

这几年大家会发现业界内频繁地提到可观测,也有很多人会问可观测跟之前传统的监测到底有什么区别?可观测并不是一个新的概念,它其实是传统监测的扩展。传统监测领域更多是基于外部的视角去看一个系统,去看一些系统的行为,从而规划整个系统的失败模型,它更多的是从运维的视角来看。
今天,我们把这个概念从监测扩展到可观测,其实更多是从系统内部的白盒化思路去看系统内部的运行状况,是由内往外的,同时结合多种观测手段,包括我们传统说的 Metrics 指标,从而做一个非常深入的分析,了解整个系统运行状态的根因。
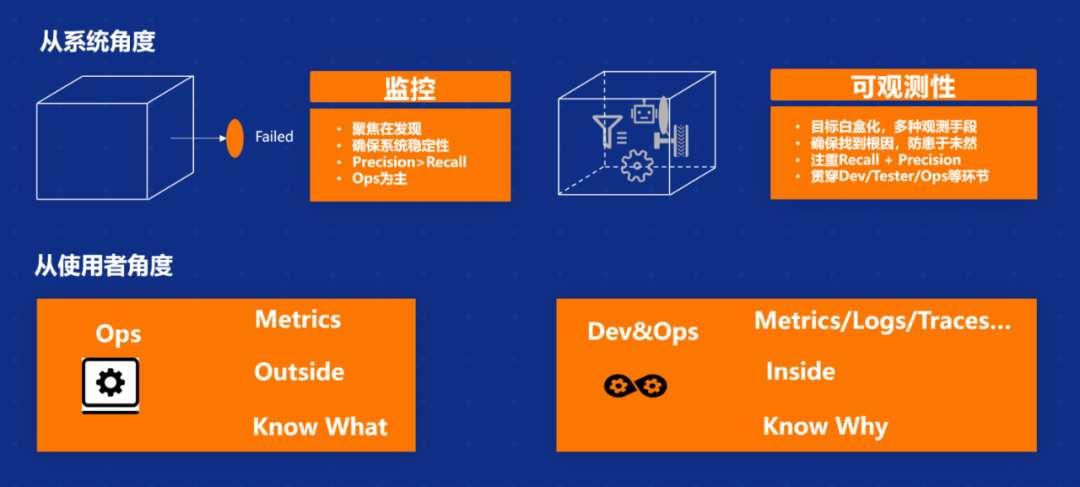
另外从使用者角度来讲,传统监测更多是从运维角度,一些传统的 Metric 维度指标,从外部进行观测来得知里面发生了什么。云原生可观测贯穿了整个应用,甚至整个应用开发的生命周期,包括开发、测试、上线、部署、发布。所有的生命周期不仅会通过 Metrics,还会有系统日志、业务日志、链路追踪等方式来进行整个全方位 360 度无死角的监测。换句话说,更多是从内往外来诊断出系统内部产生问题的根因,究竟出现了什么样的问题,发生的原因,以及一些对应的恢复手段,这些是我们整个可观测核心关注的点。
云原生时代对稳定性提出更高要求
随着容器、微服务逐渐流行起来,我们进入到了云原生时代。传统企业要做云原生转型,对整个监测以及稳定性方面提出了更高的要求:

第一,支撑业务快速迭代。举个例子,阿里巴巴内部有将近 8000 到 9000 个应用,每天会做将近 4000 次的应用发布,这样频繁快速的迭代,对系统的稳定性、可观测、运维等方面提出了极高的要求,要求通过各种手段完成稳健的支撑。
第二,复杂的调用拓扑。随着整个微服务化的兴起,传统的大型单体应用在微服务化之后,带来非常好的弹性、便捷的服务,但同时也导致整个应用的链路会变得非常复杂。今天如果按照传统的方式来做的话,我们可能只需要依赖于一些专家的经验去看个别问题,这本质上是一个瓶颈类型的问题。
第三,极致的用户体验。今天企业拥抱云原生时代,对数字化转型有强烈的诉求,需要一个更极致的 IT 方面的体验。比如说故障响应必须要更快,一个问题从发现到恢复也希望更快,处理的时间更要加快,这是一个挑战。
最后,高效的运维协同。通过传统的工单方式有时候的效率会偏低,如何解决组织协同的问题,这也是我们关注的一个方向。
云原生可观测覆盖场景
云原生可观测重点包括以下几个场景:
1、应用发布部署。在特定的场景下我们需要能支撑非常场景化的监测和观测能力。
2、全景监测。这个很好理解,因为今天无论从应用的前端,从用户侧到应用侧,再到中间件,还是再到底层的 IaaS、基础设施层,从端到端,这其中所有的链路都需要纳入到企业的监测体系中做一个全景监测,这是企业应该致力于做的事。
3、智能告警。如今仅是把所有的观测做好了是远远不够的,我们需要引入一些更高级的玩法。阿里内部这么多年将一些人工智能技术引入到我们的观测领域来,是为了能够帮助减轻整个运维的负担,这也是后面会详细分享的部分。
4、性能诊断。在发现问题或者说在性能压测的时候,如何快速地诊断到问题,可以依赖一些工具发现问题的调用链,以及一些专家经验级的实践,这是我们在性能诊断方面需要加强的。所有的这些场景都包含了整个应用的生命周期。同时我们也要支持各种各样的云环境,包括公有云、专有云、混合云的体系,这些是云原生的核心场景。
云原生可观测建设要点
接下来分享一下我们通过最佳实践,总结云原生可观测的几个要点。核心要点有三个:1. 我们的数据从哪里来。2. 我们如何建立这方面的可观测数据模型。3. 我们如何用好这些数据模型、如何分析。
数据从哪里来
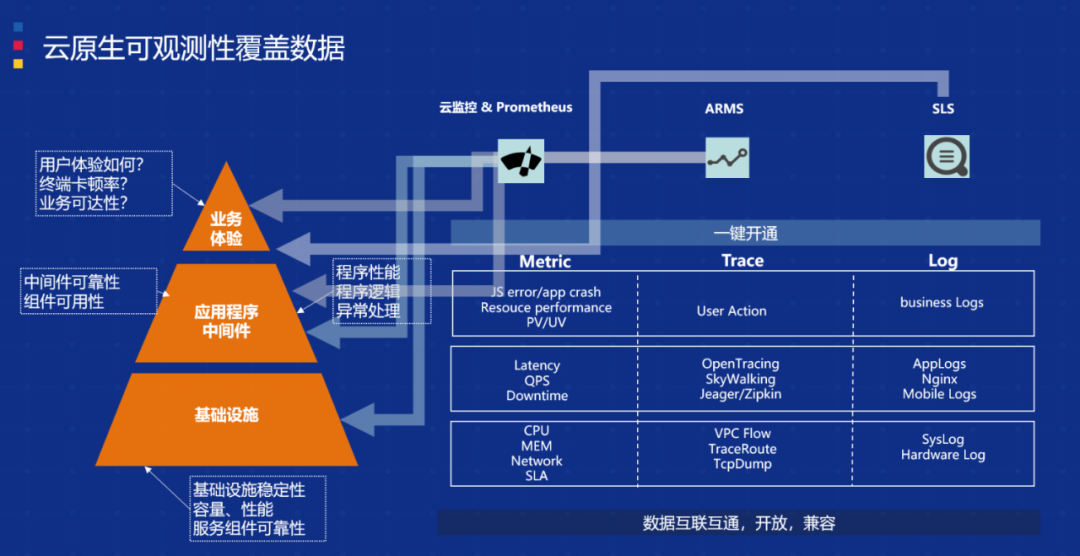
今天的整个可观测体系已经非常丰富了。我们要把所有的端到端,包括上层的业务到应用程序,再到分布式系统、中间件、底层基础设施,所有这些都纳入到可观测体系中,核心是阿里云的各种监测产品,包括云监测 & Prometheus、ARMS、SLS 等。这些产品的组合能够帮助用户把所有的可观测点都纳入到整个体系中来,包括各种维度的 Metrics、各种维度的指标、各种维度的 Trace,包括开源的兼容、自建的链路追踪,以及业务日志、系统日志、组件日志,所有维度都可以纳入到可观测里来。这是第一步,主要解决可观测的数据从哪里来、做得是否全面的问题。
如何建立可观测的数据模型
拿到数据之后怎么建模?考虑到传统企业的运维,可能更需要统一的监测视图,比如更需要做 2D 或者 3D 的展示,我今天给大家做了一个展示。
首先最底层就是 IaaS,包括一些容器、虚机。另外一层就是上面的应用,这里面也包括微服务应用和组件,分布式数据库、分布式消息,以及缓存等。再往上一层就是整个的应用服务,每一步其实都是可以做下钻的,看某一个问题节点时,可以算到非常详细的地方。
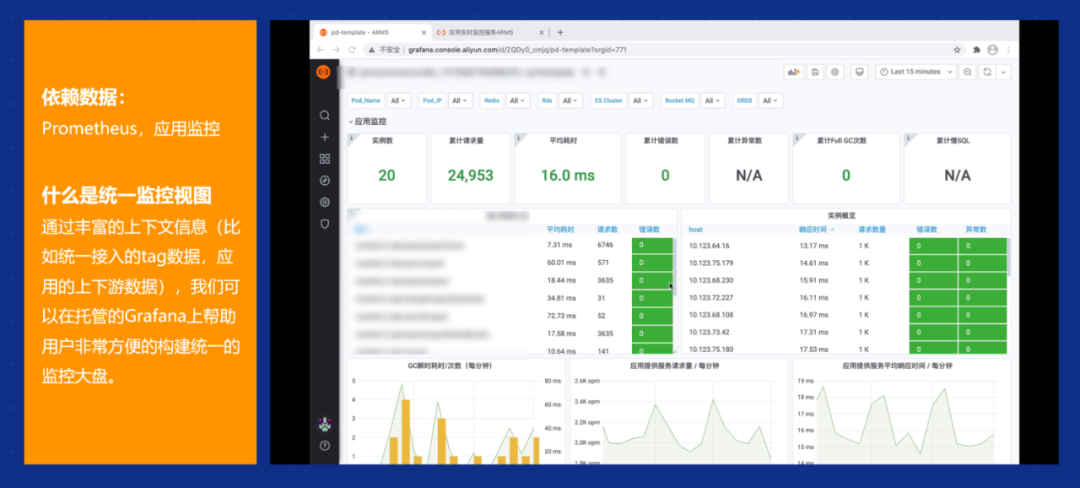
另外,在容器场景下,因为今天的容器是作为整个基础设施的标准,大家可以依托于整个监测体系快速搭建针对满足自己需求的平台。我们监测关键的核心数据组件,包括应用状态、RT、CPU 响应、消息等。另外就是缓存的状态,也可以做一个展示,包括 RDS 分布式数据库、管理型数据库、MQ、核心数据库等。我们也有非常多的数据库诊断手段,包括 ES 检索数据库、MQ 消息,整个都是构成针对运维人员的统一监测大盘,可以方便快速的自定义搭建。
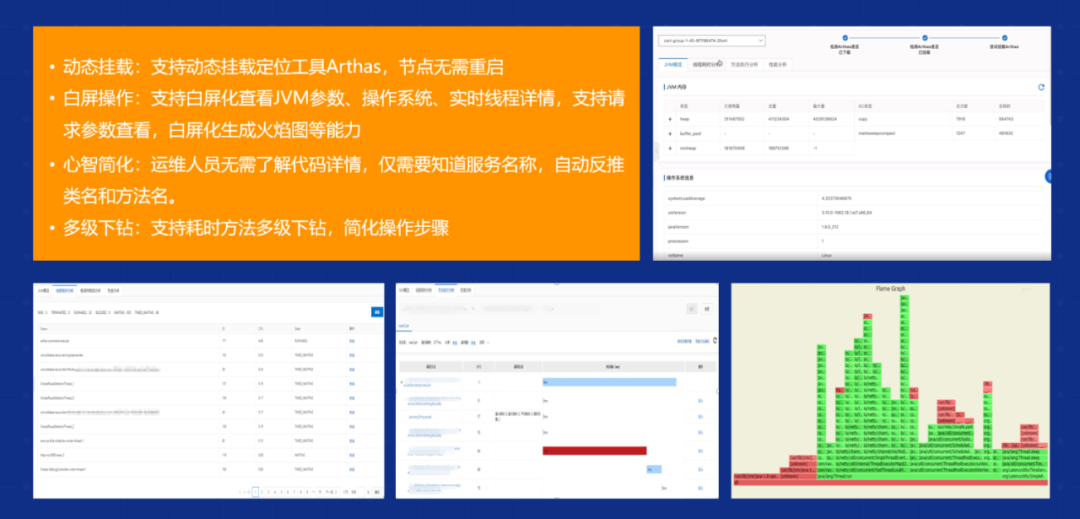
最后,白屏化的集成定位。我们监测到数据之后,接下来就是问题定位。今天不仅是在阿里内部,我们对外提供的一些产品,其实已经能够实现快速白屏化的定位,就是说今天你不需要再翻你的代码、再去登录机器看日志了,所有的问题都可以通过全链路展示的方式,定位到整个链路的根节点。包括我们关心的一些内存、CPU、JVM 参数、线程参数,都可以通过白屏化的方式展现给大家,这是我们对可观测系统做了非常高度的集成。
如何分析
介绍了数据模型怎么建、怎么收集之后,还是远远不够的。今天我们是需要对可观测数据做一个深度挖掘,主要分为两个方面:
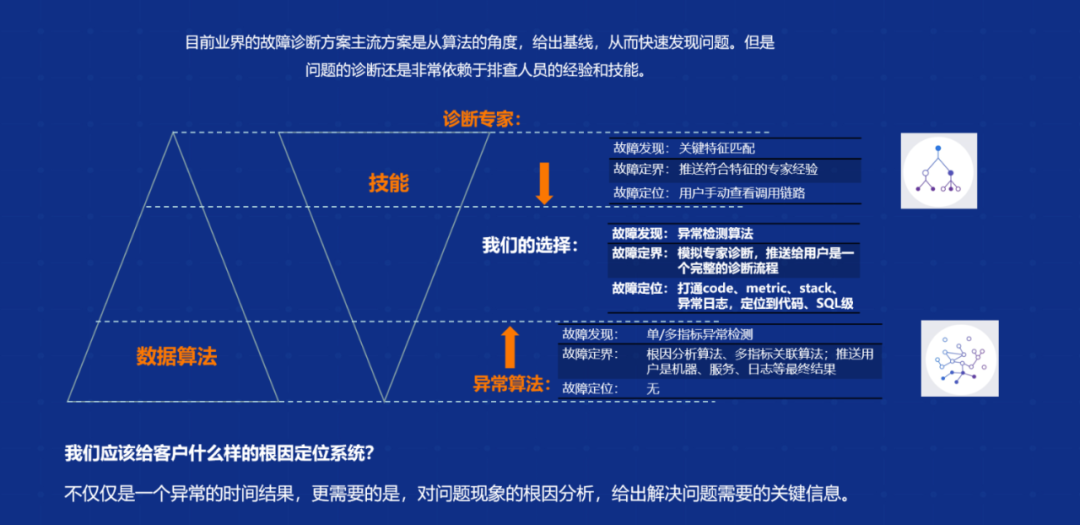
一是采用人工智能技术。但我们发现单纯采用人工智能技术来做,有时候是不起作用的,同时也需要一些专家经验指导,我们需要把整个专家经验沉淀下来。目前业界做故障诊断主流的方法是从算法的角度给出一些基线发现问题,但是针对问题根因的诊断还是源于排查人员的技能。今天我们要找到的不仅仅是异常结果,还需要把整个端到端到问题的根因分析,以及相应的关键信息都展现出来。这里面依赖两点:一是人的技能问题,二是机器的算法问题。
首先是人的技能问题。我们的专家经验是能够在一定程度上帮助大家去解决问题的,但是怎么把这个东西给沉淀下来,这是一个问题。另外在机器方面,我们采用确定性的人工智能算法,能够通过对指标的检测从而解决问题。
今天我们的思路是把这两项相结合,在人工智能这种算法应用的基础上,再通过专家经验的沉淀来做指导。因为我们在实战过程中发现,如果仅仅依赖于人工智能的话,其实人工智能在有些场景下就变成了人工智障,所以必须依靠专家经验的沉淀来指导这个算法。
所以为了达到两者的结合,在专家经验方面,阿里云将其沉淀在产品中。阿里云可观测产品 ARMS 覆盖了 50 多个故障场景,包括应用的变更、RT 的突增、突发的大请求、单机的问题、MySQL 等,都会把相应的经验固定下来帮助大家快速自动诊断这部分问题场景,这是我们通过大量的实践,把专家经验通过白屏化的方式沉淀下来,自动化的展示给大家。
这里面必不可少的是我们要做可观测的日常预测监测,这也是集团内用的非常多的。阿里内部做异常检测主要是三个方面,一个是服务器层面,将服务器故障的特征训练出来。另外是集群层面的一些异常指标、特征给训练出来。最后是应用层面,面向应用和日志的,我们通过一些 API 出口的异常模型把它训练出来。
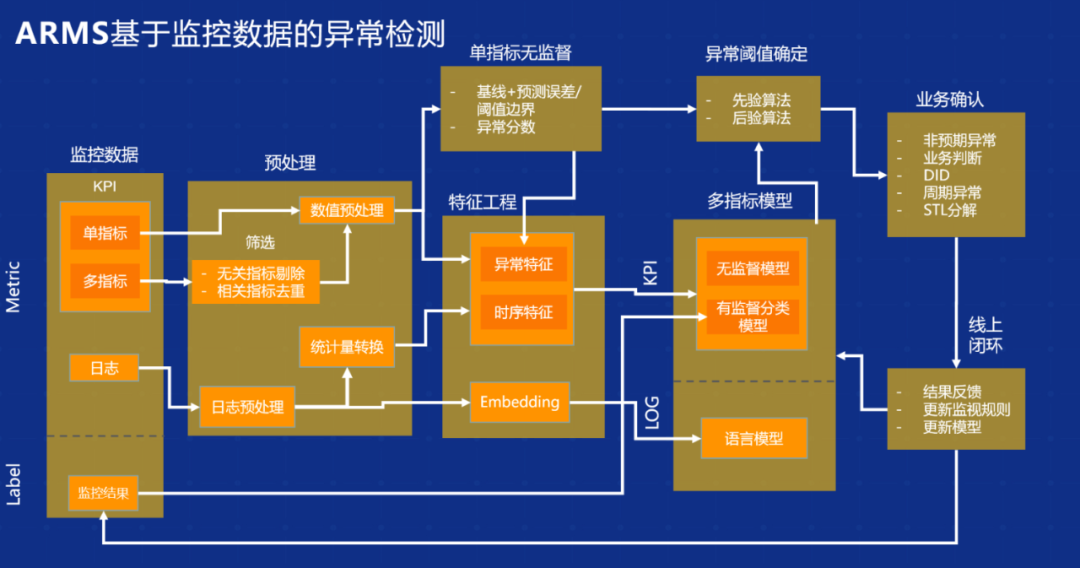
首先是监测数据,包括多指标的监测数据收集上来之后,通过做一方面的预处理,把一些无关的指标去除,或者说一些相关的指标去重。这里面我们也用到了创新的方法,采用了标准化的模型方式,把正常跟异常的差异纳入到某一个区间内进行分析。做完这些预处理之后,就要建立特征工程,今天我们也是把单指标异常的分数作为异常特征方式,这块我们做得比较多,核心是把整个异常特征以及时序特征的准确率提得更高。特征做完之后就是多指标方式,阿里采用时序预测的方式,多指标模型建立的更准确。同时,模型建立完之后,上线运行的过程中,我们会不断反馈,对整个训练出来的模型进行不断地修正,形成一个闭环的正反馈。这就是可观测产品基于日常检测的基本的框架。近期阿里云会慢慢将这部分开放出来给大家用,大家可以关注一下。
云原生可观测建设的最佳实践

场景一,容器场景下的全景可观测能力。今天容器已经成为 IaaS 层的标准,整个容器场景下的可观测能力,包括全链路端到端多样的数据接入能力,包括 APM 厂商、Prometheus、主动拨测、流量监测、网络监测等,全部纳入到容器场景下的可观测能力。另外就是全方位数据可视,我们会把数据的可观测建模呈现得非常通俗易懂,对于运维人员和客户以非常友好的方式展现出来,而且每一层都可以 2D、3D 拓扑全景展示,每一层都可以层层下钻,帮助分析根因。还有一个特点是快速发现问题,通过专家和白屏化的诊断手段,所有的问题都可以层层下钻,直到找到最底层的相关信息,帮助大家解决问题。

场景二:复杂链路的智能诊断。主要依托于两点。第一是专家经验,我们沉淀下来将近 50 多个场景的专家经验做白屏化的根因分析。第二是确定化的人工智能技术进行一些问题的异常预测和检测等等,包括整个阿里云可观测的体系,把整个阿里云的核心云产品,包括 ECS、EDAS、AHAS、MSE,能够跟所有产品之间做一个深度对接,之后再注入一些组建的自恢复能力,这样能生成一个自动化的问题发现、自动化诊断、自动化恢复。
场景三:对人工智能技术在异常检测场景下的最佳实践。主要是两个场景:
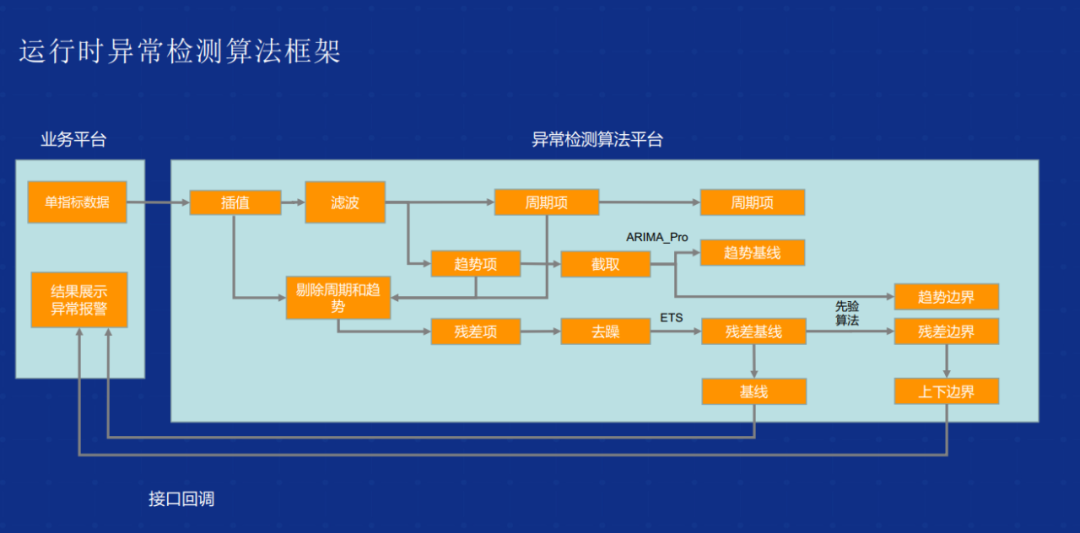
一个是比较常见的运行时的异常检测。阿里巴巴内部有将近 8000 到 1 万 个应用,我们的监测频度比较高,都是分钟以内,这样的话几乎每时每刻都有上百万个指标要进行监测,这个量非常大。如果依赖于运维人员做这个事显然是不现实的,所以说我们采用异常检测算法平台,主要思路是基于 STL 时序分解的基线预测,再加上基于上下边界的预估。
基线方法我们内部有几个最佳实践第一个是我们采用的 STL 的时序数据的预测分解,另外一个是基于 ARIMA 框架的拓展 ARIMA-PRO,对周期性的序列做到更好的预测,并且能够自动的去更新我们的 ARIMA 框架参数,包括 DBQ 参数,就是差分、AR 参数,这些核心的人工智能参数我们是能够做到自闭环。
另外一个是基于 Holt-winters 时续预测的模型,进行残差值的预测。另外上下文预估方案,我们是采用 IQR+历史同笔的先验方案的做的,这是我们内部比较好的实践。这是刚才说的简单的运行时的检测算法框架,核心是几个创新点,一个是 ARIMA-PRO,可以做到关键参数自动更新的框架的增强。
还有一个是基于 STL 以及 IQR 残差值的检测,并且基于 IQR 上下文边界的划分,是算法平台里面比较核心的几个技术点。比如说基于 RMSE 均衡分布差的统计方式,能够从之前的 0.74 下降到 0.59,误差下降了 20 个百分点。在 2019 年这个算法框架成功预测了某一次因为退款下跌引发的故障,取得了不错的效果。
另一个是应用发布时异常检测。很多故障都是新版本上线的时候,所以我们针对应用发布也做了非常多的算法,尤其在阿里,前面也说了我们 8000 个 应用,每天可能有 4000 次 的应用发布,内部应用迭代非常快。如果是依靠传统的设置固定的阈值监测的话不够灵活,拓展性比较差,而且需要人工去不断地更新。效率是非常低下的。
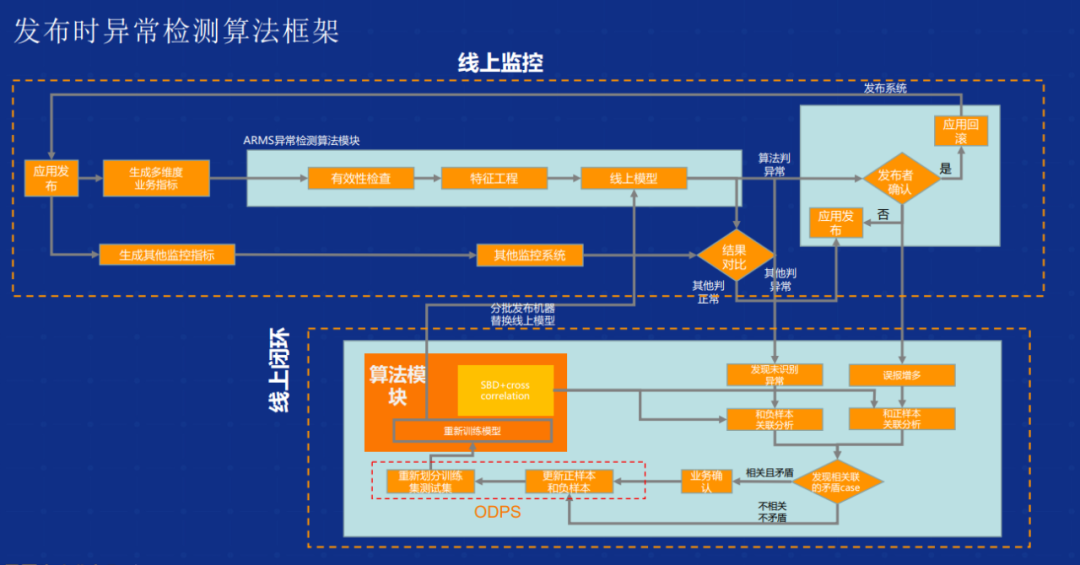
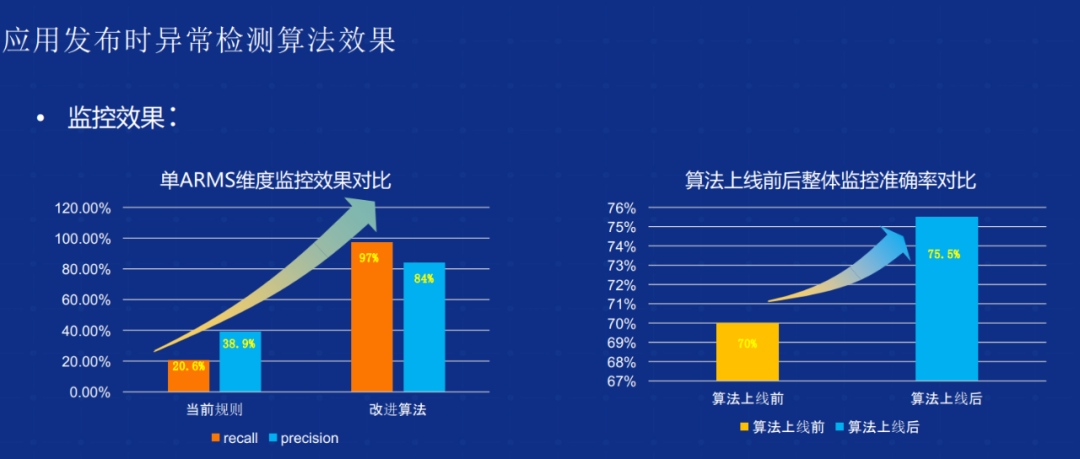
今天我们在发布时实现的框架,核心是实现了我们算法模型自适应的闭环。我们整个线上的模型以及事例,通过筛选误报和微检测的异常来更新正负样本,在我们的大数据平台更新训练集、重新更新模型。同时基于 SBD,是能够针对偏移后的序列相关性进行很好的序列分析算法,把整个训练闭环做得非常好。这是当时做发布时的异常检测算法框架的比较核心的创新点。整个算法框架上线之后,内部单个维度的监测效果有了 3 到 5 倍的提升。另外从整体监测维度,提升了大概将近 5 到 10 个 百分点,整个效果还是比较明显的。
本文主要介绍了运行时和上线发布时的监测案例,其实还有很多其他的,比如说日常出现异常情况的监测,也是业内比较典型的例子,其他还有一些包括业务指标的异常检测等。我们已经把一些人工智能技术以及专家的经验沉淀到云原生产品上,除了在我们内部使用之外,正在慢慢地开放到外部的云产品上,欢迎大家去使用。
本文转载自:阿里巴巴中间件(ID:Aliware_2018)
原文链接:云原生可观测建设要点与案例分析

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论