么就返回失败,并提示失败的原因。这样可以有效的避免两个作业都只拿到一半的资源,谁也无法启动的互锁局面。
除此之外,Gang Scheduler 还有个特性是超低延迟, 它可以在毫秒级给出 All-or-Nothing 的结论,这样可以大大缓解流式作业在重启时的 lag 积压问题。
最重要的是,Gang Scheduler 为流式作业和训练作业提供了全局视角,每个作业可以通过配置自己定制的强约束和弱约束来达到全局最优的放置策略。其中,强约束是指必须要满足的条件;弱约束是指尽量满足,但确实无法满足时可以接受降级的约束。目前支持的强约束包括节点属性, 高负载等;支持的弱约束包括:节点属性,高负载,Container 打散,Quota 平均,GPU 亲和性等。
2.2.2 更加精细化的 CPU 使用策略

除了开启 YANR 原生默认支持的 CGroup 限制之外,我们还配置了更加丰富的 CGroup 管理策略,比如在 share 模式下支持自定义的最大值限制,支持绑核,支持绑 NUMA 节点等. 通过这些措施,给流式作业和训练作业更加灵活的管控策略,满足不同场景下的隔离或共享需求。
2.2.3 训练场景下的其它定制

对于训练场景,我们还定制了更丰富的内容。包括:
为了更好的隔离性,定制了支持 GPU 和 Ceph 的 Docker
为了更灵活的资源申请,定制了带范围的资源值 (传统的 YARN 资源只有个数, 没有范围,比如多少个 CPU,多少 GB 内存,但在训练场景下,有时希望有范围,比如当需要两个 GPU 卡时,不止希望随意的两张卡,而是希望要一台机器上两个连号的 GPU 卡,比如卡 0 和卡 1 是连号的,而卡 0 和卡 2 不是连号的。这个场景同样也适用于端口号。)
为了更高效的同时使用 CPU 和 GPU 机器,定制了节点属性功能。
2.2.4 跳过高 Load 节点
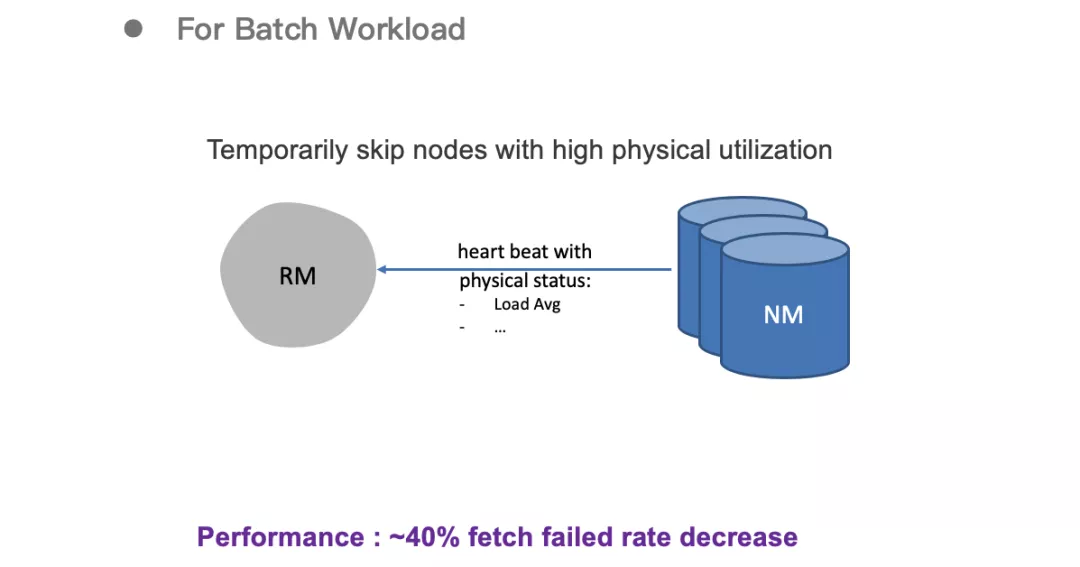
离线批处理场景经常会遇到"Fetch Failed"的问题,主要来源是本地的磁盘 IOPS 不足,导致 Shuffle Service 卡住,为了缓解这个问题,我们在资源调度的过程中加入目标主机 LoadAvg 的考虑因素,如果一台机器的 LoadAvg 过高,则暂时跳过对其分配新任务. 通过这个机制,将"Fetch Failed"问题降低了约 40%。
2.3 稳定性优化

字节跳动的 YARN 服务规模巨大,在稳定性方面遇到了很多挑战,有很多细节方面的优化, 在这里由于时间有限,挑选几个比较有代表性的优化点跟大家分享一下:
将 HDFS 做成弱依赖
对于一般的离线批处理来说,如果 HDFS 服务不可用了,那么 YARN 也没必要继续运行了。但是在字节跳动内部由于 YARN 还同时承载流式作业和模型训练,因此不能容忍 HDFS 故障影响到 YARN。为此,我们通过将 NodeLabel 存储到 ZK 中,将 Container Log 在 HDFS 的目录初始化和上传都改为异步的方式,摆脱了对 HDFS 的强依赖。
Container 分级与驱逐
某些 Container 的磁盘空间占用过高,或者将单机 Load 打得非常高,会比较严重的影响到其它 Container 的正常运行,为此,我们为 YARN 定制了 Container 分级与驱逐机制。对于可能会严重影响到其它 Container 的 Container 会进行主动驱逐。对于被驱逐的作业,可申请到独立的 Label 中运行。
非受控 Container 的清理机制
由于种种原因,线上总是会出现一些 Container 明明还在运行,但是已经不受 YARN 的管控。通常是由于不正常的运维操作产生,或者机器本身出现故障导致。对于这些 Container 如果不加管制,不仅会让单机的实际资源紧张,有时还会造成 Kafka Topic 的重复消费导致线上事故。为此我们在 YARN 的 NodeManager 中增加了非受控 Container 的清理机制。
2.4 异地多活
随着公司发展迅猛,YARN 也迎来了异地多机房的场景,原生的 YARN 只支持单集群使用,对用户的使用造成不便,如果每个集群都孤立的提供给用户的话,会让用户使用起来很困难,为此,我们对异地多活做了一些定制工作:
全球统一的 YARN UI 界面
为所有的 YARN 用户统一定制了一个 YARN UI 界面,该界面包含全球的所有队列和用户的作业。
放弃数据本地性调度延迟等待
当有多个集群时,很难与 HDFS 的数据进行本地性对齐。
机房内网络资源富余,数据本地性对性能提升不明显,还会导致集群吞吐下降。
YARN 安全模式
为了配合多机房容灾,有时需要主动将部分 YARN 集群设置为不调度新任务的安全模式。
3. 未来工作

未来我们会持续的优化与流式和在线服务的混部工作,包括:
物理利用率提升
更好的隔离
更加可控的杀死率
GPU 资源的混部
同时,我们也会继续完善 YARN Gang Scheduler,包括:
更加丰富的调度谓词
更加低延迟
4. 团队介绍
基础架构 YARN 团队负责字节跳动公司内部离线/流式/模型训练三大场景的资源管理和调度, 支撑了推荐/数仓/搜索/广告等众多核心业务,管理着在集群规模、调度吞吐能力、资源利用率、业务复杂性等多个方向上都在业界领先的超大规模集群。
针对公司内的抖音、今日头条等产品重度依赖推荐的特点, 团队对调度器进行了深度定制以支持流式(Flink)训练和 GPU 训练等场景, 拥有几十项专利技术。同时为了进一步提升集群资源利用率,调度团队已经开启在离线大规模混部,并且预期在不久后会进一步融合 YARN / K8S 等调度系统。
本文转载自公众号字节跳动技术团队(ID:toutiaotechblog)。
原文链接:
https://mp.weixin.qq.com/s/9A0z0S9IthG6j8pZe6gCnw

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论