

本文从只有成功/失败和多个选择项两种情况,举例说明了采用真随机、受控随机和混合的算法,对分布图的不同影响,认为受控随机解决了之前游戏中随机算法存在的问题,避免一行频繁选取同一事物,避免某件事成功之前的等待时间太长,避免太多可预见性,避免在某种情况下,某个项永远不会被选取到。
我不知道这个问题是否有正确的名称,但在游戏开发中通常不需要真随机。我看到这个解决方案命名为“ 伪随机分布 ”,但“伪随机”在游戏设计之外已经有了不同的含义,所以我在本博客文章称之为受控随机。
这个问题的描述如下:按预期,一个敌人会有 50%的时间丢下道具。玩家不停的打这个敌人,10 次之后,该道具还是没有丢掉,他们会觉得这个游戏坏了。或者一次攻击预计有 90%的成功率,但是一行中有三次失败了,玩家会认为游戏出问题了。
在这篇博客中,我想把这个问题扩展为不只两个选择(成功或失败),而是很多选择的情况。比如,我们想创建一个马路上的交通情形,需要随机放置一系列的车,相同的车出现的次数不能太多。对于只有成功、失败的情况来说,这个问题已经部分解决了,对于有多个选择项的情况,我在本文会改进该解决方案。
根据希望得到的结果,我们也可以自己控制需要多大程度上的随机性和非随机性。如果在某种特定情况下,一行失败三次的 90%的成功率是可接受的,但希望在其他情况下能更可靠,则可以通过一个数字进行调整。
首先,我要澄清下,这个游戏的确有些问题。如果某件事有 90%的成功率,但在一行中失败了三次,玩家完全会认为这个游戏出现了问题。一行三次失败是 1/1000 的几率,因此如果玩家足够多,或者玩家玩游戏的时间足够长,这种情况会发生很多次。你可能觉得玩家统计学的很烂,不应该抱怨,但这个问题是更深层次的。
我们使用随机的大部分时间,其实并不需要随机性。使用随机性的一种情况是要产生多样化,比如你不希望相同的道具随处可见。但是,真随机性并不能保证多样性,因此不要使用真随机。
另外一种使用随机性的例子是模拟一个不能完全模拟的复杂系统。比如,只给出一个有 90%几率命中的攻击,而不用模拟剑的移动、敌人的闪避或回击。但是,真随机数很少能正确模拟以下系统:如果有 90%的命中率(比如从后面刺到敌人),可能头两次都失败了,实际上第三次肯定能中。如果不想模拟基本系统的复杂性,但至少需要在某种程度上接近它,一旦系统微复杂一点并包含一个对前两次失败做出反映的反馈环路,真随机就是一个错误的选择。
成功和失败的解决方案对于一个简单的例子,我所知道的最好的解决方案是用在 Warcraft 3 上的 Blizzard,点击查看详情,我也会举例来解释。
其思想就是,在每次出现失败时,持续增加机会。比如说有 19%的机会获得暴击,那么第一次攻击时,要计算本次攻击是否是一次暴击,使用真随机增加 5%的成功几率。如果没有得到暴击,下一次得到的机会就是 10%。如果再次失败,则机会增加到 15%,到 20%,25%,以此类推。如果一直都在失败,在某个点上就肯定会有 100%的几率获得一次暴击。如果成功了,则下一次的成功几率会降回到 5%。
这种方法可以完成两件事情:
1、如果根本就不可能得到暴击,避免做无谓的努力。
2、它让我们在一行获得两次暴击的可能性减少。如果你按上述方法增加了 5%的几率,则平均成功概率大致能到 19%。 怎么才能获得这 5%的基本机会呢?
我确实不知道怎么用分析方法来达到,但是可以写一个循环,运行上百万次,这样通过实验来简单说明成功或失败的频率,就建立了一个包含百分比的查询表。
但是,这种算法在 60%到 70%间有些问题。从上面的链接来看,Blizzard 可能只通过混合百分比的方法就解决了这个问题。比如,在他们的例子中,开发人员设置某件事的发生概率为 70%,而实际的概率是 60%。这个算法是怎样失效的呢?为了得到 70%的概率,第一次尝试时的概率要为 57%,第二次的概率为 100%。这样一来,显而易见的问题就是让游戏变得可预测。一旦玩家注意到之前失败而现在能一直成功,就会利用这一点。所以我实际倾向于使用一种不同的方式,即将百分比相乘而不是相加。
对于上面 19%概率的例子,用相乘的方法,其工作方式如下:第一次尝试时,有 94.4%的失败概率。(这次,我们用失败概率,而不是成功概率)。在第二次尝试中,会得到 (94.4%)^2 = 89%的失败率。在第三次尝试中,会得到 (94.4%)^3 = 84%的失败率,失败概率会一直下降,直到实际概率接近零(永远不会到零)。这样可以得到较小的失败率,而且永远不会被完全预测,不过失败率在某些点会非常小。
我们可以轻松得到以下代码:
(本篇博客中的代码使用 boost license 来授权使用,可参见文末。在随意使用复制+粘贴来使用这段代码时,需要注意我用 unidcode 来替换了一些字符,因为在敲“小于”和“大于”符号时,考虑到他们是 HTML 标签,输入有些麻烦。因此使用时,需要重新做比对和模板)。
为每个不想被其他状态打扰的状态构建一个 ControlledRandom 对象。这意味着如果有多个角色,每个角色都有一次暴击的机会,就需要为每个角色创建一个对象。随机参数是一个随机引擎,比如,std::mt19937_64,可以在实例间进行共享。
在这个函数中,我使用查找表来确定每次需要对状态变量乘多少,函数才能返回失败。可以看到,对于 19%,它很接近上面提到过的 94.4%的失败率。我的查找表中只包含 99 个数字,这样几率会四舍五入到最接近的乘 1%的结果。意味着如果你想要的几率是 5.4%,实际会得到 5%。如果你想要得到 0.1%的几率,实际得到的几率是 1%。如果觉得这样不好,可以继续阅读。我提出的针对“多选择”的解决方案也适用只有两种选择的情况,还可以做的更精确些。
为了说明它已经解决了刚开始提出的问题,我们来看一种情况,即敌人有 50%的几率丢掉道具。查看代码中的表,我们看到,50%的几率会用到 64.5%的乘方。这意味着第一次杀死敌人时,该道具放弃的几率实际只有 35.5%。但是如果它没有放弃,则下一次我们可以获得 1-64.5%^2 = 58.4%的几率。当几率达到 73.2%,它仍然没有放弃时,几率就会达到 82.7%,88.9%,92.8%,以此类推。现在,在一行的 10 次中不放弃道具的几率小于 1/10,000,000,000。到达 1/1024 的几率前,一旦道具放弃了,几率会回降到 35.5%。意味着不大可能在一行里放弃两次。有 90%的几率而在一行里失去三次机会的几率接近 1/1,000,000,之前是 1/1000。百万分之一的几率可能很常见,但是一行里失败 4 次的几率小于 1/1,000,000,000。(该几率会下降的越来越快。一行失败 5 次的几率小于 1/100,000,000,000,000)
多选择时的受控随机过程
多个选择时的问题是和受控随机相关的。比如要在高速公路上增加交通数据,并在路上随机放置一些车辆。如果在游戏中,有 10 种不同类型的车,而且选择是完全随机的,有时就会不停得到同类型的车。或者你可能在很长时间内看不到其中一种类型的车。这些都是我们会遇到的不利情况。而且,你可能想以不同频度来放置不同的车。比如跑车可以不像 SUV 那样多。
另一个“多选择”下的受控随机过程则是,如果敌人有多个攻击模式,你希望他每次都做“随机”的攻击。这又是一个复杂系统的仿真例子。我们不想程序化敌人的整个决策逻辑过程,因此随机是一个很好的替代方法。但是真随机很容易导致相同模式的攻击重复出现。
可能最典型的例子就是,当你的音乐播放器要随机播放音乐。你不想一遍又一遍的播放两首相同的曲子,但是在真随机中则可能会出现这种情况。
经典的解决方法是把所有歌曲放在一个列表并调整顺序,然后顺序播放,当播放完毕,再一次调整顺序,然后重新开始,而不是每次从头随机选取一首来进行播放。虽然不能确保在顺序调整后不会有重复的情况出现,但总体说来这种方案效果不错。
如果这些选项有不同的权重,这种方法的问题就会显现出来。这和路面上的跑车不如 SUV 多的例子一样。一个简单的解决方案就是在列表中增加的 SUV 数量超过增加的跑车数量,不过这只在不同对象间比例固定的情况下适用。(比如投放的 SUN 数量是跑车的 2 倍)种类越多,权重差别越大,这个问题越复杂。如果有 50 种不同的车,每种车的权重不同,就只能近似的做到这一点。
有一天,我在工作中突然想起这个问题,并希望一劳永逸的解决它,Jason Frank(Just Cause 4 的引擎程序员)正好路过。我们一起想出了一个解决方案,它占用 O(n)内存和 O(log n)的 CPU 开销,其中 n 是选择项的个数。这种方案可以让人们来决定是需要更多的随机性还是更多的确定性。
其想法和顺序列表一致。但是,我们是把对象随机的放在一条线上。然后我们沿着线走,并按放置顺序选取选项。但和顺序列表不一样,我们会一直进行直到结束。每次我们选择一个项后,我们会很快把它放回到线上往前一点的位置。放回去的位置取决于其权重。如果对象 A 要出现的次数是 B 的两倍,则我们放置 A 的位置是放置 B 的距离的一半。我们还会做一些随机化的工作,让对象不能以相同的顺序出现。
我们用一些数字来深入说明一下。有三个项,A 出现的次数是 B 的 2 倍,B 则是 C 的 3 倍。为了得到这种分布,我们把 C 放在 0.6 个单元处,B 则在 0.2 单元处,A 在 0.1 单元处。也就是说我们现在在位置 0,前方 0.05 单元处,能找到 A,0.1 处找到 B,0.15 处找到 C。
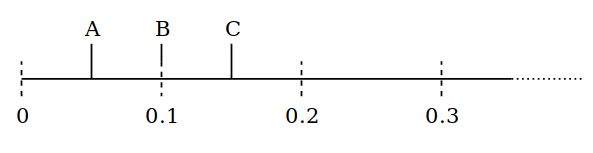
我们选择 A 时,生成一个从 0 到 0.1 的随机数,并把 A 沿线放置的更远。比如我们生成的随机数为 0.07,则新的放置位置在 0.12。
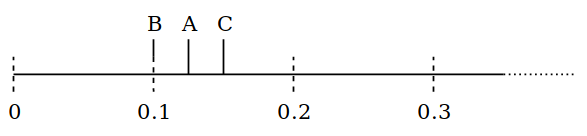
现在新的第一个对象是 B,因为它在位置 0.1。为了沿线移动,我们选择一个从 0 到 0.2 的随机数字,比如 0.11,则 B 现在的位置在 0.21,A 再次成为第一个对象。
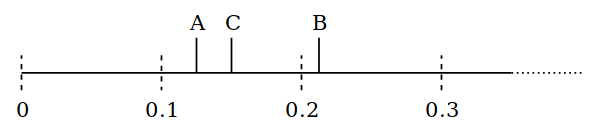
我们再次选择 A,移动到一个随机选择的位置,如 0.17,现在 C 成为第一个项。
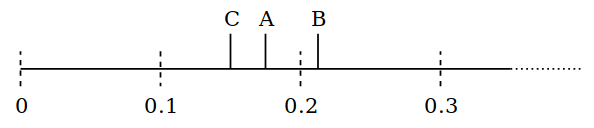
我们一直在向前移动,这样不管沿线有多长,都可以保证在某些点上可以得到每个项。长间隔不像真随机过程中那么多,重复性也比真随机过程少。我以后会正确说明这一点,现在先来看看代码:
这段代码稍有点复杂,最下面的 heap_top_updated 函数不是严格需要的(如果在 std::pop_heap 后马上进行 std::push_heap 的操作,它可以对该种情况进行优化),我们可以用一个例子来一步步的深入理解:
例如,我创建了一个权重分别为 1、2、3 和 4 的加权分布。也就是说第四个项被选中的次数是第一个的 4 倍。增加权重后,必须调用 initialize_randomness 一次,否则头几次的选择就是确定的。然后在循环中调用 pick_random,并统计每个项被选中的次数。在本例中,第一个项被选中的次数约为 1000 次,第二个约 2000 次,第三个约 3000 次,最后一个约 4000 次。
为了理解这段代码,首先解释下,为什么要使用定点分数,而不是浮点数。因为用 uint32_t 来表示一段无限长的线比用浮点数要简单。浮点数在数字变得很大时精度会下降,需要做其它的来进行弥补。比如不时将整个线进行翻转。而使用 uint32_t 没有这个问题。它会一直递增、绕回,不会出现任何问题。唯一需要做的是在 CompareByNextTime 里处理 uint32_t 绕回的情况。否则这段代码不会真正依赖于定点运算。这种转换只会在第一次添加权重时出现,在其他任何地方都不是问题。
在 initialize_randomness 中,给每个项分配了线上的一个位置,该位置从 0 到最远能放置的距离中随机选择。然后,把它放入一个最小堆,这样距离最短的项是该堆的第一个元素。接下来看 pick_random。
首先,选择列表中 next_event_time 值最小的第一项。每次随机选择一个数值,增加到 next_event_time,这样在列表中分配一个新的位置,更新堆并把该项移回到线上。当 uint32_t 绕回时,用 reference_point 来进行处理。
选择 next_event_time 增量时的重点是:在代码中,该增量是个从 0 到不同事件平均概率的一个数。这个数值对于每个权重会不一样。在上面的例子中,对于第一个权重,它为 1,对于第二个为 0.5,对于第三个为 1/3,对于第四个为 0.25。(除非使用定点数运算,第一项的为 10241024,最后一个则为 2561024)这意味着最后一个在线上放置的位置增加 0.25 个单元,而第一个增加 1 个单元。因此可以清楚的看出,最后一个项被选中的几率是第一个的 4 倍。
因此,增加该数值意味着把选择项往线的后方推进,更新堆就是沿着线一直进行。
但这真的可以让我们得到受控随机吗?怎样保证它不会像每次从头开始随机选取一个项所表现的那样随机呢?理论上,我们可以在一行中多次随机得到很小的数,只能在线上缓慢移动。最简单验证该方式能起到预期效果的方法是长时间模拟行为。比如一百万次的选择。为此,我从上例中选择第三个项,从长期看,它选择的次数应该有 3/10。如果使用真随机,总是根据权重来选择一个随机项,能得到两次选择间的等待时间分布图:
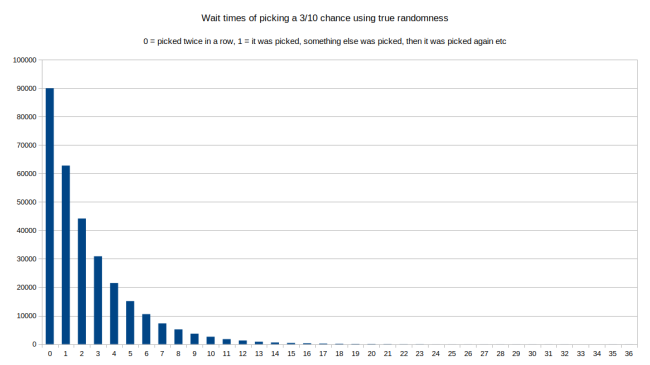
在该图中,我们可以看到,一百万次后,最常见的选择是第三个项,每行选择了两次。还有种情况,即它是和其他项交替进行选取的。两次选取的间隔越长,越不容易被选上。看下图的右侧:最长的间隔是间隔了 36 个项的等待时间。这意味着如果第 3 项被选了,在它再次被选之前会有 36 个其他项被选取。我们在受控随机中看看同样情况的处理:
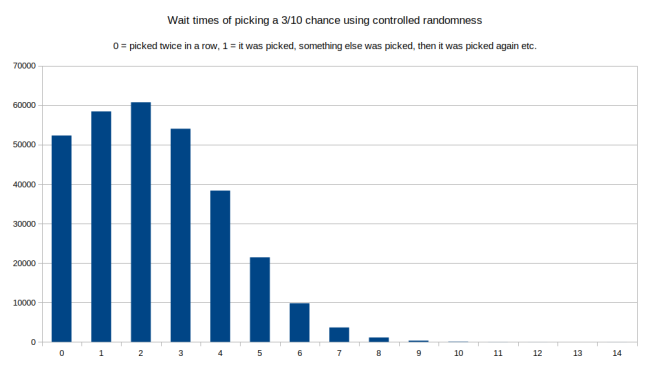
现在我们看到在一行中选取两次不那么常见了。等待时长为 2 是最常见的。图的右部短了很多。最长的等待时间是 14。相比真随机,这并不常见。
这种算法有趣的是,我们可以将沿线移动的方式进行混合。比如,我刚才使用了从 0 到平均等待时间的 uniform_int_distribution。如果我们使用 std::exponential_distribution(即 1/average_wait_time),(注意将其从定点运算转回到到浮点数运算)我们可以看到和第一个图很像。因为 exponential_distribution 实际定义的就是第一个图。Wikipedia定义提到:在一个过程中,事件以固定的频率、持续并独立发生时,其分布很大可能呈指数分布。我们可以来试试:
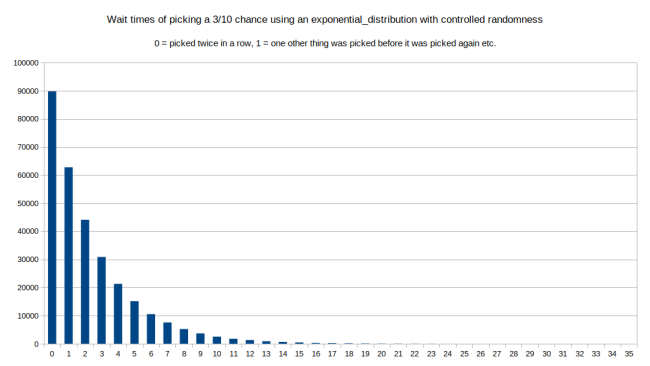
这和第一张图非常的相似。在这种情况下,最长等待时间是 35 而不是 36,不过可以把它只看作是随机噪声。
如果我们完全不用随机,只是一直增加 average_time_between_events,会发生什么情况呢?
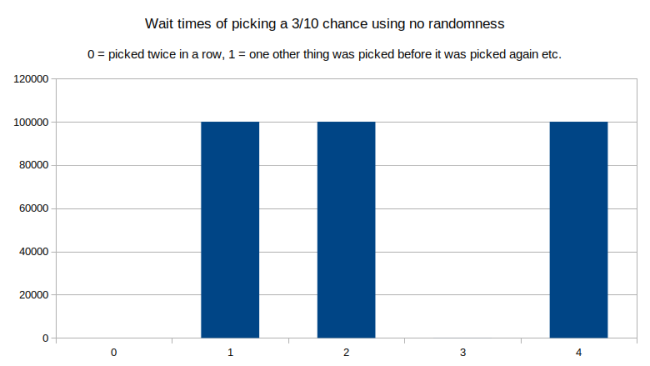
这很有趣吧,如果我们去掉所有的随机,它在一行中不会被选取两次,也不会有等于 3 的等待时间。仔细想想是合理的:没有随机过程,沿线行进时就不会进入重复模式。
但实际这取决于我们怎么控制需要的随机程度,我们可以使用上述所有方法的组合。只要我们在线上的点,有相同的平均距离,我们就不会影响值的长期分布。例如,使用 75%受控随机(最长等待时间为 14 的那个图)和 25%的无随机(最近的那张图)时,可以得到下图:
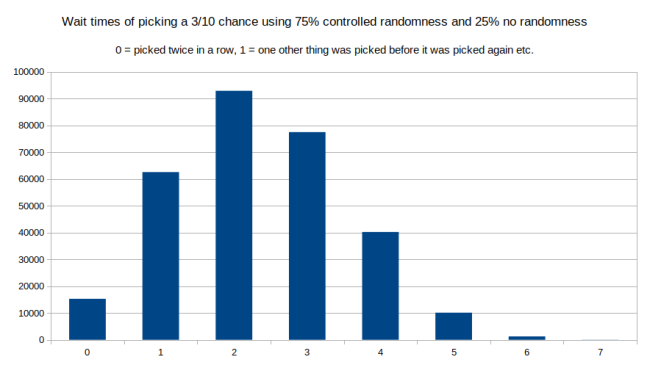
效果非常好:一行中选择两次的几率下降,右边分布的长度也下降了。最长的等待时间现在为 7。不过平均来说,仍有 3/10 的次数被选中。因此使用这种混合不同分布的方法,可以实际控制需要多大程度的随机性和确定性。实际上,我们可以对每个项进行自由组合和匹配。也许,某个项非常重要,我们需要它以一定的频率出现。而某件事不大重要,它表现的更随机也没有问题。只要不做平均混合,就可以进行任何形式的组合。
我们来看第二个问题:在进行其他选择前,选择相同的项的最长链路是多长。还是看上面这个例子里相同的项,需要平均 10 次选择三次。使用真随机,一旦被选取后,其被选取的概率分布图如下:
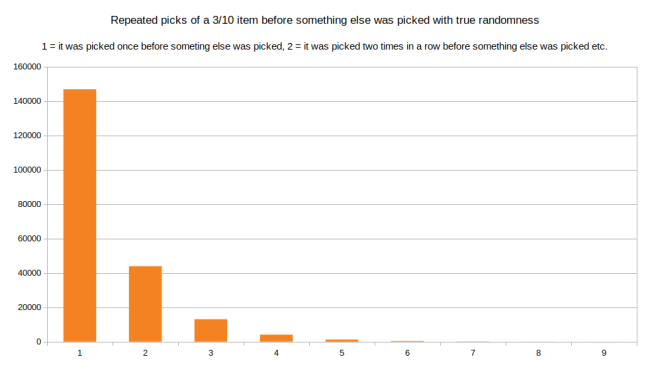
可以看到,最常见的是选择其它项之前选择该项一次。不过一行里被选择两次或三次的情况就不那么常见了。最长的链路是在其它项被选择前被选择了九次。下面我们来看看受控随机怎样影响该分布图:
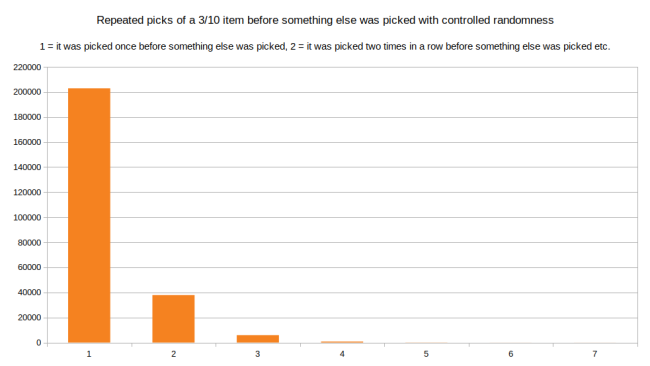
看起来和前图有点相似,但实际上到数字 1 的次数更多,意味着其它项选择前,该项被选取一次。我们可以读取数值来比较数字 2 对应的高度,不过越往后,变化越大。使用真随机时,有该项在一行被选取 4 次的情况出现了 4087 次,而使用受控随机时,同样的情况下,只有 769 次。这就意味着链路越长,其差别也越大。受控随机让交替选择更多,重复选取同一项的几率下降。最后,我们可以看到现在最长的链路为 7。
如果我们把受控随机和完全确定的方式结合起来,差别会更让人惊讶。下面是混合 75%的受控随机和 25%的确定性:(确定性指不添加随机数字,只增加 average_time_between_events)
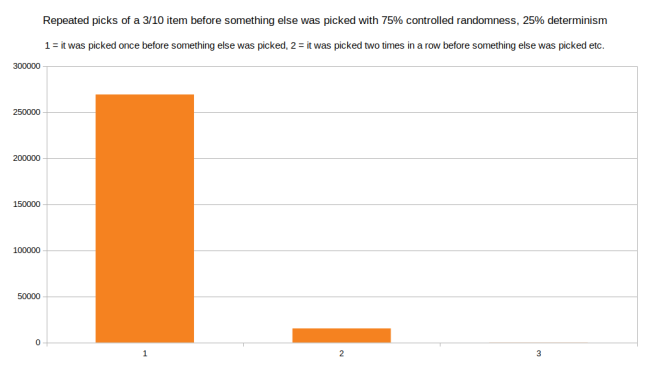
只混合 25%确定性就让长链路彻底消失了。最长的链路现在为一行中被选择三次。这是合理的,因为在确定性中,每次沿线的步进是个最小值。在确信遇到其他情况前,步进只能这么大。
我认为受控随机的问题已经解决了。我们回顾一下谈论的所有问题,看看是否已经被解决:
避免一行选取同一事物过于频繁:已解决,因为相比真随机,多次选取同一事物的几率已经降低。我们还组合了部分确定性,让该几率更低。
避免某件事成功之前的等待时间太长:已解决,因为上面等待时间分布显示分布图的尾部已经缩短很多。
避免太多可预见性,也就是 Warcraft 3 受控随机的问题:任何高于 70%的事物在一行都会失败一次。如果一旦失败,可以确信下次一定会成功。这在受控随机的新算法中不会发生(除非加入太多的确定性)
避免在某种情况下,某个项永远不会被选取到。我之前没有提及这一点,但在 Warcraft 3 版本上和我基于乘方的版本上,受控随机的第一个算法都存在该问题:为了长远得到 1%的几率,第一次尝试只能从高于 1/10,000 的几率开始,然后慢慢提升几率。这就意味着如果某件事有 1%的几率,在第一次尝试时,几乎是不可能成功的。受控随机的新算法没有该问题。 相比真随机,第一次有 1%的几率还是很有可能的。
不希望被分布图所困扰。Warcraft 3 解决方案实际提供 60%的成功机会,而设计者要求有 70%的成功几率。我们不希望这样。让随机过程接近人们的期望是可以的,但是当他们和数字开始较劲时,没有必要去欺骗我们的设计人员。
另外一个好处就是它效率高:O(n)表示存储空间,其中 n 表示项数,O(log n)则是选择下一项的 CPU 时间。 这意味着在整个的音乐收集中,很快速能播放一首随机音乐,当然,也可以用于小数字,如选取三次随机攻击中选择一次。 还可以用它来代替只有成功/失败两种选择例子里的算法。如果这样,可以重构而不使用内嵌的 std::vector,不使用堆和定点数。 这是一个有趣的练习,可以大大的简化这个过程,我把它留作给读者的一个练习。 像我提供的第一段代码一样使用单精度浮点状态变量是不可行的,双精度应该可行,这是 github上的代码链接。
下面是上述所有代码的授权许可文本。如果你只是想参考该算法,不需要写“it’s an algorithm invented by Malte Skarupke”,应该写“it’s an algorithm invented by Jason Frank and Malte Skarupke”,因为 Jason Frank 在一行设置多个对象和受控随机上提供了非常关键的想法。我只是编写了代码。授权如下:
为方便读者翻到文末直接找到链接,再一次给出 github链接。
原文链接:https://probablydance.com/2019/08/28/a-new-algorithm-for-controlled-randomness/

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论