

本文是Apache Flink 零基础入门系列文章第七篇,本文主要包含三部分:第一部分,主要介绍什么是 Table API,从概念角度进行分析,让大家有一个感性的认识;第二部分,从代码的层面介绍怎么使用 Table API;第三部分,介绍 Table API 近期的动态。
文章结构如下:
什么是 Table API
Flink API 总览
Table API 的特性
Table API 编程
WordCount 示例
Table API 操作
如何获取一个 Table
如果输出一个 Table
如果查询一个 Table
Table API 动态
一、什么是 Table API
为了更好地了解 Table API,我们先看下 Flink 都提供了哪些 API 供用户使用。
1.Flink API 总览
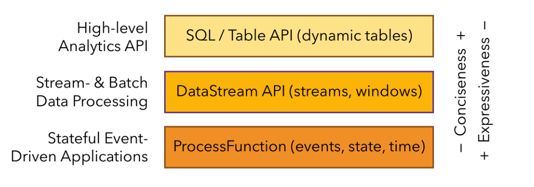
如图,Flink 根据使用的便捷性和表达能力的强弱提供了 3 层 API,由上到下,表达能力逐渐增强,比如 processFunction,是最底层的 API,表达能力最强,我们可以用他来操作 state 和 timer 等复杂功能。Datastream API 相对于 processFunction 来说,又进行了进一步封装,提供了很多标准的语义算子给大家使用,比如我们常用的 window 算子(包括 Tumble, slide,session 等)。那么最上面的 SQL 和 Table API 使用最为便捷,具有自身的很多特点,重点归纳如下:

第一,Table API & SQL 是一种声明式的 API。用户只需关心做什么,不用关心怎么做,比如图中的 WordCount 例子,只需要关心按什么维度聚合,做哪种类型的聚合,不需要关心底层的实现。
第二,高性能。Table API & SQL 底层会有优化器对 query 进行优化。举个例子,假如 WordCount 的例子里写了两个 count 操作,优化器会识别并避免重复的计算,计算的时候只保留一个 count 操作,输出的时候再把相同的值输出两遍即可,以达到更好的性能。
第三,流批统一。上图例子可以发现,API 并没有区分流和批,同一套 query 可以流批复用,对业务开发来说,避免开发两套代码。
第四,标准稳定。Table API & SQL 遵循 SQL 标准,不易变动。API 比较稳定的好处是不用考虑 API 兼容性问题。
第五,易理解。语义明确,所见即所得。
2.Table API 特性
上一小节介绍了 Table API 和 SQL 一些共有的特性,这个小节重点介绍下 Table API 自身的特性。主要可以归纳为以下两点:
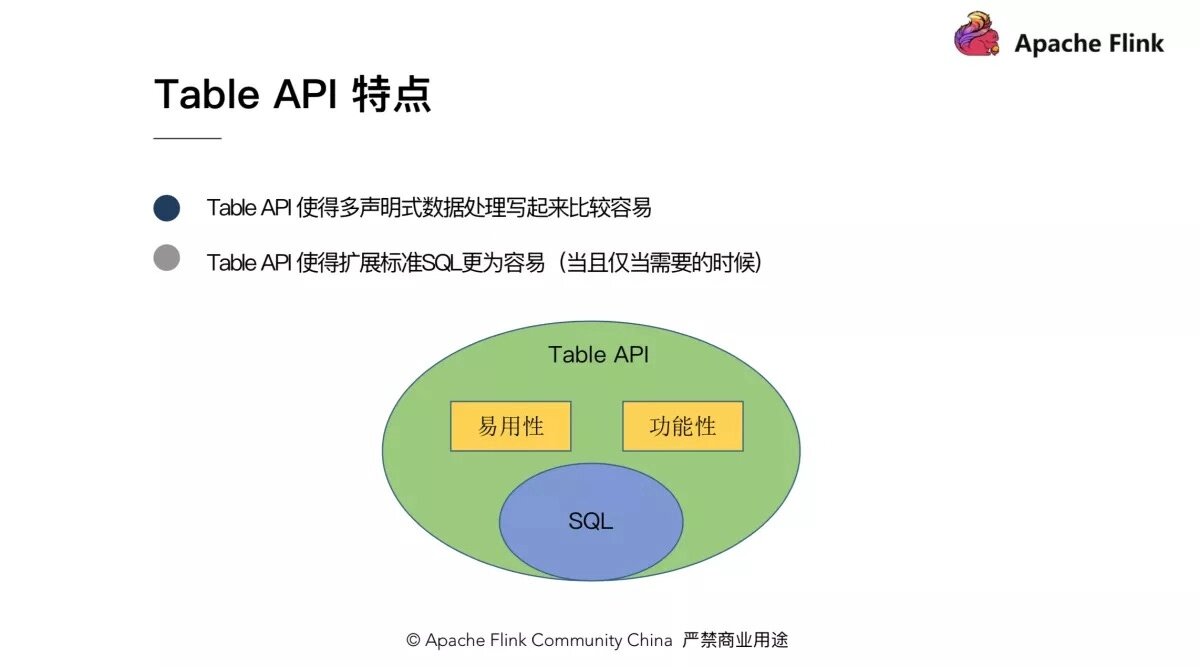
第一,Table API 使得多声明的数据处理写起来比较容易。
怎么理解?比如我们有一个 Table(tab),并且需要执行一些过滤操作然后输出到结果表,对应的实现是:tab.where(“a < 10”).inertInto(“resultTable1”);此外,我们还需要做另外一些筛选,然后也对结果输出,即 tab.where(“a > 100”).insertInto(“resultTable2”)。你会发现,用 Table API 写起来会非常简洁方便,两行代码就把功能实现了。
第二,Table API 是 Flink 自身的一套 API,这使得我们更容易地去扩展标准的 SQL。当然,在扩展 SQL 的时候并不是随意的去扩展,需要考虑 API 的语义、原子性和正交性,并且当且仅当需要的时候才去添加。
对比 SQL,我们可以认为 Table API 是 SQL 的超集。SQL 有的操作,Table API 可以有,然而我们又可以从易用性和功能性地角度对 SQL 进行扩展和提升。
二、Table API 编程
第一章介绍了 Table API 相关的概念。这一章我们来看下如何用 Table API 来编程。本章会先从一个 WordCount 的例子出发,让大家对 Table API 编程先有一个大概的认识,然后再具体介绍一下 Table API 的操作,比如,如何获取一个 Table,如何输出一个 Table,以及如何对 Table 执行查询操作。
1.WordCount 举例
这是一个完整的,用 java 编写的 batch 版本的 WordCount 例子,此外,还有 scala 和 streaming 版本的 WordCount,都统一上传到了GitHub 上,大家可以下载下来尝试运行或者修改。
我们具体看下这个 WordCount 的例子。首先,第 13、14 行,是对 environment 的一些初始化,先通过 ExecutionEnvironment 的 getExecutionEnvironment 方法拿到执行环境,然后再通过 BatchTableEnvironment 的 create 拿到对应的 Table 环境,拿到环境后,我们可以注册 TableSource、TableSink 或执行一些其他操作。
这里需要注意的是,ExecutionEnvironment 跟 BatchTableEnvironment 都是对应 Java 的版本,对于 scala 程序,这里需要是一个对应 scala 版本的 environment。这也是初学者一开始可能会遇到的问题,因为 environent 有很多且容易混淆。为了让大家更好区分这些 environment,下面对 environment 进行了一些归纳。
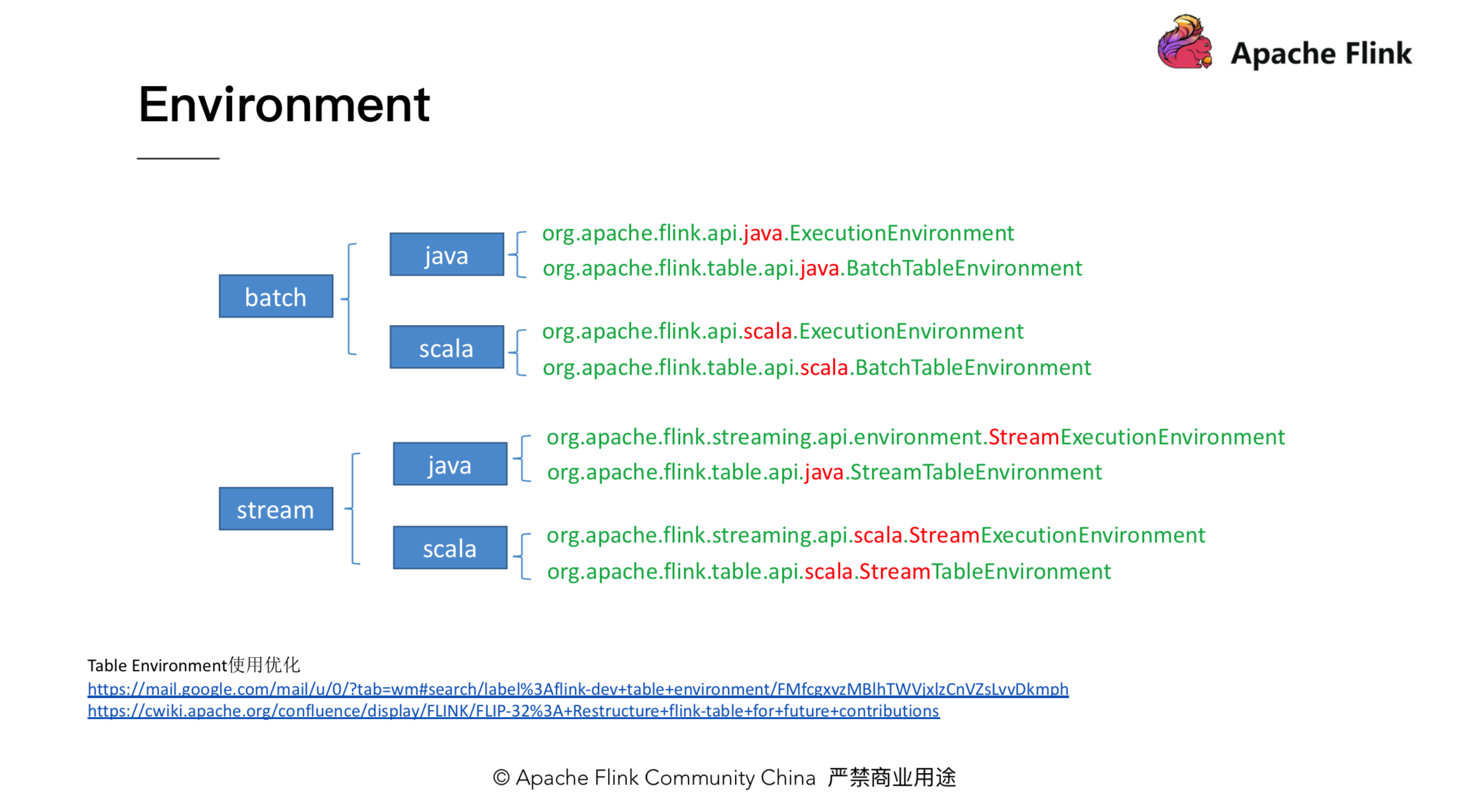
这里从 batch/stream,还有 Java/scala,对 environment 进行了分类,对于这些 environment 使用时需要特别注意,不要 import 错了。environment 的问题,社区已经进行了一些讨论,如上图下方的链接1和链接2,这里不再具体展开。
我们再回到刚刚的 WordCount 的例子,拿到 environment 后,需要做的第二件事情是注册对应的 TableSource。
使用起来也非常方便,首先,因为我们要读一个文件,需要指定读取文件的路径,指定了之后,我们需要再描述文件内容的格式,比如他是 csv 的文件并且行分割符是什么。还有就是指定这个文件对应的 Schema 是什么,比如只有一列单词,并且类型是 String。最后,我们需要把 TableSource 注册到 environment 里去。
通过 scan 刚才注册好的 TableSource,我们可以拿到一个 Table 对象,并执行相应的一些操作,比如 GroupBy,count。最后,可以把 Table 按 DataSet 的方式进行输出。
以上便是一个 Table API 的 WordCount 完整例子。涉及 Table 的获取,Table 的操作,以及 Table 的输出。接下来会具体介绍如何获取 Table、输出 Table 和执行 Table 操作。
2.如何获取一个 Table
获取 Table 大体可以分为两步,第一步,注册对应的 TableSource;第二步,调用 Table environement 的 scan 方法获取 Table 对象。注册 Table Source 又有 3 种方法:通过 Table descriptor 来注册,通过自定义 source 来注册,或者通过 DataStream 来注册。具体的注册方式如下图所示:

3.如何输出一个 Table
对应输出 Table,我们也有类似的 3 种方法:Table descriptor, 自定义 Table sink 以及输出成一个 DataStream。如下图所示:

4.如何操作一个 Table
4.1 Table 操作总览
第 2、3 节介绍了如何获取和输出一个 Table,本节主要介绍如何对 Table 进行操作。Table 上有很多操作,比如一些 projection 操作 select、filter、where;聚合操作,如 groupBy、flatAggrgate;还有 join 操作,等等。我们以一个具体的例子来介绍下 Table 上各操作的转换流程。
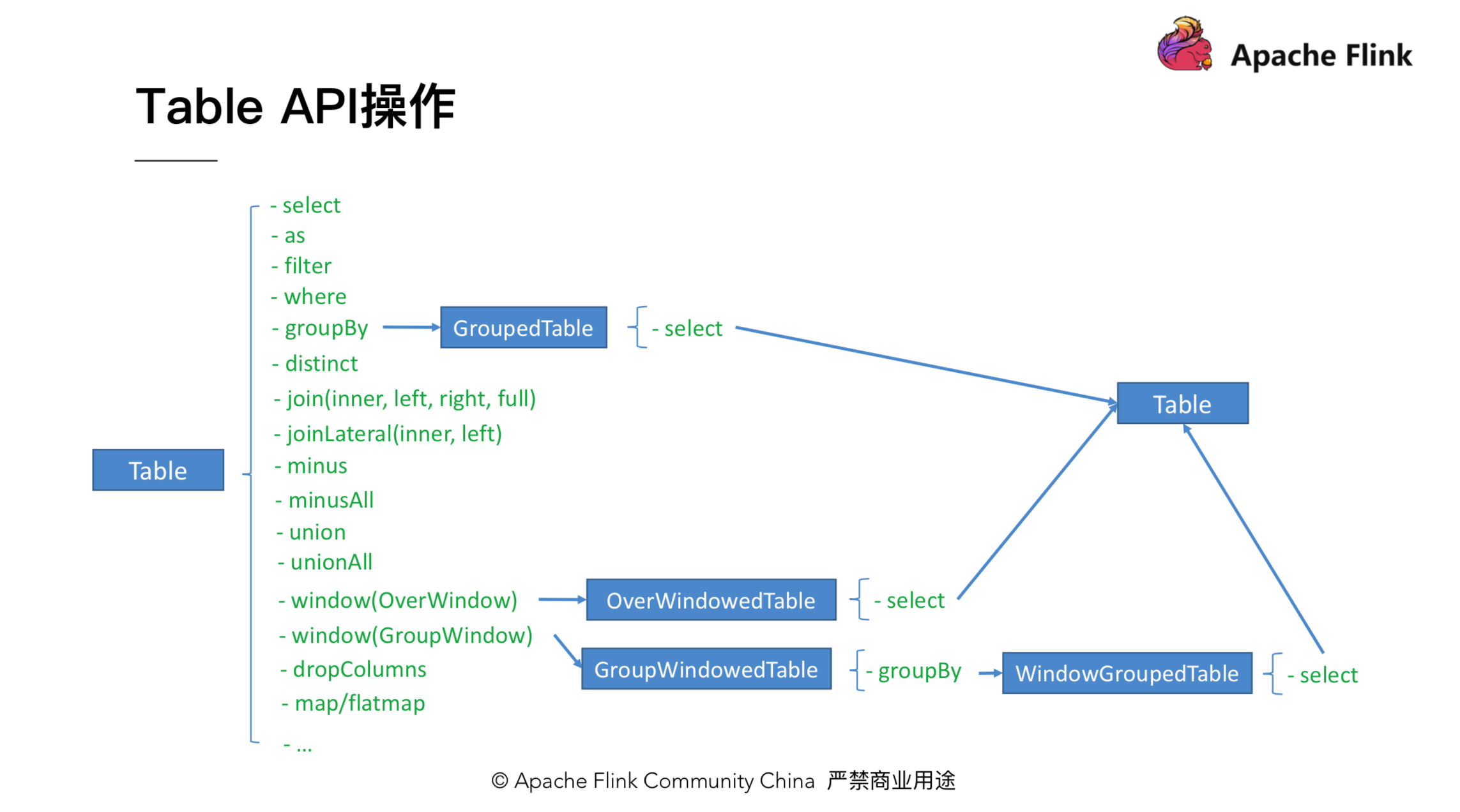
如上图,当我们拿到一个 Table 后,调用 groupBy 会返回一个 GroupedTable。GroupedTable 里只有 select 方法,对 GroupedTable 调用 select 方法会返回一个 Table。拿到这个 Table 后,我们可以再调用 Table 上的方法。图中其他 Table,如 OverWindowedTable 也是类似的流程。值得注意的是,引入各个类型的 Table 是为了保证 API 的合法性和便利性,比如 groupBy 之后只有 select 操作是有意义的,在编辑器上可以直接点出来。
前面我们提到,可以将 Table API 看成是 SQL 的超集,因此我们也可以对 Table 里的操作按此进行分类,大致分为三类,如下图所示:
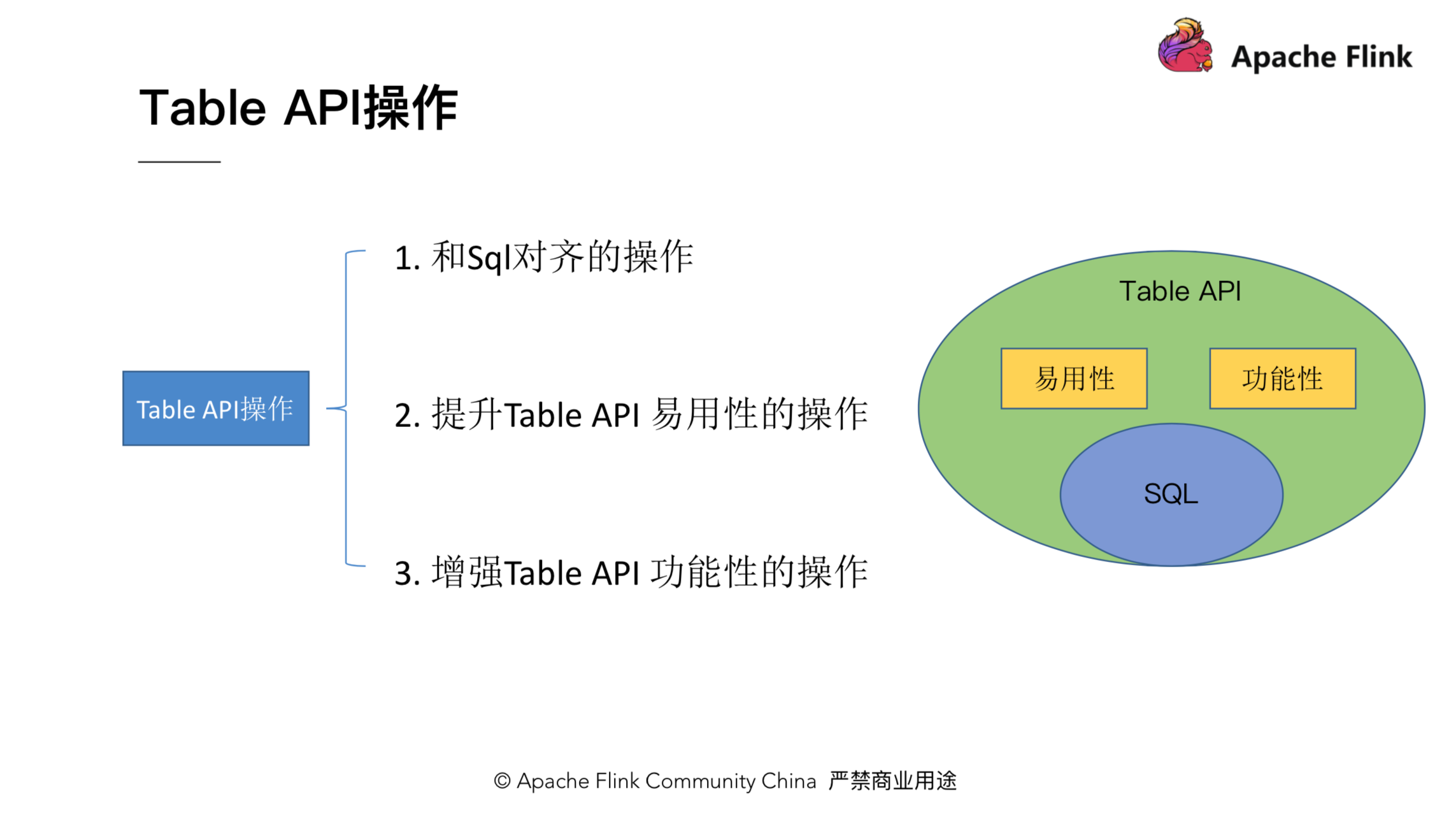
第一类,是跟 SQL 对齐的一些操作,比如 select, filter, join 等。第二类,是一些提升 Table API 易用性的操作。第三类,是增强 Table API 功能的一些操作。第一类操作由于和 SQL 类似,比较容易理解,其次,也可以查看官方的文档,了解具体的方法,所以这里不再展开介绍。下面的章节会重点介绍后两类操作,这些操作也是 Table API 独有的。
4.2 提升易用性相关操作
介绍易用性之前,我们先来看一个问题。假设我们有一张很大的表,里面有一百列,此时需要去掉一列,那么 SQL 怎么写?我们需要 select 剩下的 99 列!显然这会给用户带来不小的代价。为了解决这个问题,我们在 Table 上引入了一个 dropColumns 方法。利用 dropColumns 方法,我们便可以只写去掉的列。与此对应,还引入了 addColumns, addOrReplaceColumns 和 renameColumns 方法,如下图所示:
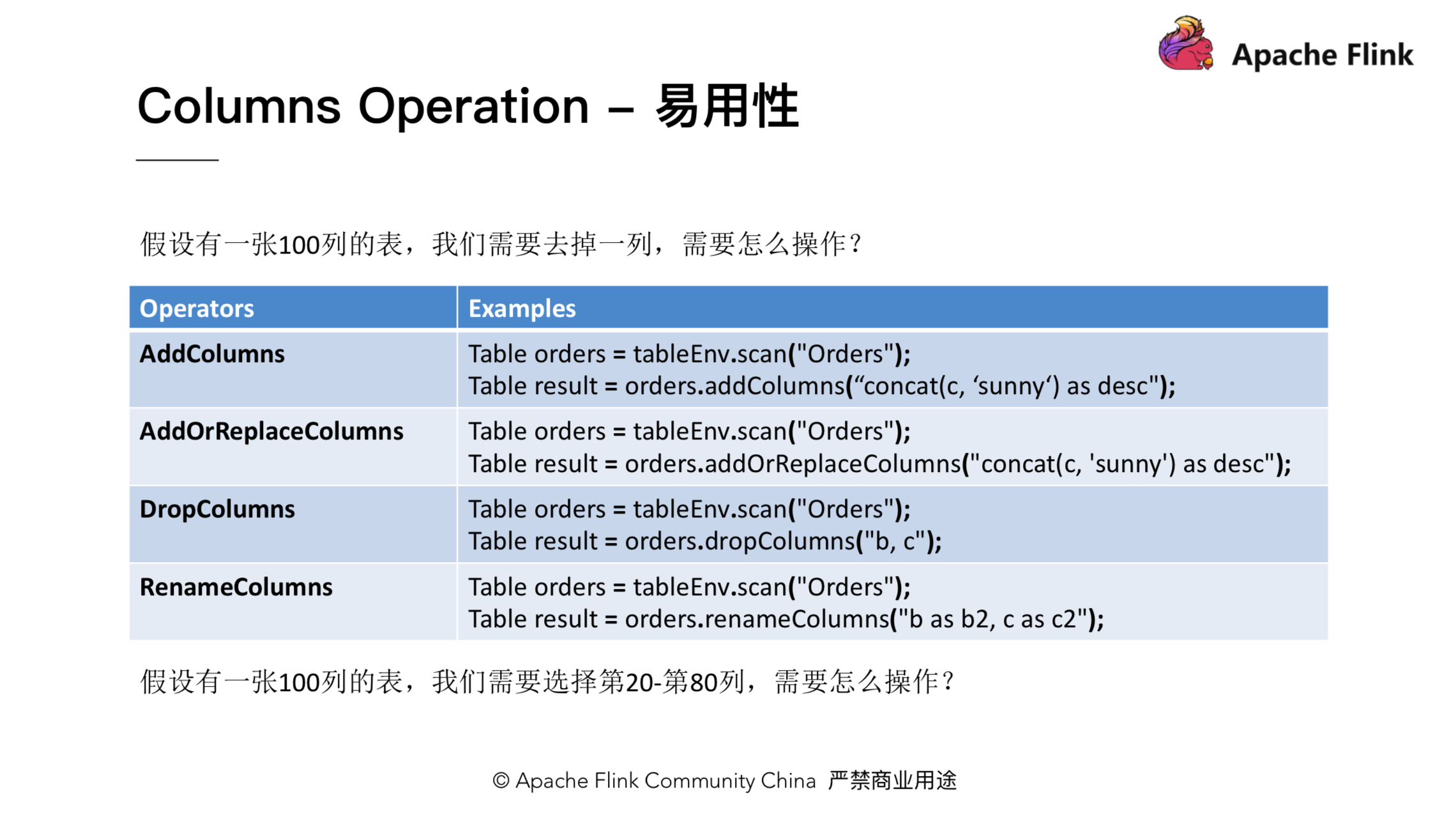
解决了刚才的问题后,我们再看下面另一个问题:假设还是一张 100 列的表,我们需要选第 20 到第 80 列,那么我们如何操作呢?为了解决这个问题,我们又引入了 withColumns 和 withoutColumns 方法。对于刚才的问题,我们可以简单地写成 table.select(“withColumns(20 to 80)”)。

4.3 增强功能相关操作
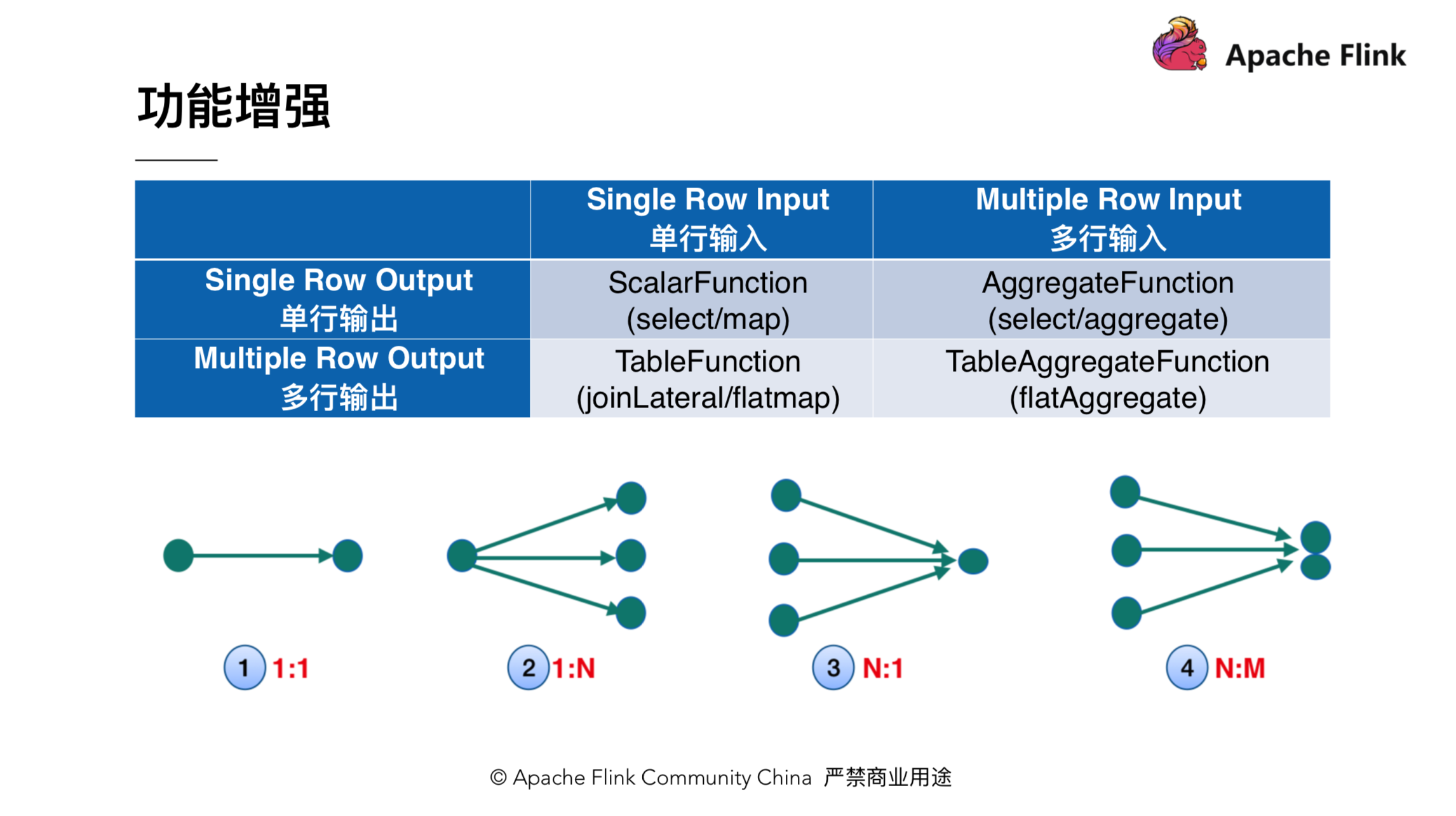
该小节会介绍下 TableAggregateFunction 的功能和用法。在引入 TableAggregateFunction 之前,Flink 里有三种自定义函数:ScalarFunction,TableFunction 和 AggregateFunction。我们可以从输入和输出的维度对这些自定义函数进行分类。如下图所示,ScalarFunction 是输入一行,输出一行;TableFunction 是输入一行,输出多行;AggregateFunction 是输入多行输出一行。为了让语义更加完整,Table API 新加了 TableAggregateFunction,它可以接收和输出多行。TableAggregateFunction 添加后,Table API 的功能可以得到很大的扩展,某种程度上可以用它来实现自定义 operator。比如,我们可以用 TableAggregateFunction 来实现 TopN。
TableAggregateFunction 使用也很简单,方法签名和用法如下图所示:

用法上,我们只需要调用 table.flatAggregate(),然后传入一个 TableAggregateFunction 实例即可。用户可以继承 TableAggregateFunction 来实现自定义的函数。继承的时候,需要先定义一个 Accumulator,用来存取状态,此外自定义的 TableAggregateFunction 需要实现 accumulate 和 emitValue 方法。accumulate 方法用来处理输入的数据,而 emitValue 方法负责根据 accumulator 里的状态输出结果。
三、Table API 动态
最后介绍下 Table API 近期的动态:
1.Flip-29
主要是 Table API 功能和易用性的增强。比如刚刚介绍的 columns 相关操作,还有 TableAggregateFunction。
详见社区对应的Jira链接。
2.Python Table API
希望在 Table API 上增加 python 语言的支持。这个应该是 Python 用户的福音。
详见社区对应的Jira链接
。
3.Interactive Programming(交互式编程)
即 Table 上会提供一个 cache 算子,执行 cache 操作可以缓存 table 的结果,并在这个结果上做其他操作。
详见社区对应的Jira链接。
4.Iterative Processing(迭代计算)
Table 上会支持一个 iterator 的算子,该算子可以用来执行迭代计算。比如迭代 100 次,或者指定一个收敛的条件,在机器学习领域使用比较广泛。
详见社区对应的Jira链接。
更多干货内容参见Apache Flink 零基础入门专题。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论