

论文导读: 这篇综述论文解读了 2006 大数据系统兴起以来代表性应用和开源基准测试集。近年来,随着大数据系统的快速发展,各式各样的开源基准测试集被开发出来,以评测和分析大数据系统并促进其技术改进。然而,迄今为止,还没有就这些基准测试集进行系统调研。因此,本文对当前最前沿的开源大数据基准测试集进行全面总结,阐述其历史、现状并展望下一步研究方向。首先,我们从大数据系统的角度对大数据基准测试集进行了定义和分类。随后,我们回顾了基准测试技术的三个重要方面——工作负载生成技术、输入数据生成技术和系统评估指标。最后,论文从这三个方面对现有基准测试集进行归类,并重点描述其中具有代表性的测试集,进而讨论未来研究方向,以推动该领域工作的持续发展。
大数据开源基准测试集
1. 大数据系统及开源基准测试简介
大数据系统通常被分为三个阵营,如图 1 所示:
(1)Hadoop 相关系统;
(2)数据库管理系统(DBMSs)和 NoSQL 数据库;
(3)针对图数据、流数据和复杂科学数据的特殊处理需要的专用系统。
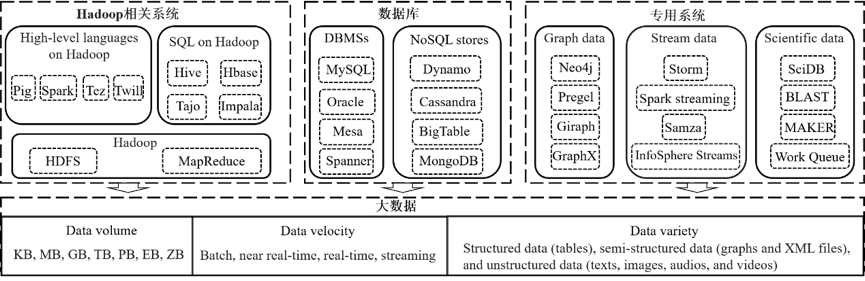
图 1. 大数据系统分类与总述
总结归纳了当前流行的开源基准测试集,图 2 显示了这些基准测试集的词云图,其中词的大小和流行度成比例。

图 2. 开源大数据基准的词云云
2. 大数据基准测试分类及发展历史
大数据基准测试集的类别:
(1)微基准测试集。这类基准测试集被用于评估单个系统组件或特定系统行为(或代码的功能);
(2)端到端基准测试集。这类基准测试集的目的是使用典型应用场景评估整个系统,每个场景都对应一个工作负载的集合。
(3)基准测试集套件是不同的微基准测试集或端到端基准测试集的组合,这些套件的目标是提供全面的基准测试解决方案。
发展历史:大数据基准测试是一个活跃的研究领域,许多基准测试集在最初发布之后仍在发展,图 3 显示了它们的初始发布年份。
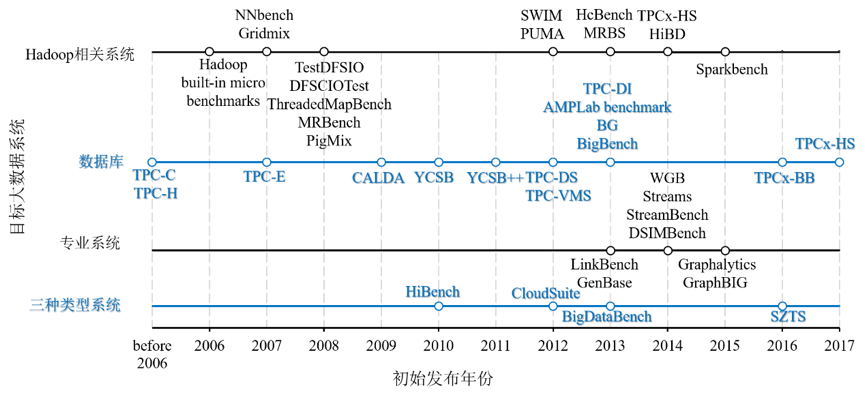
图 3. 大数据基准测试集发布时间轴
3. 工作负载生成技术
工作负载实现技术:我们将大数据工作负载划分为三类:
(1)I / O 操作。这些操作在输入数据或文件上执行(例如,读、写、移动数据或新建、删除文件)。
(2)算法操作。当作为一种算法实现时,一个工作负载由一个或多个对输入数据的独立操作组成。
(3)基本操作(EO)。这些操作要么是标准的 SQL 操作符[102],要么是具有类似语法的操作符(如 Pig Latin)。图 4 显示了代表性负载和操作的词云图。

图 4. 代表性大数据工作负载的词云图
工作负载提交技术:我们将本文回顾的基准测试集的提交策略分成三类:
(1)预先指定。在许多基准测试集中,工作负载的输入数据、提交速率和顺序都是在执行前指定的。
(2)参数控制。这类基准测试集允许用户使用参数控制工作负载的执行。
(3)真实日志驱动。通过使用这种提交策略,基准测试集可以根据真实世界的日志来真实地复现工作负载。
开放性挑战:已有的大数据基准并不能完全符合以上三个准则:(1)相关性。鉴别被测系统的典型行为是实现高度相关性负载的先决条件。(2)可移植性。我们首先从软件系统(即软件栈)的角度讨论这个准则。(3)伸缩性。为了评估不同规模的系统,基准测试集应该能够调整工作负载的规模,同时保证其提交和混合的真实性。
4. 输入数据生成技术
大数据基准测试中的数据生成器:
(1)现有数据集:许多大基准测试提供固定大小的数据集作为其工作负载的输入;
(2)基于合成分布的数据生成器;
(3)基于真实数据的数据生成器;
(4)混合数据生成器。
开放性挑战:考虑大数据的数据量和速度,以及不同的数据类型和来源(数据种类),此处有两个具有挑战性的关键问题:第一个问题是现有的基准测试集可以构建模型来提取某些数据类型(如表格,文本和图数据)的真实数据集的特征,但是很少关注其他数据类型,如流、图、视频和科学数据。第二个同时也是更具挑战性的问题是如何评估产生的合成数据的真实性水平。
5. 评估中的指标和性能参数
评估中的指标和性能参数:
(1)通用性能指标包括响应时间、吞吐量、可靠性、可用性;
(2)体系结构指标包括执行周期划分、处理器计算强度;
(3)价格和能耗指标包括性价比指标、能耗指标。
大数据系统性能参数:
(1)系统配置参数。大数据系统中大量软件栈和多种编程语言的使用会带来大量的配置参数。
(2)资源分配参数。当数据中心中部署大数据系统时,计算和网络资源由不同系统的工作负载共享。
论文原文:2018 年发表于服务计算领域顶级期刊 TSC: (http://ieeexplore.ieee.org/document/7990174/),图5显示了英文原文导读图。
中文技术报告:https://mp.weixin.qq.com/s/qW2UPheanJcda_lfuTXyMw
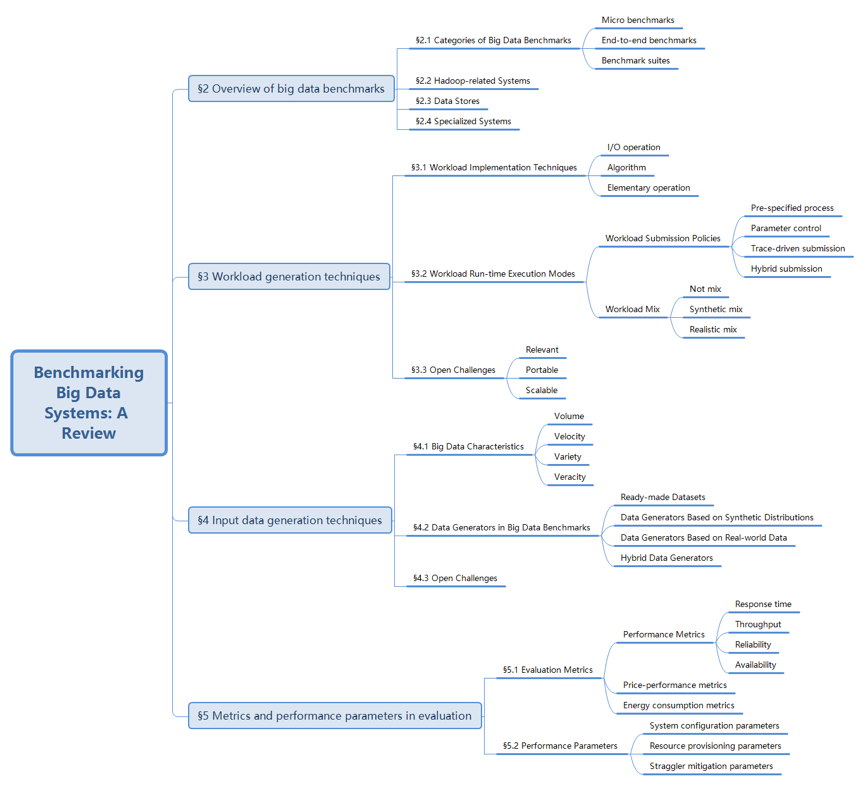
图 5. TSC 英文原文导读图

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论 1 条评论