

嘉宾:赵明
整理:李慧文
通常 AI 模型的测试需要依赖高质量的标注数据,不过在不同的应用场景下,所需要的数据标注体量存在差异。QCon 全球软件开发大会(2021)北京站上,好未来 AI 研究院赵明分享了好未来通过借助语音、图像、NLP 等 AI 模型进行有机组合,加入预处理和后处理过程,搭建自动化流水线,在不依赖于标注数据的情况下,对被测模型进行 Badcase 的自动化筛选,从而提高测试效率,辅助算法角色提升算法模型的优化迭代速度的真实案例。
赵老师的演讲很受听众欢迎,所以我们整理了他的演讲内容,分享给你。
AI 中台业务、技术背景与工作痛点
好未来 AI 研究院研究的是在教育场景下如何通过 AI 提升用户体验,提高整体运营效率。我今天会分享我院实践中的痛点及解决方案,包含在细分领域中筛选 Badcase 的方案,如何通过平台化整合这些方案便捷地做根因分析、Badcase 定位,以及对 AI 研发提效的探索。
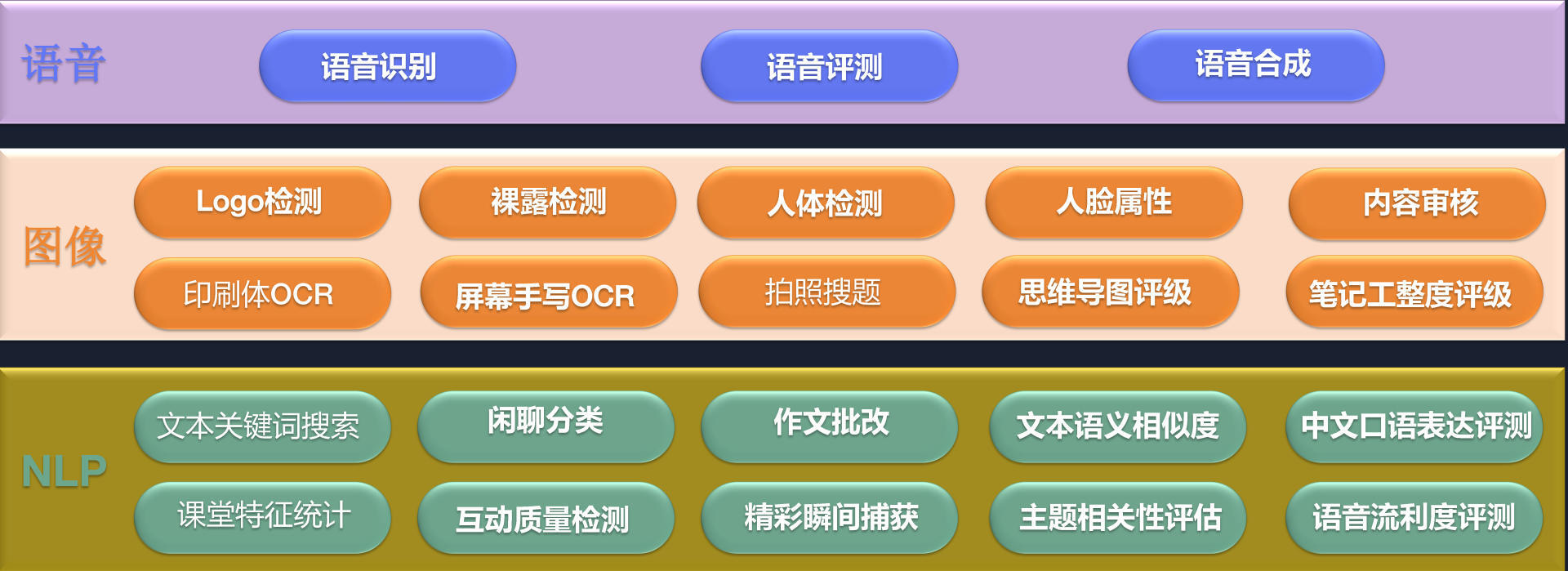
AI 覆盖了好未来教育业务的方方面面,具体分为三个方向:语音类、图像类和 NLP。语音类包括语音的识别、评测和合成;图像类包括内容审核、印刷体或屏幕手写 OCR(Optical Character Recognition,光学字符识别)、拍照搜题、笔记工整度评级等;NLP 领域包括课堂特征统计,互动质量检测、作文批改等。
通过 AI 虽能大幅度降低人工成本,但实践中仍有很多痛点。第一,教育场景碎片化,分为不同的学科、年级、班次、地区,每个细分场景都需要定制化 AI 能力。
第二,评估需要持续获取线上反馈,即大量高质量人工标注数据。人工标注和质检成本高,周期长,难以常态化运营。
第三,造成 Badcase 的因素较多,如数据、预处理、模型参数、模型本身泛化能力及鲁棒性等,导致 Badcase 定位难,周期长。
基于以上痛点,我们设计了以下筛选 Badcase 的流水线。
TTS 语音合成 Badcase 自动化筛选方案
TTS 语音合成是将文本自动合成音频,要求不能吞音丢字、不能有机械音、停顿及语气要与常人讲话相仿。
通过人工打分测评合成语音质量不仅效率低,且主观性较强,需要多人评测才能获得较客观的分数,因此我们研发了如下流水线,分为四步。
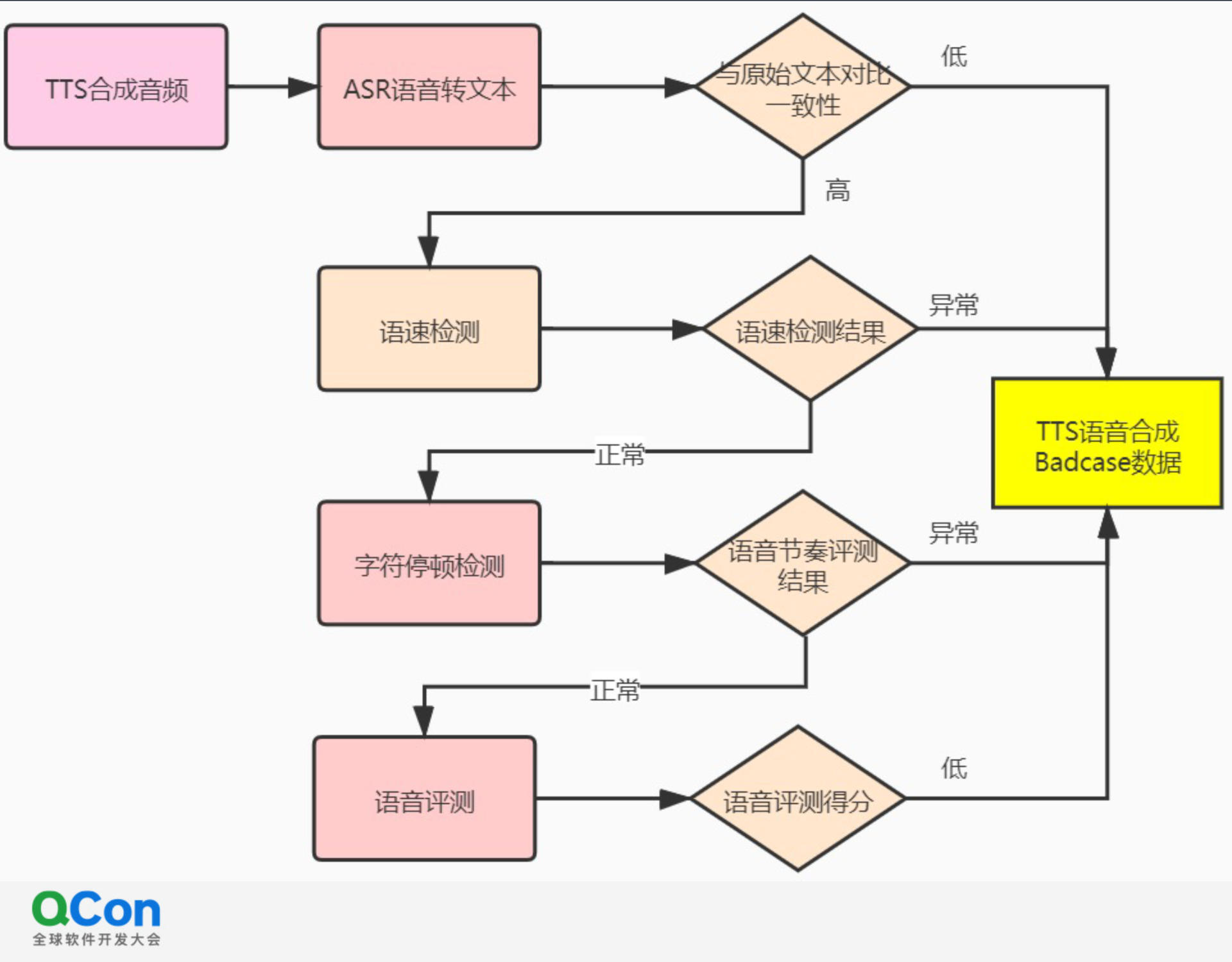
首先,将 TTS 合成的音频输入一个文本转录模型(ASR)中,该模型会将收到的音频转化为新文本,对比该文本和原始文本的一致性,即可初步判断合成语音的质量。对比一致性可以使用莱温斯坦比或 CER、WER 等指标,差异较大或字词错率较高时即为 Badcase。
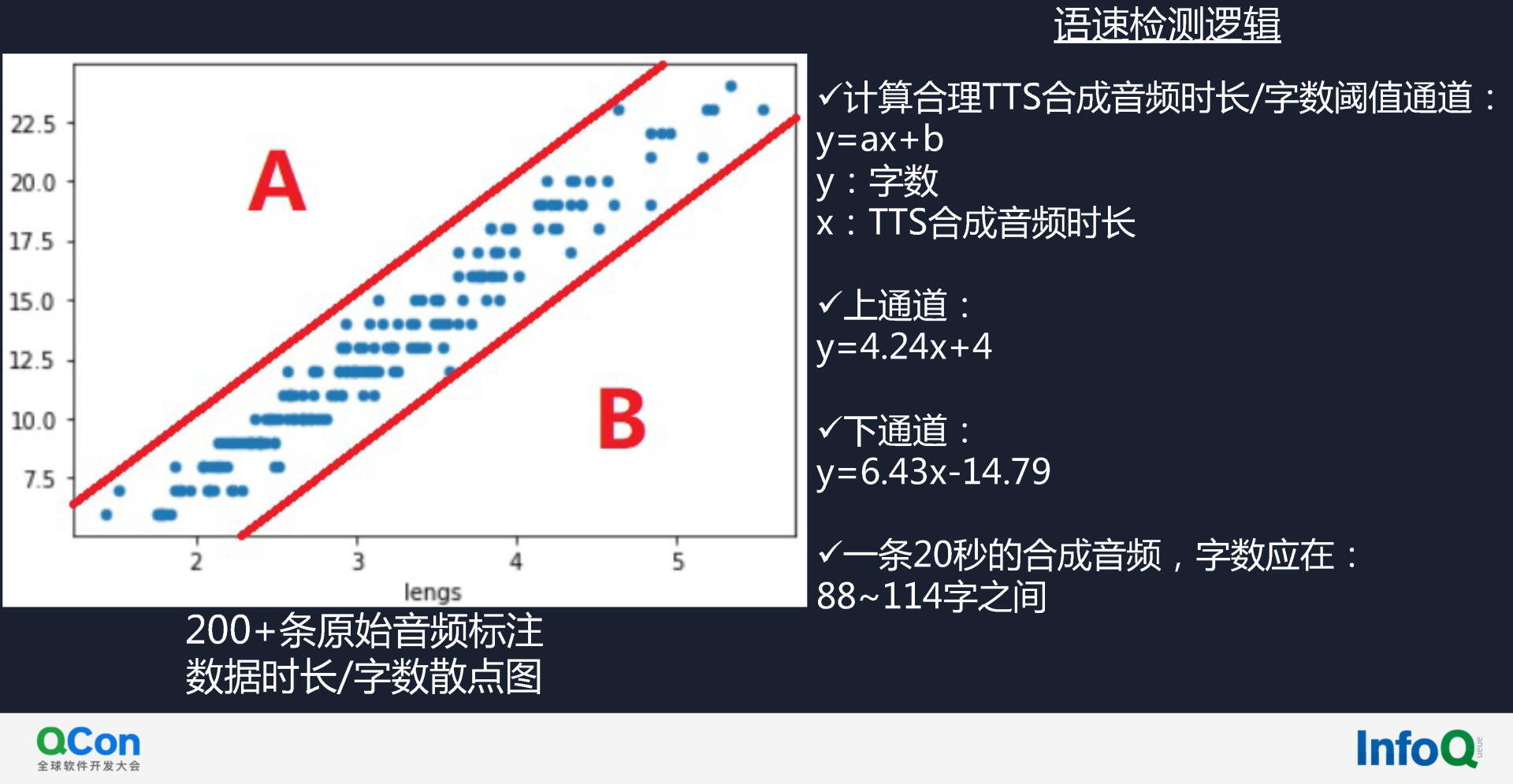
第二,将语音输入语速检测模型中,检查该语音能否和预标注数据的整体趋势相拟合,进行宏观校验。过程如下图所示,图中原始的音频已有标注,是训练的样本。该样本的音频时长和字数的关系如散点图所示,数据点集中在一个通道中,字数和音频的时长有线性关系,A、B 两个区域的数据点即为语速异常的 Badcase。
第三,通过工程的方式即对比 JSON 文件进行字符停顿检测,检查合成音频断句停顿是否符合人类语言节奏,进行微观校验。我将图中的静音检测标黄了,读图可得 1.0 版本的断句为“天气/很晴朗”,但 1.1 版本成了“天/气很晴朗”,停顿出错。

音频打点是用 ARS(Automatic Speech Recognition,自动语音识别技术),获取每一个字起始和结束的时间点及时间间隔。
最后,通过语音评测模型,以流利度、音色标准为指标为合成语音和人类语音拟合程度打分。如果得分较低,则证明存在一定的机械音,需要作为 Badcase 处理。
该方案只要有回流的数据,即可迅速发现线上合成音频的问题,召回率达到了 99%,基本不会漏检,但可能会误检,需要人工复核。
OCR Badcase 自动化筛选方案
搜题是凭借题目的照片,调用 OCR 将图片转换成文本,去题库中搜索正确答案。OCR 场景的技术难关是处理由拍摄光线、拍摄角度、手写和印刷混排等原因造成的低质图片。
我们先初步筛选线上回流数据,随后通过图像质量检测模型筛选出低质数据,将低质数据同时输入两个模型:OCR 被测模型和数据增强模型。
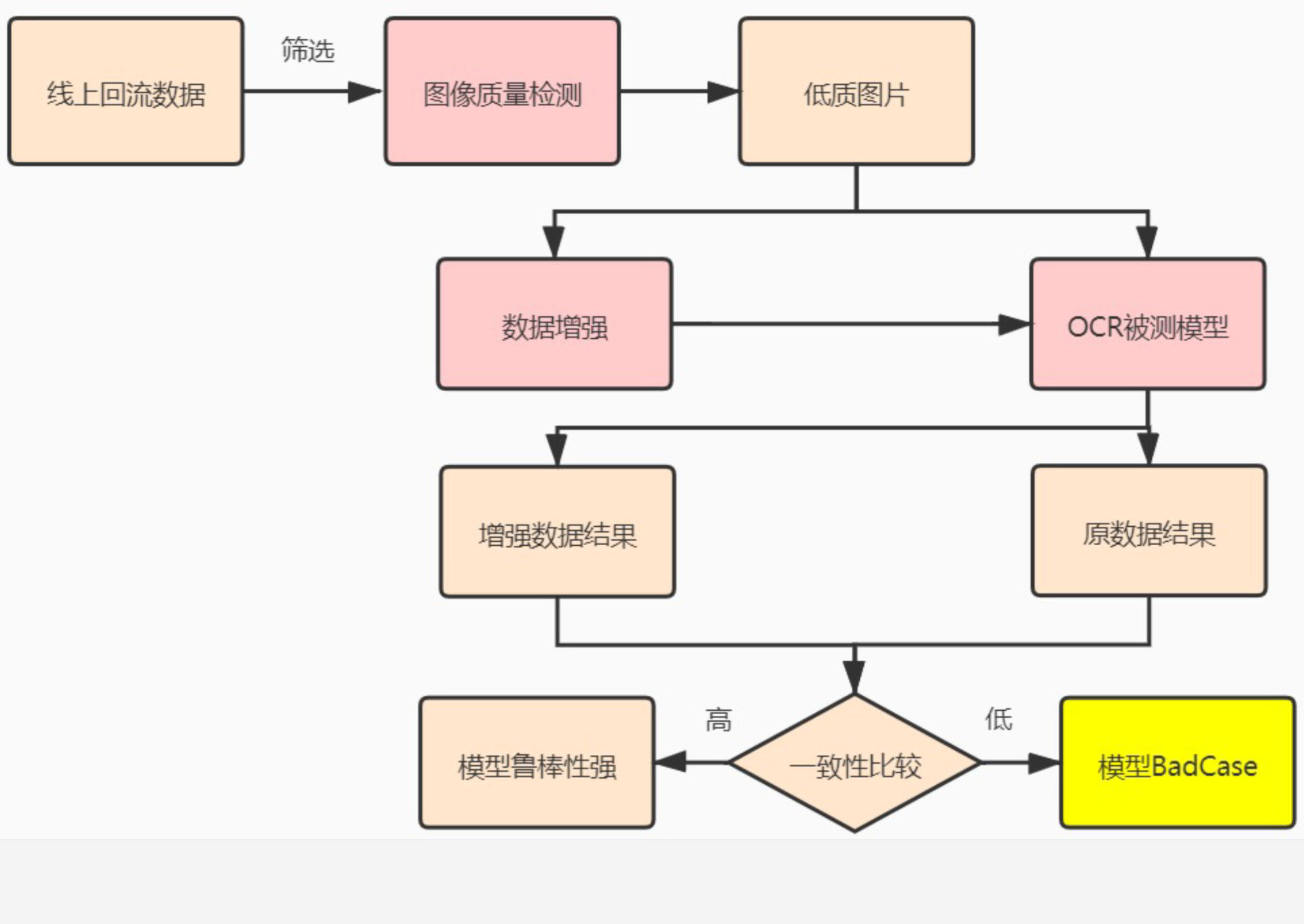
数据增强模型通过可以调亮过暗图片、调整过曝图片的对比度等等,提高模型识别准确率。对比 OCR 被测模型和数据增强模型的结果,差异越大说明模型拟合效果越差,即为 Badcase。下图为该方案的案例:

原始输出结果经过了去雾、清晰增强、对比增强、图像增强等处理后,输出结果增多,效果较好。增强后模型效果好,即证明原模型鲁棒性较差,需要将该数据同步算法工程师进行定向优化。通过提高图像质量检测模型的精度,也可以实现本功能。实际上线效果如下图所示:
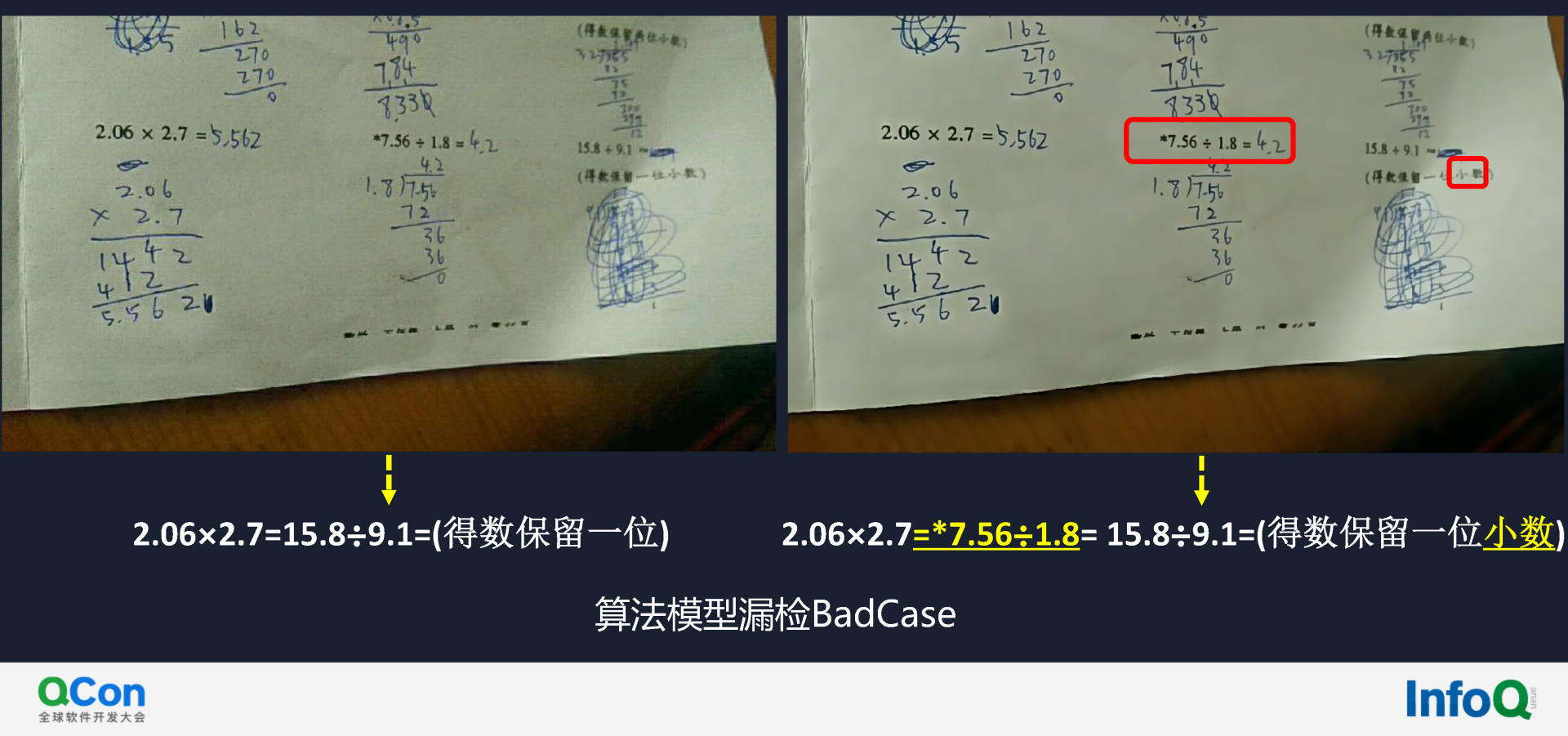
左侧图片经过数据增强后结果如右图所示,此时机器可识别红框中的内容。通过计算莱温斯坦比可得黄色的文字,即漏检的文本信息。
传统的方式很难从亿级别数据中找到有问题的数据,通过该流水线能够提效至少 50%,成本也会大幅度降低。
NLP 作文批改 Badcase 自动化筛选方案
作文批改是先通过 OCR 手写体识别获取文本信息,将其送入 NLP 模型,识别及纠正其中的错别字,将修辞的手法(如夸张、比喻、拟人)作为量化评估的方法,评估该作文的水平。
好未来作文批改的 Badcase 自动化筛选模型分为两条路线,如下图所示:
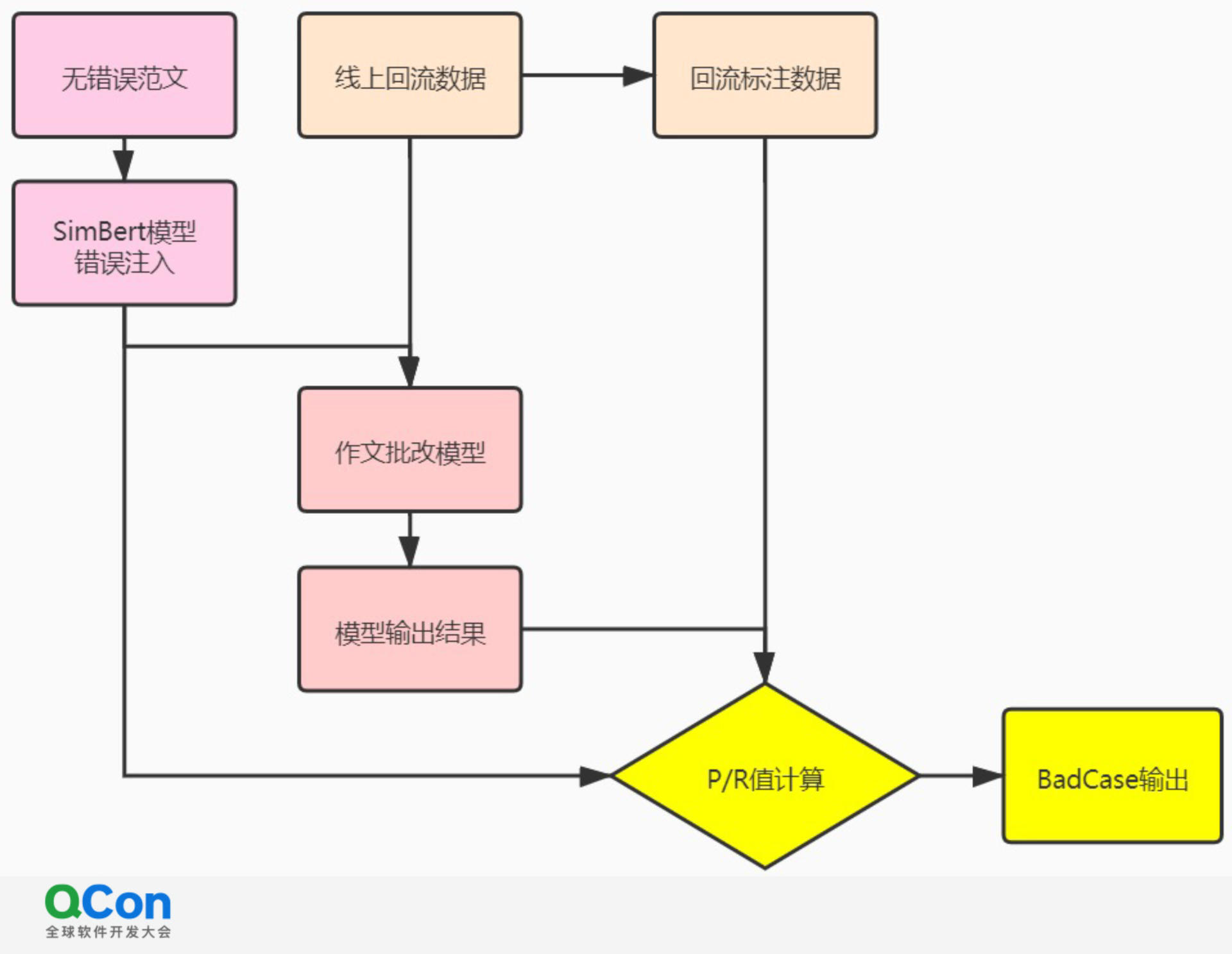
左侧路线是调用 SimBert 模型(可在 GitHub 上搜到),获取形似字、易错字、近义词等作为错误插入范文,将含错范文输入作文批改模型。如该模型能正确检测出插入的多数错误, 则 P/R 值高,如遗漏率高,则为 Badcase。因为前置处理 OCR 精度无法达到 1,所以本流水线需要兼容或部分兼容前置 OCR 的错误。
前期模型无法检测出某些语法错误,所以需补充右侧路线:人工标注回流数据,结合左侧路线共同判别 Badcase。
该流水线实现了每日消息无人值守:首先在凌晨进行线上回流数据的清洗、脱敏,随后将所得部分数据的子集输入该流水线,即可得到昨日线上的高疑似 Badcase。将所有 Badcase 整理为 List,即可供进一步调优和根因分析以及后期模型的迭代优化使用。
AI 模型指标评测平台化整合
图像、语音、NLP 等各大能力虽然逻辑简单,但每个子模型的输入输出均不完全相同,对平台的整合挑战巨大。我们设计了如下分层方案。
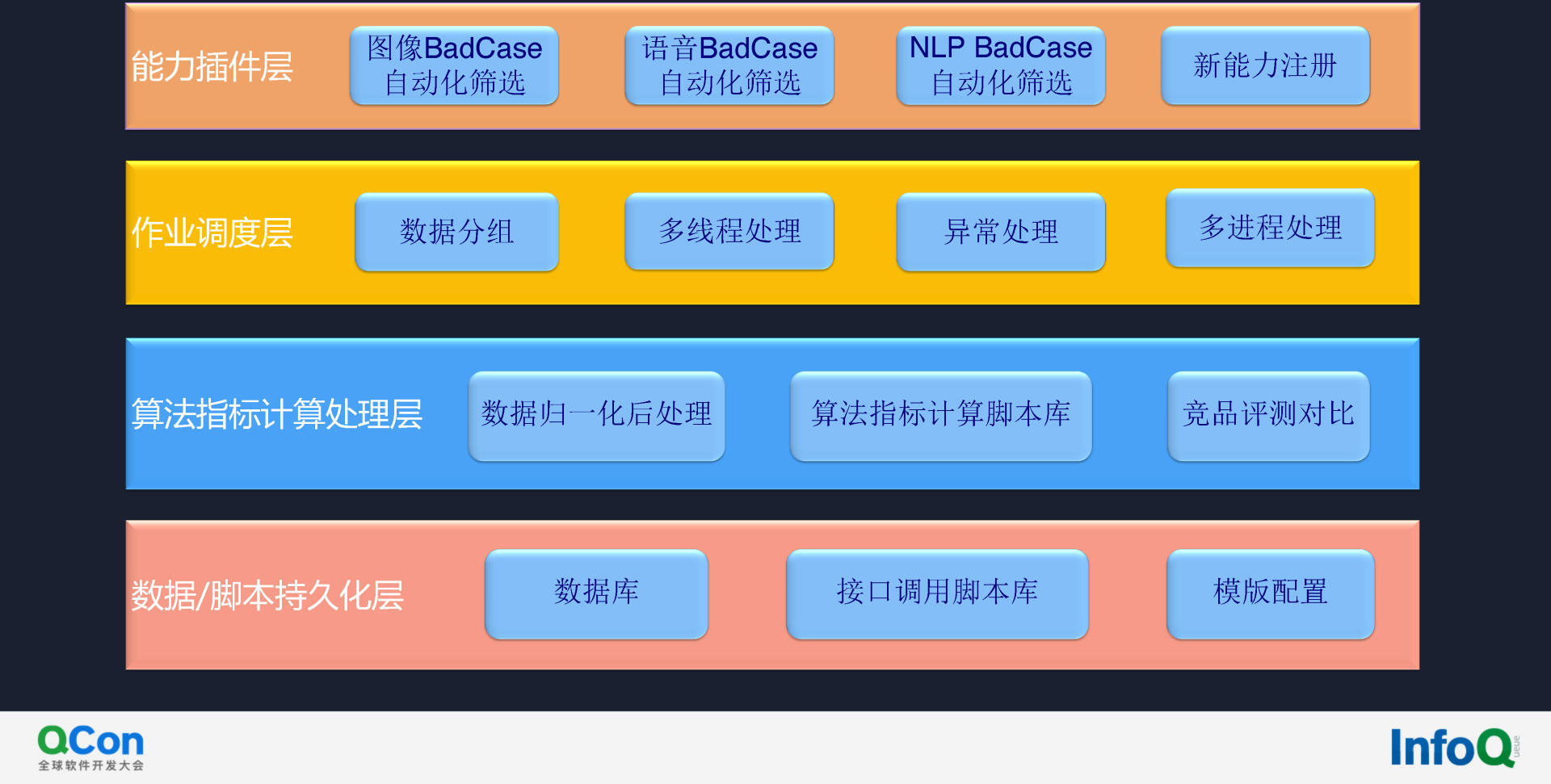
底层是数据/脚本持久化层。在该层我们存储部分的目标数据,设定部分接口调用脚本逻辑,通过模板配置快速兼容新能力。
第二层算法指标计算处理层。算法分析指标众多,如语音类的 WER、CER,图像类的序列准确、字符准确度等。归一化这些指标后,即可获取算法指标计算脚本库和归一化处理逻辑的映射,也可做竞品评测对比。
第三层是作业调度层。大量数据处理速度会较慢,因此我们会将数据分片、拆开做分布式处理,辅以多线程处理和多进程处理。
上层由前文介绍的众多 Badcase 筛选流水线组成而成。平台效果如下图:
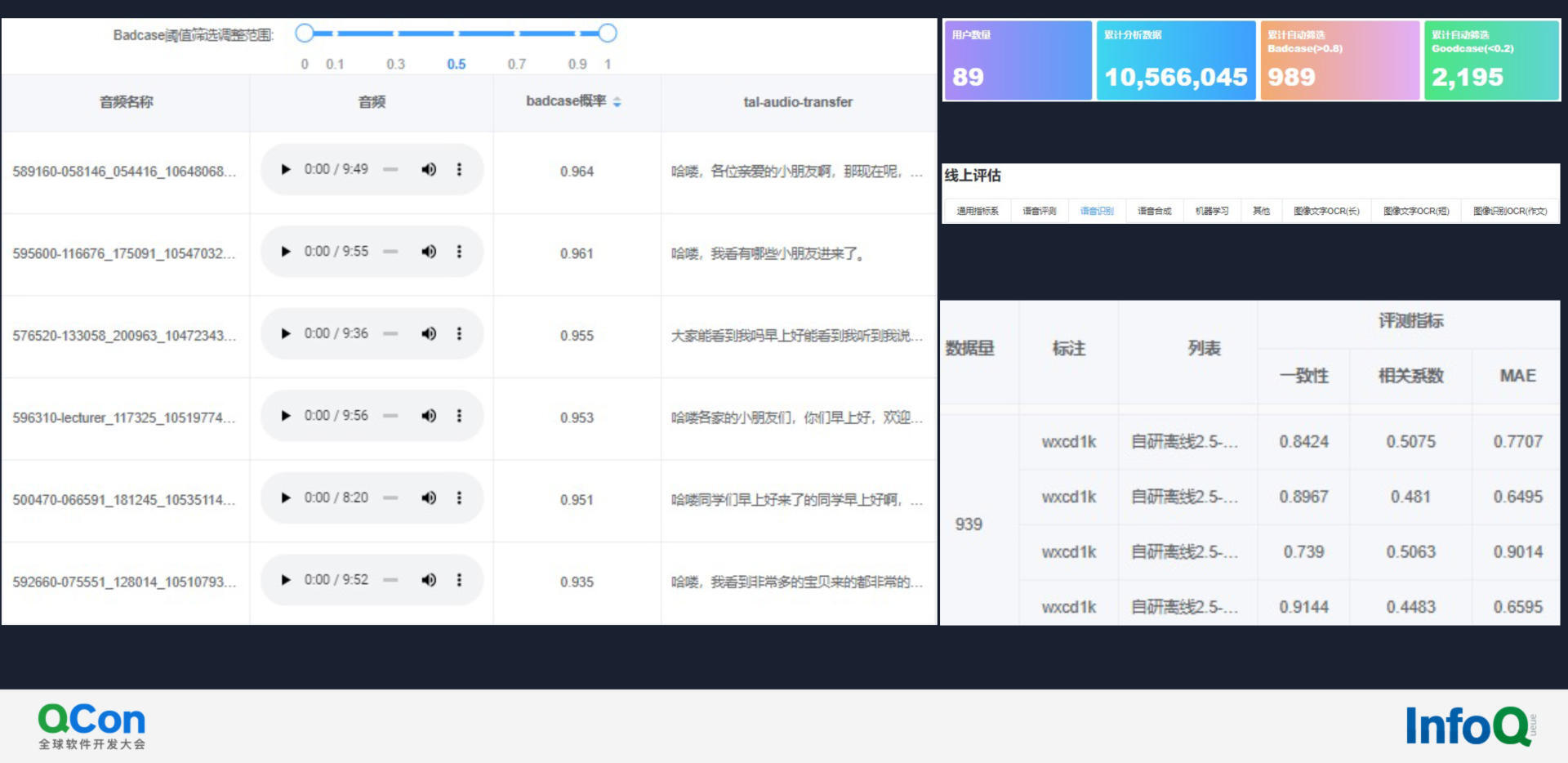
该平台汇集了 Badcase 的标注数据、实际在线处理数据、转录后的语音及文本结果等,可供随时查询、事后跟踪和分析。内部验证集和测试集不能完全的拟合线上的情况,通过该平台,即可常态化地定量抽取线上数据,评估实际线上表现,如低于内部评测表现可继续深入分析。
该平台研发仅半年,处理数据已破千万。使用者除了算法测试的工程师外,还包括产品。产品推广 AI 能力,需要提供 WER 值行业内水平等量化评估数据。通过该数据平台,产品可便捷地查询最新量化指标。图中指标包括一致性、相关系数和 MAE 等。而工程的人员即使不懂算法和计算逻辑,也可通过该平台快速算出最新版模型的线上效果。
AI 研发提效的持续思考
我们在数据、代码、模型、产品四个方面探索了 AI 研发提效。对于数据,我们正在探索如何精准标注、自动标注、管控质量。精准标注即用最少数据获取有用算法和加速 PR 值提升,会通过对线上回流后的数据打签,减少识别效果好的数据选取。比如印刷版本识别即可少选数据,而手写公式识别则需多选数据。自动标注即用成熟模型做预标注。但有预标注的话,标注员可能会放松审核,因此需建立体系管控外部标注团队的质量。
算法模型有工程代码,因此无法避免内存泄露、模型崩溃、缓存器溢出等问题。拿到数据后通过静态和动态扫描,可避免后期才发现前期的问题而返工,造成资源的浪费。此外,对复杂代码进行降维,如果代码的圈复杂度高或模型性能衰退严重立即反馈。
模型方面,我们做了自动训练、历时估算、一致性对比。自动训练指自动化调参、拟合,也可以是半自动的,即通过配置预设参数,每一参数后接一个自动化评测的脚本,通过选举法选取 PR 值最大的模型。历时估算即用内部 Kubernetes 容器调度的一个集群,通过每个模型的复杂度、数据质量预测当前训练任务的结束时间,减少排队和碎片化的情况。此外,模型归一化后输出的指标和线上经过工程处理后的指标存在一致性问题,需要权衡性能和效果。
在产品方面,我们做了 A/B 实验、在线评估和埋点反馈。
A/B 实验即并行上线两版模型,定期回捞数据,根据用户反馈,或标注后的真实情况,选择更好的模型;在线评估即通过前文中方案筛选 Badcase,秒级评估且反馈模型的表现情况;埋点反馈即通过埋点,判断模型实际预测结果和最初标注的数据是否吻合。
以上机制保证了微服务和产品在客户端上的体验。
外部链接
通过专利号:TAL202000729、TAL202100901、TAL202000769 即可查询本次分享的更多技术细节。
嘉宾介绍
赵明,好未来 AI 中台质量与工程效率负责人,毕业于清华大学软件学院,具有 10 余年项目实战与管理经验,曾就职于 IBM、FreeWheel 等知名外企,从事产品质量自动化与工程效率工具链研发、测试与管理工作。现就职于好未来教育集团任 AI 中台质量与工程效率负责人,带领 50 人团队负责人工智能产品质量保障,AI 与工程效率平台研发等工作。
带领团队自主研发算法指标评测平台、自动化探测平台、数据清洗与增强平台、算法 API 测试自动化平台等。
活动推荐
我们在 ArchSummit 全球架构师峰会中,邀请了腾讯杰出科学家、PGG 应用研究中心专家主任单瀛博士作为出品人,共同策划了【AICon全球人工智能与机器学习技术大会】专题,和国内 AI 技术专家合作,邀请 Google、阿里巴巴、腾讯、虾皮、华为等公司技术专家,分享最新的人工智能技术,尤其是知识图谱,知识计算等话题。
如果你感兴趣的话,扫描下图中的二维码即可获得更多信息。

公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论