

百度 Noah 平台的 TSDB,是百度最大规模的时序数据库,它为 Noah 监控系统提供时序数据存储与查询服务,每天承接多达数万亿次的数据点写入请求,以及数十亿次的查询请求。作为监控系统的后端服务,在如此大规模的写入情况下,保证快速的查询响应非常重要,这对系统提出了巨大挑战。通过对用户日常查询行为进行分析,用户的查询需求与数据的时间轴有强关联,用户更加关心最近产生的数据。因此 Noah 的 TSDB 在架构上,利用百度 BDRP(百度的 Redis 平台)构建缓存层,缓存最近几小时的数据,极大提升查询性能,有效降低查询平响。
同样 Facebook 为了提高其 ODS TSDB 读写性能,设计了基于内存的 Gorilla 时序数据库,用作 ODS 的 write-through cache 方案缓存数据。可以看出在缓存这层,我们都采用基于内存的方式做数据缓存。采用内存最大的优势是其数据读写速度远快于磁盘速度,然而缺点是需要占用较大的内存空间资源。为了有效节约内存空间,Gorilla 设计了时序数据压缩算法对时序数据进行实时压缩。在 Gorilla 论文[1]中表明,利用其压缩算法,在 Facebook 的生产环境下平均压缩数据 10 倍。
我们在对缓存层数据存储设计的时候,结合 Noah TSDB 的具体情况,借鉴了 Gorilla 数据压缩算法对数据进行压缩,存储空间资源占用降低了 70%,有效降低资源成本。因此本文简单和大家分享一下该压缩算法的基本原理,没准儿也能节约下不少钱呢。
基础介绍
典型的时序数据,是由 Key-Value 组成的二元组, Key 中可能包含如 Cluster、Tag、Metric、Timestamp 等信息。为了便于理解,这里将时序数据简单理解为 Key 是时间戳(Timestamp),Value 是在该时间戳时的具体数据值。
假设这是某 CPU 在不同时间的利用率:
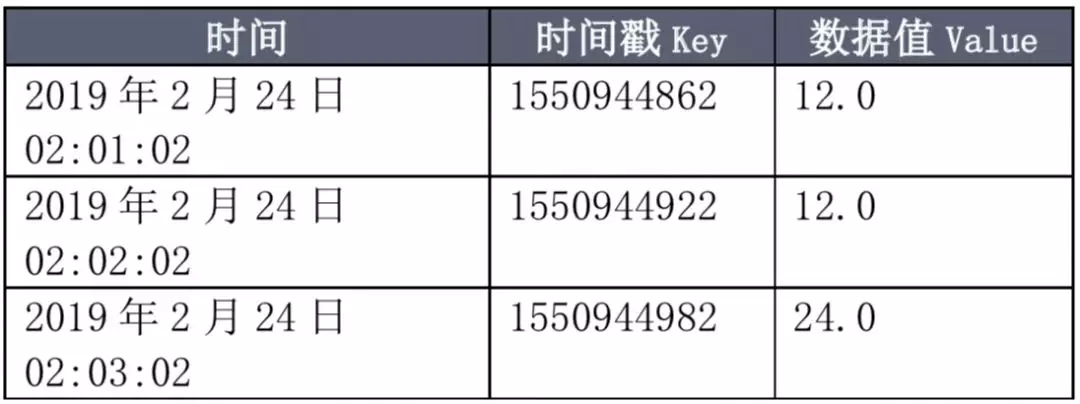
以这份数据为例,在后续介绍中我们一边介绍算法,一边采用 Gorilla 的压缩方法对这个测试数据进行压缩,观察该算法压缩效果。
压缩思想
1 基本原则
Gorilla 压缩算法,其核心思想建立在时序数据场景下,相邻的时序数据相似度很大这一特点之上。基于这个基本的原则,尽量只保留数据差异的部分,去除相同的部分,来达到压缩数据的目的。
2 数据结构
Gorilla 将数据组织成一个个数据块(Block),一个 Block 保存连续一段时间且经过压缩的时序数据。每次查询的时候会直接读取目标数据所属的 Block,对 Block 解压后返回查询结果。Facebook 经验表明,如果一个 Block 的时间跨度超过 2 小时,由于解压 Block 所消耗的资源增加,其压缩收益会逐渐降低,因此将单个 Block 的时间跨度设置为 2 小时。
每个 Block 的 Header 保存其起始时间戳(Timebase),例如如果某时序数据产生时间点是 2019/2/24 14:30,则以 2 小时为单位向上取整,该数据所属的 Block 的 Timebase 为 2019/2/24 14:00,时间戳为 1550944800 如下图所示。然后以 KV 的形式依次保存属于该 Block 的时序数据。

接下来分别介绍对 Key 和 Value 的压缩方法。
时间戳压缩
时序数据的产生,大部分都有固定的产生时间间隔,如间隔 10s、15s、60s 等。即使由于各种因素造成时序数据产生有一定延迟或者提前,但是大部分数据的时间戳间隔都是在非常接近的范围内。因此对时间戳压缩的思想就是不需要存储完整的时间戳,只存储时间戳差值的差值(delta of delta)。具体以本文测试数据的时间戳 Key 为例介绍时间戳压缩算法。
压缩前
每个秒级的时间戳用 Long 型存储(8Bytes),本文测试数据中的 3 条数据时间戳共需要占用 388 = 192(Bits)。T 均为 Unix 时间戳。
Gorilla 压缩
对于每个 Block:
1.Block 的头部 Header 存储本 Block 的起始时间戳 T-1,不做任何压缩。
2.第一个时间戳存储 T0 与 T-1 的差值(Delta),占用 14(Bits)。
3.对于本 Block 后面的时间戳 Tn:
a.计算差值的差值:
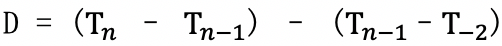
b.存在 Block 中时间戳数据由 [标识位+D 值] 组成,根据 D 的不同范围确定标识位的取值和保存 D 值所需占用的空间。如下表所示:
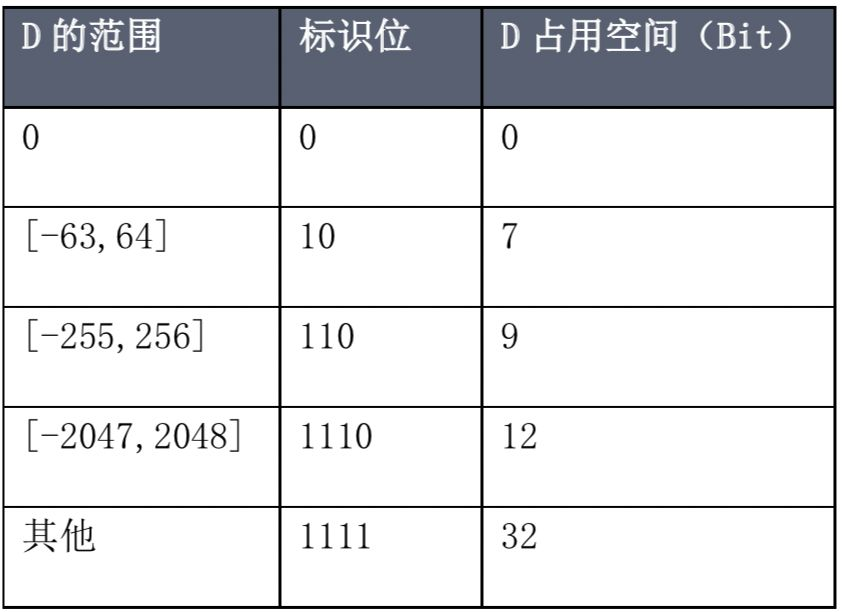
具体对于本例而言,采用上述对时间戳的压缩方式后结果如下所示:
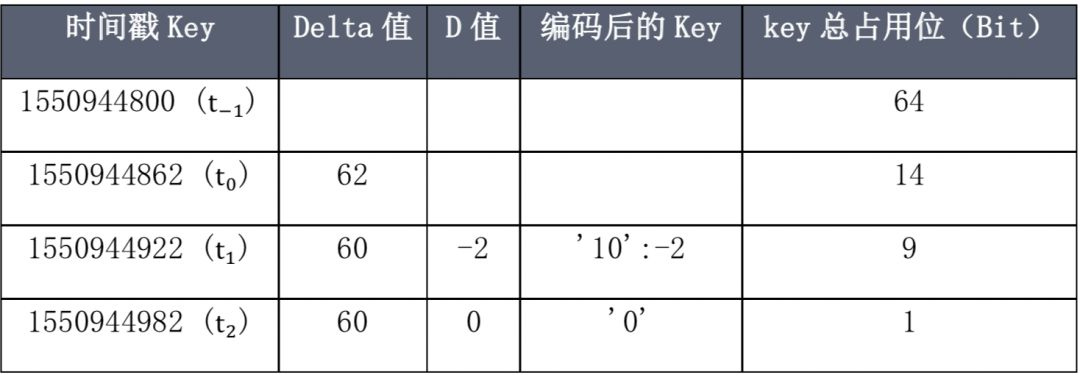
利用上述的压缩编码方式对本文的测试数据编码后,其所属的 Block 内数据如下所示:

其中只填写了 T 的部分,V 的部分由下文进行补充。经过压缩测试数据,总共占用 64+14+9+1=88(Bits),压缩率为 88/192=45.8%。
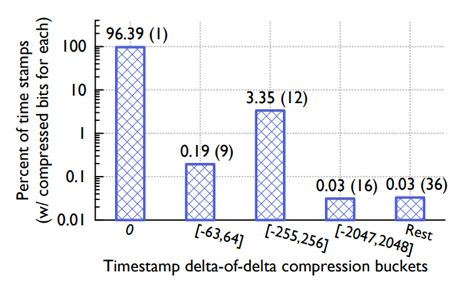
由于本例的测试数据较少,Header 空间占比较大,导致压缩收益与实际环境中收益有一定差距。在实际环境中,Header 所占有的空间相对于整个 Block 来说比例较小,压缩收益会更大。根据 Facebook 线上数据统计,如下图所示,96%的时间戳都被压缩到 1 个 Bit 来存储,因此在生产环境将会带来不错的压缩收益(结合数据分布再回过头看编码方式,是不是有点 Huffman 编码的感觉)。
数据值压缩
对时间戳 Key 压缩后,接下来对 Value 进行压缩。与 Key 类似,通过对历史数据进行分析,发现大部分相邻时间的时序数据的 Value 值比较接近(可以理解为突增/突降的现象比较少)。而如果 Value 的值比较接近,则在浮点二进制表示的情况下,相邻数据的 Value 会有很多相同的位。整数型数据的相同位会更多。相同位比较多,意味着如果进行 XOR 运算的话会有很多位都为 0。
为了便于说明,这里首先定义一个 XOR 运算后的结果由三部分组成:
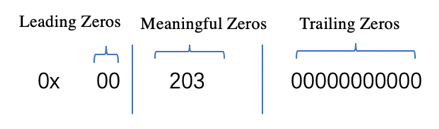
Leading Zeros(LZ): XOR 后第一个非零位前面零的个数
Trailing Zeros(TZ): XOR 后最后一个非零位后面零的个数
Meaningful Bits(MB): 中间有效位的个数
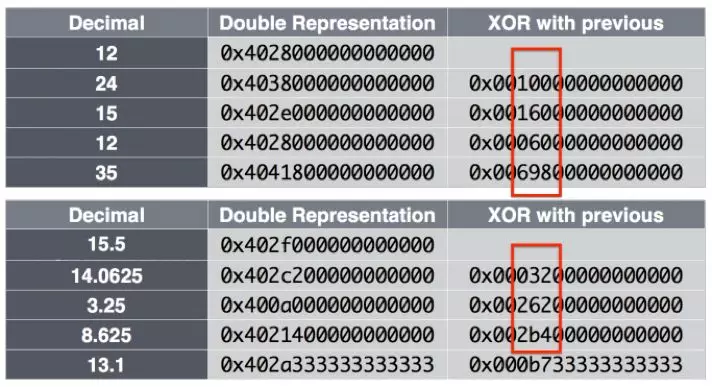
上图是 Gorilla 论文里给的示例,可以理解该数据为一系列相邻时序数据的 Value。可以看出对相邻数据进行 XOR 运算后,MB、LZ 和 TZ 非常相似。基于此,其压缩方式参考之前其他工作[2,3]已经提出的数据压缩方法,将当前值与前序值取 XOR(异或)运算,保存 XOR 运算结果。具体方式如下:
压缩前
每个浮点类型数据 Double 型存储占用 8Bytes,本文测试数据中的 3 条数据 Value 共需要占用 388 = 192(Bits)。
Gorilla 压缩
在同一个 Block 内,Value 的压缩规则如下:
1.第一个 Value 的值 V0 不压缩。
2.对于本数据块后面的 Value 值 Vn:
a.XOR 运算结果:
b.对结果进行如下处理:
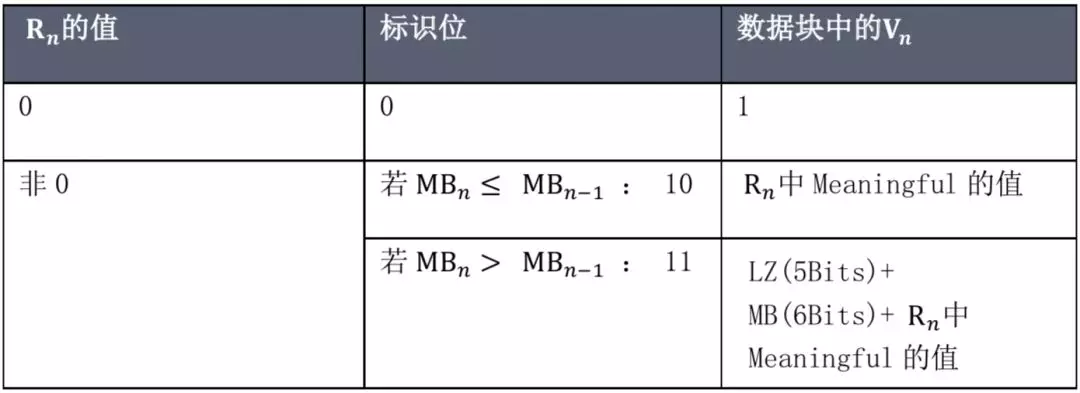
基于上述压缩编码规则,对本文测试数据的 Value 进行压缩后结果如下所示,压缩后总共占用 64+1+1+14 = 80(Bits),压缩率为 80/256=31.2%。
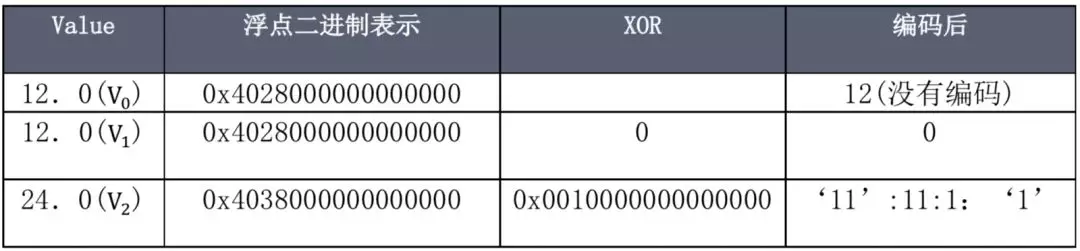
此时该 Block 内的数据如下所示:

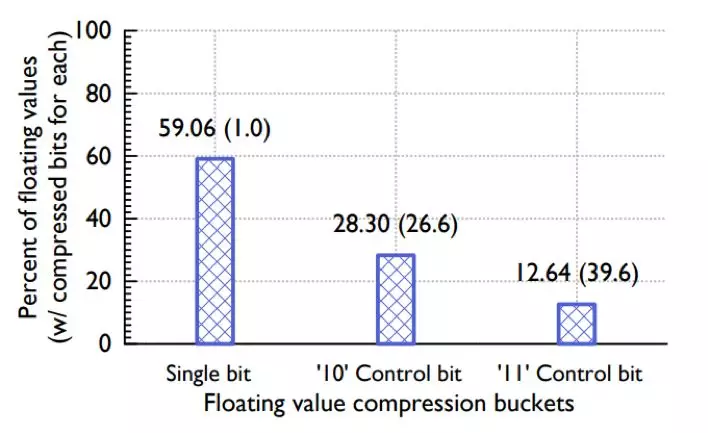
以上就是对于 Value 值的压缩方法。与 Key 的压缩一样,在线上环境数据量较多的情况下压缩效果会更好。根据 Facebook 线上数据统计,59.06%的 value 值都被压缩到 1 个位来存储。
总结
总的来说,利用上述的压缩方式,我们的测试数据由 384Bits(Key+Value)变为 168Bits,压缩率达到 43%,具有不错的压缩效率。当然由于数据量的原因,在实际生产环境下压缩收益会更大。百度 Noah 的 TSDB 在应用上述压缩算法的实践中,基于我们的实际情况进行了一定的改造(后续序列文章会另行介绍),存储空间的资源占用减少超过 70%,表明这个算法能真实有效对时序数据进行压缩。
另外一点,我们发现在做压缩的时候 Gorilla 对 Key 和 Value 分开进行了压缩处理。将 Key 和 Value 分开压缩的好处在于,可以根据 Key、Value 不同的数据类型、数据特点,选用更适合自己的压缩算法,从而提高压缩效率。在时序场景下,KV 分别处理虽然不是一个新的思想,但是可以将该思想应用在多个地方。比如本文提到的 Gorilla 是将该思想应用在压缩方面,FAST2016 年的 WiscKey[4]利用 KV 分离思想优化 LSM 的 IO 放大问题。有兴趣的读者可以针对 KV 分离方法探索一下。
由于本人水平有限,若理解不到位或者大家有任何想法,欢迎指出交流。
作者介绍:
任杰,百度高级研发工程师,负责百度智能运维产品(Noah)的分布式时序数据存储设计研发工作,在大规模分布式存储、NoSQL 数据库方面有大量实践经验。
本文转载自公众号 AIOps 智能运维(ID:AI_Ops)。
原文链接:
https://mp.weixin.qq.com/s/KKnOjvc5PthkRhNkTh6DZA

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 1 条评论