

本文讲述了我们在首款产品上市之前就差点破产、最后幸存下来并从中汲取教训的故事。
2020 年 3 月,COVID-19 疫情全面爆发,我们的初创公司 Milkie Way 也遭受巨大打击,差点破产。因为我们在对 Firebase 和 Cloud Run 进行内部测试的期间,一不小心在几个小时里烧掉了 72000 美元(约 47 万人民币)。
2019 年 11 月,我们开始开发 https://announce.today服务,希望借此打造 MVP 产品的可用功能 V1 版本。作为初步尝试,我们的代码以简单的底层栈为依托,使用 JS、Python 代码并将产品部署在 Google App 引擎之上。
因为团队规模很小,所以我们的重点放在编写代码、设计 UI 以及准备产品身上。我们没在云管理上花多少心思,当时的目标很简单——能支撑起基本的开发流程(CI/CD)就行。
在这款 V1 Web 应用程序中,用户体验并不算流畅。但没关系,我们的诉求只是开发出一些可供用户体验的产品,同时也构建了更好的 Announce 版本。随着 COVID 疫情全面来袭,我们认为这正是做出改变的最佳时机,没准 Announce 会成为各国政府在全球范围内发布公告的理想选择。
当时用户还没有创建任何内容,但我们认为能在平台上提供一些既有数据可能更好。所以我们又建立了 Announce-AI 项目,旨在自动发布由 AI 创建的丰富内容。这里的丰富内容是指各类事件、地震等安全警告,以及本地用户可能关心的相关新闻。
技术细节
为了开发 Announce-AI,我们决定使用 Cloud Functions。由于我们抓取数据的周期还很短,所以 Cloud Functions 几乎是完美的选项。但在决定扩展规模之后,我们马上遇到了麻烦——Cloud Functions 的超时时间长达 9 分钟。
于是我们开始研究 Cloud Run,并发现它提供规模可观的免费资源使用层!必须承认,那时候我们对 Cloud Run 并不够了解,只是匆忙要求团队在 Cloud Fun 上部署“测试”Announce-AI 功能。我们当时想得很简单:尽快熟悉 Cloud Run,在探索中不断学习。
为了简单起见,我们在实验中只引入一个很小的站点,就使用了 Firebase 作为数据库(因为 Cloud Run 不提供任何存储功能)。站点规模真的很小,完全用不上 SQL Server 或者任何其他成熟的商业数据库。
我创建了名为 ANC-AI Dev 的新 GCP 项目,设置了 7 美元的云资源使用预算,并选择使用 Firebase Project on the Free(Spark)计划。我们当时觉得,最糟糕的结果应该无非就是超出每日 Firestore 的免费限额,对吧?
在稍稍调整了代码之后,我们开始部署流程,向其发出了几条手动请求,而后就留下它保持运行。
噩梦由此开始
测试当天一切顺利,我们又回到了 Announce 本体的开发当中。在第二天下班之后,我稍微睡了一会。醒来之后,我发现邮箱里有几封来自 Google Cloud 的提醒邮件,而且邮件之间的间隔只有几分钟。
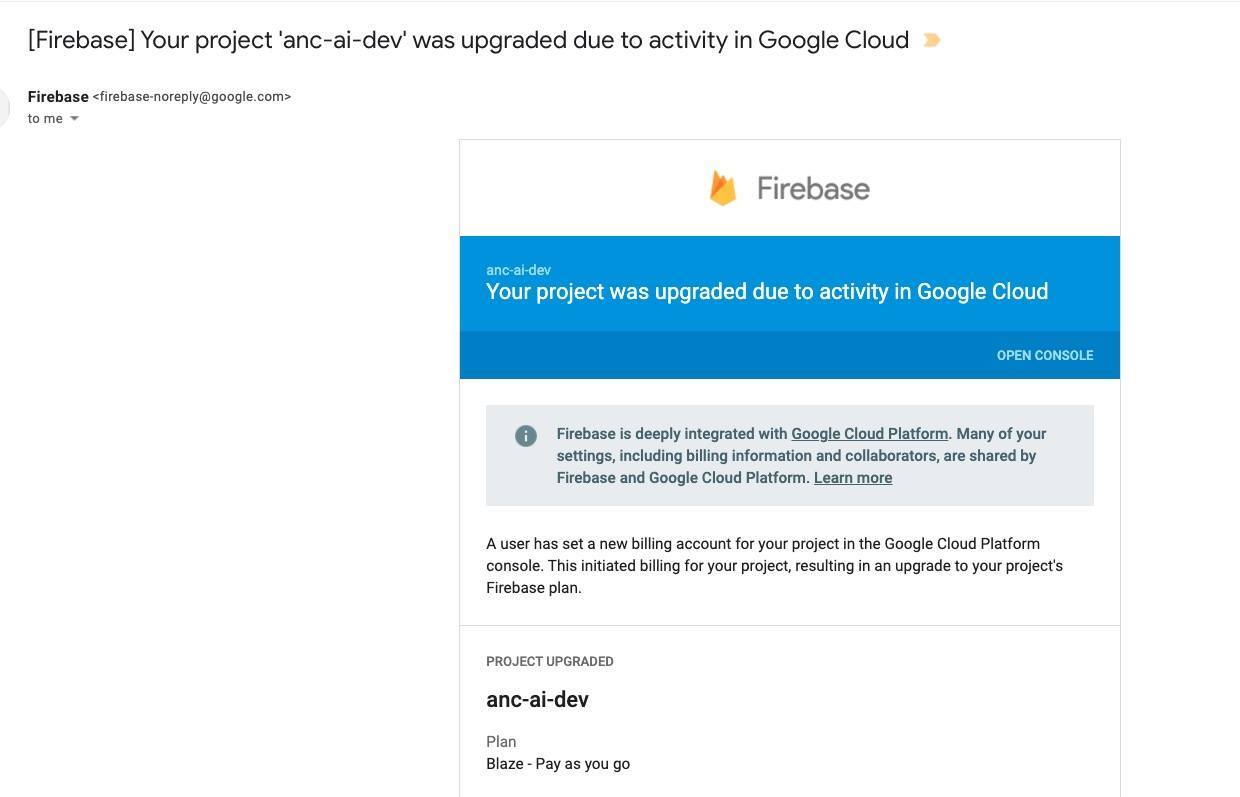
第一封邮件:Firebase Project 自动升级
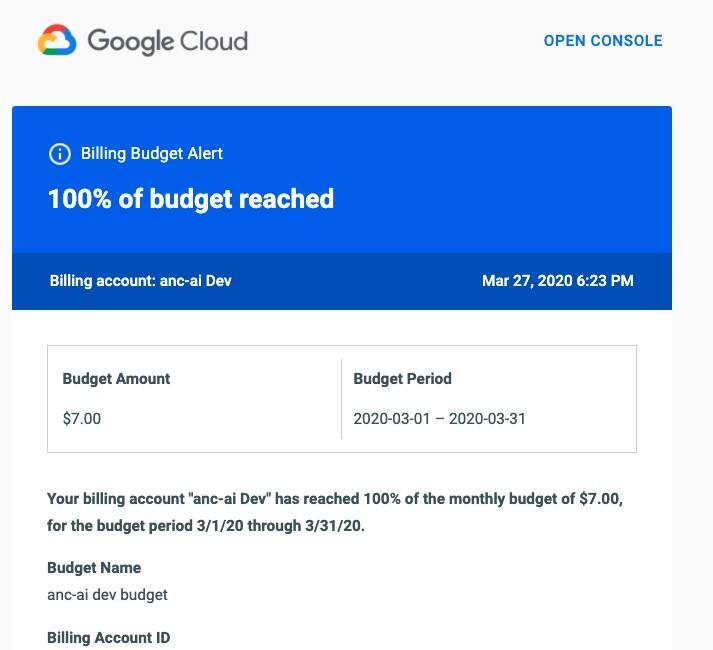
第二封邮件:预算超支
幸运的是,我使用的信用卡设有 100 美元消费限额。于是收费停止,谷歌暂停了我们的所有账户。
第三封邮件:信用卡支付被拒
我跳下床,登录 Google Cloud Billing,并看到一张约 5000 美元的账单。说实话,那一刻我慌得不行,根本没办法正常思考。我到处张望,想弄明白出了什么问题,包括到底该怎么付清这笔 5000 美元巨款。
但问题在于,账单金额每分钟都在上涨。
5 分钟之后,账单数额增长到了 15000 美元;20 分钟后,数额增长至 25000 美元。我不确定这一切什么时候会停,或者说恐怕永远不会停止?
2 个小时后,数额最终定格在 72000 美元。
这时我和我的团队正忙着疯狂确认情况。我彻底呆若木鸡,根本不知道接下来该做点什么。我们停用了结算功能,同时关闭了所有服务。
由于我们在全部 GCP 项目中使用的都是同一张对公支付卡,所以谷歌已经全面关停了我们的账户及项目。
噩梦仍在继续
事情发生在 3 月 27 日星期五晚上,即我们计划发布 Announce V1 的三天之前。由于谷歌冻结了绑定同一张信用卡的全部项目,我们的产品开发工作陷入了僵局。士气低落,这家年轻的公司前途未卜。
所有云项目都被关停,开发工作陷入僵局
到这天午夜,我终于缓过神来,开始展开调查。我把调查工作中的每个步骤都详细记录在了文件当中……并将文件命名为“第 11 章”。
另外两位团队成员也加入了调查工作,与我一同不眠不休地探索真相。
第二天,也就是 3 月 28 日星期六,我打电话或发邮件给了十几家律师事务所预约面谈。大多数律所拒绝受理,只有一封邮件发来回复,让我具体解释解释整个过程。必须承认,这件事即使对工程师来说也是细节过多、复杂难懂,我压根不知道该怎么用简单易懂的语言向律师做出说明。
作为一家自负盈亏的公司,我们拿不出 72000 美元。
到这时,我甚至认真研究过了《破产法》的第 7 章与第 11 章,并对接下来可能发生的一切做好了心理准备。
喘息之机:GCP 的漏洞
就在同一个周六,我开始查阅更多内容,特别是 GCP 说明文档中的各种条目。好吧,我们确实犯了错误,但谷歌在一笔实际支付都没完成的情况下就给我们计上了 72000 美元的账,这正常吗?!

GCP 与 Firebase
1. 自动将 Firebase 账户升级为付费账户
在注册 Firebase 时,我们从没想过这还带自动升级的,提示条款中也绝对没有提及。我们的 GCP 项目确实接受了结算条款,因为只有这样才能正常使用 Cloud Run;但 Firebase 不是,我们用的可是免费计划。GCP 突然就进行了升级,并向我们收取巨额费用。
事实证明,他们就是这么设计的,理由是“Firebase 与 GCP 深度集成。”
2. 所谓的计费“限额”根本不存在,预算管理至少延迟了一天
GCP Billing 实际至少了延迟了一天。谷歌在大多数说明文档中都建议用户使用 Budgets 与自动关闭云功能。但你猜怎么着?在中断功能被触发或者通知到云用户时,问题可能已经发生了。
结算过程大约需要一整天时间,所以我们第二天才收到计费提醒。
3. 谷歌应该向我们收取 100 美元,而不是 72000 美元!
由于我们的账户一直没有实际支付,所以 GCP 应该先根据账单信息收取 100 美元的费用,并在无法继续付款后停止服务。但实际情况并非如此,后来我弄清了原因,问题仍然跟用户这方无关。
我们账户的第一笔费用约为 5000 美元,下一笔就暴涨到了 72000 美元。

我们账户的计费上限为 100 美元
4. 别相信 Firebase 仪表板!
不只是 Billing 功能,就连 Firebase 仪表板也要超过 24 个小时才能正常更新。
根据 Firebase 控制台说明文档,Firebase 控制台的仪表板数字可能与 Billing 账单报告“略有不同”。
以我们的情况为例,二者的差异高达 86585365.85%,也就是 86 万倍。而且在向我们发出账单之后,Firebase 控制台的仪表板仍然显示当月出现了 42000 次读取+写入操作(低于每日上限)。
新的一天,新的挑战
我之前曾在谷歌工作过大约六年半,也写过几十份项目说明文档、取证报告。结合过往工作经验,我整理出一份文件,向谷歌概述了这次事件,并总结了谷歌方面的错误和疏漏。照理来说,两天后的周一,谷歌工作小组就会正常上班并接手处理。
增订:部分读者朋友建议我直接跟之前的谷歌同事联系。事实上,我没有动用任何原有的人脉,使用的就是普通开发商/公司采取的常规办法。于是乎,我在聊天频道、咨询、冗余的电子邮件和一个个小错误身上浪费了无数时间。下面,咱们具体来看交涉过程中的种种细节。

离开谷歌的那一天
与此同时,我们也在整理自己这边犯下的错误,并制定新的产品开发策略。团队里还有不少人根本不清楚发生了什么,只知道公司遇上了大麻烦。
作为前谷歌员工,我有丰富的“犯错”经验,还给谷歌造成了数百万美元的损失。但谷歌的企业文化拯救了员工(当然,涉事工程师还是得写一份长长的事件回顾报告)。这一次,我不再是谷歌人,我们手头的资金有限、而之前投入巨大心力的成果正身陷风险。
先来看一个数字:1160 亿,这是我们的测试代码在一个小时之内读取 Firestore 数据库的次数。
这是我人生中第一次遭遇如此重挫,有可能彻底改变整个公司乃至我生活的未来方向。关于问题,我们可以说很多,但其中最重要的反而是个简单的道理——保持坚强。
作为一家小公司的管理者,我手底下只有一支由 7 名工程师/实习生组成的团队。谷歌那边大概得 10 天左右才能与我们进一步接洽。在此期间,我们必须恢复开发,找到解决账户关停的方法。此外,产品及功能的设计工作也得尽快重启。
我们到底做了什么?
因为团队规模不大,我们希望尽可能使用无服务器架构。而 Cloud Functions 与 Cloud Run 等无服务器解决方案处理问题的基本思路,就是超时。
具体来讲,实例会持续将 URL 抓取到网页当中;但在 9 分钟后,该实例就会超时。
可能是失败激发了脑中的智慧,我在几分钟内就在白板上列出了一大堆设计问题。不知道为什么,在部署之前,我们能想到的就只有快速犯错、快速尝试。

Announce-AI 在 Cloud Run 上的“Hello World”版本
为了克服超时限制,我建议使用 POST 请求(将 URL 作为数据)将作业发送至某一实例,且并发使用多个实例以替代串行使用单一实例。这样 Cloud Run 中的每个实例只会抓取一个页面,所以永远不会超时。另外,由于 Cloud Run 的处理操作能够精确到毫秒,所以全部页面都将得到并发处理,整体性能得以高度优化。
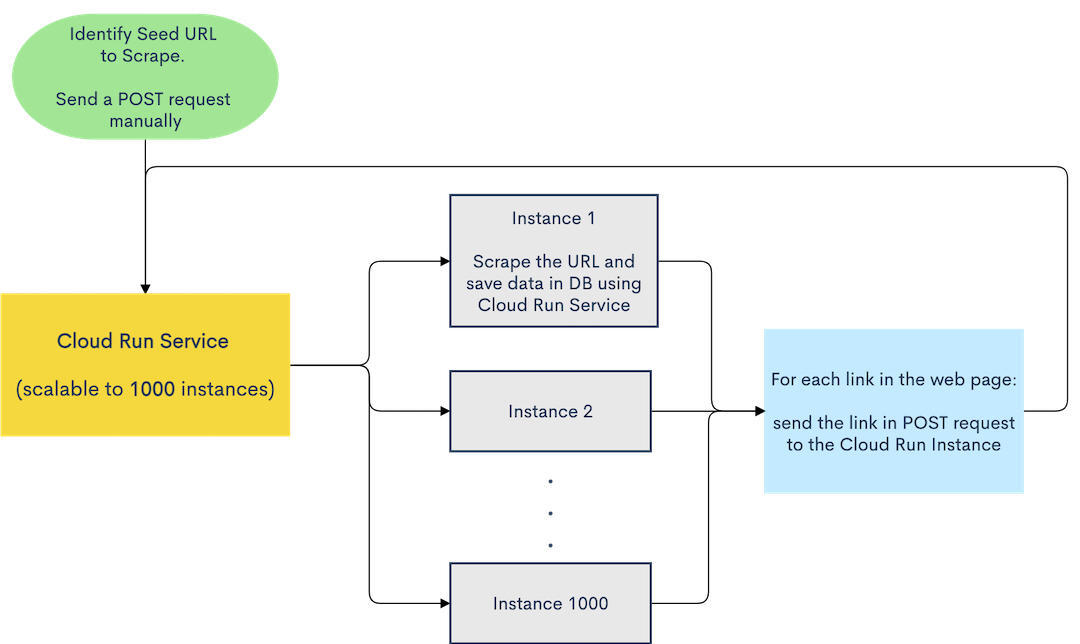
部署在 Cloud Run 上的抓取器
如果仔细观察,就会发现流程中缺失了一些重要的部分:
不中断的指数递归:由于没有 break 语句,因此实例不知道该何时中断。
POST 请求可以具有相同的 URL。如果存在指向上一页的反射链接,则 Cloud Run 服务将陷入无限递归当中;而最糟糕的是,这个递归将呈指数增长(我们将最大实例数设置为 1000!)。
大家可以想象,这意味着多达 1000 个实例会不断查询,且每几毫秒就向 Firebase 数据库写入一次。查看数据发布事件,我们发现 Firebase 在某一时间点上的每分钟请求数量增长到了 10 亿个!
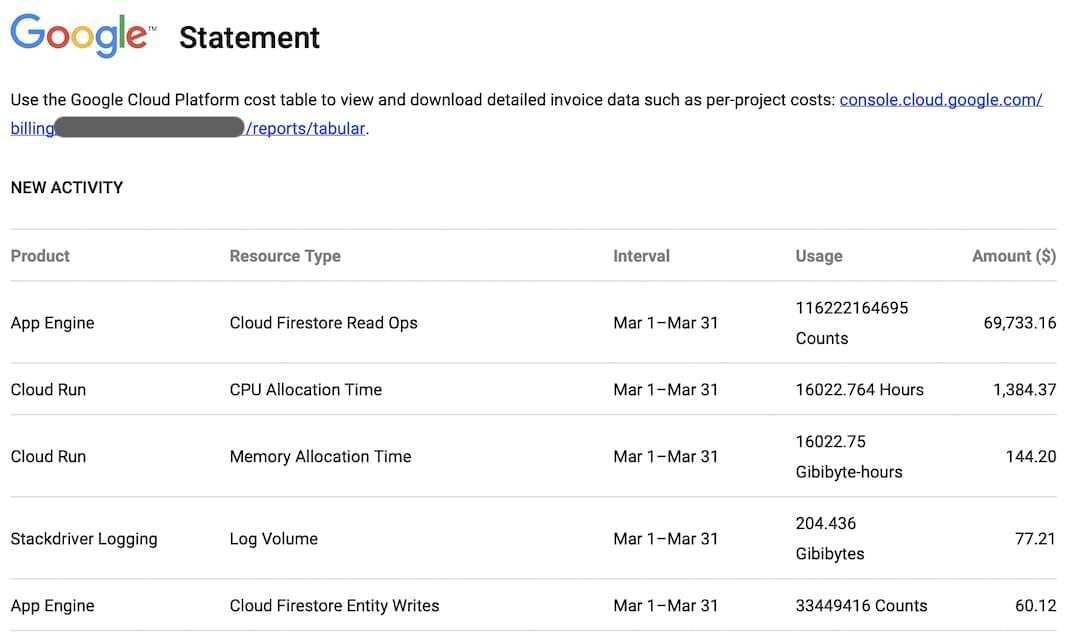
GCP Billing Account 的月末交易摘要
1160 亿次读取,3300 万次写入
总体来看,我们这套部署在 Cloud Run 的“Hello World”版本共执行了 1160 亿次读取与 3300 万次写入……我的妈呀!
Firebase 上的读取操作成本:
(0.06 美元 / 100,000) * 116,000,000,000 = 69,600 美元
1600 个 Cloud Run 计算时
经过测试,我们假设该请求因日志记录的停止而终止,但实际上它只是转入后台进程。由于我们没有删除服务(我们这是第一次用 Cloud Run,还不太了解具体细则),因此继续有多个服务缓慢运行。
在 24 个小时之内,这些服务版本各自扩展到了 1000 个实例,共消耗掉 16022 个计算时。
我们犯了什么错误?
在云上部署了存在缺陷的算法
根据之前的讨论,我们确实发现了一种通过 POST 请求使用无服务器资源的新方法。这确实是种独创性的方法,在互联网上并没有现成的参考,遗憾的是其中存在着我们当初没有意识到的大问题。
使用默认选项部署 Cloud Run
在创建 Cloud Run 服务时,我们在服务中选择使用默认值,即 max-instances 被设置为 1000,concurrency 设置为 80。一开始我们并不知道,这些预设值对我们的测试程序来说可以算是最不适用的组合。
如果我们把 max-instances 设定为 2,那我们的成本只会是现在的五百分之一,即由 72000 美元转变为 144 美元。
如果我们将 concurrency 设定为 1,那么基本不会产生任何费用。
在不完全了解的情况下使用 Firebase
有些经验必须从实践当中获取。Firebase 不像是能够直接学习的编程语言,它是谷歌提供的一项容器化平台服务,其中使用的是大量预定义规则,而且规则内容跟用户的直觉或者倾向没有任何关系。

另外,在 Node.js 中编写代码时,必须注意后台进程。如果代码进入后台进程,则开发者很难意识到该服务仍在运行、而且在很长一段时间内持续运行。后来我们发现,这正是我们大多数云功能同样出现超时的原因所在。
别在云上搞“快速失败、快速学习”
云平台像是一把双刃剑。如果使用得当,它确实威力巨大;但如果使用不当,后果也将极为严重。
翻翻 GCP 说明文档,大家就会发现它的页数比几本小说加起来还多。换言之,了解云定价及使用方式不仅非常耗时,而且要求相关人员充分了解云服务的工作原理。所以,别以为在传统头衔前面加个“云”是骗人的——这真是项技术活!
Firebase 与 Cloud Run 真的很强大
在峰值时期,Firebase 每分钟能够处理约 10 亿次读取,这真是太强大了。我们已经在 Firebase 上测试了 2 到 3 个月,目前仍在继续学习,但完全没有触及到它的极限。
Cloud Run 也是如此!当 Concurrency == 60, max_containers == 1000 且每条 Request 用时 400 毫秒时,Cloud Run 每分钟能够处理 900 万条请求!
60 * 1000 * 2.5 * 60 = 9,000,000 请求/分钟
相比之下,谷歌搜索每分钟也只能完成 380 万次搜索。
使用 Cloud Monitoring
虽然Google Cloud Monitoring 不会停止计费,但它能及时发送警报(延迟仅为 3 到 4 分钟)。Google Cloud 的原型/命名结构有一定学习曲线,但在投入时间和精力之后,仪表板、警报与指标确实能让我们更为轻松。
这些指标将保留 90 天。遗憾的是,我们在此次事件中的指标已经过期了,否则我很乐意在本文中向大家展示。
好消息:我们没倒闭!

但很悬,太悬了
在认真阅读了关于此次事件的报告之后,经过一系列咨询、讨论与内部研究,谷歌直接免除了我们的账单!
谢谢你,谷歌!
我们又恢复了活力,能够继续开发 Announce。而且这一次,我们拥有更好的视角、更强的架构与更安全的实现思路。
谷歌是我最欣赏的科技企业,这不只是因为它是一家值得为之工作的伟大公司,同时也因为它有着很强的同理心。谷歌提供的工具很合开发者的胃口,很重视说明文档质量(大多数情况下),而且一直在不断发展。(作者注:这只是我作为独立软件开发者的个人感受,绝非软文或者刻意吹捧。)
接下来怎么办?
经历了这次事件,我们花了几个月时间学习云架构和我们自己的业务体系。几周之后,我们的知识提升到新的境界,于是开始使用经过改进的算法通过 Cloud Run 抓取“整个网络”。
而在事后的整体分析中,我们决定放弃 V1 版本架构,转而使用更具可扩展性的基础设施为产品提供支持。
在 Announce V2 中,我们不再构建 MVP;相反,我们打造出一套平台,借此快速迭代新产品,并在安全环境中进行全面测试。
这段经历确实拖慢了我们的脚步……V2 在 11 月底才正式亮相,比原计划的 V1 发布日晚了大约 7 个月。但 V2 可扩展性更强,能够更充分地动用云资源,同时也拥有更好的优化水平。
我们还得以将其推向所有平台,而不仅仅是 Web 平台。
更重要的是,我们利用同一套平台构建起第二款产品Point Address。这两种产品不仅可扩展性极佳、拥有出色的架构与高效性,还建立在同一套平台之上。这使我们得以快速将业务灵感转化为现实,并立即将其引入实际产品当中。
原文链接:

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 4 条评论