本文是 Apache Beam 实战指南系列文章第五篇内容,将对 Beam 框架中的 pipeline 管道进行剖析,并结合应用示例介绍如何设计和应用 Beam 管道。系列文章第一篇回顾Apache Beam 实战指南 | 基础入门、第二篇回顾Apache Beam 实战指南 | 玩转 KafkaIO 与 Flink、第三篇回顾Apache Beam实战指南 | 玩转大数据存储HdfsIO、第四篇回顾Apache Beam实战指南 | 如何结合ClickHouse打造“AI微服务”?。
关于 Apache Beam 实战指南系列文章
随着大数据 2.0 时代悄然到来,大数据从简单的批处理扩展到了实时处理、流处理、交互式查询和机器学习应用。近年来涌现出诸多大数据应用组件,如 HBase、Hive、Kafka、Spark、Flink 等。开发者经常要用到不同的技术、框架、API、开发语言和 SDK 来应对复杂应用的开发,这大大增加了选择合适工具和框架的难度,开发者想要将所有的大数据组件熟练运用几乎是一项不可能完成的任务。
面对这种情况,Google 在 2016 年 2 月宣布将大数据流水线产品(Google DataFlow)贡献给 Apache 基金会孵化,2017 年 1 月 Apache 对外宣布开源 Apache Beam,2017 年 5 月迎来了它的第一个稳定版本 2.0.0。在国内,大部分开发者对于 Beam 还缺乏了解,社区中文资料也比较少。InfoQ 期望通过 Apache Beam 实战指南系列文章 推动 Apache Beam 在国内的普及。
一.概述
其他行业问咱们 IT 具体干什么的,很多 IT 人员会自嘲自己就是“搬砖”(此处将复制代码称为搬砖)的民工。过了两天 GitHub 出现自动写代码的人工智能,IT 程序员深深叹了一口气说道“完了要失业了,代码没得搬了”。其实从入行 IT 那一刻起,不管我们做前端、服务端、底层架构等任何岗位,其实我们都是为数据服务的服务人员(注:不是说从民工转岗到服务员了):把数据从后端搬到前端,把前端数据再写入数据库。尽管编程语言从 C、C++、C#、JAVA、Python 不停变化,为了适应时代背景框架也是千变万化,我们拼命从“亚马逊热带雨林”一直学到“地中海”。
然后 Apache Beam 这个一统“地中海”的框架出现了。Apache Beam 不光统一了数据源,还统一了流批计算。在这个数据传输过程中有一条核心的技术就是管道(Pipeline),不管是 Strom,Flink ,Beam 它都是核心。在这条管道中可以对数据进行过滤、净化、清洗、合并、分流以及各种实时计算操作。
本文会详细介绍如何设计 Apache Beam 管道、管道设计工具介绍、源码和案例分析,普及和提升大家对 Apache Beam 管道的认知。
二.怎样设计好自己的管道?
设计管道注意事项
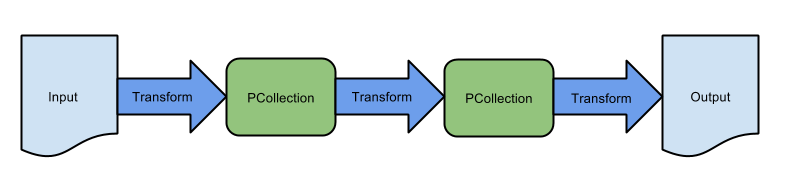
图 2-1 简单管道
1. 你输入的数据存储在那里?
首先要确定你要构造几条数据源,在 Beam 可以构建多条,构建之前可以选择自己的 SDK 的 IO。
2. 你的数据类型是什么样的?
Beam 提供的是键值对的数据类型,你的数据可能是日志文本、格式化设备事件、数据库的行,所以在 PCollection 就应该确定数据集的类型。
3. 你想怎么处理数据?
对数据进行转换、过滤处理、窗口计算、SQL 处理等。 在管道中提供了通用的 ParDo 转换类,算子计算以及 BeamSQL 等操作。
4. 你打算把数据最后输出到哪里去?
在管道末尾进行 Write 写入操作,把数据最后写入你自己想存放或最后流向的地方。
管道的几种玩法
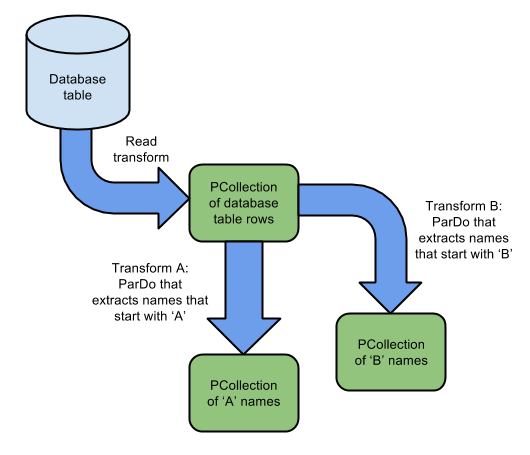
1. 分支管道:多次转换,处理相同的数据集
图 2-2-1 多次转换处理相同数据示意图
描述:例如上图 2-1-1 图所示,从一个数据库的表读取或转换数据集,然后从数据集中分别找找以字母“A”开头的数据放入一个分支数据集中,如果以字母“B”开头的数据放入另一个分支数据集中,最终两个数据集进行隔离处理。
数据集:
//为了演示显示内存数据集final List<String> LINES = Arrays.asList( "Aggressive", "Bold", "Apprehensive", "Brilliant");
复制代码
示例代码:
PCollection<String> dbRowCollection = ...;// 这个地方可以读取任何数据源。PCollection<String> aCollection = dbRowCollection.apply("aTrans", ParDo.of(new DoFn<String, String>(){ @ProcessElement public void processElement(ProcessContext c) { if(c.element().startsWith("A")){//查找以"A"开头的数据 c.output(c.element()); System.out.append("A开头的单词有:"+c.element()+"\r"); } }}));PCollection<String> bCollection = dbRowCollection.apply("bTrans", ParDo.of(new DoFn<String, String>(){ @ProcessElement public void processElement(ProcessContext c) { if(c.element().startsWith("B")){//查找以"A"开头的数据 c.output(c.element()); System.out.append("B开头的单词有:"+c.element()+"\r"); } }}));
复制代码
最终结果展示:
A开头的单词有:AggressiveB开头的单词有:BoldA开头的单词有:ApprehensiveB开头的单词有:Brilliant
复制代码
原示例代码地址 :pipelineTest2_1
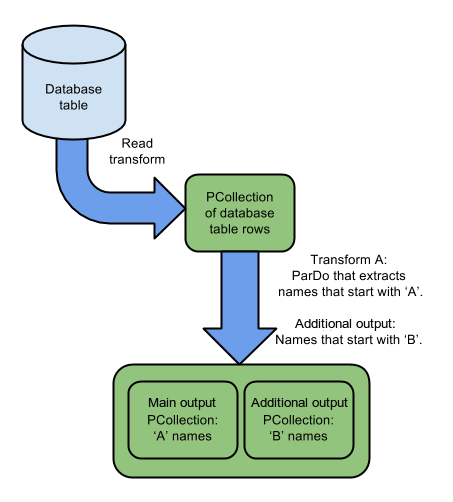
2. 分支管道:一次转换,输出多个数据集
图 2-2-2 一次转换多个输出示意图
描述:根据图 2-2-1 和图 2-2-2 图中可以看出,他们以不同的方式执行着相同的操作,图 2-2-1 中的管道包含两个转换,用于处理同一输入中的元素 PCollection。一个转换使用以下逻辑:
if(以'A'开头){outputToPCollectionA}
复制代码
另一个转换为
if(以'B'开头){outputToPCollectionB}
复制代码
因为每个转换读取整个输入 PCollection,所以输入中的每个元素都会 PCollection 被处理两次。
图 2-2-2 中的管道以不同的方式执行相同的操作 - 只有一个转换使用以下逻辑:
if(以'A'开头){outputToPCollectionA} else if(以'B'开头){outputToPCollectionB}
复制代码
其中输入中的每个元素都 PCollection 被处理一次。
数据集:同 2-1-1 数据集
示例代码:
// 定义两个TupleTag,每个输出一个。final TupleTag<String> startsWithATag = new TupleTag<String>(){};final TupleTag<String> startsWithBTag = new TupleTag<String>(){};PCollectionTuple mixedCollection = dbRowCollection.apply(ParDo .of(new DoFn<String, String>() { @ProcessElement public void processElement(ProcessContext c) { if (c.element().startsWith("A")) { // 返回首字母带有"A"的数据集。 c.output(c.element()); } else if(c.element().startsWith("B")) { // // 返回首字母带有"B"的数据集。 c.output(startsWithBTag, c.element()); } } }) // Specify main output. In this example, it is the output // with tag startsWithATag. .withOutputTags(startsWithATag, // Specify the output with tag startsWithBTag, as a TupleTagList. TupleTagList.of(startsWithBTag)));// Get subset of the output with tag startsWithATag.mixedCollection.get(startsWithATag).apply(...);// Get subset of the output with tag startsWithBTag.mixedCollection.get(startsWithBTag).apply(...);
复制代码
如果每个元素的转换计算非常耗时,则使用其他输出会更有意义,因为一次性过滤全部数据,比全部数据过滤两次从性能上和转换上都存在一定程度上提升,数据量越大越明显。
最终结果展示:
A开头的单词有:ApprehensiveA开头的单词有:AggressiveB开头的单词有:BrilliantB开头的单词有:Bold
复制代码
原示例代码地址 :pipelineTest2_2
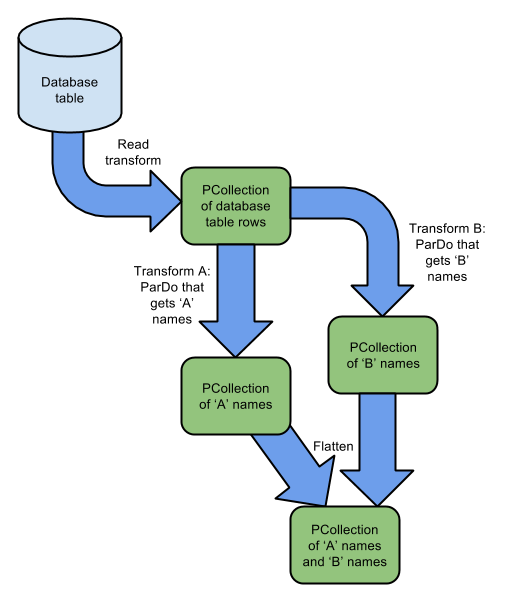
3. 合并管道:多个数据集,合并成一个管道输出
图 2-2-3 多数据集合并输出图
描述:
上图 2-2-3 是接图 2-2-1 的继续,把带“A” 的数据和带“B” 字母开头的数据进行合并到一个管道。
这个地方注意点是 Flatten 用法必须两个数据的数据类型相同。
数据集:
//为了演示显示内存数据集final List<String> LINESa = Arrays.asList( "Aggressive", "Apprehensive");final List<String> LINESb = Arrays.asList( "Bold", "Brilliant");
复制代码
示例代码:
//将两个PCollections与Flatten合并PCollectionList<String> collectionList = PCollectionList.of(aCollection).and(bCollection);PCollection<String> mergedCollectionWithFlatten = collectionList .apply(Flatten.<String>pCollections());//继续合并新的PCollectionmergedCollectionWithFlatten.apply(...);
复制代码
结果展示:
合并单词单词有:AggressiveBrilliantApprehensiveBold
复制代码
原示例代码地址 :pipelineTest2_3
4. 合并管道:多个数据源,链接合并一个管道输出
图 2-2-4 多数据源合并输出图
描述:
你的管道可以从一个或多个源读取或输入。如果你的管道从多个源读取并且这些源中的数据相关联,则将输入连接在一起会很有用。在上面的图 2-2-4 所示的示例中,管道从数据库表中读取名称和地址,并从 Kafka 主题中读取名称和订单号。然后管道 CoGroupByKey 用于连接此信息,其中键是名称; 结果 PCollection 包含名称,地址和订单的所有组合。
示例代码:
PCollection<KV<String, String>> userAddress = pipeline.apply(JdbcIO.<KV<String, String>>read()...);PCollection<KV<String, String>> userOrder = pipeline.apply(KafkaIO.<String, String>read()...);final TupleTag<String> addressTag = new TupleTag<String>();final TupleTag<String> orderTag = new TupleTag<String>();// 将集合值合并到CoGbkResult集合中。PCollection<KV<String, CoGbkResult>> joinedCollection = KeyedPCollectionTuple.of(addressTag, userAddress) .and(orderTag, userOrder) .apply(CoGroupByKey.<String>create());joinedCollection.apply(...);
复制代码
管道的设计工具
对于管道的设计不光用代码去实现,也可以用视图工具。现在存在的有两种一种是拓蓝公司出品叫 Talend Big Data Studio,另一种就是免费开源的视图设计工具kettle-beam。
三.怎样创建你的管道
Apache Beam 程序从头到尾就是处理数据的管道。本小节使用 Apache Beam SDK 中的类构建管道,一个完整的 Apache Beam 管道构建流程如下:
首先创建一个 Pipeline 对象。
不管是数据做任何操作,如“ 读取”或“ 创建”及转换都要为管道创建 PCollection 一个或多个的数 据集(PCollection**<String>**)。
在 Apache Beam 的管道中你可以对数据集 PCollection 做任何操作,例如转换数据格式,过滤,分组,分析或以其他方式处理数据中的每一个元素。每个转换都会创建一个新输出数据集 PCollection,当然你可以在处理完成之前进行做任何的转换处理。
把你认为最终处理完成的数据集写或以其他方式输出最终的存储地方。
最后运行管道。
创建管道对象
每一个 Apache Beam 程序都会从创建管道(Pipeline)对象开始。
在 Apache Beam SDK,每一个管道都是一个独立的实体,管道的数据集也都封装着它的数据和对应的数据类型(在 Apache Beam 中有对应的数据转换类型包)。最后把数据进行用于各种转换操作。
在创建的管道的时候需要设置管道选项 PipelineOptions,有两种创建方式第一种是无参数和一种有参数的。具体两种有什么不同呢? 无参数的可以在程序中指定相应的管道选项参数,如显示设置执行大数据引擎参数。有参数的就可以在提交 Apache Beam jar 程序的时候进行用 Shell 脚本的方式后期设置管道对应的参数。
具体示例如下:
无参数
// 首先定义管道的选项PipelineOptions options = PipelineOptionsFactory.create();options.setRunner(DirectRunner.class); //显示设置执行大数据引擎// 创建管道实体对象Pipeline p = Pipeline.create(options);
复制代码
有参数
PipelineOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().create();
复制代码
提交设置参数的格式如下:
将数据读入你的管道
创建 PCollection 的初始值,请读取外部的数据源及指定的本地数据。例如读取数据库,文本文件,流数据等等,现在 Apache Beam java SDKS 支持 33 种数据源,正在接入集成的有 7 种,Python 13 种,正在集成的 1 种。基本覆盖了 IT 行业的一切数据源。例如读取文本数据我们可以用 TextIO.Read 的方法进行读取数据。转换应用于管道对象 p 中。并且返回对应格式的数据集 PCollection:
PCollection<String> lines = p.apply( "ReadLines", TextIO.read().from("/home/inputData.txt"));
复制代码
注意:在 Apache Beam 程序执行中,Beam 程序 2.2.0 以前版本不支持 Windows 如:D\inputData.txt 路径格式。只支持 linux 路径格式,及其他如 HDFS 等存储路径。
已经支持的数据源统计如下表:
| 数据源名称 | Java | Python |
|---|
| Apache HDFS | ✔ | ✔ |
| Amazon S3 | ✔ | |
| Google Cloud Storage | ✔ | ✔ |
| FileIO | ✔ | |
| AvroIO | ✔ | ✔ |
| TextIO | ✔ | ✔ |
| XmlIO | ✔ | |
| TikaIO | ✔ | |
| ParquetIO | ✔ | ✔ |
| RabbitMqIO | ✔ | |
| TFRecordIO | ✔ | ✔ |
| vcfIO | | ✔ |
| SqsIO | ✔ | |
| Amazon Kinesis | ✔ | |
| AMQP | ✔ | |
| Apache Kafka | ✔ | 孵化 |
| Google Cloud Pub/Sub | ✔ | ✔ |
| JMS | ✔ | |
| MQTT | ✔ | |
| Apache Cassandra | ✔ | |
| Apache Hadoop Input/Output Format | ✔ | |
| Apache HBase | ✔ | |
| Apache Hive (HCatalog) | ✔ | |
| Apache Kudu | ✔ | |
| Apache Solr | ✔ | |
| Elasticsearch (v2.x, v5.x, v6.x) | ✔ | |
| Google BigQuery | ✔ | ✔ |
| Google Cloud Bigtable | ✔ | ✔(写) |
| Google Cloud Datastore | ✔ | ✔ |
| Google Cloud Spanner | ✔ | |
| JDBC(mysql,) | ✔ | |
| MongoDB | ✔ | |
| Redis | ✔ | |
| Local filesystems | ✔ | ✔ |
| ClickHouse | ✔ | |
| Apache DistributedLog | 孵化 | |
| Apache Sqoop | 孵化 | |
| Couchbase | 孵化 | |
| InfluxDB | 孵化 | |
| Memcached | 孵化 | |
| Neo4j | 孵化 | |
| RestIO | 孵化 | |
将管道数据转换为处理的格式
很多时候直接从数据源读取的数据不会直接流入目标存储。大部分需要进行数据格式的转换,数据的清洗,数据的过滤,数据的关联处理,数据累加操作等。这里需要对源数据进行处理,处理完成的数据处理流入目标存储外还可以进行当作参数一样,传递并继续应用到管道中。
以下示例代码为 把一串数据通过转换操作赋值给 words , 然后再把 words 再次传递到下一个操作应用,再进一步进行操作的处理工作。
PCollection<String> words = ...;PCollection<String> reversedWords = words.apply(new ReverseWords());
复制代码
编写或输出管道最终输出数据的地方
经过一些列的清洗、过滤、关联、转换处理工作后的数据,最终都会通过 SDKIO 进行写入管道外的存储或着数据库表。然而这种写入操作大部分都是在管道的末尾端进行操作的。
如下面代码示例,就是把管道的数据通过 Apache Beam 中的 TextIO.Write 写入 Linux 的文本文件 test.txt 中。
PCollection<String> filteredWords = ...;filteredWords.apply("WriteMyFile", TextIO.write().to("/home/test.txt"));
复制代码
运行你的管道
构建管道后,使用 run 方法最后执行管道。 管道以异步方式执行的。 写完这一句代码后你就可以把自己的程序用 Jenkins 进行编译并提交给运行管道平台,最终有管道执行平台来运行。
运行代码示例:
处理异步执行的方式,还有同步执行方式,是在 run 方法后面加个看守方法 waitUntilFinish。具体代码如下:
p.run().waitUntilFinish();
复制代码
四.怎样测试你的管道
Apache Beam 管道开发中最后的测试在整个开发中也是非常重要的一个环节。Apache Beam 的代码程序不必要每次都进行远程构建执行到 Flink 集群上,因为管道代码的错误及 Bug 的修改在本地能更好的调试,然而每次构建到远程上面去执行是非常麻烦的事情。Apache Beam 提供 DirectRunner ,一个用于本地测试的执行引擎。
使用 DirectRunner 测试管道的时候,你可以用小规模的数据进行测试。此外你如果开发机器上装了本地的 flink ,也可以指定本地的 Flink 执行。 例如测试一个简单的转换函数 DoFn,符合变换,数据源输入到管道尾端数据输出等操作。
注意点:DirectRunner 是用于管道或 Apache Beam 程序 本地开发调试测试的 数据执行引擎,不可以用于真正生产环境中运行。否则程序执行性能会大大降低,这里有坑要避开。
测试单个 Pipeline 步骤
我们开发完成管道 Beam 程序后需要本地测试,Beam SDK for Java 提供了一种方便的方法来测试TestPipeline的封装类。 在 Beam SDK testing 包中。
它的使用操作方法:
1.创建一个 TestPipeline。
2.创建一些已知的静态测试数据,也称为内存数据,真正应用基本是流或批数据。
3.使用 Create 方法创建 PCollection 输入数据。
4.使用 Apply 方法进行数据的转换处理并且返回指定的 PCollection。
5.最后使用 PAssert 去验证输出的结果是否为预期结果值。
测试实战示例
Apache Beam 中简单的管道单元测试实例。
public class CountTest {// 创建静态的内存数据static final String[] WORDS_ARRAY = new String[] {"hi", "there", "hi", "hi", "sue", "bob","hi", "sue", "", "", "ZOW", "bob", ""};static final List<String> WORDS = Arrays.asList(WORDS_ARRAY);public void testCount() { // 创建一个测试管道. Pipeline p = TestPipeline.create(); // 创建一个输入数据集. PCollection<String> input = p.apply(Create.of(WORDS)).setCoder(StringUtf8Coder.of()); // 添加转换统计单词个数. PCollection<KV<String, Long>> output = input.apply(Count.<String>perElement()); // 验证结果. PAssert.that(output) .containsInAnyOrder( KV.of("hi", 4L), KV.of("there", 1L), KV.of("sue", 2L), KV.of("bob", 2L), KV.of("", 3L), KV.of("ZOW", 1L)); // 运行整个管道. p.run();}
复制代码
端到端的测试管道
端到端的测试,主要针对输入端和输出端两端的测试。要测试整个管道,请执行以下操作:
创建一个 Beam 测试 SDK 中所提供的 TestPipeline 实例。
对于多步骤数据流水线中的每个输入数据源,创建相对应的静态(Static)测试数据集。
使用 Create Transform,将所有的这些静态测试数据集转换成 PCollection 作为输入数据集。
按照真实数据流水线逻辑,调用所有的 Transforms 操作。
在数据流水线中所有应用到 Write Transform 的地方,都使用 PAssert 来替换这个 Write Transform,并且验证输出的结果是否我们期望的结果相匹配
由于端到端测试跟单个 Pipeline 步骤相似就不在举示例代码。其实开发过程中本地调试打断点,写日志测试也是更快解决问题的一个办法。
五. Apache Beam 的管道源码解析
Apache Beam Pipeline 源码解析
管道源代码主类是比较简单的,本文针对 Pipeline.java 进行解析。
1. 定义管道参数及管道创建
在管道创建首先可以定义管道的选项,例如 Beam 作业程序的名称、唯一标识、运行引擎平台等,当然也可以提交引擎平台用命令指定也可以。然后实例化一个管道对象。
源码示例如下:
PipelineOptions options = PipelineOptionsFactory.create();Pipeline p = Pipeline.create(options);
复制代码
2. 读取数据源
读取要处理的数据,有文本数据,结构化数据和非结构化数据以及流数据。作为数据处理的源数据。
源码示例如下:
PCollection<String> lines = p.apply(TextIO.read().from("gs://bucket/dir/file*.txt"));
复制代码
3. 进行数据处理操作
在管道里面可以进行窗口操作、函数操作、原子操作以及 SQL 操作。
数据统计的源码示例:
PCollection<KV<String, Integer>> wordCounts =allLines.apply(ParDo.of(new ExtractWords())).apply(new Count<String>());
复制代码
4. 输出结果及运行
源代码示例:
PCollection<String> formattedWordCounts = wordCounts.apply(ParDo.of(new FormatCounts())); formattedWordCounts.apply(TextIO.write().to("gs://bucket/dir/counts.txt"));p.run();
复制代码
六.管道实战案例
案例场景描述
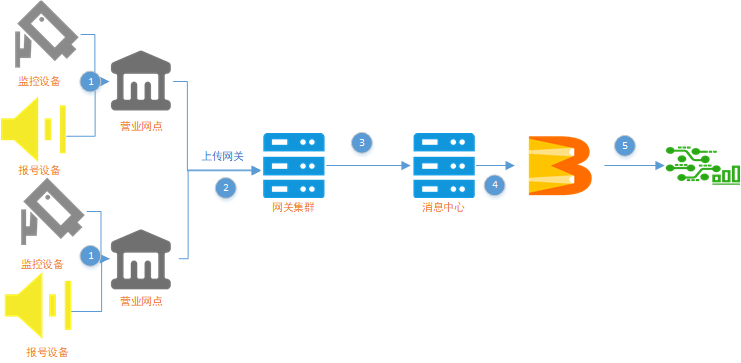
随着人工智能 的不断发展,AI Cloud 在银行加快落地,安防 AI 碎片化的应用场景遍地开花。本文结合银行营业网点的业务,介绍管道案例实战。
以银行的员工脱离岗检测中的行为分析数据预处理为例。我们去银行办理业务过程中,首先要取号,然后叫号。叫号提示会对接系统形成一条消息回传后台,但是有时候正常办理业务期间有柜台营业员出去,然后很久才回来。这个时候摄像头会根据柜台离岗时间自动 AI 行为分析生成报警处理。
案例业务架构流程
叫号报警和行为分析报警产生的数据通过营业网点进行上报。
上传网关集群,网关集群进行转换消息格式压缩消息。
消息流入消息中心等待消费,消息中心再次起着消峰作用。
用 Beam 管道的时间窗口特性、流合并处理特性进行消息消费处理
消息进入大数据实时分析处理平台处理应用消息。
案例示例核心代码
1. 本案例为了节约阅读时间,采用静态数据
// 创建管道工厂 PipelineOptions options = PipelineOptionsFactory.create(); // 显式指定PipelineRunner:FlinkRunner必须指定如果不制定则为本地 options.setRunner(DirectRunner.class); // 生产环境关闭 // options.setRunner(FlinkRunner.class); //生成环境打开 Pipeline pipeline = Pipeline.create(options);// 设置相关管道 // 为了演示显示内存数据集 // 叫号数据 final List<KV<String, String>> txtnoticelist = Arrays.asList(KV.of("DS-2CD2326FWDA3-I", "101号顾客请到3号柜台"), KV.of("DS-2CD2T26FDWDA3-IS", "102号顾客请到1号柜台"),KV.of("DS-2CD6984F-IHS", "103号顾客请到4号柜台"), KV.of("DS-2CD7627HWD-LZS", "104号顾客请到2号柜台")); //AI行为分析消息 final List<KV<String, String>> aimessagelist = Arrays.asList(KV.of("DS-2CD2326FWDA3-I", "CMOS智能半球网络摄像机,山东省济南市解放路支行3号柜,type=2,display_image=no"),KV.of("DS-2CD2T26FDWDA3-IS", "CMOS智能筒型网络摄像机,山东省济南市甸柳庄支行1号柜台,type=2,display_image=no"),KV.of("DS-2CD6984F-IHS", "星光级全景拼接网络摄像机,山东省济南市市中区支行4号柜台,type=2,display_image=no"), KV.of("DS-2CD7627HWD-LZS", "全结构化摄像机,山东省济南市市中区支行2号柜台,type=2,display_image=no")); PCollection<KV<String, String>> notice = pipeline.apply("CreateEmails", Create.of(txtnoticelist)); PCollection<KV<String, String>> message = pipeline.apply("CreatePhones", Create.of(aimessagelist)); final TupleTag<String> noticeTag = new TupleTag<>(); final TupleTag<String> messageTag = new TupleTag<>(); PCollection<KV<String, CoGbkResult>> results = KeyedPCollectionTuple.of(noticeTag, notice).and(messageTag, message).apply(CoGroupByKey.create()); System.out.append("合并分组后的结果:\r"); PCollection<String> contactLines = results.apply(ParDo.of(new DoFn<KV<String, CoGbkResult>, String>() { private static final long serialVersionUID = 1L; @ProcessElement public void processElement(ProcessContext c) { KV<String, CoGbkResult> e = c.element(); String name = e.getKey(); Iterable<String> emailsIter = e.getValue().getAll(noticeTag); Iterable<String> phonesIter = e.getValue().getAll(messageTag); System.out.append("" + name + ";" + emailsIter + ";" + phonesIter + ";" + "\r"); } })); pipeline.run().waitUntilFinish();
复制代码
2. 测试运行结果
源码地址:pipelineTest2_5.java
七.小结
近几年随着 AloT 发展得如火如荼,其落地场景也遍地开花。loT 作为 AI 落地先锋,已经步入线下各行各业。本文以 Beam 管道的设计切入,重点对 Beam 管道设计工具和源码进行解析,最后结合银行金融行业对 AI 碎片化的场景进行数据预处理的案例,帮助大家全面了解 Beam 管道。
作者介绍
张海涛,目前就职于海康威视云基础平台,负责海康威视在全国金融行业 AI 大数据落地的基础架构设计和中间件的开发,专注 AI 大数据方向。Apache Beam 中文社区发起人之一,如果想进一步了解最新 Apache Beam 和 ClickHouse 动态和技术研究成果,请加微信 cyrjkj 入群共同研究和运用。
系列文章传送门:
















评论