

一、引子
在 eBay 新一代基于 Kubernetes 的云平台 Tess 环境中,流量管理的实现逐步从传统的硬件 Load Balancer 向软件过渡。在 Tess 的设计中,选用了目前比较流行的开源 Serivce Mesh 框架 Istio。
Istio 的组件中,控制平面的 Pilot 和数据平面的 Envoy 无疑最为重要。Pilot 提供了服务发现功能,并且把高层的规则转化为数据面组件识别的配置推送给数据面 Envoy,Envoy 根据这些规则去管理整个云平台环境的网络流量。
在 eBay 对于 Istio 的落地实践中,随着规模的不断扩大,Tess 系统迎来了诸多挑战,各种奇奇怪怪的问题也应运而生。最近,我们遇到 Pilot 在推规则给 Envoy 的时候,耗费时间很长甚至因此失败的问题。
在问题出现的时候,通过查看 Pilot Pod 的日志文件,发现了 Reset Connection 这样的日志。这些日志说明 Pilot 在推送规则的过程中,和 Envoy 之间的网络连接不时的被 Reset。正常传输过程中是不会出现连接被 Reset 的情况,那究竟为何会导致这不正常的 Reset 呢?因此,本文就这个典型案例做了比较详细深入的分析。
二、Kubernetes 网络基本原理
既然从日志看这是一个和网络相关的问题,我们首先得了解一下 Tess(eBay 内部容器云平台的代号)也就是 Kubernetes 的网络基本原理。
在 Kubernetes 里,每个 Pod 都有一个自己的 IP 地址,Pod 之间通过这些 IP 地址可以互相访问。为了保持网络的简洁性,Kubernetes 要求网络的实现中,Pod 之间的通信不需要做网络地址转化(NAT),不管 Pod 在同一个节点还是在不同的节点,都可以直接通信,从 Pod A 到 Pod B 的网络报文必须保持源 IP 地址和目的 IP 地址不变。
当 Pod 需要和 Kubernetes 集群外部通信的时候,情况就变得大不一样。Pod 在集群中获取的 IP 地址非常不稳定,随时都有可能因为种种原因不能正常工作。
为了保证 Pod 能提供稳定的服务,Kubernetes 引入了 Service 的概念。Service 允许长时间对外暴露稳定的 IP 地址和端口,因此后面一系列的 Pod 对外提供服务由 Service 替代进行,原先对于 Pod 的访问就变成对这个 Service 的访问,Service 再根据它所监管的 Pod 的健康状况或者负载均衡要求,把请求发送给这些 Pod。Kubernetes 的 Service 实际上就是一个架设在 Pod 前面的 4 层网络负载均衡器。
Service 有多种类型,其中 ClusteIP 是最基本的类型,这种类型 Service 的特点是它的唯一 VIP 是一个集群内部可见的地址,并且这个 ClusteIP 在集群内部不同的节点之间不可见,必须通过每个节点上 Kube-proxy 这个组件来保证节点之间的可达。通常情况下,Kube-proxy 通过 Iptables 的规则或者 IPVS 的规则来完成节点之间的可达。
有了以上的基础知识,我们再来分析这次问题就比较容易理解了。在我们这次出现问题的环境中,拓扑结构如下图所示:
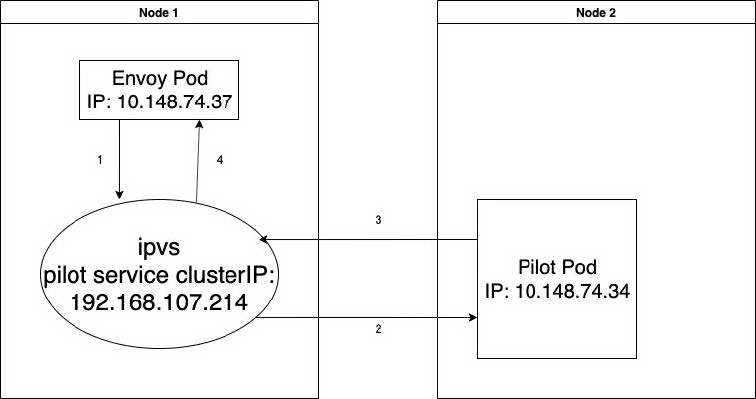
图 1
报文的转发流程如下:
去程:
1 src(10.148.74.37:48640) dst(192.168.107.214:15010) 2 src(10.148.74.37:48640) dst(10.148.74.34:15010) # DNAT回程:
3 src(10.148.74.34:15010) dst(10.148.74.37:48640) 4 src(192.168.107.214:15010) dst(10.148.74.37.48640) # SNAT
三、问题的排查过程
我们都知道,一切的网络问题,在你经过无数次的逻辑推理仍然毫无头绪的时候,只能回归到最原始的抓包大法,于是我们决定去案发现场全面撒网捕获凶手。对于我们遇到的问题,通信的双方来自 Pilot Pod 和 Envoy Pod,于是我们在这 2 个 Pod 上面同时开启 Tcpdump。规则推送是基于 TCP 端口 15010,所以只抓 TCP 端口 15010 的包(不限定 IP 地址),同时打开 Pilot 的 Log,看什么时候 Reset 的 Log 出现了,就停止抓包。由
于这个问题出现的概率很高,5 分钟之后就再现了。但是抓包文件多达几百兆,在经过了对网络拓扑结构的分析后,在 Envoy Pod 上的抓包过滤出 10.148.74.37:48640 <—> 192.168.107.214:15010 的一条 TCP 流,在 Pilot Pod 上的抓包过滤出 10.148.74.37:48640 <—> 10.148.74.34:15010 的一条 TCP 流,这样每个抓包文件大约 30M,保存成 2 个文件。最后我们同时打开 2 个 Wireshark,对照分析。剧透一下,事实上这里我们先通过 TCP 五元组过滤出我们认为正确的 TCP 流来分析,反倒是误导了我们分析的方向,让我们走入了死胡同。点开这 2 个抓包文件以后,我大致扫了一眼也开始凌乱,这 5000 多个报文来来回回,重传看上去很严重,TCP 重传的报文本来也算正常,只要不是一直丢包,最后总能成功,这不就是 TCP 存在的意义么?因此我第一猜想是网络环境导致丢包严重,应用程序一直等不到数据,然后超时,所以应用主动结束了连接。于是去查证 Envoy 的抓包文件,是不是收到了所有 Pilot 发过来的数据?
通过对比发送报文的序列号和接受到的 ACK 信息,发现最终结果 Pilot 发送的所有数据都收到了来自 Envoy 的 Ack,尽管中间出现了乱序重传的现象,但也算是完整的收到了所有数据,在 2 个抓包文件的最后都发现了 Reset 报文。图 2 是 Pilot Pod 的部分截图,可以看到 1992 号报文是 Pilot 收到的第一个 Reset 报文,后面 Pilot 持续收到 Reset 报文,从这些 Reset 的报文源 IP(10.148.74.37)来看应该来自于 Envoy Pod。同时从 1994 号报文开始,Pilot Pod 也持续的发 Reset 报文给 Envoy。
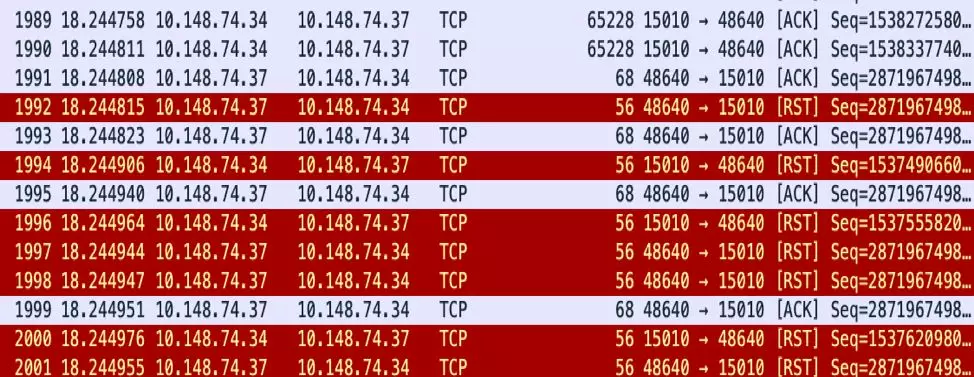
图 2
再去 Envoy Pod 的抓包文件(图 3)看看是怎么回事,奇怪的是我们过滤出来的 TCP 流只有一个 Reset 报文,这个 Reset 报文源 IP 来自于 Pilot Service 的 ClusterIP, 可以认为是来自 Pilot Pod。Envoy Pod 并没有发出任何 Reset 的报文。那么问题来了,Pilot 收到的这些 Reset 报文都是谁发出来的呢?从源地址看的确是来自于 Envoy Pod 的 IP,但是 Envoy 上我们过滤出来的 TCP 流也的确没有这些 Reset 报文。
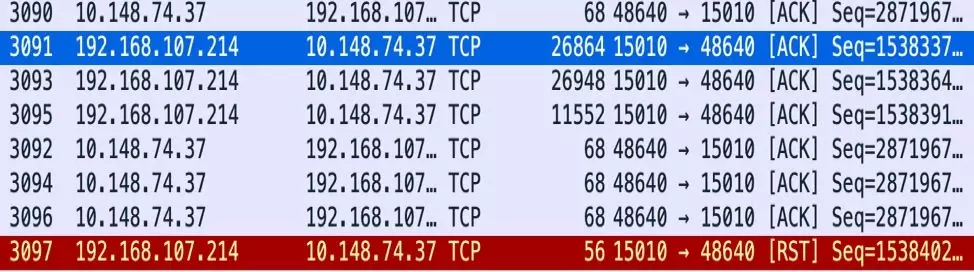
图 3
凭借多年防火墙开发经验,我立马想到防火墙经常干的事情不就是给 Client/Server 两端同时发 TCP Reset,让 Client 和 Server 都以为是对方发出来的嘛?难道是 Pilot 和 Envoy 中间的什么组件构造了 TCP Reset 发给了 Pilot 和 Envoy?于是和同事讨论了这个假设存在的可能,如果真是这样,那么就得知道 Pilot 和 Envoy 中间到底经历了哪些设备或者组件。
从软件角度看,中间也就是经过了 Kube-proxy,然后我们 Tess 的底层网络实现 OVN。但是 OVN 作为底层实现,不太可能涉及到传输层的东西,OVN 去主动发报文的可能性应该没有。后来和 OVN 大牛周涵确认,OVN 的确不会干这种事情,所以只能怀疑是 Kube-proxy。
Kube-proxy 是通过 Iptables 或者 IPVS 来实现,我们 Tess 环境里目前用的是 IPVS。理论上说,Kernel 里 Connection Track 模块是基于 4 层网络来实现,如果出现异常是有可能主动发 Reset 到 Client 和 Server。于是去 IPVS 官网查询是否有相关机制去主动向两端发 Reset,结果并没有找到相关证据。
在 Google 寻找相关问题的时候,发现有人遇到过 IPVS TCP Connection Reset 的问题,他们遇到的问题是 TCP Connection 在长时间 Idle 以后被 Reset, 这是因为 IPVS 里设置的 Connection Idle 超时时间比应用设置的超时时间短,当这个发生在应用是长连接的协议的时候,IPVS Idle 超时时间默认是 900 秒,如果该连接空闲时间超过 900 秒,那么 IPVS 就会删除该连接,如果 Client/Server 再发 TCP 报文,IPVS 就会回应 Reset。
这个和我们的情况有相似性,因为 Pilot 和 Envoy 之间是 gRPC 协议,gRPC 是长连接协议。但是从抓包和实际情况看,我们的环境并没有出现连接空闲这么长时间的情况,于是这个可能性也被否定了。
哪里来的 Reset?这个问题始终找不到答案,难道是我们漏掉了抓包?突然想起最初我们分析的抓包文件是过滤了 TCP 流之后的(即限定了五元组)。为了确保不漏掉任何报文,我们重新去看了原始的抓包文件,在 Envoy 的原始抓包文件里意外发现了另外一条 TCP 流 (见下图):

图 4
这条 TCP 流应该出现在 Pilot 上,Envoy 是只知道 Polit Service 的 IP 地址,而不知道 Pilot Pod 的地址,那怎么会在 Envoy 上抓到 Pilot Pod 的 IP 的报文呢?从这个抓包文件上看,之前找不到源头的 TCP Reset 全部都在这里了。之前的一番困惑,迎刃而解。
Pilot 收到的和发出的 Reset 都在这里,但并不是出现在本应该出现的 10.148.74.37:48640 <—> 192.168.107.214:15010 这条 TCP 流上。于是大胆猜测:从 Pilot 发给 Envoy 的报文没有经过 Kube-proxy 的 SNAT 直接到了 Envoy 上面。Envoy 收到源地址是自己不知道的 TCP 报文,于是就发 Reset, 同时这个 Reset 报文的五元组和 Pilot 上五元组是一致的,而且 Kubernetes 里 Pod 之间又是可达的,那么 Pilot Pod 就会收到这个它认为合法的 Reset 报文,然后把自己的 TCP 连接删除,于是我们在 Pilot Pod 的 Log 里看到了 Connection Reset!之后因为网络环境的问题,还有一些重传的报文在 Pilot Pod 删除了连接之后再收到,所以 Pilot 也会发 Reset。这样就解释了抓包文件里所有的 Reset 报文的产生原因了。描述起来可能比较麻烦,看下图会比较直观:
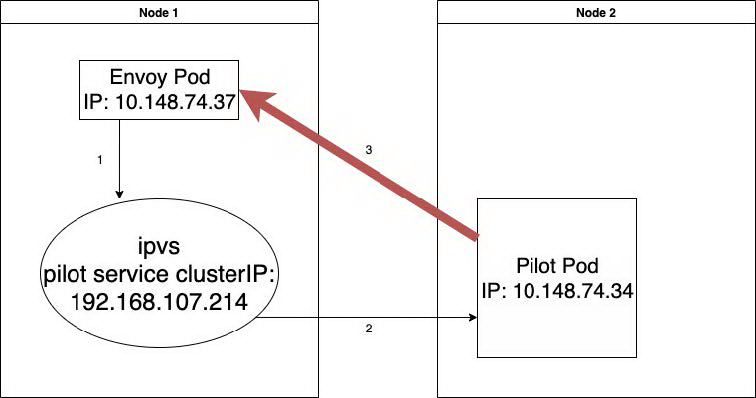
图 5
“凶手”算是找到了,可是“动机”呢?接下来的问题就是 Envoy 为什么会收到没有经过 Kube-proxy SNAT 的报文?从 Pilot 发给 Envoy 的报文,Kube-proxy(IPVS) 肯定会收到,除非就是 IPVS 没有处理这样的报文直接交还给协议栈,然后送回给了 Envoy Pod。带着这样的猜想,继续 Google 相关内容,终于找到 Linux Kernel 里有一个选项 nf_conntrack_tcp_be_liberal,从官方网站上看到这个选项的说明:
nf_conntrack_tcp_be_liberal - BOOLEAN 0 - disabled (default) not 0 - enabled Be conservative in what you do, be liberal in what you accept from others. If it's non-zero, we mark only out of window RST segments as INVALID.
就是说如果 Kernel 在做 Connection Track 的时候发现报文的序列号在 TCP 的窗口之外, 那么就认为这个报文是不合法的,不在 Connection Track 要处理的范围,但是并不会丢弃这样的报文,所以还是会交给协议栈继续处理。
有了这样的说明,我们重新仔细去审查所有的抓包文件,发现那个触发 RST 的包之前所有的 TCP 通信都已经完成,没有任何未被确认的数据,但异常包出现了,它的序列号比上一个包小了 5,794,996,也就是说它是最近收到的 5M 字节之前的数据,远远超出了当时的接收窗口。
四、内核选项的介绍
下面我们来看看这个内核选项到底干了啥事情,当然是直接上内核代码了。
找到 nf_conntrack_proto_tcp.c 文件,查看函数:
static bool tcp_in_window() { … if (before(seq, sender->td_maxend + 1) && in_recv_win && before(sack, receiver->td_end + 1) && after(sack, receiver->td_end - MAXACKWINDOW(sender) - 1))#检查收到的包的序列号是否在TCP接收窗口之内 { … } else {#这里就是不正常情况下,报文不在窗口里的处理,如果没有enable nf_conntrack_tcp_be_liberal, 那么res为false, 反之为true res = false; if (sender->flags & IP_CT_TCP_FLAG_BE_LIBERAL || tn->tcp_be_liberal) res = true; if (!res) { ... } } return res; } } 接着看tcp_in_window返回值的处理: static int tcp_packet() { if (!tcp_in_window(ct, &ct->proto.tcp, dir, index, skb, dataoff, th)) { spin_unlock_bh(&ct->lock); return -NF_ACCEPT; } } #define NF_DROP 0 #define NF_ACCEPT 1
如果报文不在窗口里,tcp_packet() 会返回 -NF_ACCEPT, 也就是-1。事实上返回 0 的时候会丢弃这个报文,这个时候也不会有未经 NAT 的报文到达 Envoy Pod,我们的问题也不会出现;如果返回 1,报文会正常命中 NAT 规则,Envoy Pod 也不会发 Reset。现在返回了-1,报文没有被丢弃,但同时也没有去查询 NAT 规则,最终导致了我们遇到的问题。
五、解决方案
从前面的分析,我们当然可以打开 nf_conntrack_tcp_be_liberal,但为什么报文会出现在窗口之外仍然没有明确的答案。考虑到 Tess 环境下出现问题的集群 CPU 分配比较满,同时从抓包来看乱序也比较严重,我们怀疑这和 Hyperviser 对网络报文的处理能力有比较大的关系,Hyperviser 导致某些报文处理不及时,被延迟发送到了 Kube-proxy,这个时候重传的报文已经处理过了,这些延迟到达的报文就成了窗口之外的报文。后来负责网络硬件性能的同事打开了 RPS (Receive Packet Steering),使性能得到提升,之前遇到的问题就没有再次发生。
因为更改内核参数还是具有一定未知风险,目前问题在性能提升的情况下没有再次出现,所以我们暂时没有去更改内核参数的计划。
六、总结
对于这次出现的问题的整个追踪过程比较曲折,从这个过程中我们也学习到了不少知识,累积了一些经验:
抓包尽可能的完整,在按照正常逻辑分析问题过滤的同时,也要关注非正常情况下的特殊报文,因为问题的出现往往就是非正常逻辑的报文引起的。
内核网络处理部分有很多细节的选项,在遇到百思不得其解的网络问题时,我们可以从这些选项上入手分析问题。
性能问题也会带来一些意想不到的功能问题。在我们系统设计开发的前期需要尽可能地关注和测试性能问题。
Ipvs 本身是有连接空闲超时时间的,在没有 TCP Keepalive 的情况下,中间组件也是有可能删除连接导致 Client/Server 被 Reset。虽然我们目前遇到的不是这种情况,但也是以后值得关注的问题。
作者介绍:
张博,eBay 软件工程师,目前致力于 eBay 网络流量管理以及 eBay Kubernetes 平台网络相关组件开发维护。
本文转载自公众号 eBay 技术荟(ID:eBayTechRecruiting)。
原文链接:
https://mp.weixin.qq.com/s/phcaowQWFQf9dzFCqxSCJA

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论