

本文最初发表在 Medium 博客,经原作者 Marco Cerliani 授权,InfoQ 中文站翻译并分享。
本文介绍了在模型中插入 Transformer 的不同方法。
人们对自然语言处理的不断研究催生了各种预训练模型的发展。在各种任务(如文本分类、无监督的主题建模和问题解答等)的最新结果方面,通常都有越来越多的改进,这是一个典型的现象。
最大的发现之一是在神经网络架构中采用了注意力机制(attention mechanics)。这种技术是所有称为 Transformer 的网络的基础。它们应用注意力机制来提取关于给定单词上下文的信息,然后将其编码到学习向量中。
作为数据科学家,我们可以产生并使用许多 Transformer 架构来对我们的任务进行预测或微调。在本文中,我们尽情享受经典的 BERT,但同样的推理也可以应用到其他所有的 Transformer 架构中。我们的研究范围是在双(dual)架构和孪生(siamese)架构中使用 BERT,而不是将其作为多文本输入分类的单一特征提取器。
数据
我们从 Kaggle 收集了一个数据集:News Category Dataset(新闻分类数据),它包含了 2012 年到 2018 年从 HuffPost 获得的大约 20 万条新闻标题。我们的范围是根据两种不同的文本来源对新闻文章进行分类:标题和简短描述。总共有 40 多条不同类型的新闻。为简单起见,并考虑到我们工作流的计算时间,因此我们只使用了 8 个类的子组。
我们不应用任何种类的预处理清晰;我们要让 BERT 来“完成所有的魔法”。我们的工作框架是 TensorFlow 和强大的 Huggingface Transformer 库。更详细地说,我们利用“裸”BERT 模型 Transformer,它输出原始的隐藏状态,而且上面没有任何特定头。它可以像 TensorFlow 模型子类一样访问,并且可以很容易地将其引入我们的网络架构中进行微调。
单 BERT
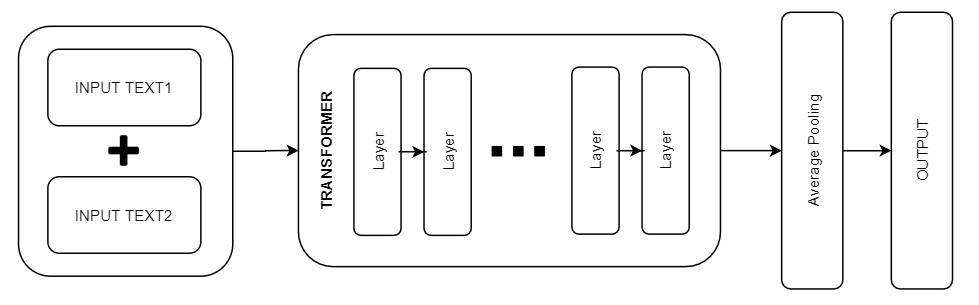
作为第一个竞争者,我们引入了一个单 BERT 架构。它只接受一个文本输入,这是我们两个文本源连接的结果。这就是常态:任何模型都可以接受连接特性的输入。对于 Transformer 来说,将输入与特殊特征符(special tokens)相结合提升了这一过程。
BERT 需要特定格式的输入数据:有特殊的特征符来标记句子/文本源的开头([CLS] [SEP])。同时,标记化涉及到将输入文本分割成词汇库中可用的特征符列表。词汇表外的单词用 WordPiece 技术进行处理;其中一个单词被逐步拆分成属于词汇表的子词。这一过程可以通过 Huggingface 预训练的词法分析器(Tokenizer)轻松完成,我们只需注意做好 padding 即可。
我们以每个文本源的三个矩阵(token、mask、sequence id)结束。它们作为 Transformer 的输入。在单 BERT 的情况下,我们只有一个矩阵元祖。这是因为我们同时将两个文本序列传递给词法分析器,这两个文本序列会自动连接起来(用 [SEP] 标记)。
我们的模型架构非常简单:将上面构建的矩阵直接馈入 Transformer。最后,通过平均池操作减少了 Transformer 的最终隐藏状态。概率分数是由最后致密层计算出来的。
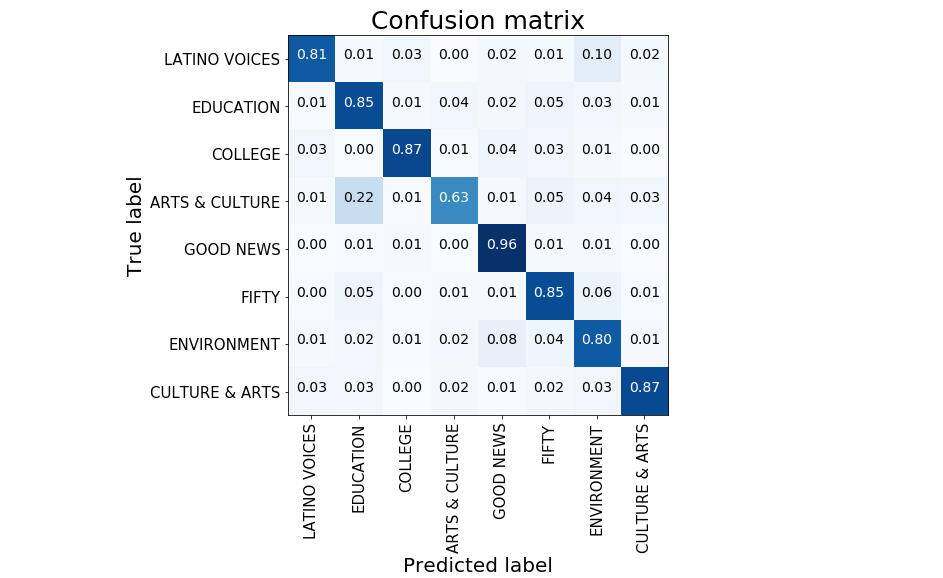
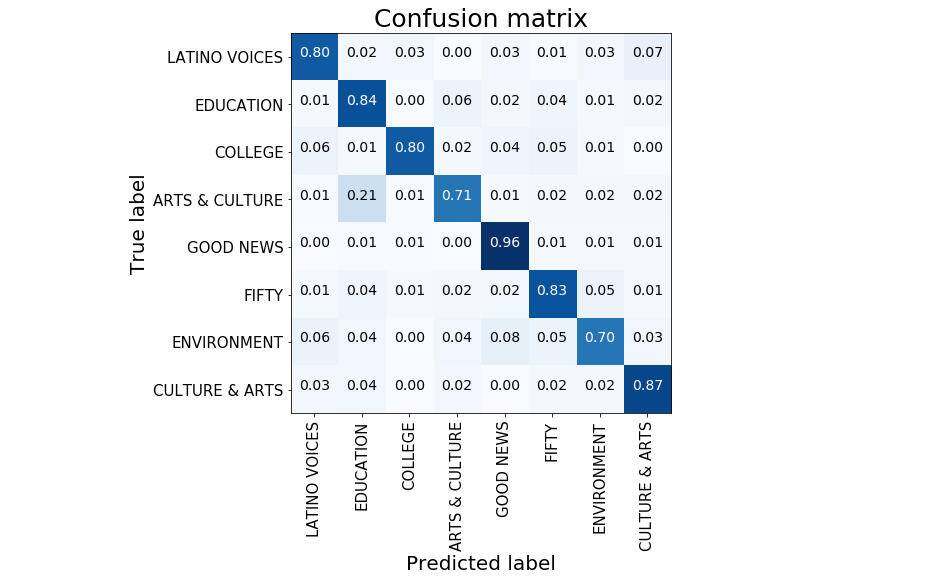
在我们的测试数据上,我们的单 BERT 达到了 83% 的准确率。性能报告请见下面的混淆矩阵中。
双 BERT
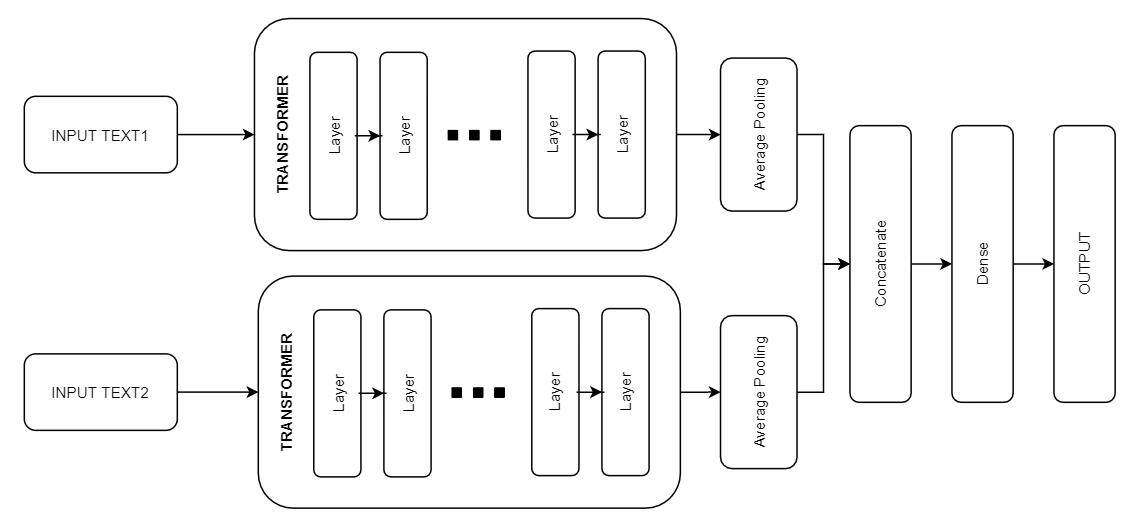
我们的第二个架构可以定义为双 BERT,因为它使用了两个不同的 Transformer。它们有相同的组成,但使用了不同的输入进行训练。第一个 Transformer 接收新闻标题,而另一个接受简短文本描述。输入被编码为始终产生两个矩阵(token、mask 和 sequence id),每个输入都有一个。对于这两个数据源,我们的 Transformer 的最终隐藏状态都是通过平均池来减少的。它们链接在一起,并通过一个完全连接层。
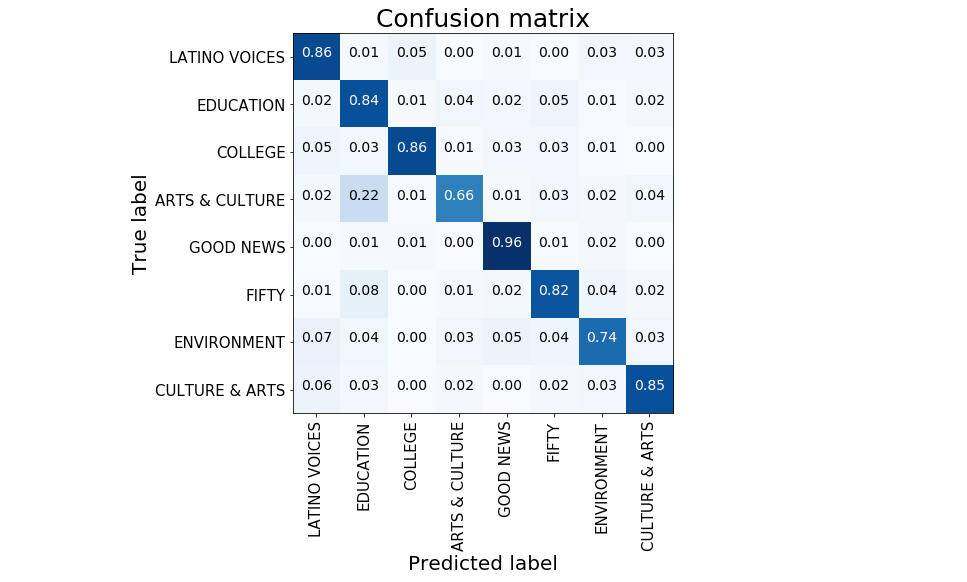
通过这些设置,双 BERT 测试数据上可以在达到 84% 的准确率。
孪生 BERT
我们的最后一种模型是一种孪生式架构。它可以这样定义,因为两个不同的数据源在同一个可训练的 Transformer 架构中同时传递。输入矩阵与双 BERT 的情况相同。对于两个数据源,我们的 Transformer 的最终隐藏状态是通过平均操作进行池化的。所得到的的结果,在一个完全连接层中传递,该层将它们进行组合并产生概率分数。
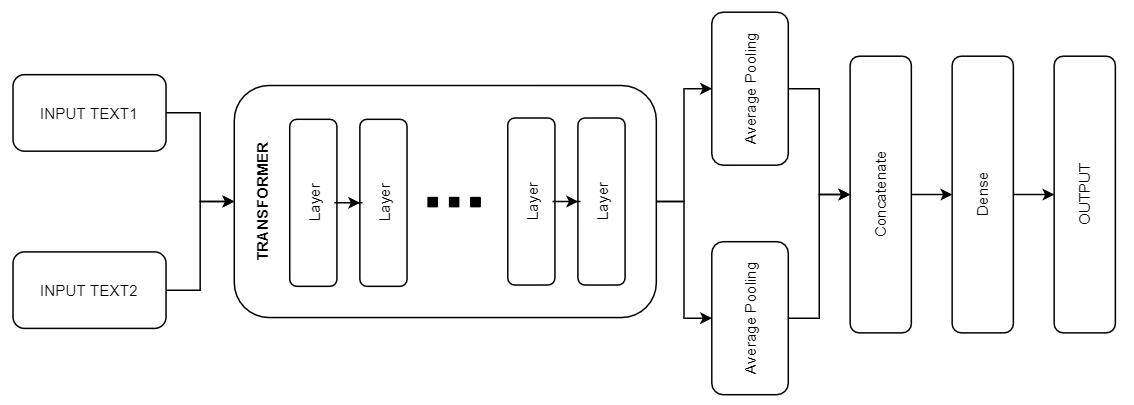
在我们的测试数据上,孪生式架构达到了 82% 的准确率。
总结
在本文中,我们应用 BERT 架构进行了多类分类任务。我们这个实验的附加价值在于,它以各种方式使用 Transformer 来处理多个输入源。我们从一个源中的所有输入的经典连接开始,然后在输入模型时保持文本输入的分离。提出的双 BERT 和孪生变体能够获得良好的性能。因此,它们可以被认为是经典单 Transformer 架构的良好替代方案。
参考资料
Kaggle: Two BERTs are better than one
Kaggle: Bert-base TF2.0
作者介绍:
Marco Cerliani,Lutech 统计学家、黑客和数据科学家。
原文链接:
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论