

导读: 前不久,滴滴 ES 团队将维护的 30 多个 ES 集群,3500 多个 ES 节点,8PB 的数据,从 2.3.3 跨大版本无缝升级到 6.6.1。在对用户查询写入基本零影响和改动的前提下,解决了 ES 跨大版本协议不兼容、文件格式不兼容、mapping 不兼容等难题,整个过程对绝大部分用户完全透明。同时还完成了 Arius 的架构升级,取得了单机查询性能提升 40%,整体集群 cpu 下降 10%,写入 tps 提升 30%,集群资源使用率提升 20%、0 故障、运维成本下降 60%的成绩。
本文将系统的介绍滴滴在从 2.3.3 跨大版本升级到 6.6.1 过程中的遇到的问题和解决方案,以及在搜索平台建设过程中的体系化思考。
01 背景介绍
1. 集群规模

目前滴滴使用的 ES 版本是 2.3.3,集群个数有 40 多个,节点规模有 3500+,集群总容量有 8PB。
2. 业务规模

1200 多个平台应用方在使用 ES,30 多个核心应用在使用 ES,写入的 TPS 有 1500W,查询的 QPS 有 25W。
02 问题分析
针对以上规模的 ES 集群,从 2.3.3 升级到 6.X 版本,小版本会根据最后分析的结果确定,需要对潜在可能的问题进行分析和区分。
1. 问题分析
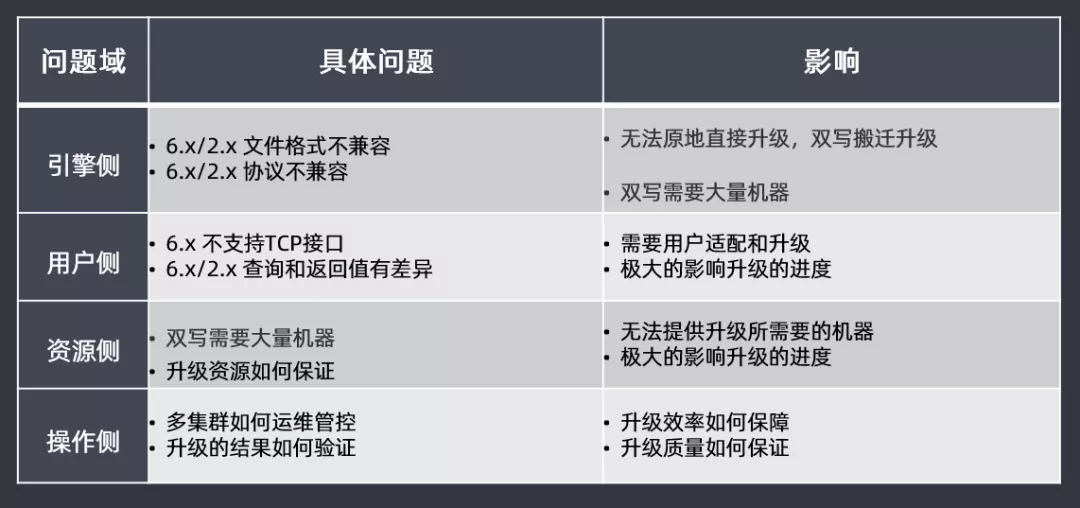
主要先从四大问题域进行区分分析:
引擎侧:由于从2.3.3升级到6.X版本,版本差距过大,在文件格式和协议上都不兼容,因此无法进行原地滚动直接升级,需要双写搬迁升级,这样会耗费大量的机器去参与其中
用户侧:6.X版本开始逐渐的不支持TCP接口,因此需要用户适配和升级;查询和返回值也有一定差异,如果用户侧做适配,会极大影响升级的进度
资源侧:由于无法直接原地滚动直接升级,需要双写使用大量的机器,但是无法提供升级所需要的机器,如果升级过程中资源无法得到保障,那也会极大影响升级的进度
操作侧:新版本的多集群如何进行运维管控?升级的结果如何验证?查询的效率和质量如何保障和保证的?这些问题都需要考虑
2. 升级思路
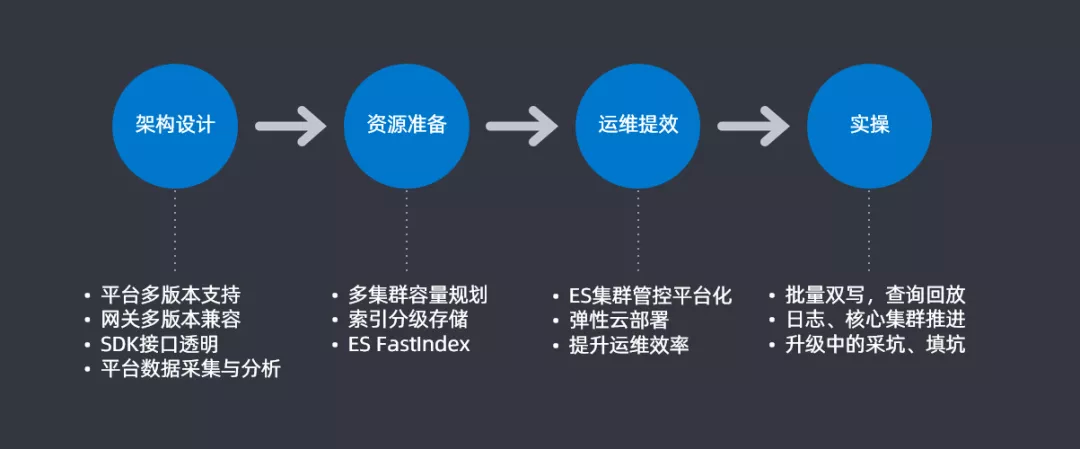
根据上一部分问题的汇总和分类,形成了一个大致的升级思路并会根据这四大步骤来解决具体的问题。
架构设计:平台支持多版本支持,查询网关上进行多版本兼容,在查询和插入使用SDK时候要做到SDK接口的透明,最后要做一个平台数据采集和分析用于后续做升级的分析对比
资源准备:进行合理的多集群容量规划来提高资源使用率,尽可能的节省机器;设计索引分级存储来提升资源的利用率;还针对大索引迁移开发了一个插件FastIndex也用来提升资源利用率
运维绩效:开发ES集群管控平台,将ES集群管控平台化和图表化;通过Docker的方式来提升部署和运维的效率
实操:在实际操作中,需要实现批量双写以及查询回放的功能;需要对业务进行区分,实现日志和核心集群的分步推进;最后就是升级过程中会遇到一些坑,需要把坑都填满,后续会详细介绍一下这些坑
3. 升级方案

上面是升级思路,接下来介绍一下升级方案:
架构:ES多版本支持的架构改造,同时支持2.3.3以及6.X版本;开发一套多集群管控平台,用于滴滴内部ES多个集群的管控;同时还开发了一套ES服务元数据体系建设
资源:设计ES分级存储体系;开发ES-FastIndex离线数据导入的插件;最后构建了一套ES集群容量规划方案来提升集群的资源使用率,节约资源成本
实操:通过ES多集群搭建、ES流量回放对比系统、ES版本升级采坑分享来完成升级和对比的一个过程
03 方案介绍
1. 架构
① 架构重构
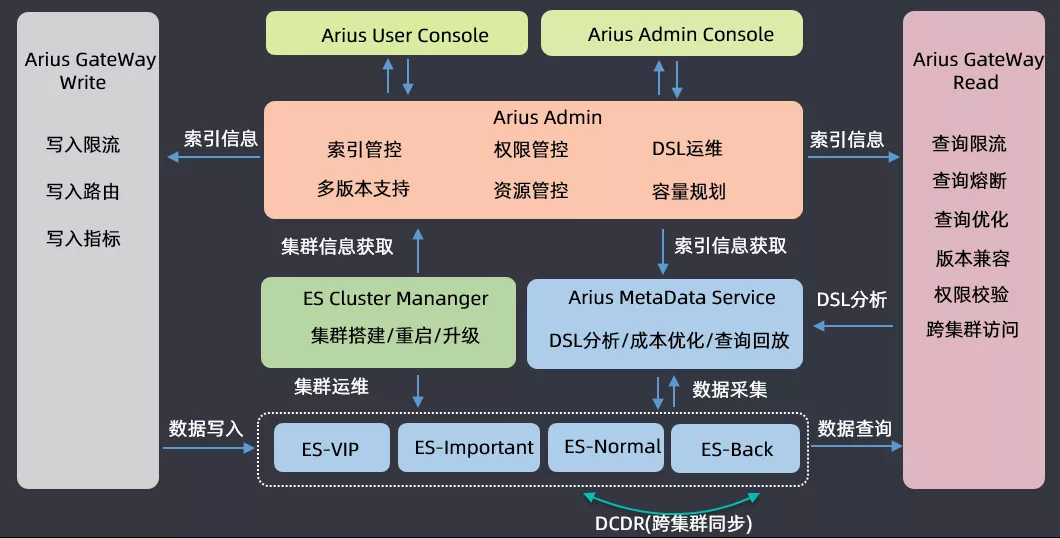
介绍一下滴滴搜索平台(Arius)的架构,业务方使用 ES 搜索进行读写请求时都会经过网关;运维的时候会根据集群的重要程度进行划分,会将四十多个集群划分为 VIP、Important、Normal、Backup 四类,开发了一个 DCDR 工具用于跨集群的数据同步;在 ES 集群运维之上开发了三大组件,一个是 ES Cluster Manager,用于集群的搭建、重启和升级混合操作的平台;第二个是集群 ES 的数据分析构建了一个 Arius Metadata Service 的元数据管理服务,用于做 DSL 分析、成本优化和查询回放;在这两个系统之上有一套 Arius Admin 管控系统,包含索引管控、权限管控、DSL 运维、多版本支持、资源管控以及容量规划等功能;基于 Arius Admin,构建了两套面向运维和用户的管控平台前端工程。
以上就是滴滴搜索平台的整体架构,然后基于此来做 ES 的版本升级。
② 升级流程
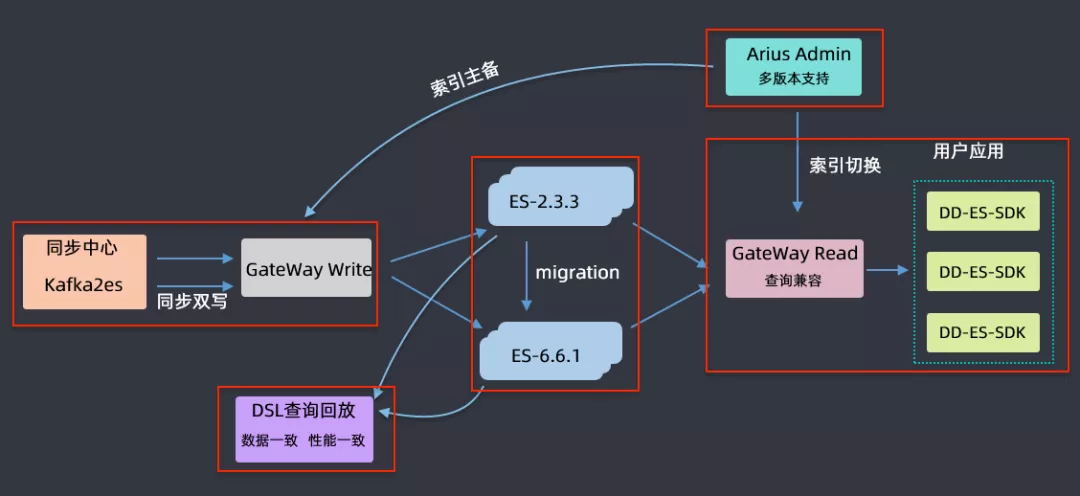
上图为升级的流程,首先是要升级对 ES 集群的管控,要支持 2.3.3 和 6.6.1 两个版本;对每个要升级的索引要进行主备索引的创建,创建完毕后通过双写的形式对主和备都同时写入到新的索引中,对于历史索引采取的是这样一个策略:在双写之前,主备创建之后,会暂停历史数据的写入,把历史数据通过 migration 的方式从低版本迁移到高版本中,迁移完后再进行双写;在迁移完成,双写链路打开之后,做一个 DSL 数据回放,由于用户的读写都是通过 gateway 进行的,所以可以拿到用户的 DSL 语句和返回数据来进行一个高低版本的查询、对比和分析,如果最后比对结果是数据一致、性能也一致,那就认为该索引在高低版本中迁移是成功的。如果迁移成功,会在网关层完成用户查询的向高版本的切换,如果切换完成后,业务方运行没有问题就会将低版本的索引下线掉,最终就完成了索引由低版本向高版本升级的过程。
③ GateWay 兼容性
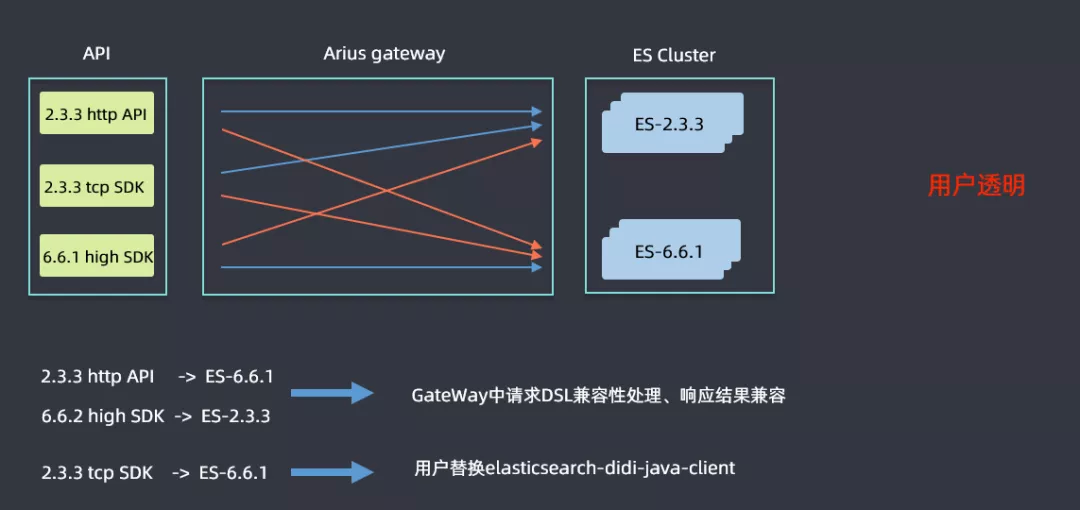
升级是一个比较漫长的过程,高低版本集群会并行运行一段时间,用户使用的 SDK 也会高低版本共存,这样就需要解决高低版本兼容性的问题。查询可能会分为上图六条线标识的六种情况,蓝色线表明不需要进行改造直接进行查询的,2.3.3 的 http 和 tcp sdk 查询 2.3.3ES 集群,6.6.1 high sdk 查询 6.6.1 的 ES 集群都是没有问题的;红色线表明是需要考虑兼容性问题进行改造的,例如 2.3.3 的 sdk 查询 6.6.1 的 ES 集群时候语法的差异性问题等,然后 ES 高版本中会逐渐取消掉 tcp 的查询接口,但是滴滴内部还是有很多用户是使用 tcp 方式查询的,如果需要用户进行代码改造的话流程会非常漫长,因此在 Gateway 层面做了一些兼容性处理:在 2.3.3http api 和 6.6.1 high sdk 查询 6.6.1 集群和 2.3.3 集群时候,做了请求 DSL 的兼容性处理和响应结果兼容,解决了用户的痛点;对于使用 tcp 方式查询的用户,开发了一个 elasticsearch-didi-java-client 的 sdk,用户替换一下 pom 即可,表面上还是使用 tcp 的方式,但是在网关层面已经将其转换为了 http 查询的方式。这样就做到了用户透明。
④ ES 集群管控平台
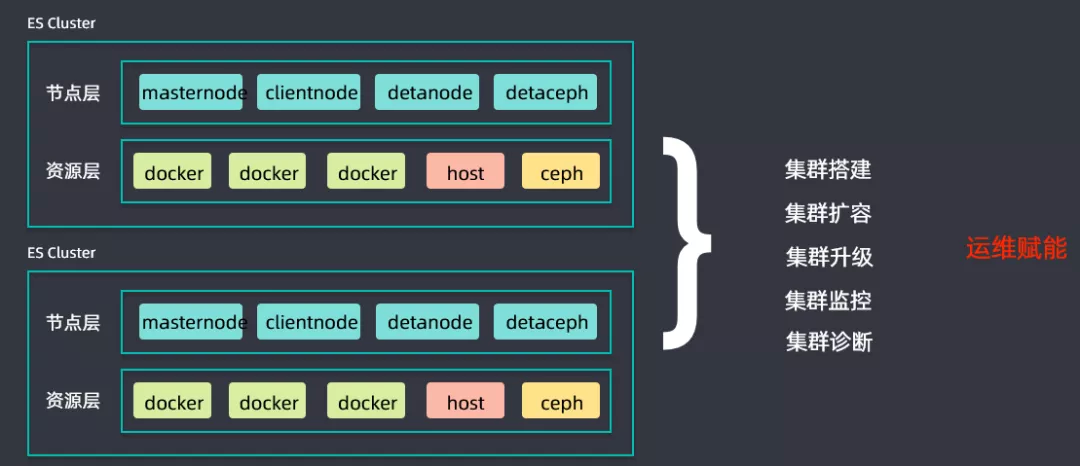
同时搭建了一套 ES 集群管控平台,用于进行集群搭建、集群扩容、集群升级、集群监控以及集群诊断等工作,为升级过程中的运维赋能,提升升级推进进度。
⑤ 元数据服务
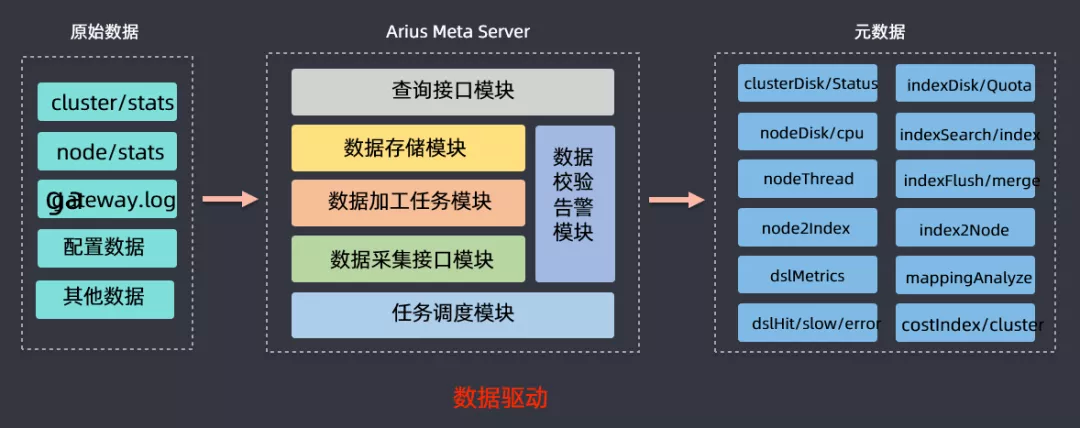
前面介绍的时候有讲到元数据服务,该模块的作用就是提供一个 ES 集群和业务方的数据的分析,然后获取 cluster/stats、node/stats、日志、监控数据等信息进行分析,最后可以得到节点磁盘使用状况、DSL 查询情况(慢查、错误查询),基于此来做容量规划、分级存储、查询回放等数据驱动型工作。
⑥ DSL 服务
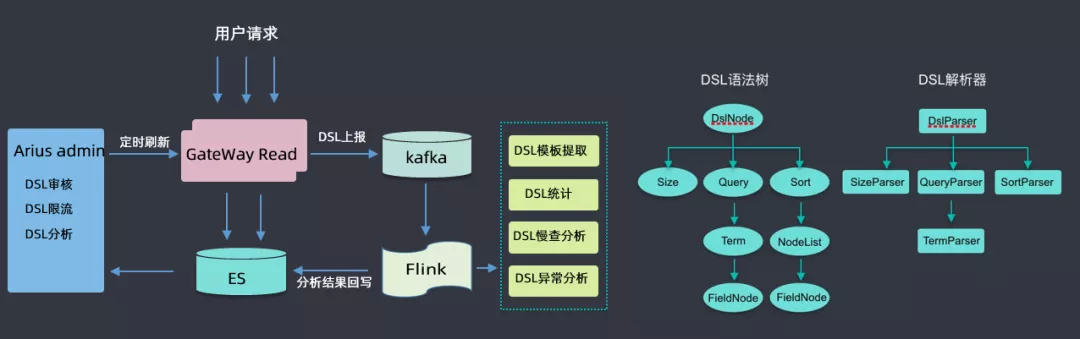
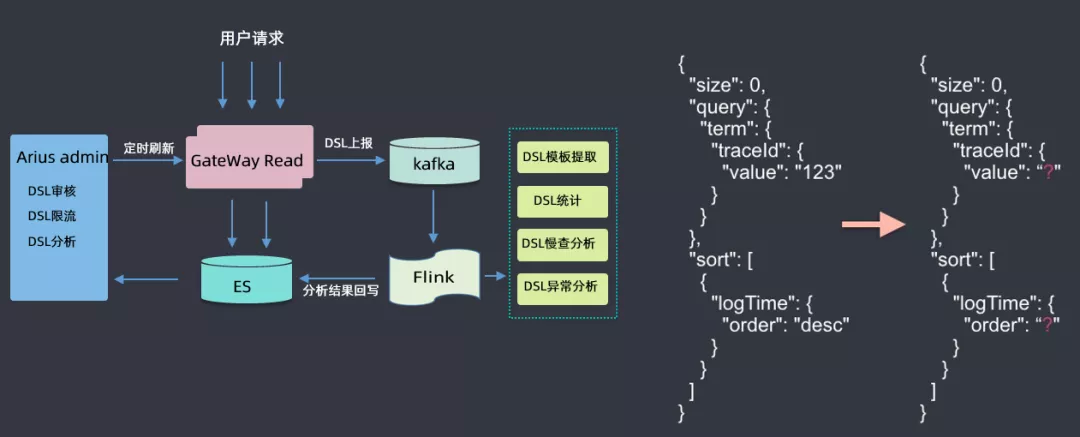
此处着重介绍一下 DSL 服务,用户所有请求都会通过网关,经过网关时会收集到 kafka,然后用 flink 做一些分析,如 DSL 模板提取(具体查询参数去掉,抽象为模板)、DSL 统计、DSL 慢查分析、DSL 异常分析等,然后将分析结果回写到 ES 集群中;然后根据这些分析的数据来做 DSL 审核(用户可能会查询滴滴的核心索引,此处需要审核才能查询)、DSL 限流(有的 DSL 里面会有大量的聚合查询,此处会进行一定限流)、DSL 分析(首先会对 DSL 语句进行语法树的解析,解析后会生成一个无参的查询模板)等。
2. 资源
① 容量规划
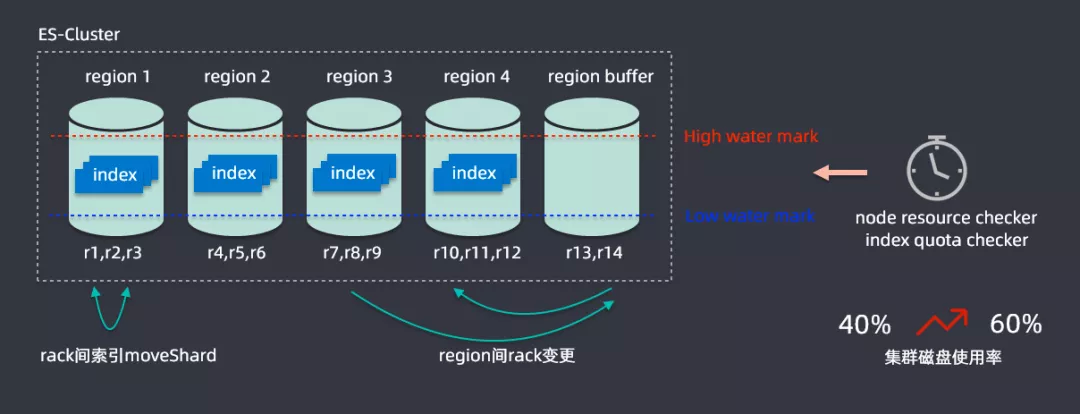
接下来将一些如何在升级过程中解决资源问题,为此开发了一个容量规划的算法,ES 缺乏一个多节点之间索引均匀分布的功能;在滴滴内部最大的集群是在两百多个节点,承载容量在 PB 级别,索引有上千个,在写入索引时候可能流量分布式不均匀的,很有可能有索引节点的热点存在。
解决思路为将两百多个节点进行划分为五个 region,一个 region 都会有很多节点组成,如 r1、r2、r3 组成,划分之后就可以计算每个 region 中节点磁盘的使用情况,设置一个高水位线和低水位线,通过分析每个 region 的数据情况,region 超过高水位就会通过 rack 变更进行扩容,region 内部会监控不同节点的使用情况,通过 rack 建索引 mockShard 进行均衡,从而整体提升资源利用率,通过该算法后集群磁盘的使用率从百分之四十提升到百分之六十,这样就节省了大量的资源。
② 分级存储
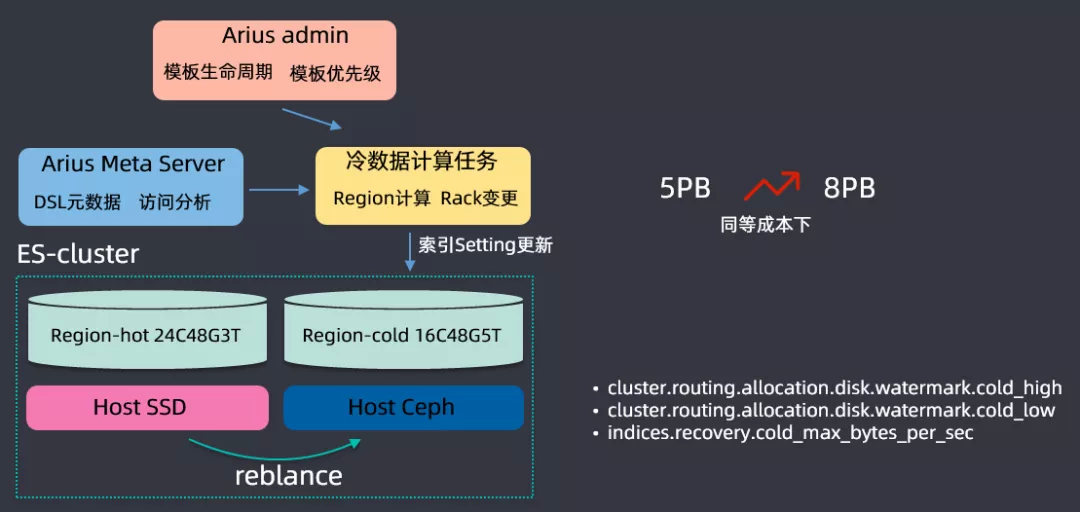
基于用户查询和保存的操作进行一个数据分析,开发了一个 ES 分级存储的体系,搭建 ES 集群时候主要基于两种磁盘进行搭建的,一种是 SSD 磁盘,另一种是 Ceph(可以理解为 HDD 磁盘组成的网络磁盘);SSD 磁盘非常贵,但是查询性能特别好,会存储一些查询频繁的数据,Ceph 磁盘比较便宜,但是查询 IO 性能比较低,存储查询不是那么频繁的数据;根据用户查询的频率,将数据区分为冷数据和热数据,根绝查询的 DSL 来分析索引的保留期限,在滴滴内部基本上索引都是按天保存的(举个例子:日志都是按天建索引保存的),三天之内的放到 SSD 上保存,三天之前的数据会放到 Ceph 上存储,这样可以大量存储的成本,同等成本情况下,把集群存储容量从 5PB 提升到了 8PB。
在分级存储之上,还开发了一些特性,专门开发了 high level 和 low level 的水位线,这是基于冷存和热存系统消耗是不一样的,冷存的时候 high level 可能会更高一点,以上就是分级存储的内容。
③ FastIndex
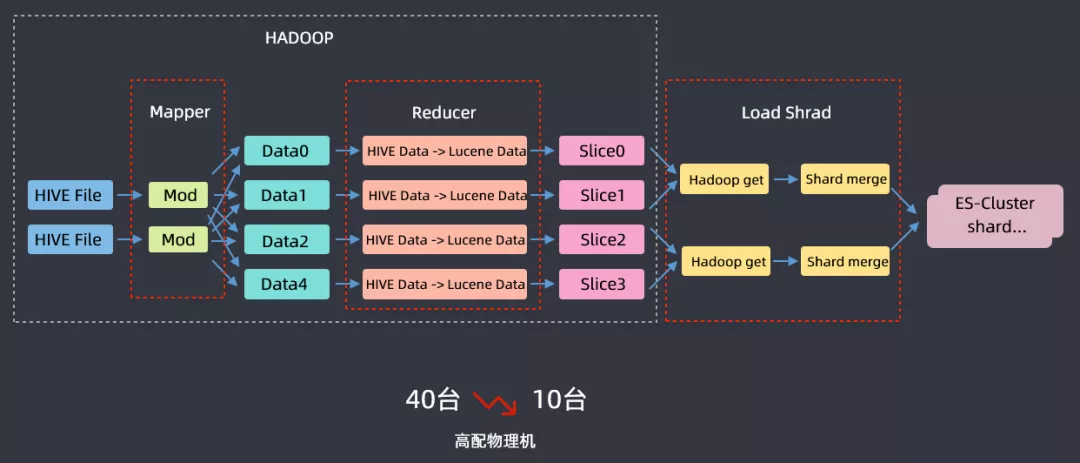
另外还为离线数据导入 ES 开发了一个 FastIIndex 的组件,该组件开发主要是基于滴滴内部用于分析乘客的标签系统,从离线系统导入 ES 集群而开发的;标签系统每天都会重新计算,数据总量在 40TB 左右,原始数据在 hadoop 上,计算好之后通过 kafka 然后实时链路写入到 ES,以前把 40TB 数据导入到 ES 需要 40 台高配物理机,基于这样一个案例开发了 FastIndex 组件,利用 hive 进行一个 mapreduce 的过程,在 reduce 阶段使用 FastIndex 组件启用 ES local 这样的模式将数据写到 lucene data 中,然后再把 lucene 文件加载到 ES 集群中,这样就完成了把离线数据导入 ES 集群的操作,资源从 40 台下降到 10 台高配物理机,时间也从 6 小时下降到 1.5 小时,节省了大量的成本。
3. 升级
① 查询回放
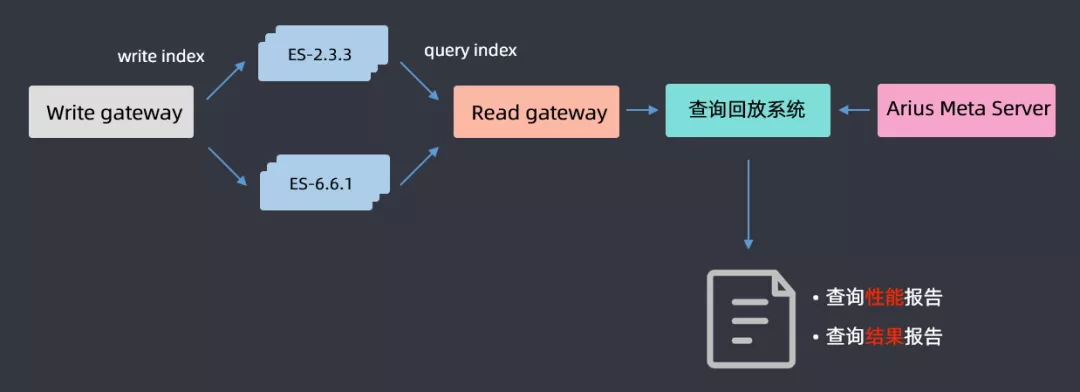
机器资源优化好了之后,开始升级,升级过程前面有讲过了,这里主要介绍一下查询回放流程,因为要保证升级后对用户的查询是没有影响的;基于 gateway 网关层 DSL 的分析,将用户查询的 DSL 全部在高低版本上进行一个回放,最后得出一份查询性能报告和查询结果报告,通过分析两篇报告,如果是一致的就认为升级完成;如果不一致,就分析 2.3.3 和 6.6.1 哪些查询导致的问题,然后做兼容性适配,适配完成后再进行查询回放,循环往复直至最后所有的报告都一致,这样就认为 ES 集群升级成功。
② 采坑
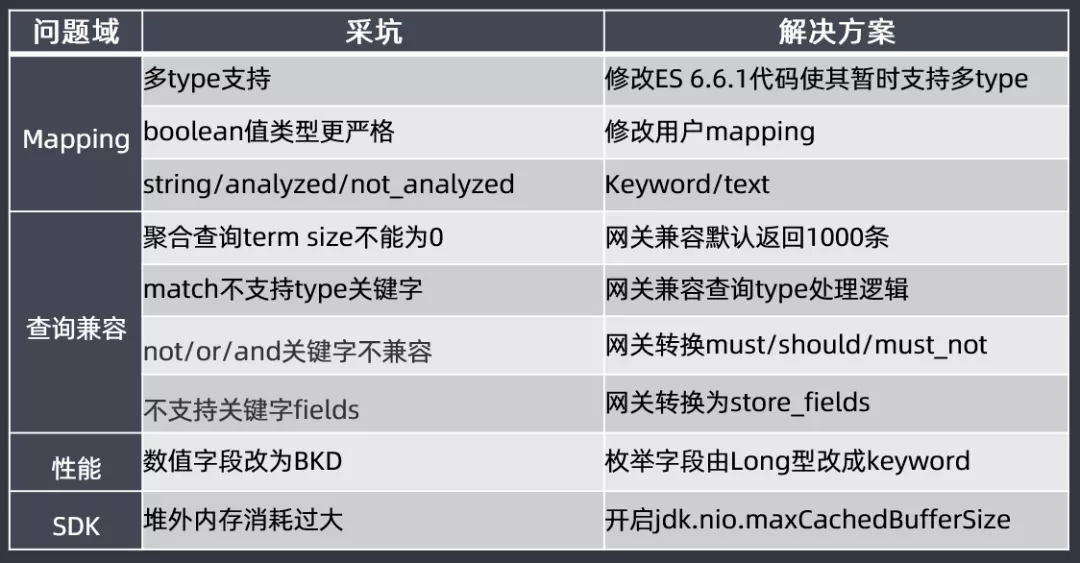
接下来介绍一下升级过程中遇到的坑:
Mapping:选择6.6.1的理由是代码里面暂时还是支持多type的;还有就是布尔类型数据的兼容,分词不分词的mapping修改,这些内容都会提前帮助用户修改好mapping。
查询兼容:聚合查询term size不能为0,网关兼容默认返回1000条;match不支持type关键字,网关兼容查询type处理逻辑;not/or/and关键字不兼容,网关转换must/should/must_not;不支持关键字fields,网关转换为store_fields
性能:数值字段改为BKD,枚举字段会从Long类型改为keyword类型;否则long类型在BKD查询时候还有问题的
SDK:使用高版本ES会有堆外内存消耗过大的问题,需要开启jdk,nio.maxCachedBudderSize参数来保障堆外内存不会消耗过大。
04 升级收益
1. 平台升级
构建了一个完善的管控的平台,大大降低了使用成本。
2. 成本下降
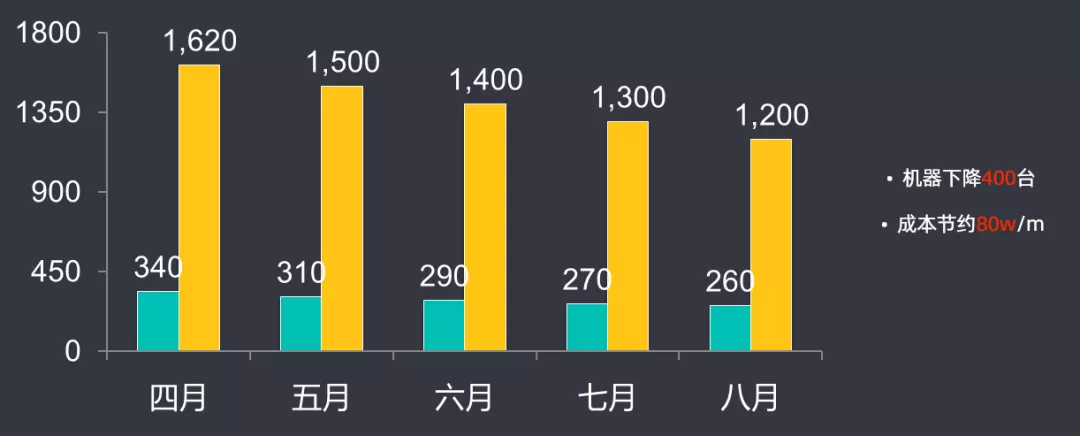
机器数量下降了 400 台,每月成本节约了 80 万左右。
3. 性能提升
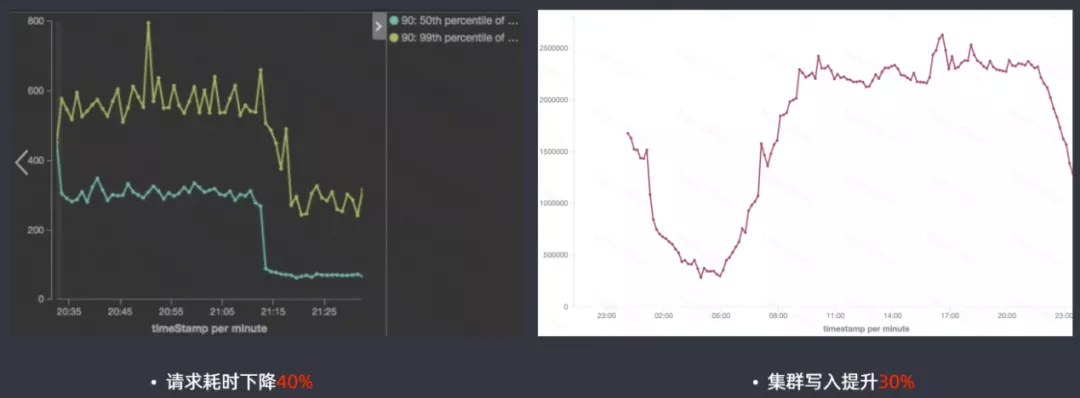
高版本的 ES 查询性能提升还是很明显的,请求耗时下降 40%,集群写入提升 30%。
4. 特性应用
使用了高版本特性带来的一些优势:
Sequence Number提升了集群升级速度
Ingest Node索引模板和限流从网关层下放到引擎层
DCDR滴滴跨集群数据同步,相比CCR性能提升2倍
Cluster reroute冷热节点shard搬迁更均匀
Cluster allocation explain降低集群状态运维成本
05 总结与展望
1. 总结

针对搜索平台进行大版本的升级时,一定要做到:
架构要可控:服务化(网关服务、管控服务、元数据服务、FastIndex服务)、高内聚、一定优先保证稳定性
平台要易用:平台化、自动化、可视化
成本要低廉:数据驱动、技术改造、业务配合
引擎要深入:深入理解版本差异、深入理解ES原理、深入定位问题根因
2. 规划

最后对滴滴搜索平台做一个整体的规划:
更大的集群:在滴滴现有的目前40多个集群的规模下,做得更大,由于master元数据管理的限制导致对集群的管控是无法做到非常大的,目前滴滴希望做到单集群支持50万下载、1500节点的支撑;同时需要做好多租户能力的支持
更易用的平台:ES云平台建设、ES专家服务
更强的引擎:CBO/RBO查询优化、提升写入性能
更多的贡献:加强和开源社区的互动、深入引擎开发
今天的分享就到这里,谢谢大家。
作者介绍:
赵情融,滴滴出行专家工程师
2018 年加入滴滴,负责滴滴搜索平台建设工作,曾在阿里工作多年,有丰富平台建设经验。
本文来自 DataFunTalk
原文链接:
滴滴 Elasticsearch 集群跨版本升级与平台重构之路

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论