

继续玩我们的计算图框架。这一次我们运用计算图搭建递归神经网络(RNN,Recursive Neural Network)。RNN 处理前后有承接关系的序列状数据,例如时序数据。当然,前后的承接也不一定是时间上的,但总之是有前后关系的序列。
RNN
RNN 的思想是:网络也分步,每步以输入序列的该步数据(向量)和上一步数据(第一步没有)为输入,进行变换,得到这一步的输出(向量)。这样的话,序列的每一步就会对下一步产生影响。RNN 用变换的参数把握序列每一步之间的关系。最后一步的输出可以送给全连接层,最终用于分类或回归。RNN 有很多种,有一些复杂的变体,本文搭建一种最简单的 RNN ,它的结构是这样的:
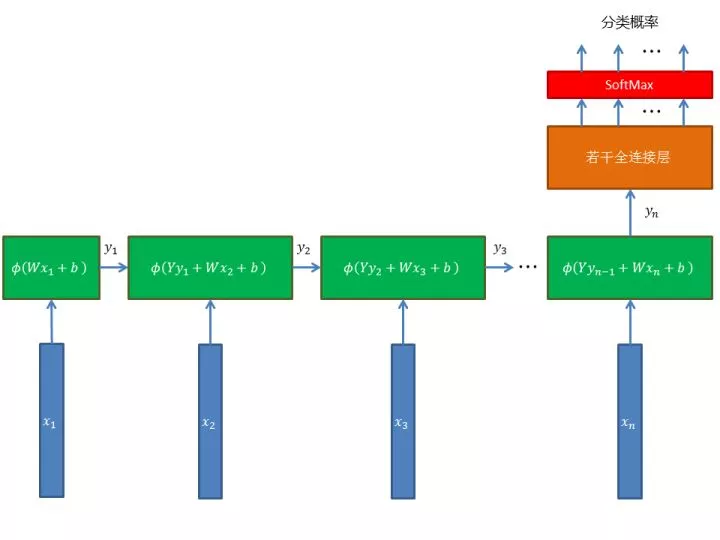
蓝色长条表示 m 维输入向量,一共 n 个。这表示数据是长度为 n 的序列,每一步是一个 m 维向量。绿色的矩形就是每一步的变换。yi 是每一步的 k 维输出向量。每一步用 k x k 的权值矩阵 Y 去乘前一步的输出向量(第一步没有),用 k x m 的权值矩阵 W 去乘这一步的输入向量,加和后再加上 k 维偏置向量 b ,施加激活函数 ϕ (我们取 ReLU),就得到这一步的输出。
最后一步的输出也是 k 维向量,把它送给全连接层,最后施加 SoftMax 后得到各个类别的概率,再接上一个交叉熵损失就可以用来训练分类问题了。用我们的计算图框架可以这样搭建这个简单的 RNN(代码):
seq_len = 96 # 序列长度dimension = 16 # 序列每一步的向量维度hidden_dim = 12 # RNN 时间单元的输出维度
# 时间序列变量,每一步一个 dimension 维向量(Variable 节点),保存在数组 input 中input_vectors = []for i in range(seq_len): input_vectors.append(Variable(dim=(dimension, 1), init=False, trainable=False)) # 对于本步输入的权值矩阵W = Variable(dim=(hidden_dim, dimension), init=True, trainable=True)
# 对于上步输入的权值矩阵Y = Variable(dim=(hidden_dim, hidden_dim), init=True, trainable=True)
# 偏置向量b = Variable(dim=(hidden_dim, 1), init=True, trainable=True)
# 构造 RNNlast_step = None # 上一步的输出,第一步没有上一步,先将其置为 Nonefor iv in input_vectors: y = Add(MatMul(W, iv), b)
if last_step is not None: y = Add(MatMul(Y, last_step), y)
y = ReLU(y)
last_step = y
fc1 = fc(y, hidden_dim, 6, "ReLU") # 第一全连接层fc2 = fc(fc1, 6, 2, "None") # 第二全连接层
# 分类概率prob = SoftMax(fc2)
# 训练标签label = Variable((2, 1), trainable=False)
# 交叉熵损失loss = CrossEntropyWithSoftMax(fc2, label)
这就是构造 RNN 以及交叉熵损失的计算图的代码,很简单,right ?有了计算图以及自动求导,我们只管搭建网络即可,网络的训练就交给计算图去做了。否则你可以想象,按照示意图表示的计算,推导交叉熵损失对 RNN 的各个权值矩阵和偏置的梯度是多么困难。
时间序列问题
我们构造一份数据,它包含两类时间序列,一类是方波,一类是正弦波,代码如下:
def get_sequence_data(number_of_classes=2, dimension=10, length=10, number_of_examples=1000, train_set_ratio=0.7, seed=42): """ 生成两类序列数据。 """ xx = [] xx.append(np.sin(np.arange(0, 10, 10 / length))) # 正弦波 xx.append(np.array(signal.square(np.arange(0, 10, 10 / length)))) # 方波
data = [] for i in range(number_of_classes): x = xx[i] for j in range(number_of_examples): sequence = x + np.random.normal(0, 1.0, (dimension, len(x))) # 加入高斯噪声 label = np.array([int(i == j) for j in range(number_of_classes)])
data.append(np.c_[sequence.reshape(1, -1), label.reshape(1, -1)])
# 把各个类别的样本合在一起 data = np.concatenate(data, axis=0)
# 随机打乱样本顺序 np.random.shuffle(data)
# 计算训练样本数量 train_set_size = int(number_of_examples * train_set_ratio) # 训练集样本数量
# 将训练集和测试集、特征和标签分开 return (data[:train_set_size, :-number_of_classes], data[:train_set_size, -number_of_classes:], data[train_set_size:, :-number_of_classes], data[train_set_size:, -number_of_classes:])
我们用这一行代码获取长度为 96 ,维度为 16 的两类(各 1000 个)序列:
# 获取两类时间序列:正弦波和方波train_x, train_y, test_x, test_y = get_sequence_data(length=seq_len, dimension=dimension)
看一看时间序列样本,先看正弦波:
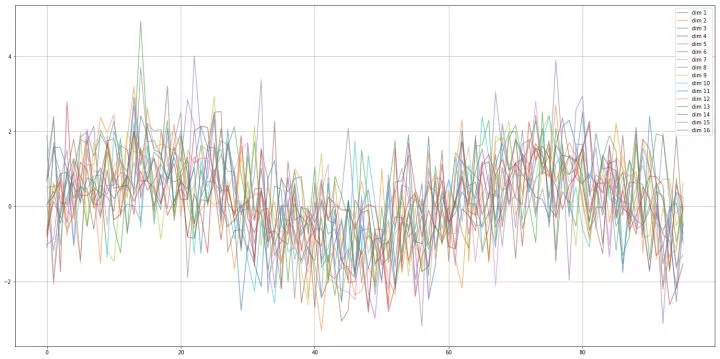
正弦波序列
这是一个正弦波时间序列样本,它包含 16 条曲线,每一条都是 sin 曲线加噪声。之所以包含 16 条曲线,因为我们的时间序列的每一步是一个 16 维向量,按时间列起来就有了 16 条正弦曲线。正弦波时间序列是我们的正样本。方波时间序列是负样本:
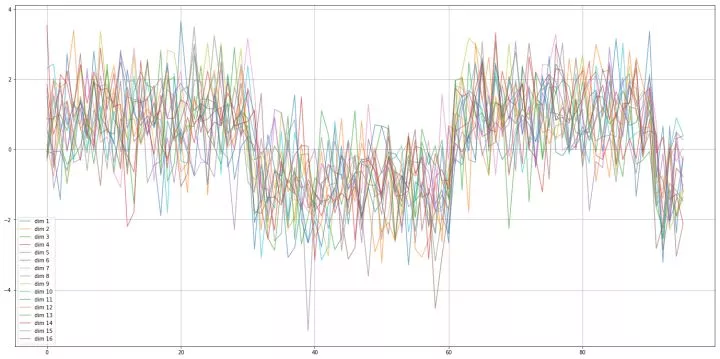
方波序列
一个方波时间序列先维持 +1 一段时间,变为 -1 维持一段时间,再回到 +1 ,循环往复。由于我们的高斯噪声加得较大,可以看到正弦波和方波还是有可能混淆的,但也能看出它们之间的差异。
训练
现在就用我们构造的 RNN 训练一个分类模型,分类正弦波和方波,代码如下:
from sklearn.metrics import accuracy_score
from layer import *from node import *from optimizer import *
seq_len = 96 # 序列长度dimension = 16 # 序列每一步的向量维度hidden_dim = 12 # RNN 时间单元的输出维度
# 获取两类时间序列:正弦波和方波train_x, train_y, test_x, test_y = get_sequence_data(length=seq_len, dimension=dimension)
# 时间序列变量,每一步一个 dimension 维向量(Variable 节点),保存在数组 input 中input_vectors = []for i in range(seq_len): input_vectors.append(Variable(dim=(dimension, 1), init=False, trainable=False)) # 对于本步输入的权值矩阵W = Variable(dim=(hidden_dim, dimension), init=True, trainable=True)
# 对于上步输入的权值矩阵Y = Variable(dim=(hidden_dim, hidden_dim), init=True, trainable=True)
# 偏置向量b = Variable(dim=(hidden_dim, 1), init=True, trainable=True)
# 构造 RNNlast_step = None # 上一步的输出,第一步没有上一步,先将其置为 Nonefor iv in input_vectors: y = Add(MatMul(W, iv), b)
if last_step is not None: y = Add(MatMul(Y, last_step), y)
y = ReLU(y)
last_step = y
fc1 = fc(y, hidden_dim, 6, "ReLU") # 第一全连接层fc2 = fc(fc1, 6, 2, "None") # 第二全连接层
# 分类概率prob = SoftMax(fc2)
# 训练标签label = Variable((2, 1), trainable=False)
# 交叉熵损失loss = CrossEntropyWithSoftMax(fc2, label)
# Adam 优化器optimizer = Adam(default_graph, loss, 0.005, batch_size=16)
# 训练print("start training", flush=True)for e in range(10):
for i in range(len(train_x)): x = np.mat(train_x[i, :]).reshape(dimension, seq_len) for j in range(seq_len): input_vectors[j].set_value(x[:, j]) label.set_value(np.mat(train_y[i, :]).T)
# 执行一步优化 optimizer.one_step()
if i > 1 and (i + 1) % 100 == 0:
# 在测试集上评估模型正确率 probs = [] losses = [] for j in range(len(test_x)): # x = test_x[j, :].reshape(dimension, seq_len) x = np.mat(test_x[j, :]).reshape(dimension, seq_len) for k in range(seq_len): input_vectors[k].set_value(x[:, k]) label.set_value(np.mat(test_y[j, :]).T)
# 前向传播计算概率 prob.forward() probs.append(prob.value.A1)
# 计算损失值 loss.forward() losses.append(loss.value[0, 0])
# print("test instance: {:d}".format(j))
# 取概率最大的类别为预测类别 pred = np.argmax(np.array(probs), axis=1) truth = np.argmax(test_y, axis=1) accuracy = accuracy_score(truth, pred)
default_graph.draw() print("epoch: {:d}, iter: {:d}, loss: {:.3f}, accuracy: {:.2f}%".format(e + 1, i + 1, np.mean(losses), accuracy * 100), flush=True)
训练 10 个 epoch 后,测试集上的正确率达到了 99% :
epoch: 1, iter: 100, loss: 0.693, accuracy: 51.08%epoch: 1, iter: 200, loss: 0.692, accuracy: 51.08%epoch: 1, iter: 300, loss: 0.677, accuracy: 78.31%epoch: 1, iter: 400, loss: 0.573, accuracy: 49.31%epoch: 1, iter: 500, loss: 0.520, accuracy: 53.92%epoch: 1, iter: 600, loss: 0.599, accuracy: 97.08%epoch: 1, iter: 700, loss: 0.617, accuracy: 99.00%epoch: 2, iter: 100, loss: 0.601, accuracy: 94.46%epoch: 2, iter: 200, loss: 0.579, accuracy: 82.08%epoch: 2, iter: 300, loss: 0.558, accuracy: 76.15%epoch: 2, iter: 400, loss: 0.531, accuracy: 67.85%epoch: 2, iter: 500, loss: 0.507, accuracy: 63.77%epoch: 2, iter: 600, loss: 0.493, accuracy: 61.15%epoch: 2, iter: 700, loss: 0.479, accuracy: 62.23%epoch: 3, iter: 100, loss: 0.443, accuracy: 69.92%epoch: 3, iter: 200, loss: 0.393, accuracy: 85.85%epoch: 3, iter: 300, loss: 0.365, accuracy: 97.69%epoch: 3, iter: 400, loss: 0.284, accuracy: 95.08%epoch: 3, iter: 500, loss: 0.199, accuracy: 95.69%epoch: 3, iter: 600, loss: 0.490, accuracy: 80.62%epoch: 3, iter: 700, loss: 0.264, accuracy: 94.31%epoch: 4, iter: 100, loss: 0.320, accuracy: 83.46%epoch: 4, iter: 200, loss: 0.333, accuracy: 80.92%epoch: 4, iter: 300, loss: 0.276, accuracy: 90.15%epoch: 4, iter: 400, loss: 0.242, accuracy: 95.00%epoch: 4, iter: 500, loss: 0.217, accuracy: 96.38%epoch: 4, iter: 600, loss: 0.191, accuracy: 95.31%epoch: 4, iter: 700, loss: 0.167, accuracy: 94.00%epoch: 5, iter: 100, loss: 0.142, accuracy: 94.62%epoch: 5, iter: 200, loss: 0.111, accuracy: 96.85%epoch: 5, iter: 300, loss: 0.116, accuracy: 96.85%epoch: 5, iter: 400, loss: 0.080, accuracy: 96.77%epoch: 5, iter: 500, loss: 0.059, accuracy: 98.54%epoch: 5, iter: 600, loss: 0.054, accuracy: 98.54%epoch: 5, iter: 700, loss: 0.042, accuracy: 99.00%epoch: 6, iter: 100, loss: 0.047, accuracy: 98.46%epoch: 6, iter: 200, loss: 0.049, accuracy: 98.08%epoch: 6, iter: 300, loss: 0.030, accuracy: 99.15%epoch: 6, iter: 400, loss: 0.029, accuracy: 99.23%epoch: 6, iter: 500, loss: 0.028, accuracy: 99.08%epoch: 6, iter: 600, loss: 0.029, accuracy: 99.08%epoch: 6, iter: 700, loss: 0.024, accuracy: 99.15%epoch: 7, iter: 100, loss: 0.023, accuracy: 99.15%epoch: 7, iter: 200, loss: 0.031, accuracy: 98.85%epoch: 7, iter: 300, loss: 0.023, accuracy: 99.46%epoch: 7, iter: 400, loss: 0.022, accuracy: 99.54%epoch: 7, iter: 500, loss: 0.022, accuracy: 99.38%epoch: 7, iter: 600, loss: 0.027, accuracy: 98.77%epoch: 7, iter: 700, loss: 0.019, accuracy: 99.46%epoch: 8, iter: 100, loss: 0.018, accuracy: 99.54%epoch: 8, iter: 200, loss: 0.018, accuracy: 99.46%epoch: 8, iter: 300, loss: 0.018, accuracy: 99.54%epoch: 8, iter: 400, loss: 0.018, accuracy: 99.62%epoch: 8, iter: 500, loss: 0.017, accuracy: 99.54%epoch: 8, iter: 600, loss: 0.026, accuracy: 99.00%epoch: 8, iter: 700, loss: 0.021, accuracy: 99.23%epoch: 9, iter: 100, loss: 0.017, accuracy: 99.62%epoch: 9, iter: 200, loss: 0.016, accuracy: 99.54%epoch: 9, iter: 300, loss: 0.015, accuracy: 99.54%epoch: 9, iter: 400, loss: 0.014, accuracy: 99.69%epoch: 9, iter: 500, loss: 0.014, accuracy: 99.62%epoch: 9, iter: 600, loss: 0.014, accuracy: 99.69%epoch: 9, iter: 700, loss: 0.014, accuracy: 99.62%epoch: 10, iter: 100, loss: 0.014, accuracy: 99.54%epoch: 10, iter: 200, loss: 0.014, accuracy: 99.54%epoch: 10, iter: 300, loss: 0.015, accuracy: 99.69%epoch: 10, iter: 400, loss: 0.014, accuracy: 99.69%epoch: 10, iter: 500, loss: 0.013, accuracy: 99.62%epoch: 10, iter: 600, loss: 0.016, accuracy: 99.38%epoch: 10, iter: 700, loss: 0.017, accuracy: 99.38%
这就是我们的简单 RNN ,以后有机会我们再尝试搭建类似 LSTM 这种更复杂的 RNN 。
作者介绍:
张觉非,本科毕业于复旦大学,硕士毕业于中国科学院大学,先后任职于新浪微博、阿里,目前就职于奇虎 360,任机器学习技术专家。
本文来自 DataFun 社区
原文链接:
更多内容推荐
阿里:Behavior Sequence Transformer 解读
现在深度学习已经广泛应用到了各种CTR预估模型中
07|AIGC 的核心魔法:搞懂 Transformer
我们只有真正理解了Transformer,才算是进入了当下AIGC世界的大门。
2023-07-31
12|深度学习(中):如何用 RNN 预测激活率走势?
RNN和其它类型的神经网络相比,它的特点是建立了自身的记忆机制,善于根据历史信息预测后续走势。
2021-09-24
颠覆者扩散模型:直观去理解加噪与去噪
扩散模型的工作原理是怎样的呢?算法优化目标是什么?与GAN相比有哪些异同?这一讲我们便从这些基础问题出发,开始我们的扩散模型学习之旅。
2023-07-28
贝壳用户偏好挖掘的思考与实践
用户偏好,即对用户内在需求的具体刻画。通过用户的历史行为和数据,对用户进行多角度全方位的刻画与描述,利用统计分析或算法,来挖掘出用户潜在的需求倾向。
Transformer 在推荐模型中的应用总结
最近基于transformer的一些NLP模型很火(比如BERT,GPT-2等)
深度广度模型在用户购房意愿量化的应用
在部分场景如点击率预估中,输入的特征一般为大规模稀疏矩阵,如何对输入进行有效表达就成了深度学习在点击率预估中应用的关键所在。
机器学习模型在携程海外酒店推荐场景中的应用
酒店涉及到的推荐场景较多,例如城市热门酒店推荐、附近同类型酒店推荐、机票页酒店交叉推荐、Meta着陆页相似酒店推荐、信息流推荐等。 大部分场景都实现了个性化的推荐服务,其核心就是一组酒店与一组用户相匹配的挑战。本文介绍机器学习模型在携程海外酒店推荐场景中的应用。
21|YouTubeDNN:召回算法的后起之秀(上)
在前面的课程中,我们讲解了几种不同的召回算法,在这节课中,我们会继续前面的课程,学习一个新的召回算法——YouTubeDNN模型。
2023-06-02
深度学习基础:你打牢深度学习知识的地基了吗?
无论是单个神经元,还是结构非常复杂的深度学习网络,在推荐系统场景下,它们都是用来预测用户对某个物品的感兴趣程度的。
2020-09-28
从 MLP 到 Self-Attention,一文总览用户行为序列推荐模型
本文介绍用户行为序列上的推荐模型。
多任务学习在推荐算法中的应用(一)
本文主要总结了近两年工业界关于 Multi-task 模型在推荐场景的一些应用和工作。
阿里 Deep Interest Evolution Network 解读
对CTR预测模型来讲,通过用户行为数据来发掘潜在的用户兴趣特征是很有必要的。
深度学习在高德 POI 鲜活度提升中的演进
本文对深度学习技术在高德地图落地的过程中遇到的业务难点,和经过实践检验的可行方案进行系统性的梳理总结。
Embedding 在推荐算法中的应用总结
Embedding向量作为推荐算法中必不可少的部分
周期性时间序列的预测
OpsDev,转载已获取作者授权。最近在研究时间序列的时候,发现很多序列具有很强的周期性,那如何对此类序列进行预测呢?
Multi-task 多任务模型在推荐算法中应用
CVR是指从点击到购买的转化,传统的CVR预估会存在两个问题
深度学习入门(一):神经网络
本文节选自图灵程序设计丛书 《深度学习入门》一书中的部分章节。
深度广度模型在用户购房意愿量化的应用
本文主要介绍了深度广度模型在用户价值量化上的应用,包括wide&deep的应用与迭代,端到端与预训练的讨论以及时序模型与深度广度模型的结合,在预测结果上也取得了较为明显的正向收益,提高了头部准确率。
Embedding+MLP:如何用 TensorFlow 实现经典的深度学习模型?
你知道微软在2016年提出的深度学习模型Deep Crossing吗?它就属于经典的Embedding+MLP模型。
2020-11-18
推荐阅读
08|巧用神经网络:如何用 UNet 预测噪声
2023-08-02
12|博观约取:重走 NLP 领域预训练模型的长征路
2023-09-06
深度学习基础入门篇 [10]:序列模型 - 词表示{One-Hot 编码、Word Embedding、Word2Vec、词向量的一些有趣应用}
2023-05-23
20|ControlNet:出道即巅峰,构图控制没有对手
2023-09-01
从头开始(概率)学 HMM:精讲第三课 - 概率计算问题
2021-10-07
机器学习之 PyTorch 和 Scikit-Learn 第 2 章 为分类训练简单机器学习算法
2023-07-13
LSTM 的兴衰
电子书

大厂实战PPT下载
换一换 
马春辉 | 字节跳动 高级工程师
谢淼 博士 | 快手 高级算法专家
李成栋 | 码题诗(杭州)科技有限公司 创始人






评论