

一. 美团点评训练 Wide & Deep Learning 模型
模型架构:
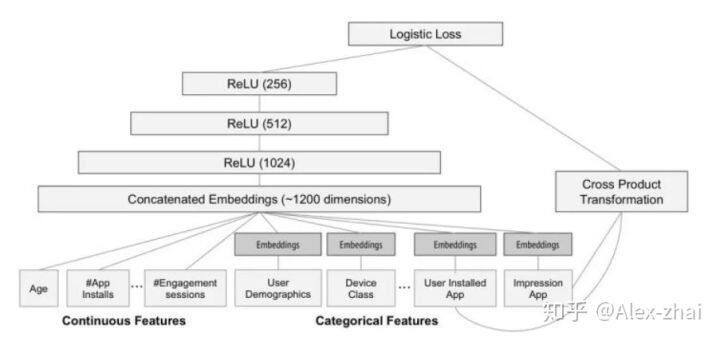
采用架构:parameter-server 参数服务器
优化点:输入数据环节、优化集群网络瓶颈、优化 PS 上的 UniqueOP 性能瓶颈。下面分别介绍这三个优化点:
输入数据环节
读取数据慢的原因:旧的 tensorflow 消费数据接口底层采用的是 python 多线程,受制于 Python 的全局解释锁(GIL),Reader 线程在训练时没有获得足够的调度执行;Reader 默认的接口函数 TFRecordReader.read 函数每次只读入一条数据,如果 Batch Size 比较大,读入一个 Batch 的数据需要频繁调用该接口,系统开销很大;
解决方法:采用新的 dataset 接口,采用批量读数据接口 TFRecordReader.read_up_to,该接口能够指定每次读数据的数量。
优化集群网络瓶颈
在推荐业务的模型中,embedding 张量的参数规模是千万级,TensorFlow 的 tf.embedding_lookup_sparse 接口包含了几个 OP,默认是分别摆放在 PS 和 Worker 上的。如图所示,颜色代表设备,embedding lookup 需要在不同设备之前传输整个 embedding 变量,这意味着每轮 embedding 的迭代更新需要将海量的参数在 PS 和 Worker 之间来回传输。
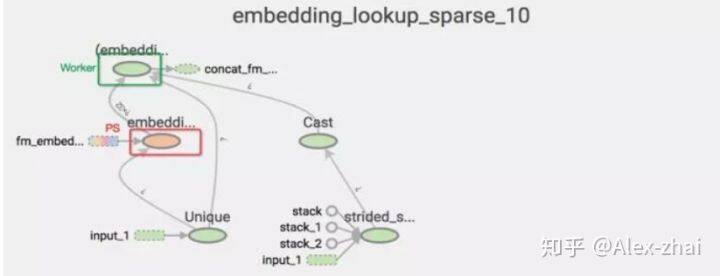
有效降低网络流量的方法是尽量让参数更新在一个设备上完成,利用 embedding_lookup_sparse_with_distributed_aggregation 接口,该接口可以将 embedding 计算的所使用的 OP 都放在变量所在的 PS 上,计算后转成稠密张量再传送到 Worker 上继续网络模型的计算。
优化 PS 上的 UniqueOP 性能瓶颈
embedding_lookup_sparse 操作会使用 UniqueOp 算子,TensorFlow 支持 OP 多线程,UniqueOp 计算时会开多线程,线程执行时会调用 glibc 的 malloc 申请内存。
而 Hadoop 有时会设置 export MALLOC_ARENA_MAX="4"的配置,该配置的意思是当进程开启多线程调用 malloc 时,最多从 4 个内存池中竞争申请,这限制了调用 malloc 的线程并行执行数量最多为 4 个。去掉该配置之后,线程并行执行数量没有限制,tensorflow 的并发性能得到极大提升。
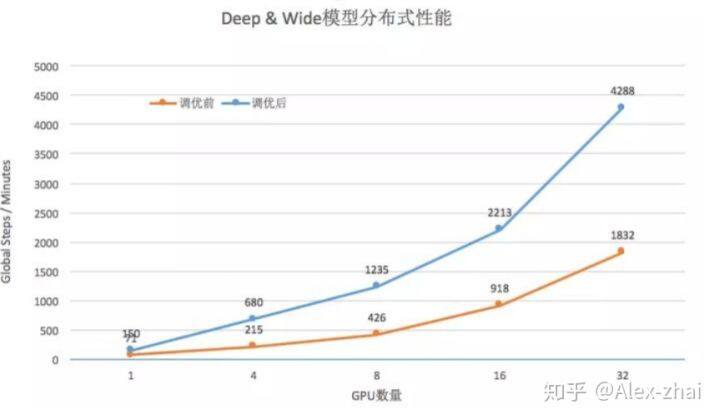
优化后效果对比
二. 美团广告交易平台
模型:Wide & Deep 模型,特征包括用户维度特征、场景维度特征、商品维度特征。Wide 部分有 80 多特征输入,Deep 部分有 60 多特征输入,经过 Embedding 输入层大约有 600 维度,之后是 3 层 256 等宽全连接,模型参数一共有 35 万参数,对应导出模型文件大小大约 11M。
采用架构:TensorFlow 同步
优化点:
采用 Backup Workers,解决异步更新延迟和同步更新性能慢的问题。
优化参数分配方式,采用 GreedyLoadBalancing 接口,根据总的参数大小平均分配参数到各个 ps 上,取代了 Round Robin 取模分配的方法,可以使各个 PS 负载均衡。
计算设备方面:只使用 CPU 而不使用 GPU,训练速度会更快,这主要是因为尽管 GPU 计算上性能可能会提升,但是却增加了 CPU 与 GPU 之间数据传输的开销,当模型计算并不太复杂时,使用 CPU 效果会更好些。
使用 Estimator 高级 API,将数据读取、分布式训练、模型验证、TensorFlow Serving 模型导出进行封装。
使用 Estimator 的优势:单机训练与分布式训练可以很简单的切换,而且在使用不同设备:CPU、GPU、TPU 时,无需修改过多的代码;Estimator 的框架十分清晰,便于开发者之间的交流;可以直接使用一些已经构建好的 Estimator 模型:DNN 模型、XGBoost 模型、线性模型和 Wide&Deep 模型等。
参考文献:https://tech.meituan.com/2018/10/11/tfserving-improve.html
三. 字节跳动 BytePS
字节跳动 AI 实验室宣布开源了一款高性能分布式深度学习训练框架 BytePS。该框架支持 TensorFlow、Keras、PyTorch、MXNet,可以运行在 TCP 或 RDMA 网络中。BytePS 在性能上超过了过去性能一直领先的 ring all-reduce。BytePS 主要的优化点为:
为云和共享集群设计,抛弃了 MPI 的通信方式。
基于优先级的调度。
NUMA 感知本地通信、 PCIe switch 的优化
分层策略
PS 的 RDMA 实现
张量分区
缺点:
不支持纯的 CPU 训练
不支持稀疏的模型训练
异步训练
容错机制
Straggler-mitigation
本文转载自 Alex-zhai 知乎账号。
原文链接:https://zhuanlan.zhihu.com/p/75946827

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论