

人工智能领域存在着工业界与学术界的分别,近年来,随着AI高速发展,在这两个不同的世界里,分别发生了哪些大事件?作为一家以安全为主要业务的企业,360又是如何在人工智能时代发挥作用?本期北大公开课请到了360副总裁,首席科学家,人工智能研究院院长颜水成教授,他将从AI观察者和实践者两个角度谈谈他对人工智能领域的洞察。
北京大学最受欢迎的 AI 公开课“人工智能前沿与产业趋势”于 2019 年 2 月 20 日正式开课。本学期的课程邀请到了商汤科技副总裁沈徽、驭势科技 CEO 吴甘沙、微软亚洲研究院副院长周明、360 人工智能研究院院长颜水成、YC 中国创始人及 CEO、百度集团副董事长陆奇等 14 位来自产业界的大咖进行授课,AI 前线作为 独家合作媒体 将全程跟进并对北大这 14 场公开课进行整理,敬请关注!

课程导师:雷鸣, 天使投资人,百度创始七剑客之一,酷我音乐创始人,北大信科人工智能创新中心主任,2000 年获得北京大学计算机硕士学位,2005 年获得斯坦福商学院 MBA 学位。

特邀讲师:颜水成,360 集团副总裁,360 人工智能研究院院长,IEEE Fellow、IAPR Fellow 及 ACM 杰出科学家。他的主要研究领域是计算机视觉、机器学习与多媒体分析,发表 600+篇高质量学术论文,论文引用过 4 万次,H-index 94。2014、2015、 2016 、2018 四次入选全球高引用学者 (TR Highly-cited researchers )。
北大 AI 公开课第七讲回顾:《微软亚洲研究院周明:NLP进步将如何改变搜索体验》
以下为 AI 前线独家整理的颜水成老师课程内容(略有删减)
对 AI 领域的观察
今天的分享主要分为两部分。
首先,作为一个 AI 领域的观察者,我想谈谈在学术界、工业界和创业的团队里,发生了一些什么事情,以及我个人对这些事情的一些看法;另外,作为一个 AI 实践者,我想为大家分享一下 360 在大安全概念的指引下,AI 发展的走势和进展。
在过去的将近一年多的时间里面,我觉得有两件事情对 AI 的影响是非常大的。

第一件事情是,在去年年初的时候,区块链和比特币爆发的时间点,很多 VC(风投)突然一下,好像对人工智能丧失了兴趣,把精力和投资的欲望完全转向了区块链,就像上面左侧这张图描述的那样。当然,这件事情也不完全是坏事,有一个好处是:大家对区块链和比特币有了更清楚的认识。
另一件事情发生之后,AI 又渐渐地开始回暖。今年,深度学习的三架马车:Yoshua Bengio、Geoffrey Hinton 和 Yann LeCun,拿到图灵奖之后,又为 AI 注入了一个强心针,大家有更强烈的热情去推动 AI 往前发展。
在学术界,我第一个观察到的是什么呢?大家可以看到,AI 的论文的数目已经完全超越了所有学者能够阅读的极限。今年恰好我是 ICCV、CVPR、AAAI 和 IJCAL 四个会议的 area chair。其中,AAAI 已经结束了,收到投稿量是 7095 篇,接收了 1150 篇;CVPR 是在 2 月底开的这个 area chair Meeting,收到了 5100 多篇论文,接收了 1300 篇,ICCV 和 IJCAL 还在审稿当中,分别至少有四千多篇的投稿。
过去我们参加一个会议,基本上利用四天左右的时间扫一遍会上感兴趣的文章,是完全没有问题的。但是现在每天发表的论文的速度,让学者完全没有时间去把它进行通读,这对于学者来说是一个非常大的挑战。很多人也希望利用 AI 来进行辅助,筛选自己感兴趣的 AI 论文,以利于我们能够更好学习 AI。
有一个人利用业余时间写了一个叫 Arxiv Sanity Preserver,希望用人工智能的方法,把读者感兴趣的论文给筛选出来,同时可以相应的去推荐一些用户可能会感兴趣论文,非常像信息流的推荐系统。我觉得如果 AI 能够帮助我们更好的读 AI 论文,也是一个非常有趣的事情。
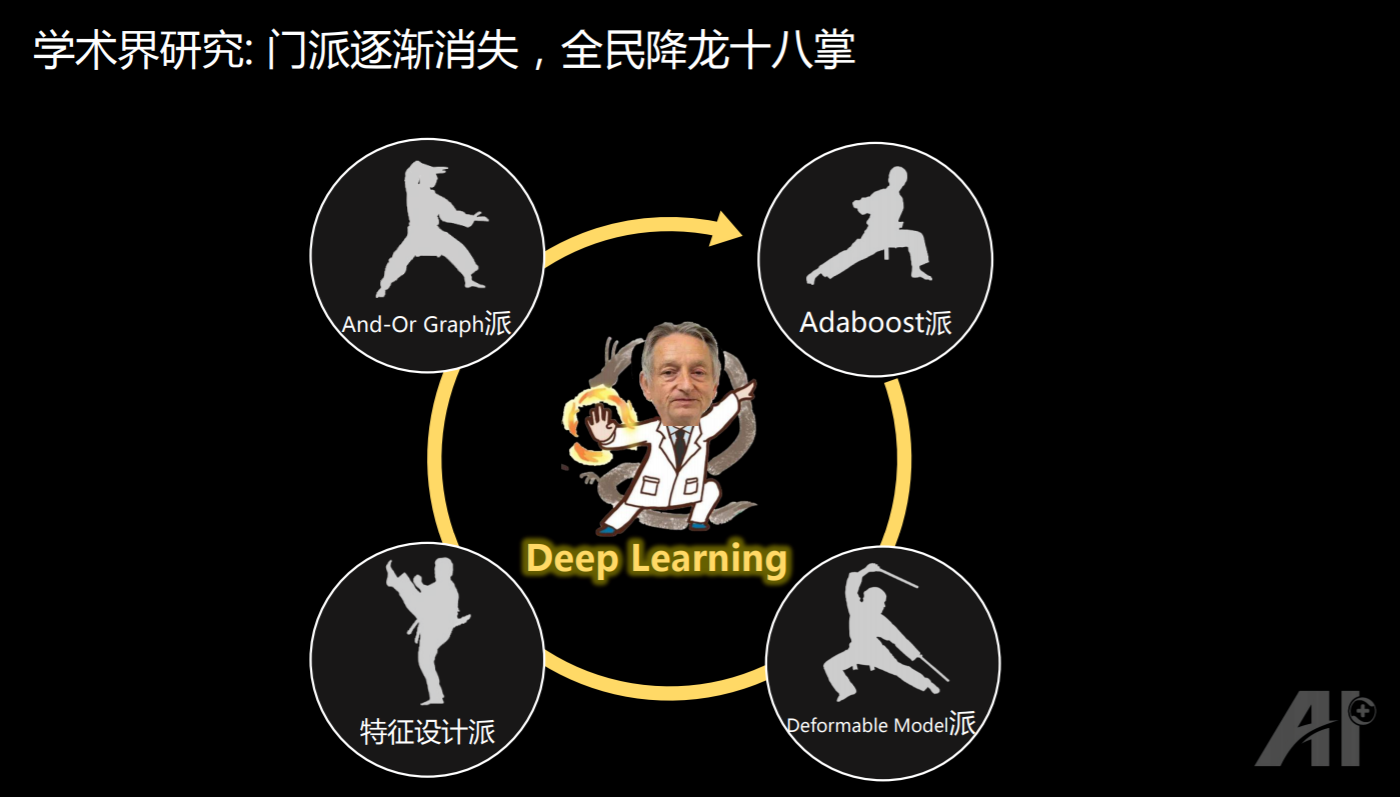
第二个观察是,门派已经逐渐消失了。以计算机视觉为例,我在读书的时候,有 Adaboost 派、有 Deformable Model 派、有特征设计派,也有理论功底比较深的 And-Or Graph 派,但现在已经完全改变了,全民都想只用一招,就是 Hinton 的深度学习。
第三个观察到的现象是,现在论文的影响力出现了资源 Biased 的现象。什么意思呢?像 Google、Facebook、微软这样的大公司,也包括国内 BAT 这样的公司,要写一篇好的论文,可以调用的 GPU 的数量可能是成百的,甚至更多,但是在高校里面,一般一个学生只能分到一块到两块 GPU,情况好点的话,也许有八块 GPU 可以去做一篇论文。

可以看到,最近发表的这些原创的有影响力的论文,它使用的 GPU 的资源是非常令人惊讶的,比如谷歌这篇 NASNet 的论文,它花了 83 个 GPU-Days;另外一篇 Facebook 的论文,用了 7382 个 GPU-Days,这在学校里面是基本上不可能做到的事情;前不久发布的 BERT,用了 256 个 TPU-Days。
大家可以看到,这些工作确确实实都开创了一个新的时代,或者说一个新的方向,都非常有价值,但这些工作从某种意义上来说,已经是学术界没有办法去做的了。这个情况对于学校的研究者,以及 AI 研究公平性方面要引起反思,当然我们不能说它好或不好,但是事情都已经发生了,我们大家还是需要注意的。
第四个观察是,在近一年时间里出现的重要的进展,它们的落地性还不是特别的好,所以我们用了一个词叫:让子弹再飞一会。比如今年的 BigGAN 和 StarGAN,它的效果是确实非常好,但是我们也没有想清楚这个东西到底可用来干什么,到底有什么样的商业场景。

这可能是在接下来的一年或者更长的时间里面大家所需要思考的,比如今天的 BERT 效果非常的好,但是它的功耗实在太大了,还暂时没有办法直接在产品中使用,怎么样去降低功耗,让 BERT 模型仍然能够达到比较好的效果,是需要进一步往前推进的事情。
另外一个就是强化学习。Big GAN 花了很多的人力在做这个方向的研究,但其实,GAN 在其他场景的价值,还没有得到充分的彰显。我们也曾经尝试,让它去解决比如像广告推荐、金融风控等方面的问题,但是后来跟其他的公司进行探讨的时候,我们发现强化学习在其中发挥的价值还是非常的小。这些东西都非常有价值,但是在实际的商业场景中,可能还需要让子弹再飞一会,或许还需要更长的时间,才能让它发挥出价值来。
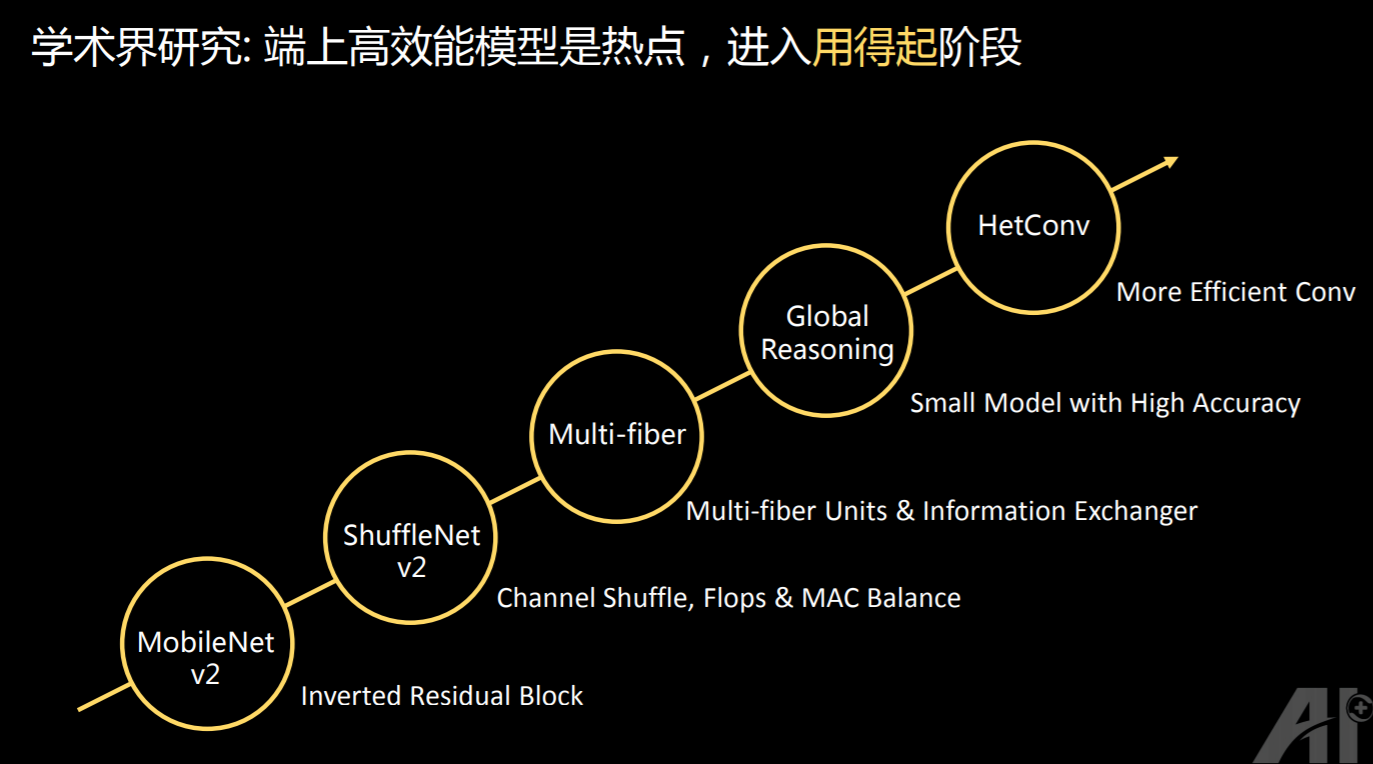
另外一个观察是,在端上的高效的模型已经成为热点,而且是刚需。也就是说,现在深度学习已经从“可以用”时代逐步进入到“用的起”时代了。所以在过去这一年里,大家可以看到有非常多的相关工作和研究在进行,比如:怎么把硬件的特性考虑进去,可以让模型在端上能够有实时性?
学术研究 VS 工业研发

从学术界的角度来看,我们基本的目标是希望能有一些优质的论文发表,能在比赛上获得更好的成绩。我认为在学术界的研究更像是一种个人的冲锋战,但是到了工业界之后,特别是成熟的公司,他们的目标不只是做算法研究,或者说纯粹的发表论文,而是需要把技术放在一个闭环里面。
现在工业研发中,有两个维度非常重要,一个是价值闭环,一个是数据闭环。
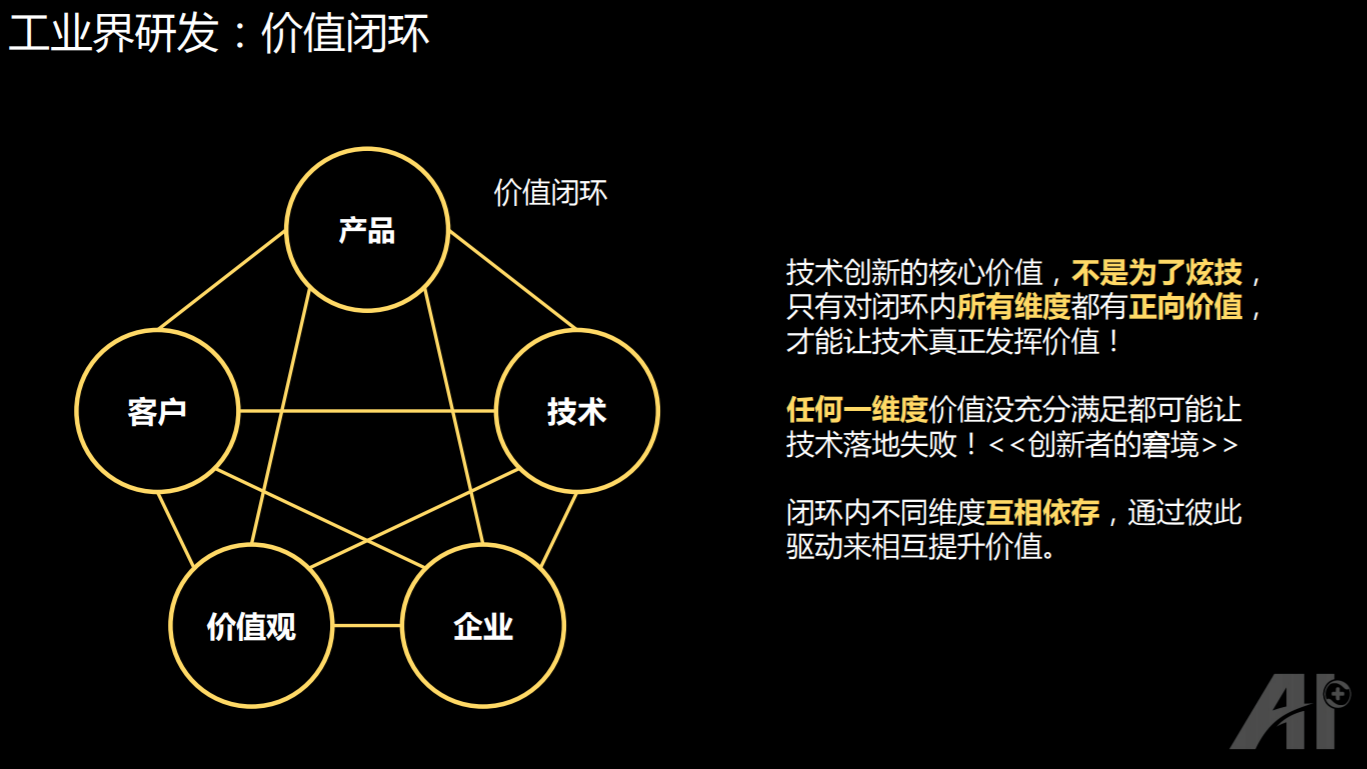
“价值闭环”我第一次看到是在《创新者的窘境》这本书里面,它在里面讲了四个纬度:技术、产品、客户和体验。为什么有一些好的技术,在传统的大企业里面,反而落地非常困难?一个主要的原因是:技术虽然能够带来价值的增加,但是对于消费者、销售商、客户或者企业,如果有一方的利益没有增加,那他就没有动力去利用这项新技术。所以一定要把技术放在一个闭环里,让闭环里每个维度的人都感受到价值的增加,这样的话,才有可能让一项技术在传统的企业里被大量的采用。但这是非常困难的。
而据我们的观察,最近很多的互联网的产品,除了这四个纬度之外,还有一个维度也变得非常重要,就是社会价值观。当有一个产品的社会价值观没有起到正向的推动作用,往往这个产品也很可能会走向失败。
在闭环中,企业、技术、产品、客户、价值观,他们之间是相互依存的。我举一个例子来说明。
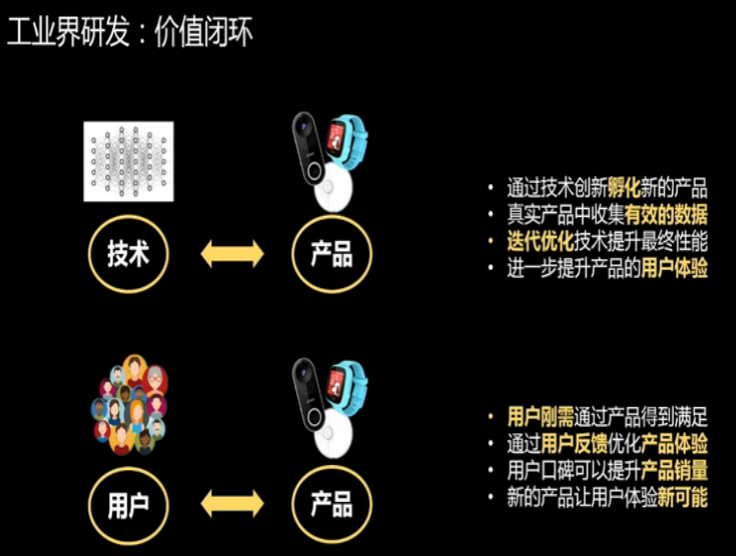
首先我们肯定是通过技术创新来孵化新的产品,但是我们会在真实产品中,去收集有效的数据,用这些数据来迭代和优化我们的技术,最终技术又进一步的提升产品的体验。
我们来看看用户的 feedback 会对我们的产品产生什么样的有意义的价值。

我们 360 做了一个扫地机器人,扫地机器人纯粹依靠传感器来转向有时候不是那么精确,有时候需要依靠碰撞的方式来确定是不是到边界了。我们其实一开始并没有在机器人外面做缓冲装置,而是有个用户,他自己在扫地机器人上面加装了这个东西,这样的话,当机器人碰到一些比较脆弱的,或者比较珍贵的家具的时候,就起到了一个很好的保护作用。
这些东西在公司里面,可能很少有人会这么去想,但是我们有这么多的用户,用户会根据他真实碰到的问题,有些时候会产生一些非常创新的想法,这个想法返回到我们企业里,有可能会给我们的产品带来进一步的改良和优化。
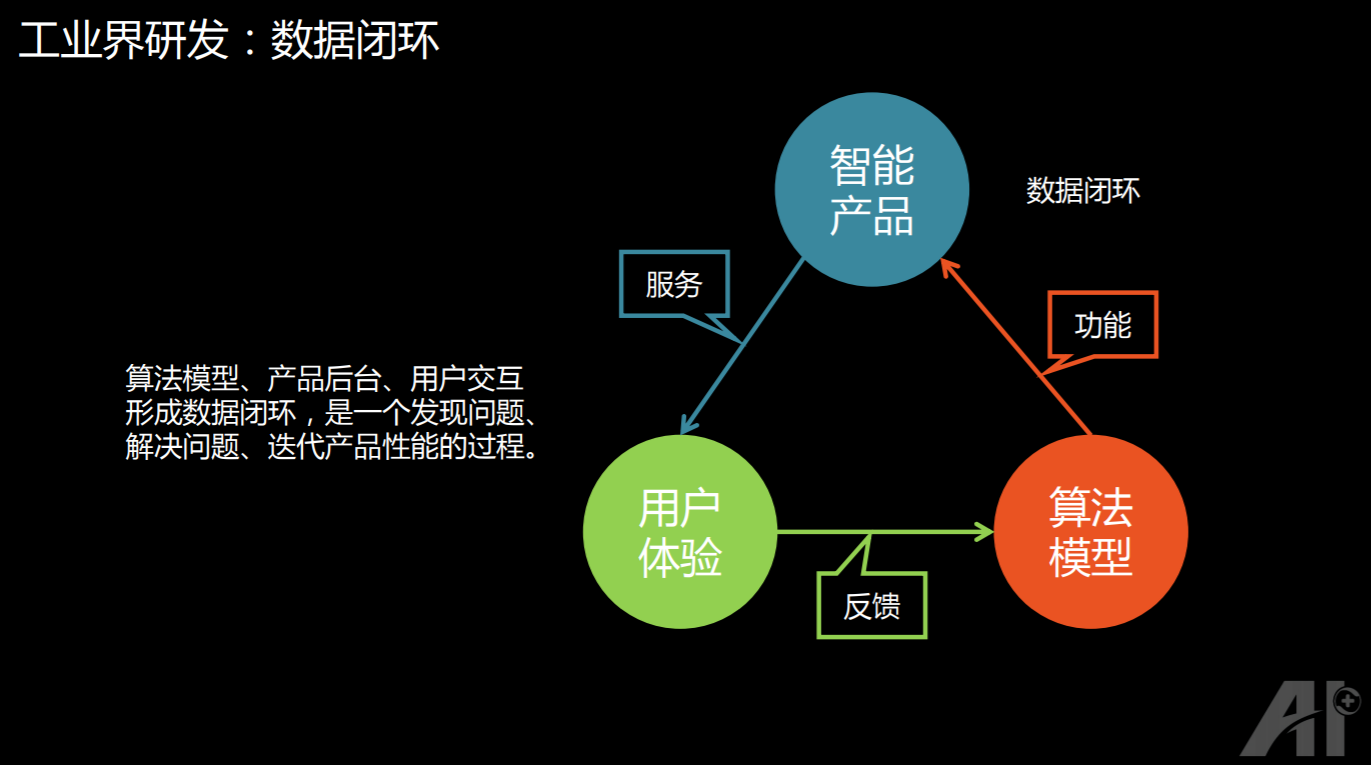
第二,数据闭环。这其实是非常重要的,特别是对算法来说,我们一定要建立起数据闭环。我们一般会专注在算法模型的部分。算法模型和产品本身产生的这个数据,以及用户在使用过程中产生的各种交互的数据,要把它形成一个闭环。
比如:算法模型为智能产品提供一个功能,同时智能产品又为用户提供服务,用户在使用过程中,又会有很多反馈信息,它们合在一起,形成一个闭环,这个闭环是我们发现问题、解决问题和不断的去迭代产品的一个过程。
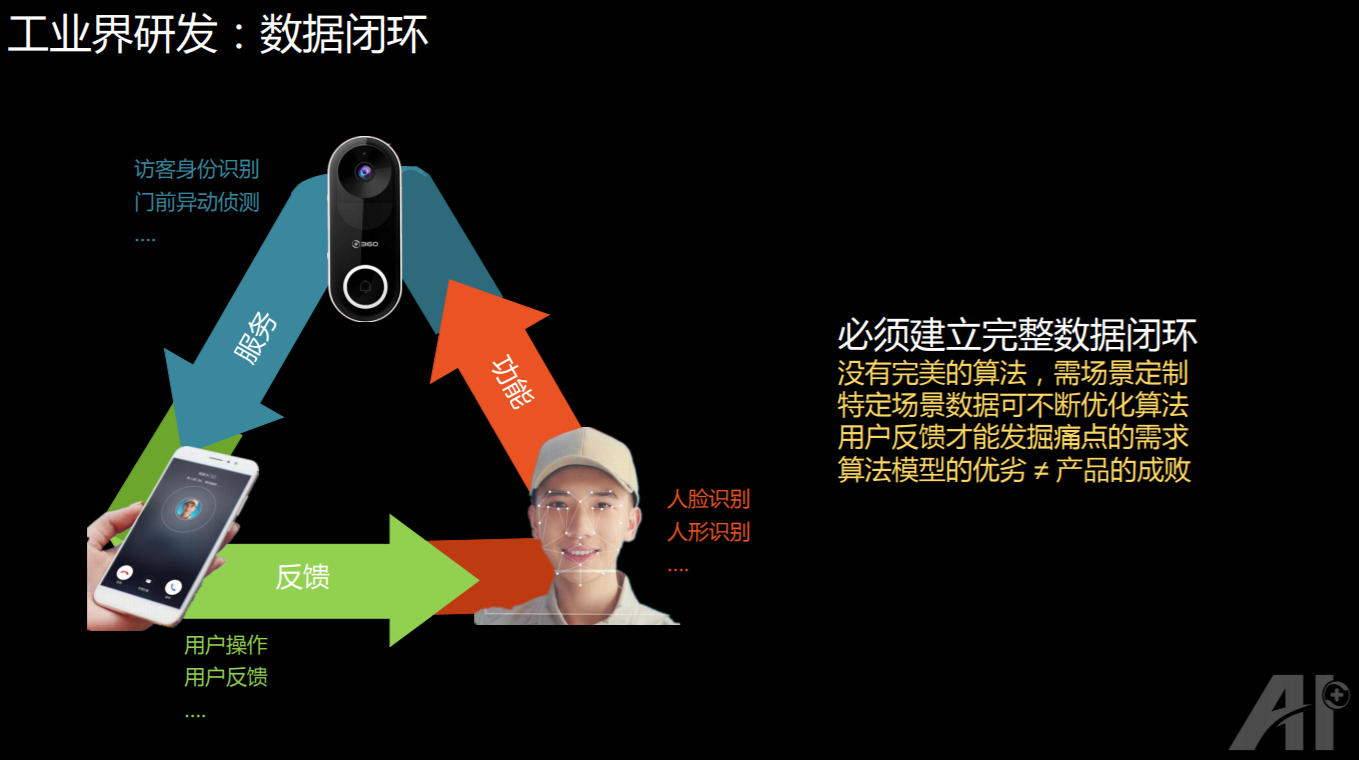
以 360 的一款门铃产品为例,这款产品有人脸识别,或者人形检测等等功能,这项功能部署在云端或者本地端,产品就会进行实时的分析,而这些分析的结果,就会发送到用户的手机上,用户在使用手机的时候,可能一开始并不知道是哪些人,但是收集到的数据比较多之后,系统就会把人聚堆,用户也可以对某个人进行标注,系统也可能会帮用户把标注内容分成几个小的聚堆。这些信息反馈回来之后,我们可以用这些数据去进一步提升人脸识别,或者人形识别的精确度。
那么为什么要建立一个闭环呢?我觉得一个核心是:因为 AI 没有完美的算法,比如设计一个人脸识别的算法,并不一定在所有场景都能取得很好的效果。至于为什么人脸识别的一些公司能存活下来?我认为主要原因是:每家公司都在特定的一些场景下,有自己的数据优势,可能在某个场景下,A 公司能一统天下,别的公司就没有办法能够进来。
另外,特定场景的数据,还可以不断的优化算法。最关键一点:产品算法模型的优劣并不是产品成败的直接决定因素,产品的设计、用户交互的友好性等等都要不断的考虑进去。这些因素可以在用户的反馈和数据的生成过程当中逐步得到,最后能形成一个非常有竞争力的产品出来。

对于学术界研究和工业界研发的差别我有一个小的总结:我认为学术界更像是两个人在谈恋爱,工业界更像是结婚后的男女。
如何理解呢?学术界的研究,每天一点点的进步都会让你非常的开心,比如你有一个 idea,发表了一篇论文,同时还希望达到新的境界,希望发一堆论文出来,看到的全是好的一面,而且你可以自由的憧憬,为什么?因为暂时没有人催你生孩子(产品),你可以梦想如果我用这些技术打造出一个产品会多么的美好,而且你会认为这个产品一定会是世界上最好的产品,因为反正你不用真的把这个孩子给生出来。这就是学术界的情况。
但是到了工业界,更像是结婚后的男女,你发现生孩子(产品)成了你最首要的任务,因为你的老板天天会催着你生孩子。你以为生出来的孩子很乖巧,特别是刚从学术界出来的时候,会认为我做出来的产品肯定是世界上最好的,但是来到工业界之后,你会发现一堆的问题,一堆的毛病,有很多问题你之前根本没有想过,比如供应链、销售等等,有各种各样的问题,都是你没有想到的。以前你不关心的因素,后来成为了最关键的因素。
用户不喜欢产品,你就要不停的根据经验和用户反馈来调整,最后这个产品越来越好了,你的头发也白了,身体也坏了,但是看着自己的孩子还是一脸的幸福。这确实是学术界和工业界的差别。
成熟企业 VS 创业公司
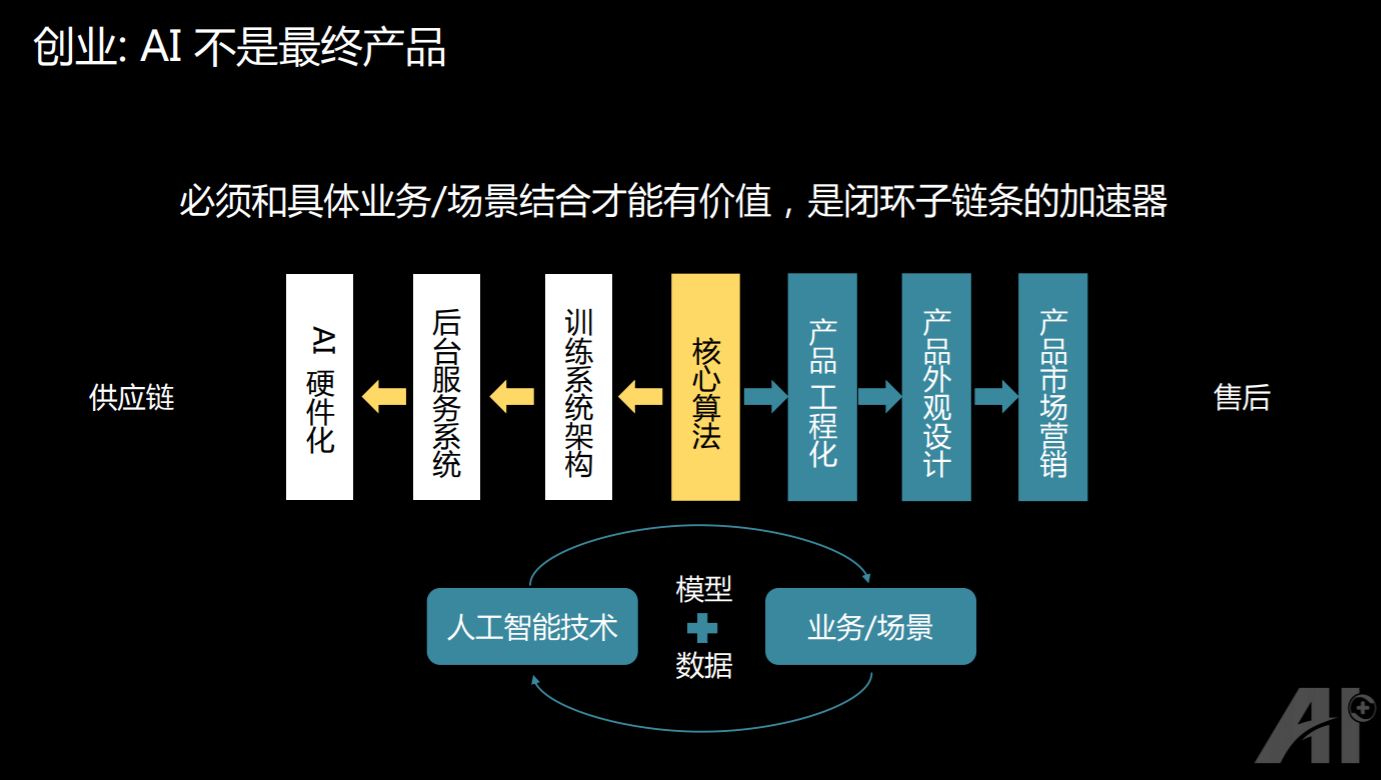
我觉得创业公司,其实有些相似性,特别在技术的维度。所以我把关于初创企业的一些观察,和成熟企业的观察就放在一起了。
首先对于初创公司来说,AI 不是一个最终的产品,它必须要跟具体的场景和业务相结合才有价值。我们总是要明白,AI 只是在一个闭环里面的一个子链条或者一个加速器,它并不能算是一个产品。
比如做一个智能硬件,除了算法之外还有产品的工程化、设计、市场销售、服务器,还要考虑 AI 的硬件化,让它能够更加的高效。但是我们往往更没有想到的是供应链和售后到底会发生什么事情。这些是我们刚开始不会想事情。

第二点,我们要承认 AI 技术已经不是孤品了,它已经不存在什么真正意义上的必杀技。我在观察的时候,突然想起我看过的《马达加斯加》,感觉非常形象:在纽约时代,这匹斑马就是一个孤品,因为没有别的同类,它所会的一切技能就是必杀技;但是当他回到草原的时候发现不是这样了,其他的同类也都会同样的技能。这段视频非常好的描述了当前的 AI 的状况,AI 技术已经不再是孤品,那么大家也不必幻想 AI 存在必杀技。我们现在更多的需要考虑,AI 怎么样能跟商业闭环融合在一起,逐步形成它的壁垒。

另外,AI 是没有完美的算法的,但是我们又希望有毫无瑕疵的用户体验。去年我也分享过,想做一款好的产品,纯粹的算法科学家是不够的,你需要有产品的工程师来帮助你去用不完美的算法,产生无瑕疵的用户体验。
举个例子,比如说你有人脸方面的各种技术,如果你只是想用它换脸肯定效果不行,但是如果你想用它来,在人脸上加上一些装饰,就能做得非常好,而且效果也会非常的不错。
另外一方面,如果 AI 没有完美的算法,那么人机协同,或者人在闭环,往往也有一些商业模式能够建立起来。一般的做法是:先人在闭环,再逐渐的 AI 化。
举个例子,我原来在新加坡的时候去评测过的一家叫 TRAX 的公司,这是一家以色列的公司,它所做的工作是识别货架上的商品,而且要识别到子类,同样是洗发水,它要知道洗发水的尺寸等等。

它的动机是什么呢?商场里面每年有大量的商品,由于样式太多,人工没有办法去实时监督商品数量,导致每年损失高达五百多亿美金;另外,货架上的商品怎么样摆放,也是有严格要求的,如何摆放才能让客户去购买的可能性最大。
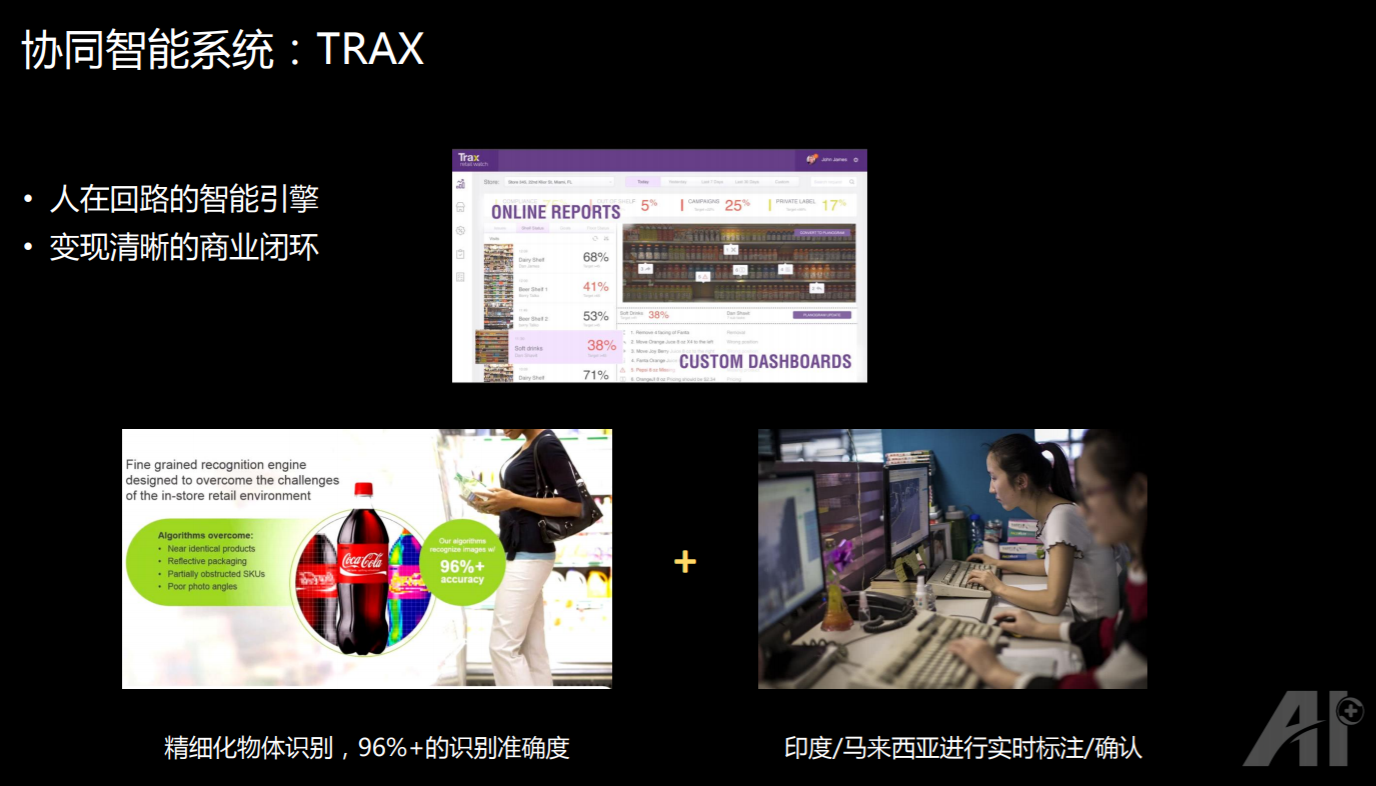
这家公司通过摄像头,去自对识别货架上商品的量有多少,以及它的位置是什么样的。有一些供应商,为了能够得到这个数据是愿意付费的,因为他们会经常派人,去不同的超市商店里检查自家产品的摆放等等,这个工作人工的成本非常高,如果能把它自动化,一些公司肯定是非常愿意的。
但是目前物体识别的精度只有 96%,怎么办?这家公司就在印度和马来西亚,召集了一批实时调度人员,先用自动算法做分析,再用人工来进行修正,通过人机协同的方式,运行起来了这样的商业模式。随着数据收集越来越多,它的精度可以逐步的提升,人工校对的人数也会随之减少。
所以,人机协同也是解决人工智能算法不完美的一种很好的方法。
另外,现在大家都在想,还有没有新的元素,能够去推进 AI 技术往前走?我个人觉得,5G 和 AI 芯片应该是 AI 两个巨大的推动力。

首先,5G 的下载速度快,据说能达到一秒钟下载 1.7G 的数据;第二个特点是高接入量,5G 的设备的数量,可能是现在的几十倍,或者更多;另外很重要的一点是低时延。
有了这些特性之后,比如在 VR 领域,如果带宽提升了,那么用户的体验就会变得更好;此外,高接入量对 IOT 有非常大的帮助;至于低时延,对于 AI 和自动驾驶是非常有价值的,因为自动驾驶车辆的设备,以及车和车之间的连接都需要具备低时延的特点。5G 对于这些场景的落地有非常好的推动作用。
而 AI 芯片最大的好处是什么呢?如果 IOT 设备的计算全部靠云端的话,那么在时延和隐私性方面可能会不那么好,如果端上智能设备的算力足够,比如家里的摄像头,那么就可以把图像通过本地进行处理,不需要上传到云端。
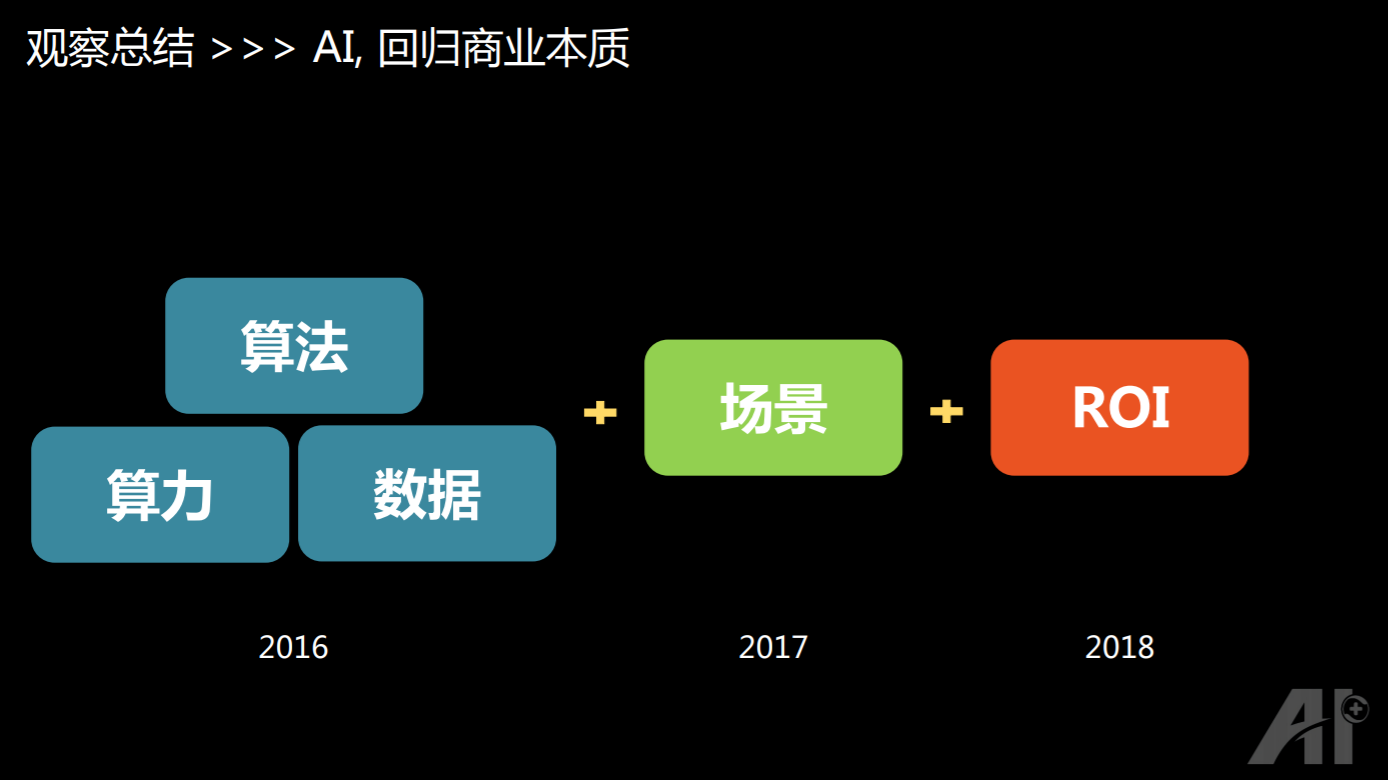
如果把对于学术界、成熟的企业和初创企业的这些观察总结起来的话,大家可以看到,对 AI 不只是去讨论它的三要素,也不只是说 AI 要落地,而是说现在大家已经开始要关心 return or investment(投资与回报),AI 也真的开始回归商业的本质,跟之前的互联网、移动互联网时代一样,商业回报是大家最关心的问题。
以上是我过去大概一年多的时间里面的一些观察。
大安全下的人工智能
接下来,我跟大家分享一下,360 在过去一年里面,AI 的布局和进展是什么样的。
大安全与安全大脑
360 去年明确提出来一个“大安全”的概念。其核心思想是:安全已经不只是局限在网络空间里面的信息安全,攻击也不只发生在网络空间,由于智能的控制的发展,原本存在于网络空间的攻击已经对物理世界产生了危害。
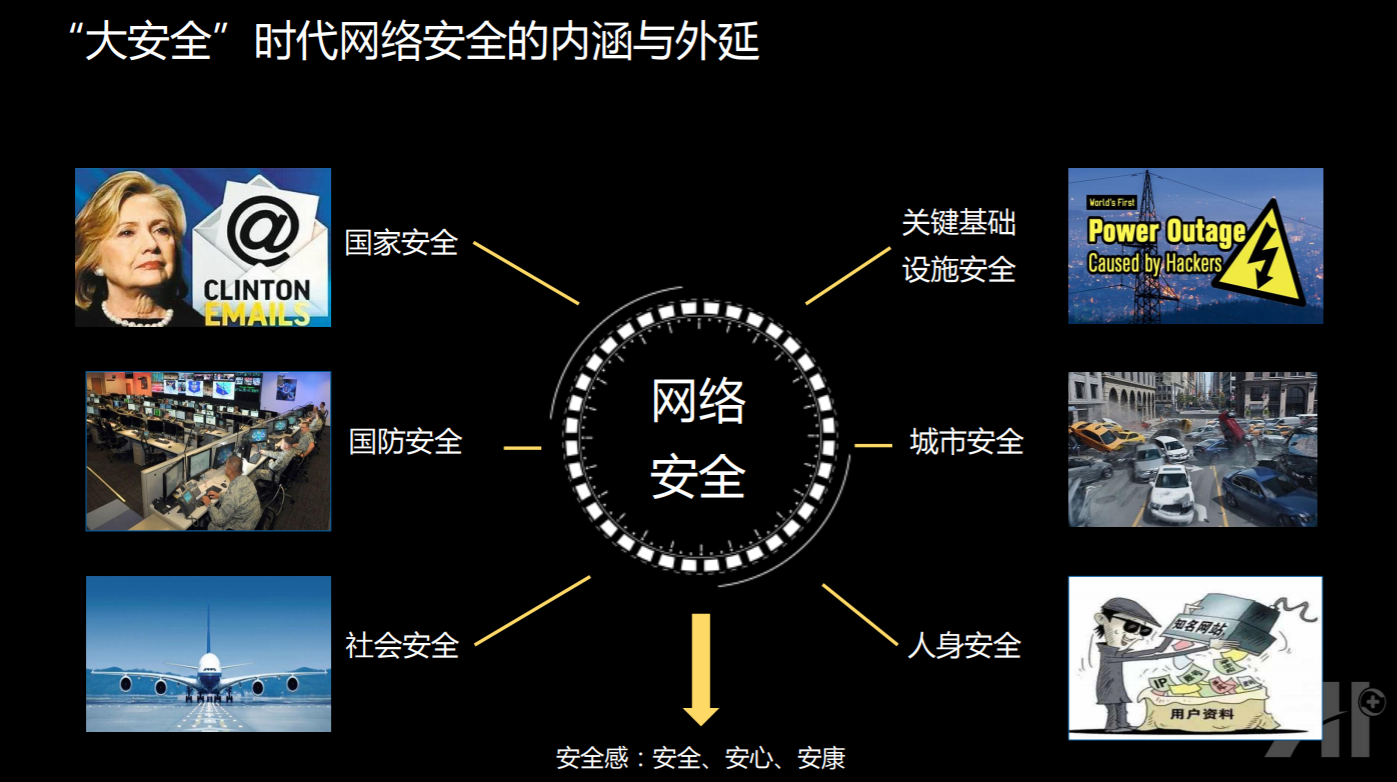
所以,安全公司希望的是,给大家提供一种安全感,包括安全、安心、安康等多个维度。
在此基础之上,360 人工智能的布局主要分成两个部分。
现在 360 的业务布局叫“一体两翼”。“一体”是核心安全,就是传统的安全业务;“两翼”一个是 IOT 业务,一个是互联网业务,比如 360 的搜索引擎、浏览器、信息流等业务。
一方面,360 去年提出了 360 的安全大脑,希望用人工智能和大数据的技术,去打造分布式的智能安全器,其主要目的是防御网络的攻击;另外一方面,是基于 360 的人工智能的平台打造四个引擎,分别是运动引擎、交互引擎、视觉引擎和决策引擎。这四个引擎一个方面是支撑 IOT 业务所需要的智能分析能力,同时还可以支持互联网的业务,因为这里有一些比较难的问题,或者可以进一步提升的问题,希望能够通过决策引擎去支持。
安全大脑的提出,是因为攻防的严重的不对等。防御方面,我们对网络所有的可能性,所有的地方都要防范;但是进攻的话,只要找到一点漏洞,就能攻进去。那么在这个时候,就会产生攻防的严重的不对等。
比如说在安全领域,每年都会有一个事故数据泄露调查报告,他们发现:黑客要进行攻击的话,如果初步得手,则需要跟踪,开始有泄露,也需要跟踪,但是网络安全人员要发现这个数据泄露了,他需要有足够的时间去启动跟踪环节措施,这是一个非常漫长的过程。
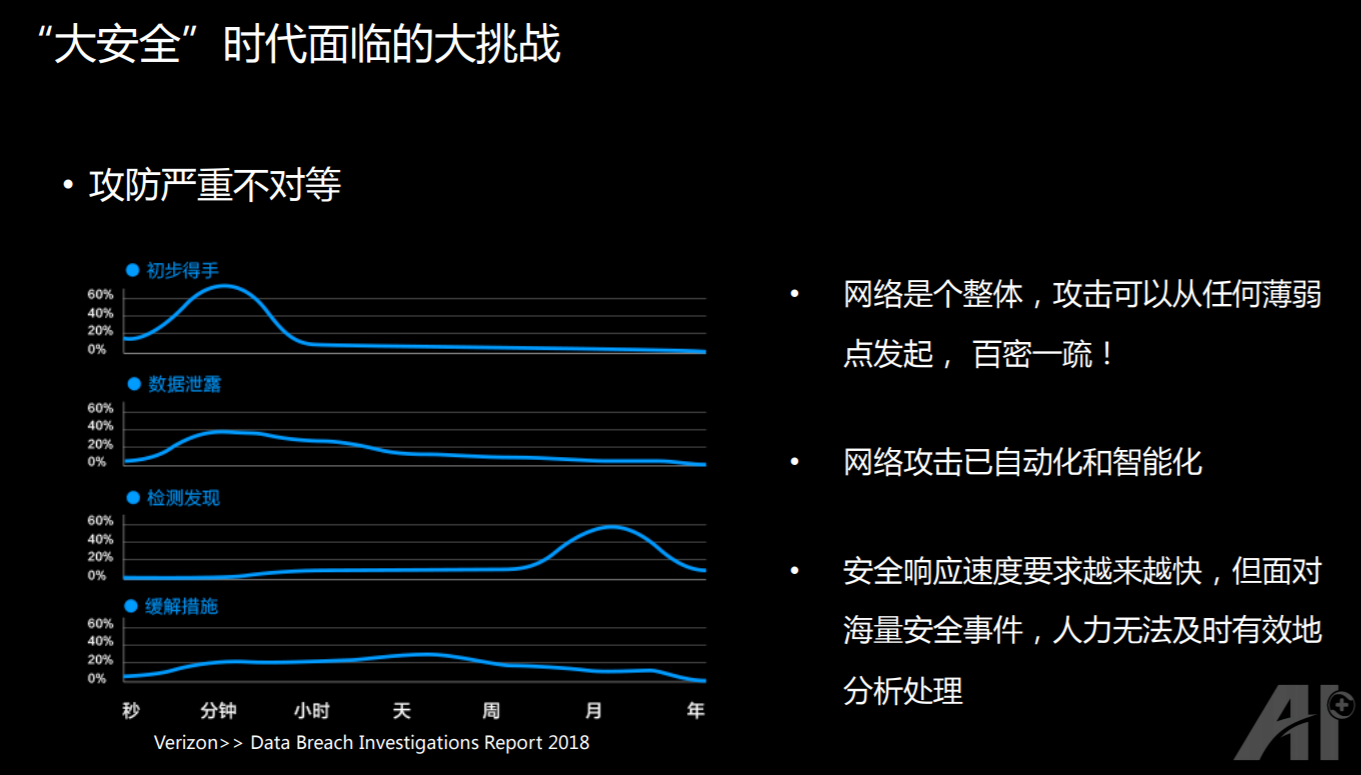
从这里可以看得到:攻击很快,防守很慢,防守环节也很慢。与此同时,网络攻击也越来越自动化和智能化,防守能用 AI,攻击当然也能用 AI。这时候就意味着我们需要对安全的响应速度比以前更快,也就需要大量技术娴熟的网络安全人员。
但是事实上,中国的网络安全人员是严重的缺乏,所以 360 希望是把多年积累的网络安全能力,形成感知学习推理决策和预测的能力,希望能为有安全需求的场景提供一站式的服务。
首先这是一个人机协同的系统,为什么?因为 AI 再怎么强,很多的场景还是需要白帽子,而且很多时候,AI 的价值是协助白帽子发现其中的问题。同时,它也是一个开放的生态,360 的网络安全人员目前不能解决所有问题,我们希望接入第三方的能力和速度,让安全大脑变成一个分布式的协同作战的武器。
此外,要把这些能力开放给第三方,让它有能力去沉积一些和安全相关的国家和企业的项目。在 2018 年的上半年,360 的安全大脑,拦截的恶意的程序就有 396 亿次,拦截钓鱼攻击 200 多亿次,拦截垃圾短信 48 亿条,拦截骚扰电话接近 200 亿次。
半年的时间,可以看到它所涉及到的面和量都是非常巨大的。
四个 AI 引擎
下面主要来给大家分享四个 AI 的引擎。
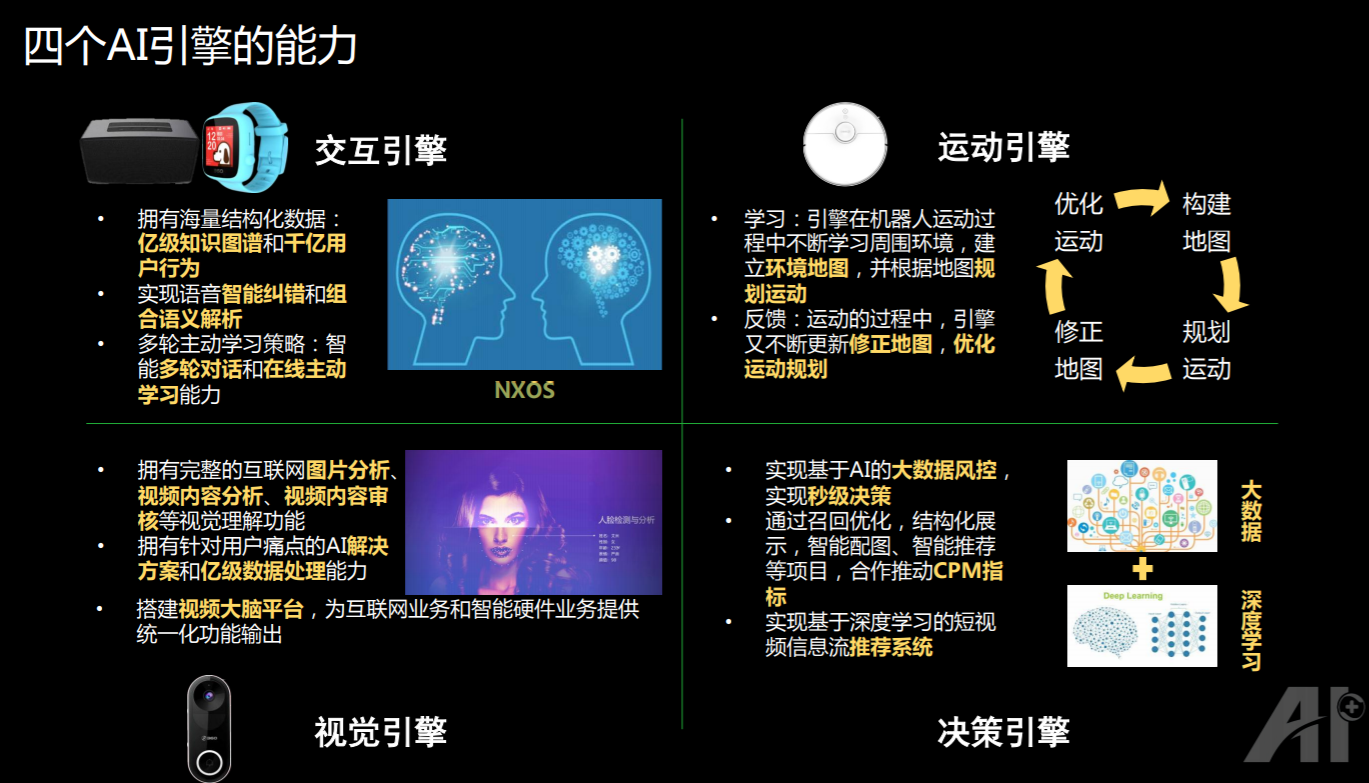
第一个引擎叫交互引擎。以 360 儿童手表为例,小孩需要跟手表利用语音交互通话,后台就需要有一个用于交互的引擎,同时 360 今年刚发布的 AI 音箱也是通过这个交互引擎来提供人机交互的能力,这个引擎叫做 NXOS。
第二个引擎叫运动引擎。这个引擎主要是希望智能硬件能够自主和安全的运行,现在主要是在支持 360 的扫地机器人。
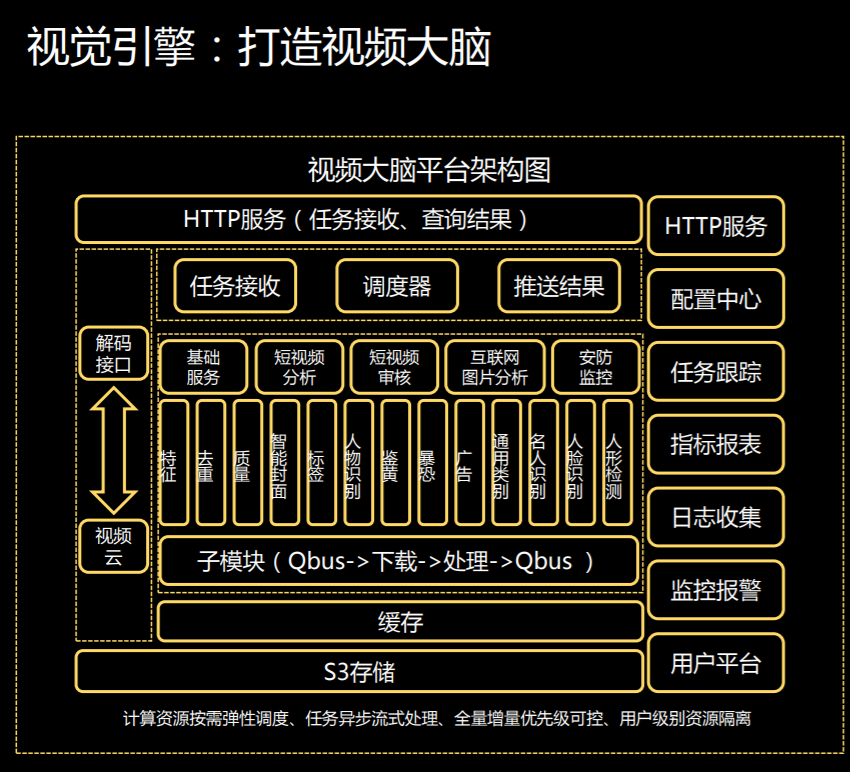
第三个视觉引擎算是 360 的强项,主要是希望对家庭还有小区的安防提供统一的解决方案。
第四个引擎叫决策引擎,依靠的是 data intelligence(数据智能),希望用 360 积累的大数据对未来的趋势进行智能的判断,用来做大数据的风控和广告,还有信息流、短视频的智能的推荐。
总结
最后做一个小的总结。
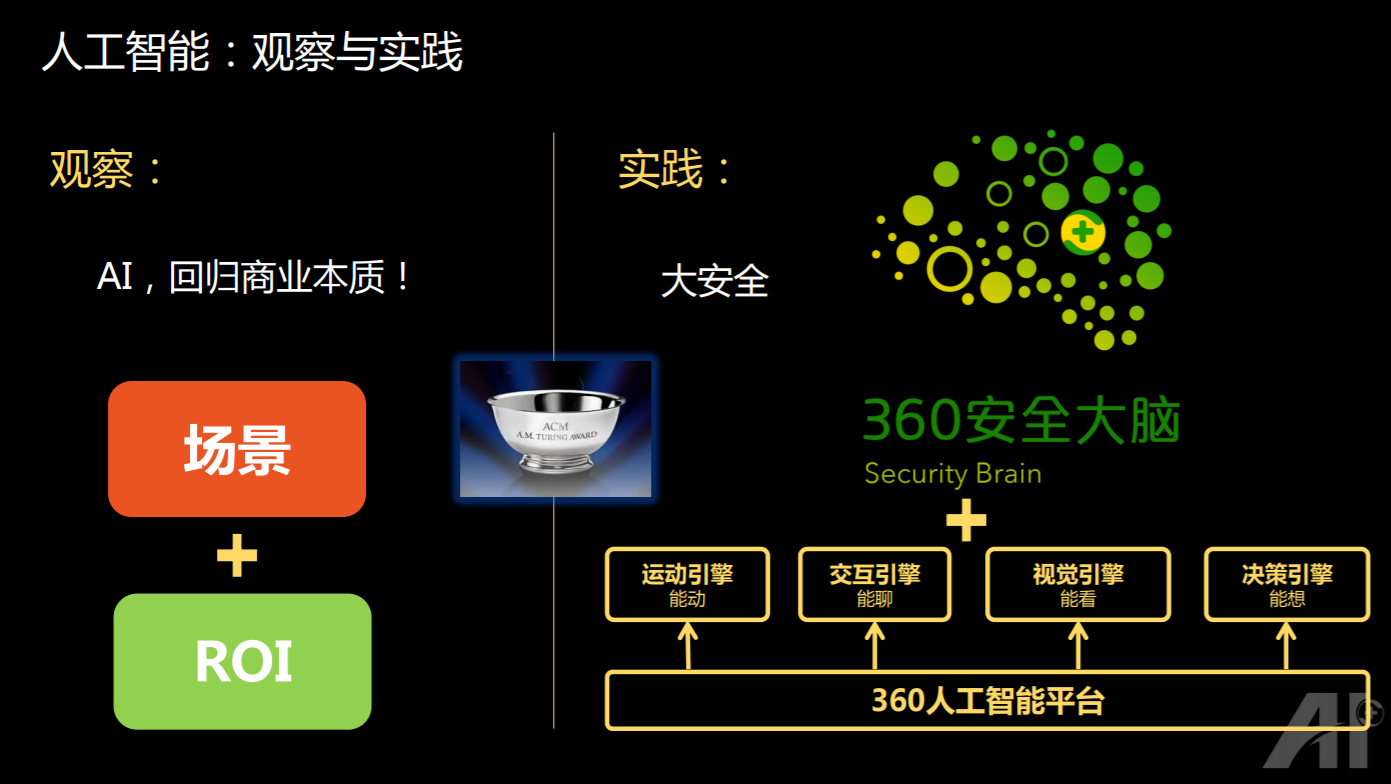
我觉得从学术界、成熟企业以及初创企业的观察来看,大家不再只是考虑 AI 长远的落地,更加关注 AI 的 ROI,也就是说,AI 正在回归它的商业本质了,这个是迟早的事情。
那么在实践的维度,360 在大安全的指导下,用 360 的安全大脑来支撑 360 的网络安全,用四大人工智能引擎去支撑 360 的 IOT 业务,和互联网业务。
同时我觉得因为三架马车获得了图灵奖,在接下来的两年,甚至更长的时间里面,跟 AI 相关的行业应该会继续具有强大的生命力,谢谢大家。
问答环节
雷鸣:对于 GAN、强化学习和 BERT,你觉得未来会有一些什么样的突破,以及这个突破会带来什么样的一些商业机会呢?
颜水成:我觉得 GAN,应该对于图像和视频的生成,肯定会有很多的回应的点。打个比方,你在社交媒体里面想用一个头像,现在网上直接下载的图像很多都有版权的问题;或者你在进行文字创作的时候,肯定会希望有一些配图,如果你到网上去买,不一定买的到,同样如果直接下载,那么版权问题的风险是非常的大的。用自动生成的方式,可以让创作产生更大的价值,而且现在有个趋势,不只是图像,连视频也能生成,这样发展的空间就更大了。当然这是指好的一面。
不好的一面就是,通过自动生成可以生成任何人,所以可能将来在网络上看到的新闻图片有些是自动生成的,这样反而会带来一些混乱。从安全的角度来说,利用 AI 判断到底哪些图片是真实的,哪些是虚假的,由此引发的相关研究也是很有前景的。
至于 BERT,我个人是非常看好它的前景,但是它的训练代价太大,最近有很多团队在用 BERT 刷榜,但如果你仔细去看会发现,刷榜的人都没有对 BERT 重新训练,都是用之前训练好的模型;当然也有一些团队在探索,有什么办法能够在真正的业务里面用上这个模型,还需要一些时间,但前景我非常的看好。
而强化学习可能前景就更不清晰了,我们看到了它确实是解决很多的问题,比如用来做模型的生成,像 GAN 这样的模型也在广泛的使用。如果公司是用它来瞄准长期的收益,这个东西可能会是很好的,但我觉得有如果公司比较愿意保障当前的收益,可能就没有办法立刻看到它的价值。
雷鸣:有一个观点认为,深度学习的发展跟算力是捆绑的,随着算力的提升,很多问题都解决了,如果没有算力大幅度的提升,很多问题仅靠调整模型可能是解决不了的,对于这个观点你是怎么看的?AI 的未来真的就是暴力求解吗?
颜水成:我的个人感觉当前确实是比较依靠算力和有效的数据,比如说,图像和语音的问题都解决的不错了,但为什么 NLP 问题没能解决的特别好?我们当时有一些探讨:
可以把这些问题看成不同的数据空间,比如语音更多的是一维的空间,很容易就能够全覆盖到;而图像的数据空间相对语音来说会更大一些,随着社交媒体的丰富,像 ImageNet 这样的数据集也越来越多,图像的数据空间也开始逐渐变得更加充分了;但是 NLP 领域,就好比要把所有的词汇全部考虑进去,包括排列组合等等,它所拥有的空间比图像空间更大,因此可能需要的样本更多,如果再把多轮对话、人机交互等等问题考虑到的话,数据空间就更大了。
现当前的状况,几乎没有这么大的数据能把整个 NLP 空间的话有效的覆盖,这也是为什么现在人机交互的过程中,机器仍然很笨的一个主要原因。假设将来收到越来越多的日常高频的人机交互数据,你或许会发现机器人变得越来越智能。也许到将来的某个时间点,平常我们能见到的一些交互,就都不成问题了。
那么要处理这些东西,首先算力要足够。大家也知道之前 OpenAI 最新开源的模型 GPT 2.0 已经可以自己生成文章,这也是靠海量的数据和大量的计算资源堆出来的结果。
也许随着数据的增加,和计算能力的增强,解决 NLP 问题会比以前解决的更好。但是我是觉得,可能还会有差别,至少现在与智能音箱对话的人机交互方式,跟两个人类交流的方式还是差别很远的,所以至少在这个维度,应该是暂时没有办法让这个机器达到一个与人类接近的地步。
雷鸣:现在也出现一种叫多模态融合的方向,要理解视频内容,还要跟自然语言有关,前段时间微软也推出一个在图片上,通过语言去寻找某个东西的模型,对于这个方向你是怎么看的?
颜水成:我是比较悲观的。大家都在讲通用智能,我也有朋友是做这个方向的,比如按照某个方式去让智能体去接触外部环境进行学习,虽然能够从理论上证明,最后会具备强人工智能的能力,但是我觉得还是有些弱。这类实验也非常简单,有点像一个非常原始的游戏,去模拟这个过程,所以我个人觉得达到强人工智能的时间还是有些漫长。
而多模态融合现在也没有看到特别的好的方法,之前也有一些研究想要弄明白,人类大脑的视觉和听觉到底是如何协同工作的,但是到 2017 年也基本上没有任何实时性的进展。
当时在多媒体领域,有一个很好的梦想是希望能把图像、语音和文字,三个模态的信息能融合在一起去做一些事情,但是,如果去看这些论文,会发现其实它的融合机制还是比较简单的,而中间是怎样交错,并影响到最后的结果,我觉得还缺少一层比较好的机制,现在的多模态,做得还是很简单。至少从我自己有限的研究里看,多模态发展需要时间还特别长。
雷鸣:你觉得在视觉上,未来有哪些产业还会落地或者发展?
颜水成:第一,我觉得教育还是一个比较重要的方向。现在的教育资源确实不够,要么把老师叫到你这边来,要么把孩子送到补习的地方去,可是有个现实问题,路上交通的时间成本太高了。我是觉得从视觉角度来说,通过基于视觉的交互,可以完成比如作业的批改,或者是在学习过程中,利用视觉技术分析孩子当前学习的状态等等。
另外由于 5G 的出现,一定会有新的内容产生出来,用视觉的方法去帮助用户产生适合在 5G 形态上的内容,肯定会催生很多新的公司。当然不仅仅是我们现在见到的短视频产品,可能会是别的视频产品,这块是视觉比较强的地方。
雷鸣:你对自动驾驶是怎么看待的,是偏乐观一点的观点,还是偏悲观的?
颜水:我有一个观点是,希望做任何事情,经常有阶段性产品出来。但是自动驾驶的话感觉,在我看来是比较难有阶段性产品出现。因为我是从学术界来到工业界,所以我内心还是希望比较快速能看到一些有效的项目出现。另外,自动驾驶的周期比我们想象的要长,今年很明显,大家开始比较少的去谈一些 L4 或者 L5 的产品,开始想要在一些受限场景下尝试产品的落地了。但是我个人还是觉得这个方向是非常这个值得投入,也是未来应该关注的一个方向,也许需要更多的年轻人做这个事情。
更多内容,请关注 AI 前线公众号。在公众号后台回复关键词“北大 AI 公开课”,可获取往期课程文字材料 + 视频回顾等学习资料。


Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...









评论