

由于神经网络模型一般非常大,因此模型压缩是当前一个比较热门的话题。彩票假设就是解决这一问题的方案之一。简单地说,就是将一个复杂网络的所有参数当作一个奖池,奖池中存在一组子参数所对应的子网络(代表中奖号码),单独训练该子网络,可以达到原始网络的测试精度。我们来看看 Jesus Rodriguez 的讲解。
在现实世界中,训练机器学习模型是数据科学解决方案中最具挑战性、也是计算成本最高的方面之一。几十年来,人工智能社区已经开发了数百种技术来改进机器学习模型的训练,这些技术都是基于一个公理假设,即训练应覆盖整个模型。最近,麻省理工学院的人工智能研究人员发表了一篇文章,挑战了这一假设,并提出了一种通过关注模型子集来训练神经网络的更智能、更简单的方法。在人工智能社区内,麻省理工学院的那篇论文被冠以“彩票假设”(Lottery Ticker Hypothesis)的名称,这一名称很容易被人记住。
论文可参阅:
训练机器学习模型的过程,是数据科学家经常面临理论与现实世界解决方案约束之间妥协的领域之一。通常情况下,对于特定问题来说,理想的神经网络架构并不能完全实现,因为训练成本过于高昂从而被禁止。一般而言,神经网络的初始训练需要大量的数据集以及昂贵的计算时间。其结果就是非常庞大的神经网络结构、神经网络与隐藏层之间的联系。这种结构往往需要经过优化技术,才能删除某些连接并调整模型的大小。
困扰人工智能研究人员几十年的问题之一就是,我们是否真的需要这些大型神经网络结构。显然,如果我们连接架构中的几乎每个神经元,我们就有可能实现一个能够执行初始任务的模型,但可能会因为高昂的成本而禁止。难道我们不能从更小、更精简的神经网络架构开始吗?这就是彩票假设提出的内容。
彩票假设
使用来自博彩业的类比,机器学习模型的训练经常被比作通过购买可能彩票来中奖。但如果我们知道中奖彩票是什么样子的话,我们不就能聪明地选择号码来购买彩票了吗?在机器学习模型中,训练过程产生的大型神经网络结构,就相当于一大袋彩票。在初始训练之后,模型需要进行优化技术,例如剪枝,去除网络中不必要的权重,从而在不牺牲性能的前提下减小模型的大小。这就相当于在一大袋彩票中寻找中奖的彩票,然后扔掉剩下的彩票。通常,剪枝技术最终会产生比原始结构小 90% 的神经网络结构。一个显而易见的问题就是,如果网络规模可以缩小,为什么我们不训练这个较小的架构,而是为了提高训练的效率呢?矛盾的是,机器学习解决方案的实践经验表明,通过修建得到的架构,从一开始就很难训练,达到的准确度比原始网络还要低。因此,你可以买一大袋彩票,然后按照自己的方式去获得中奖号码,但相反的过程太难了。我们大概是这样认为的。
麻省理工学院的彩票假设背后的主要思想是,一个大型神经网络总是包含一个较小的子网络,如果一开始就训练的话,它将获得与较大结构相似的准确度。具体而言,这篇论文概述了以下假设:
彩票假设:一个随机初始化的、密集的神经网络包含一个子网,该子网被初始化,这样当子网被单独训练时,它可以在经过最多相同迭代次数后,能够达到原始网络的测试正确度。在该论文中,较小的子网常常被称为“中奖的彩票”。
考虑一类神经网络,其形式为 f(t, a, p),其中,t 是训练时间,a 是正确度,p 是参数。现在,假设 s 是所有可训练神经网络的子集,这些神经网络来自于经剪枝过程生成的原始结构。彩票假设告诉我们,存在 f’(t’, a’, p’) € s,其中, t’<= t, a’>= a,p’<= p。简单地说,传统的剪枝技术揭示了神经网络结构,它比原始网络结构更小、更容易训练。
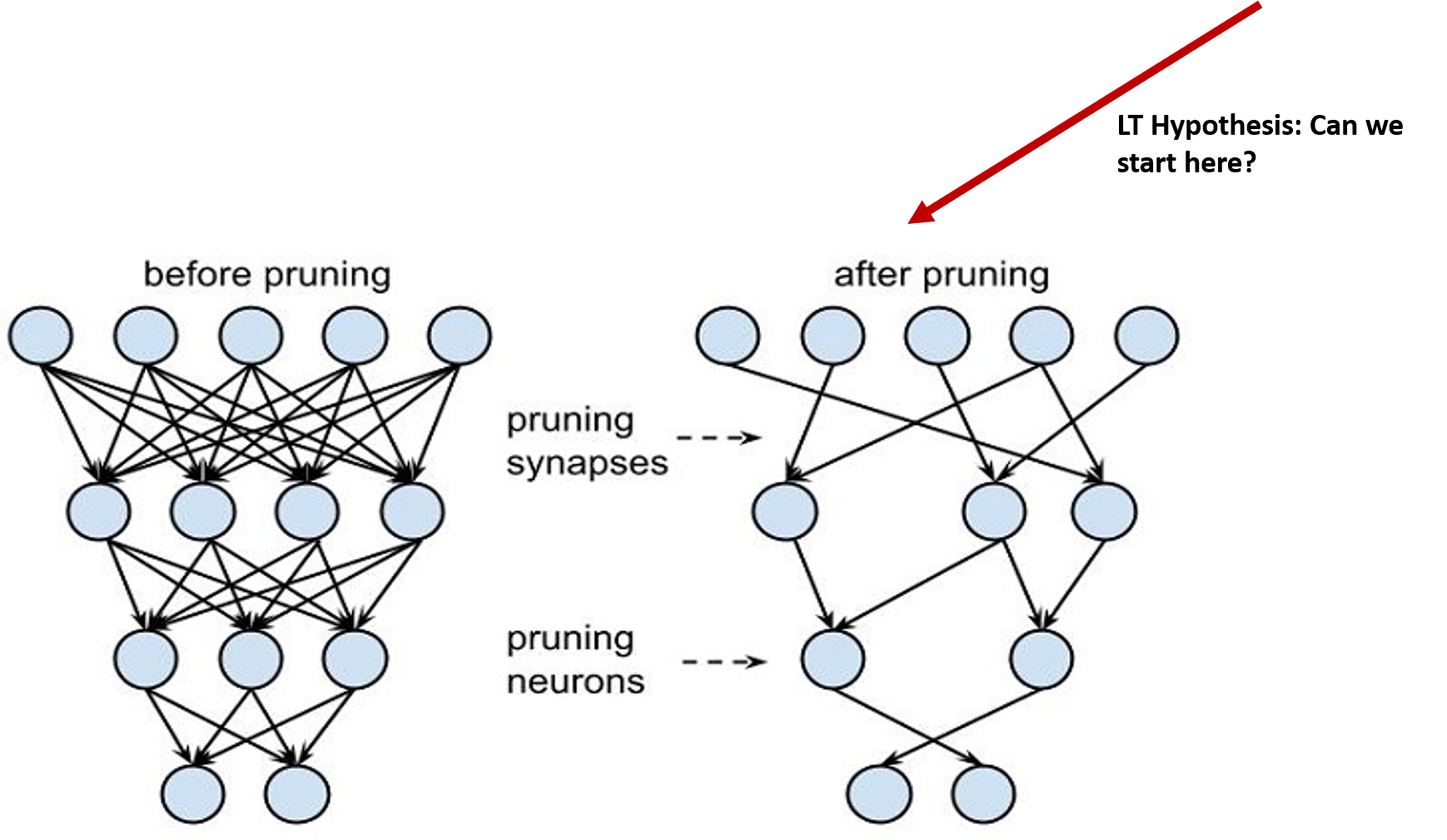
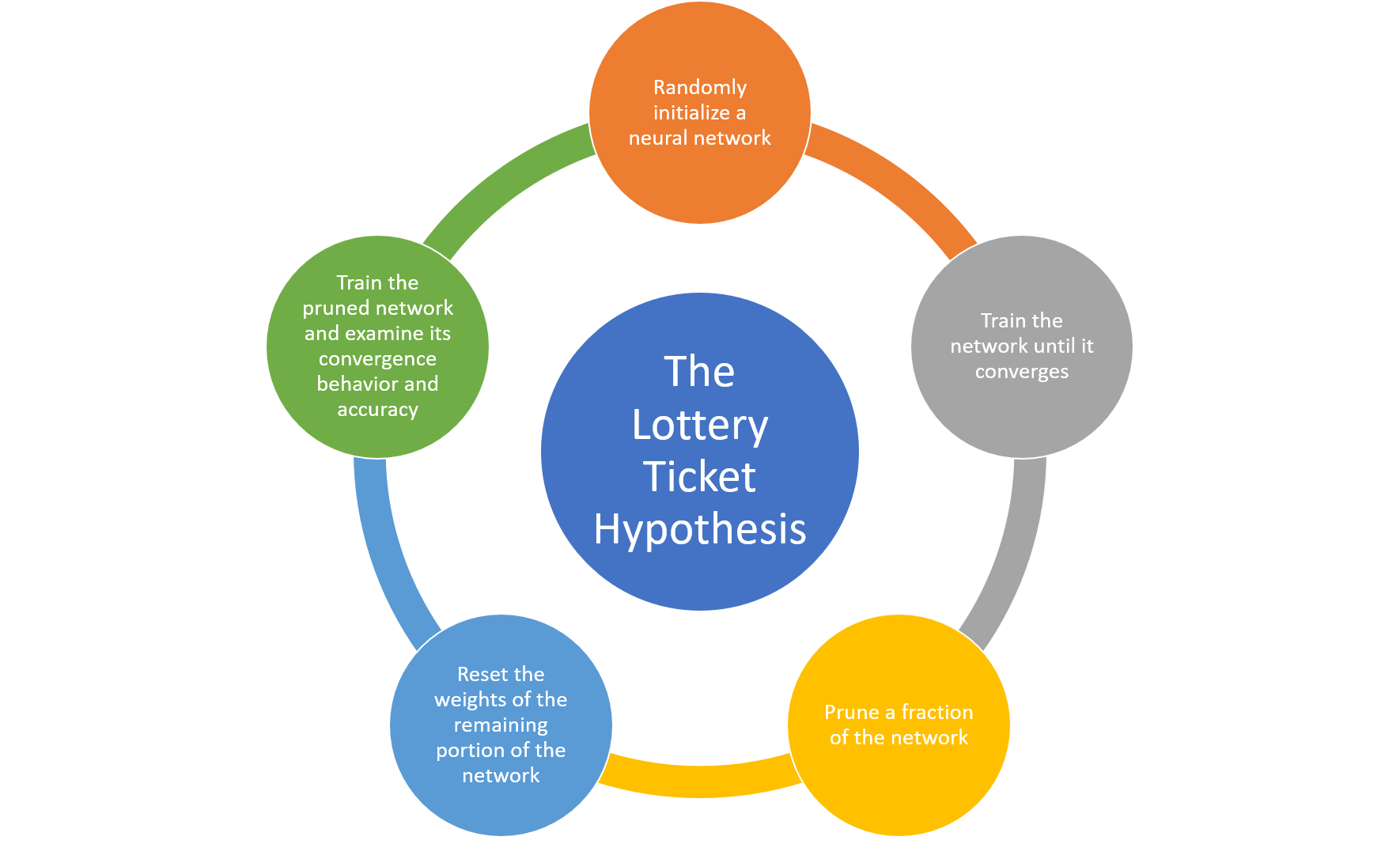
如果彩票假设是正确的,那么下一个显而易见的问题就是,找出识别中奖彩票的策略。这一过程,涉及智能训练和剪枝的迭代过程,可以总结为以下五个步骤:
随机初始化一个神经网络。
对网络进行训练,直到它收敛。
剪枝网络的一部分。
要提取中奖彩票,请将网络其余部分的权重从(1)重置为它们的值。即它们在训练开始前收到的初始化。
为了评估步骤 4 中产生的网络是否确实是中奖彩票,对经剪枝的未经训练的网络进行训练,并检查其收敛行为和正确度。
该过程可以运行一次或多次。在一次性剪枝方法中,网络被训练一次,p% 的权重值被剪枝,并对剩余的权值进行重置。虽然一次性剪枝肯定是有效的,但彩票假设表示,当该过程在 n 轮中迭代应用时,效果最好;每一轮剪枝上一轮剩余权重的 p1/n%。然而,一次性剪枝通常会得到非常可靠的结果,而无需昂贵的计算训练成本。
麻省理工学院的研究团队在一组神经网络架构中,测试了彩票假设,结果表明,剪枝方法不仅能够找到优化架构的方法,而且能够找到中奖彩票。请看以下图表:
观察这些结果中的两个主要内容。中奖彩票在没有大型网络剩余冗余的情况下,要比大型网络训练得更快。事实上,它们越精简,训练的速度就越快(在合理范围内)。但是,如果你随机重新初始化网络的权重(控制),那么生成的网络的训练速度现在要比完整的网络要慢。
根据实验结果,麻省理工学院的研究团队扩展了他们最初提出的假设,称之为“彩票系统猜想”,表达了以下内容:
彩票猜想:回到我们的动机问题,我们将假设扩展为一个未经验证的猜想,即 SGD(Stochastic Gradient Descent,随机梯度下降)寻找并训练一个初始化良好的权重子集。与剪枝后的稀疏网络相比,密集的、随机初始化的网络鞥个容易训练,因为存在更多可能的子网络,而训练可以从中恢复出中奖彩票。
这个猜想在概念上来讲似乎有道理。经剪枝后的子网池越大,就越有可能找到中奖彩票。
彩票假设对神经网络训练中的传统观点提出了挑战,有望成为近年来最重要的机器学习研究论文之一。虽然剪枝通常是通过训练原始网络、删除链接和进一步微调来进行的,但彩票假设告诉我们,从一开始就能学习到最优的神经网络结构是有可能的。


暂无签名

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论