

我的个人网站是用 Hugo 静态网站生成器创建的。Hugo 非常了不起,但它的文档却并非如此。本文是我的个人观点,解释了为什么我觉得 Hugo 现有的文档如此令人失望,以及这些文档应该如何改进。
Hugo 确实拥有大量有用的文档,我为此很开心。首先,我要声明的是,Hugo 是一项开源项目,我们应该感谢这些文档的存在,用户应当为提高这些文档的质量作出贡献。本文是一种善意的批评,旨在能够提高现有文档的质量。另外,也许大部分的 Hugo 用户比我更博学或更有耐心,所以他们没有遇到我描述的问题。
网络开发并不是我的强项。我偶尔把它作为一种业余爱好,比如创建像网站。过去,我曾自行托管和使用 Joomla、Drupal、WordPress、Octopress、Pelican 和 Grav,但从来没有什么特别花哨的东西,我也不是一个专家。
说完这些,让我们深入了解下存在问题的两个模式。
有问题的模式
模式 1:第一次从头到尾阅读 Hugo 文档,很少能真正帮我理解某个概念或得到特定的答案。
大多数的时候,一旦我开始阅读某些东西,就有必要连续阅读,去了解一个不同但相关的概念。比如,当我开始阅读 A 页,勉强读完一段后,有必要翻到 B 页。一旦进入 B 页,几乎需要立即跳到 C 页,以此类推。很快,我就到了 Q 页。我需要把 A 到 P 页所有阅读过的部分记在脑子里,并试图理解 Q 页上的一些内容,同时不能忘记我最初想了解的东西。
更糟糕的是,有些 M 页的第一段会指向 N 页,而 N 页的第一段又会反过来指向 M 页,从而形成一种循环依赖关系。最终的结果是我需要阅读很多页,而在第一次阅读时,我几乎什么都不懂,而且脑海中未解决的问题还在不断增加。只有在阅读了大量的页面并同时思考后,其中一个页面的内容才开始变得有意义。
模式 2:某个文档页面有时会引入新的概念或术语,但并没有明确说明它们是什么或者与当前主题的关系。
这给人的感觉就像是,文件突然转移到了一个完全不同的主题上。当然,实际情况并非如此。只不过,新的主题与先前主题之间的关系并没有很明确。
举例说明
接下来,让我们来看看这两个模式在描述内容组织的文档页面中具体是如何体现的。
以下是所有 Hugo 初学者都必须阅读的经典页面。(因为这个页面的内容在未来可能会有所变化,所以这个 PDF 是在撰写本文时页面的静态快照)。假定读者是一个有心人,至少在浏览了文档的快速入门之后才会进入到这个页面。开始阅读页面时的视图如下所示:
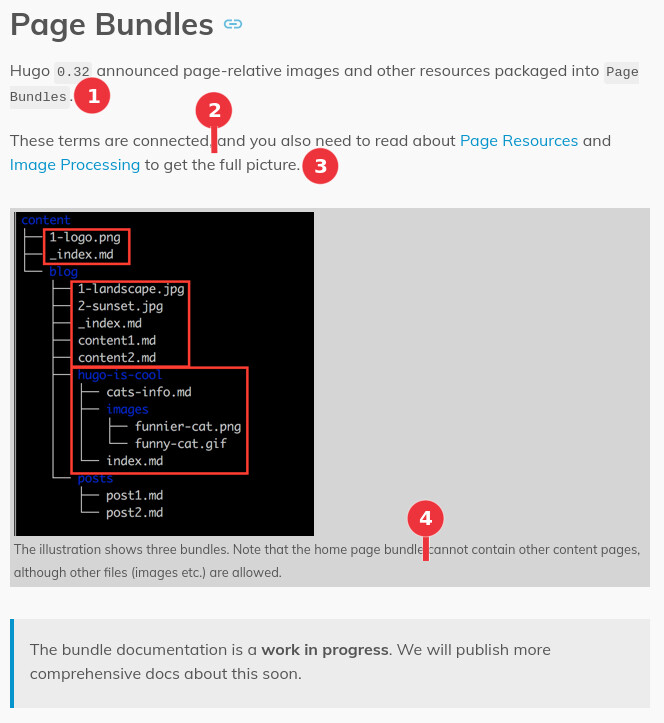
在编号为红色圆圈的位置,我的想法是:
“……与页面有关的图像和其他资源,都会被打包成页面包(Page Bundles)”。——好吧,但什么是“页面包”?
“这些术语是相互关联的……”——哪些术语??
“……以获得全貌。”——什么的全貌?大概是页面包吧?好吧,我可能需要阅读这两个链接(页面资源(Page Resources)和图像处理(Image Processing))才能完全理解这一点。
“……注意主页包(home page bundle)……”——“主页包”是啥玩意儿?图中三个红框中,哪个是主页包?“主”(home)这个词,并未在截图中显示。
请注意,到目前为止,读者还不能确定“页面包”是什么,除了它是打包页面相关的图像和其他资源的某种东西。从截图来看,我们也许可以间接地推测,“页面包”是一个包含了某些内容的文件夹或目录?但它没有被清楚地提及。
好了,我们先别看这个页面了,去点击这两个链接。下面的图片显示了你这么做时所发生的事情:
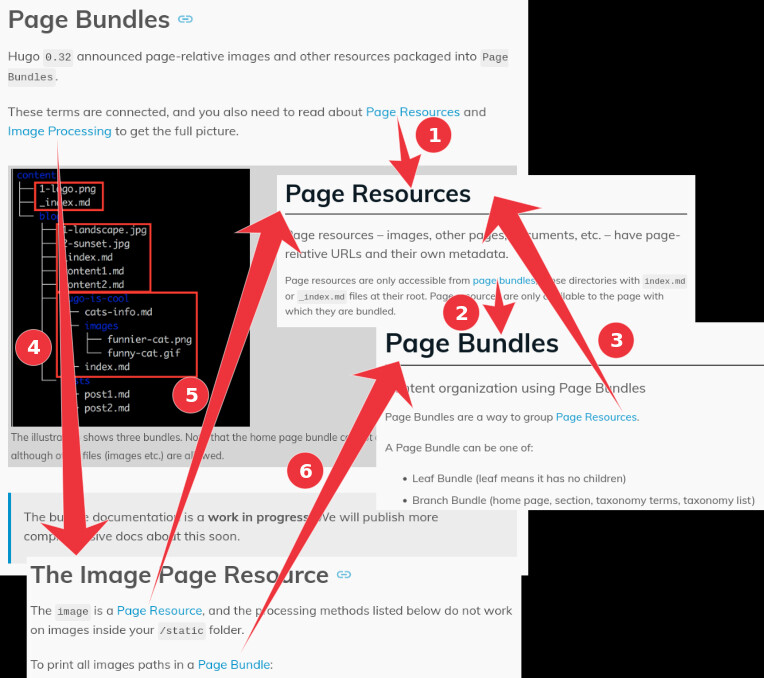
页面资源(Page Resources)页面上写着:“页面资源只能从页面包中访问,这些目录的根目录是 index.md 或 _index.md 文件。”——很好!所以,假定“页面包”只是一个包含特定内容的普通目录,这一点看起来是对的。不过,要真正知道什么是页面包,你现在需要跳到关于页面包的链接页面。页面包页面一开始就告诉你,“页面包”是对页面资源进行分组的一种方式。所以,嘿,这是一个回到我们来的那个页面的链接。到目前为止,我们仍然没有真正理解什么是页面包,也没有理解什么是页面资源。因此,也许可以通过阅读这一页、关于页面资源的前一页,以及我们最初阅读的那个页面来了解这一切?不过,等一下,我们还没有接触到图像处理,这又是一个未知的概念,但我们先这么做吧。访问图像处理页面。从字面上看,第一行链接到页面资源页面,第二行链接到页面包页面。
⚠到了这个时候,作为一名读者,我已经浏览了相互引用的 4 页文档。起初,我并不知道什么是页面包,到现在我仍然不完全清楚。另外,我也不知道什么是页面资源、什么是图像处理。我需要阅读所有这些页面……祈祷它们不会跳到其他页面(剧透:它们还是会!)然后反复思考我读过的所有东西,让它们在我的脑海中“合拍”。
请注意,密集的材料相互链接其实是件好事。事实上,这些页面都是相互链接的,这很好!但问题是,这些页面并没有尝试将附加/深度的内容加上链接让读者阅读,甚至有部分是独立的。相反,你必须找到那些链接,甚至要从头开始了解这个页面是什么主题。
我能想到最接近的编程类比就是一条嵌套的函数链。函数 A 调用函数 B,而函数 B 调用函数 C 等等,程序流需要沿着这个函数链往下走,然后在最初的函数 A 执行完毕之前再往上走。同样,对于 Hugo 文档,如果你从 A 页开始,你需要到 B 页,然后迫使你到 C 页等等,你需要阅读所有的页面(在页面之间有一些循环链接),然后一路回到 A 页,以便理解 A 页的内容。这就是模式 1 的一个典型例子。
注意:内容组织(Content Organization)页面确实写道,“包文档是一项正在进行的工作。……”问题是,页面包文档是存在的,只不过它没有在页面包的部分中被提及。不过我们还是接着往下阅读吧。

“虽然 Hugo 支持任何级别的内容嵌套,但……要阅读更多关于节(section)的内容,那么……”——嗯?“节”到底是什么?“节”与所描述的内容有什么关系?直到这时,这个页面从未提到过“节”这个词,而似乎没有理由地就突然要求读者去其他页面了解关于节的信息。
这就是模式 2 的一个典型例子。我可以简单地点击一下链接就能知道,但那将是另一个“兔子洞”。让我们先忽略这一点,继续阅读该页面。
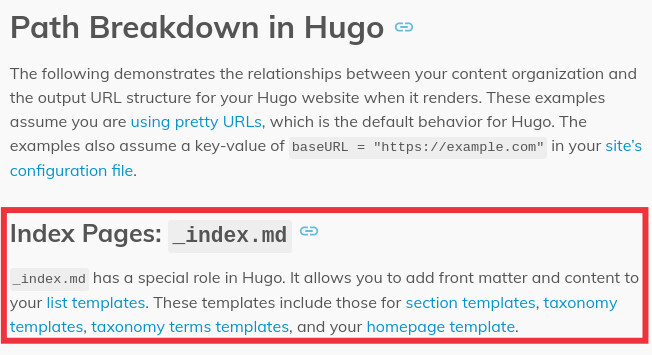
文档页面现在开始谈论一个名为 _index.md 的文件,这个文件以前没有提及过。对 _index.md 的描述是,它“……在 Hugo 中有一个特殊的作用。它允许你为你的列表模板添加前言和内容。这些模板包括那些节模板、分类法模板、分类法术语模板和你的主页模板。”——啊!此时,要理解 _index.md 到底有什么用,也许你需要理解什么是列表模板,甚至什么是“节”、“分类”、“分类术语”和“主页”模板。文档基本上要求用户阅读五个新术语,以便理解 _index.md 的用处。
⚠如果你读到这里,你已经阅读了一半的文档页面,但并没有理解多少东西!你不知道的东西增加了。不过,你倒是知道了自己有那么多不懂的,你现在明白必须要多阅读才能让这些变得有意义。
如何改进
模式 1:使每一页都完全自成一体是不可行的,也是不可取的。但是,如果 A 页提到的概念在 B 页有深入的描述,那么只要 A 页简要地描述了这个概念,那么读者就可以避免跳到 B 页。这对读者有很大的帮助,读者随后可以到 B 页去更好地理解,而不必打断在 A 页的阅读。实际上,Hugo 文档在某些页面上就是这样做的,但并未做到统一。例如,页面资源页面简要地描述了什么是页面包(“……那些根目录有 index.md 或 _index.md 文件的目录。”)。在这点上,这几个字可能就够了。
模式 2:这是一个特别恶劣的错误,没有任何借口可以去纵容。在没有开始介绍之前,不要随意地在一段中使用新的术语/概念。如果你不能这样做,那么你至少在前面要有一个“前提阅读”部分。
文档要适合你的读者。总的来说,Hugo 的文档看起来是熟练和有经验的程序员为熟练和有经验的用户编写的。如果你已经知道了大量的基本概念,那么这些文档就可以作为一个很好的参考。我不知道作者是否有意让它成为这样。相比之下,有经验的人往往会忘记身为初学者的感受,这种感受体现在他们的写作中。作者要以初学者的视角去阅读你所撰写的作品,就得花大力气。
很多项目将它们的文档划分成“入门”、“用户指南”和“参考”,每一个都比后面的要“温和”。也许 Hugo 可以采用类似的模式。入门类的文档也有,还有许多优秀的博客文章全面地记录了 Hugo。那些热衷于撰写和分享这些文章的作者是否对 Hugo 的文档有所帮助,例如用户指南中的章节?
从某种意义上说,这两种模式都违背了优秀技术写作的基本原则:给定的信息先于新的信息。在这页的 PDF 文件中描述和说明了这个原则。我认为,如果作者只采用这一条原则,而不采用其他原则,那么文档可读性将会得到极大地提高(假设你一开始就有可靠的内容)。多年来,在要求学生和同事遵守这一条原则之后,我发现这种观点是正确的。
我在这篇文章中对内容组织页面的前半部分进行了批评。但如果我不分享一个更好的页面版本的例子,那么这个批评就是不完整的。这样一个例子可以在这里找到。通过一些小的修改,加上一些解释,对初学者来说更加合适。
这些很重要吗?
难道是我在读完 Hugo 的文档后真的很生气,然后要长篇大论来发泄一下吗?嗯,似乎是这样的 :)
问题是,在花了很多时间修补 Hugo 之后,我现在已经吸收了足够的知识,以至于现有的 Hugo 文档在大多数时候都很有意义。或许 Hugo 的其他用户也是这样。
但我还清楚地记得,当我第一次阅读这份文档时,那种挫败的感觉。有时候,我会选择不去阅读官方文档,而是选择看博客或者指南来更好地理解那些概念。其他时间,我会重新寻找 Hugo 的替代方案,或者连续几天对 Hugo 置之不理,直到我有精力重新尝试。如果要学会使用 Hugo,我觉得 Hugo 的官方文档是我最不应该看的东西。
作者介绍:
Sagar Behere,架构师、系统集成商。Aurora Innovation Inc.的高级总监。
原文链接:

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论