

Amazon Aurora 作为 AWS 增长最快的服务,已经在中国宁夏区域可用。越来越多的客户选择 Aurora 作为核心关系型数据库,处理核心数据业务。除了 Aurora 之外, AWS 还提供了 RDS Mysql 等数据库引擎,供客户选择。另外,AWS 还有 Amazon Redshift 数据仓库产品,作为海量大数据分析使用。
那么,如何选择合适的产品,来满足自己的业务需求呢?接下来我们会从技术和成本方面,详细分析 Aurora/Mysql/Redshift 这三款产品。
性能
Aurora 日志即数据库+计算存储分离的设计理念,使得 Aurora 拥有相比传统数据库更高的性能表现。
以下是 AWS 数据库专家使用 Sysbench 工具对 Aurora 和 Mysql 5.6 分别进行压力测试的结果。实例类型 r4.8xlarge(32 vCPU, 244GB 内存)。
https://aws.amazon.com/cn/blogs/china/aurora-test/
只读负载
读/写混合负载
可以明显看到 Aurora 相比 Mysql,无论在 QPS/TPS,还是在响应时间上,都有巨大的优势。从并发连接数来看,随着并发数的增加,这个优势会更加明显。当 Mysql 并发数大于 1000 时,由于资源争用,QPS/TPS 急剧下降。而 Aurora 虽然略有下降,但是仍然能保持相对平稳的水平。当并发数到达 6000 时,Aurora 659K vs Mysql 8.9K,QPS 的差距就更大了。
并发量巨大时,Mysql 已经支撑不住业务压力,再如何加机器,或者提升机型,都效果不好。此时通常的做法,是分库分表。此方式能暂时减缓压力,但是引入了更复杂的中间件,加大了管理难度。Aurora 在高并发时的优异表现,完全能承载压力,而无需分库分表。
典型的场景,适用于金融、电信等大量在线交易。客户包括 Dow Jones、Capital One、Verizon、NTT DOCOMO、Netflix 等等。
这只是普通的测试。现在 Aurora Mysql 5.6 加入了并行查询的支持,利用底层存储节点的计算能力,进行并行计算,大幅提升查询速度。参考:
https://aws.amazon.com/blogs/aws/new-parallel-query-for-amazon-aurora/
Aurora 的优势,在大并发的场景下表现得淋漓尽致。那么,是否所有场景都适合 Aurora 呢?
在频繁更新的业务场景下,如果 Innodb 表添加了二级索引,并且禁用了 change buffer,那么由于没有索引写缓存,直接写入磁盘会极大影响性能。Aurora 和 Mysql 都会受到此影响。在此场景下,Aurora 对于 Mysql,优势不再明显。
请记住:Aurora 也是 SQL 关系型数据库,传统数据库的优化机制,包括索引、缓存、SQL 等,仍然适用。良好的表设计和 SQL 优化,仍然是 DBA 需要考虑的问题。
在单个读写的请求表现上,Aurora 并不对 Mysql 有优势。在没有压力的情况下,一个简单的 SELECT 查询,Aurora 和 Mysql,响应时间可能很接近。
以下是在一张千万行的表上,Aurora 和 Mysql 的查询响应时间对比。
Aurora:
mysql> mysql> select count(*) from user_test where create_time between ‘2013-01-01 00:00:00’ and ‘2015-01-01 00:00:00’ and age =31;
+———-+
| count(*) |
+———-+
| 60633 |
+———-+
1 row in set (2.80 sec)
Mysql:
mysql> select count(*) from user_test where create_time between ‘2013-01-01 00:00:00’ and ‘201500:00:00’ and age =31;
+———-+
| count(*) |
+———-+
| 60633 |
+———-+
1 row in set (2.51 sec)
可以看到,响应时间上,Aurora 2.80 秒,Mysql 2.51 秒,Aurora 甚至还要低于 Mysql。
Aurora 优化的是底层架构,而数据库层面,仍然兼容传统的 Mysql 或 PostgreSQL。如果并发量不大,Aurora 的优势没有发挥出来,和 Mysql 的性能表现可能差不多。但是,随着并发量增加,Aurora 的性能会超过 Mysql。
我们在选择数据库时,通常会进行测试对比。测试时,一定要保证两边的环境一致,包括节点数量,类型,数据库参数等等。如果只是简单跑几个查询,可能出现的情况是,本地物理机上自己搭建的 Mysql,比 Aurora 要快。因为本地是单机,SSD 磁盘,不需要经过网络通信。数据库没有压力的时候,处理速度更快。
压力测试一定要并发足够大,大到把 CPU 利用率打满,并且持续一段时间。没有压力的测试是不准确的。可能的话,尽量可以用接近生产环境的测试数据和语句,更加模拟真实场景的压力。
数据库参数也会对测试结果影响很大。例如,Aurora 启用了 binlog,并且设置了 innodb_flush_log_at_trx_commit=1,也会影响性能。默认 Aurora 没有启用 binlog,只读副本可以访问和主节点一样的底层共享存储,不需要以 binlog 从主节点同步。Aurora binlog,适用于跨区域同步,或者与其他 Mysql 进行同步。
Redshift
如果需要对海量数据进行复杂的查询,这是属于 OLAP 的场景。例如,在 10TB 的数据中,按照某个产品的消费额,查询出某个时间段的 TOP 10 用户。普通的 OLTP 数据库擅长在线交易,如此海量的查询,难以胜任。即使勉强能查询,所花费的时间远超业务能承受的范围。对于海量数据的查询,可以考虑把数据通过 ETL 工具,抽取到专门的数据仓库,例如 Amazon Redshift,来进行查询,性能会有极大提高。Redshift 在设计表时,要遵循最佳实践,包括事实表和维度表选择、分配键、排序键、压缩等等。表设计的好坏与否,在性能表现上差别可达几倍甚至几十倍。
以下测试,在 Redshift 测试同样的表,同样的查询,响应时间是 62 ms,大幅低于 Aurora 和 Mysql 的 2 秒多。
dev=# select count(*) from user_test where create_time between ‘2013-01-01 00:00:00’ and ‘2015-01-01 00:00:00’ and age =31;
count
——-
60633
(1 row)
Time: 62.148 ms
这还只是简单的单表查询,数据量也不大,而且还没有做过优化。Redshift 更擅长的是,海量数据里的各种表,做复杂的联合查询。此时表现更加优异。
不过,Redshift 并不适合大并发的查询,或者写入。虽然支持 SQL insert, update 等语句,但是并不建议直接更新表。在插入数据时,需要从 S3 的 CSV 等格式化文件批量导入。
在很多业务场景中,例如广告、电商等,Mysql 数据库用于 OLTP 实时在线交易。还有分析系统,需要每隔一段时间从数据库中获取生产数据,导入数据仓库,让分析系统查询处理,得出报表并展现给用户。导入过程使用 ETL 工具,可以使用 Amazon Glue 服务,或者使用 Talend 等第三方工具,或者自己编写 spark 程序。在此场景中,无论使用何种 ETL 工具,都要尽量避免实时更新 Redshift 等数据仓库。Amazon Glue 在数据导入 Redshift 之前,先把数据写入临时的 S3,再批量 Copy 到 Redshift。其他工具也应该遵守此实践。
请记住,数据仓库不适合实时更新。
以下架构描述了数据 ETL 过程。日志和 RDS 数据库,通过 Glue ETL 导入到 Redshift,查询分析后进行展现。
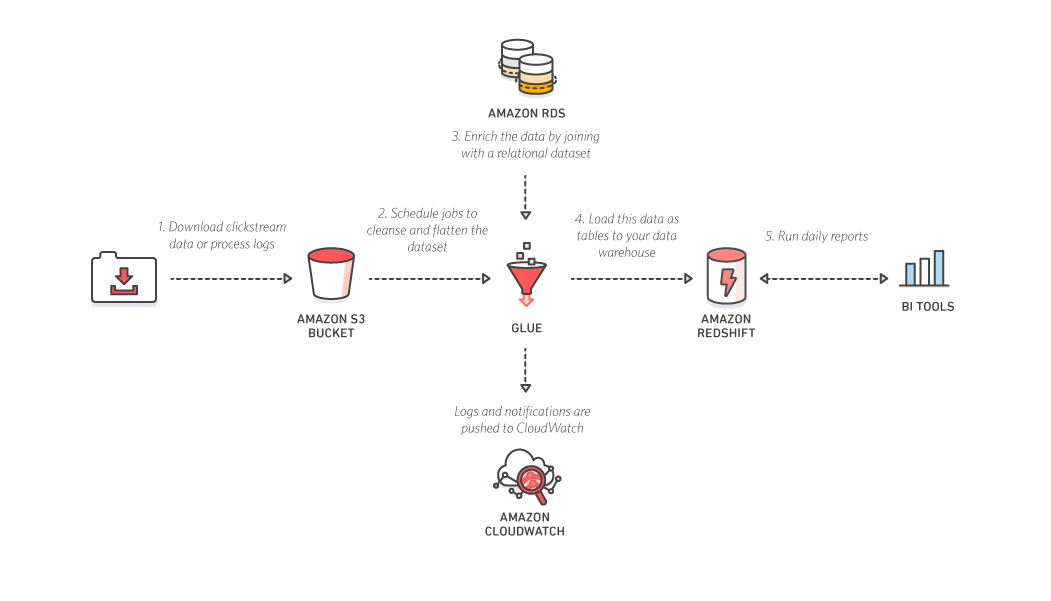
除了性能方面,还有很多方面需要考虑。数据库和 Redshift 数据仓库属于不同的场景,这里主要以 Aurora 和 Mysql 进行技术对比。
存储
Aurora 无需事先指定存储大小和 IOPS,根据实际数据量以每 10GB 自动扩展,存储最大容量可达 64TB。这省去了磁盘容量或者 IO 不足时,需要扩容而带来的影响。
Aurora 只支持 Innodb 存储引擎。如果需要用到 MyISAM,那么还是适合使用 RDS Mysql。
扩展性
Aurora 最多支持 15 个只读副本,相比 Mysql 5 个副本有很大提高。Aurora 的只读副本有 reader endpoint,能够对只读请求做负载均衡。对于应用程序来说,只需指定只读 endpoint,就无需再考虑只读副本的流量均衡与故障切换。而 Mysql 还没有提供只读副本的负载均衡功能,需要在应用程序和数据库之间,加入中间件,或者在应用程序加入逻辑,把请求尽量平均分配给数据库只读副本。否则,一旦 Mysql 只读副本出现故障,域名或者 IP 会变化,应用程序端还需要调整。
Aurora 还支持 Autoscaling 自动扩展,根据 CPU 使用率或连接数,超过指定阈值时,自动增加只读副本,以满足业务变化的需求。
可靠性
Aurora 写入时自动复制数据到 3 个 AZ 的 6 个副本,持续把日志和数据备份到更可靠的 S3,数据不会丢失。自动故障恢复,能在主节点出现故障时,自动提升只读副本为主节点,实现数据库高可用。
Aurora 还有快速恢复等功能,即使在数据库需要恢复时,也能更快启动数据库。
回溯功能更可以在短时间内恢复到之前的某个时间点,而无需重新恢复新的数据库,这需要更改应用程序指向新的数据库。
Aurora 和 Mysql 都支持跨区域副本复制。Aurora 还推出了 Global Database 功能,物理层面进行数据复制,相对与 Mysql binlog 同步,效率更高,跨区域主从延迟能达到 1 秒以内。
成本
Aurora 和 Mysql 的费用都包含流量和备份,这些价格相近。不同的地方在于数据库实例和存储费用。
以下是两者在美国东部地区的价格对比:
Aurora R4
RDS Mysql R4 Single-AZ
Aurora Storage and IO
Mysql Provisioned IOPS (SSD) Storage Multi-AZ
实例价格上,Aurora 大约是 RDS Mysql 的 1.2 倍(9.28/7.68=1.2)。看上去 Aurora 贵一些。考虑到 Aurora 相比 Mysql 的性能优势,同样的业务量场景下,即使 Aurora 相对 Mysql 只提升了 2 倍的性能,成本也会降低很多。例如,Mysql 需要 4 个 r4.xlarge 节点,Aurora 由于性能提升,只需要 2 个 r4.xlarge 即可满足业务需求,总成本上,Aurora 0.582=1.16,Mysql 0.484=1.92,Aurora 更便宜。
存储价格上,容量价格 Aurora 便宜一些(0.1 vs 0.125),而且 Aurora 按实际容量收费,对比 RDS 在创建实例时就要指定存储容量,价格会更便宜。Aurora 实际容量,可以在 Cloudwatch 监控的[Billed] Volume Bytes Used 指标查看。
IO 价格不好直接比较,Mysql Provision IOPS EBS (IO1) 按照预设容量收费,此费用固定。Aurora 按照 IO 总量计算,不同时段的 IO 请求不一样,费用也不同。可以监控 Cloudwatch [Billed] Volume Read IOPS 和 [Billed] Volume Write IOPS 这两个读写 IO 的指标,估算某个请求量的场景下,所花费的 IO。如果开启了 Aurora 并行查询,IO 费用会更高。
以下总结了 Aurora/Mysql/Redshift 的应用场景、特性和成本对比。
作者介绍:
章平
亚马逊 AWS 解决方案架构师。2014 年加入 AWS 技术支持团队,解决客户疑难杂症,熟悉各种用户场景。对于各类云计算产品和技术,特别是在数据库和大数据方面,拥有丰富的技术实践和行业解决方案经验。
本文转载自 AWS 技术博客
文章链接:
https://amazonaws-china.com/cn/blogs/china/aurora-mysql-redshift-application-scene-cost-analysis/


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论