
在本系列的第 1 部分,我们介绍了在 Azure 上进行网格计算的设计模型。在这篇文章中,我们将用 C#来开发一个网格应用程序以实现这个模式;而在第 3 部分,我们将首先在本地运行这个应用程序,接着在云中运行。为了实现这些功能,我们需要网格计算框架提供的辅助功能。
网格框架的角色
除非你准备编写大量的底层基础软件,那么应该为你的网格应用程序选用一个框架,来消除繁重的工作,让你集中精力于应用程序代码的编写。虽然 Azure 实现了你想在网格计算基础结构中所需的很多服务,但仍然需要在 Azure 和网格应用程序之间添加一些特定于网格的功能。一个优良的网格计算框架应该为你完成如下工作:
- 提供对工作运行的计划调度和控制能力
- 从底层存储中检索输入数据。
- 为网格执行器生成任务以便执行
- 把任务分发到可用的执行器
- 在网格执行应用程序的时候跟踪任务的状态
- 从执行器中收集结果
- 把结果存储到底层存储中
下图显示了框架如何把网格应用程序和 Azure 平台结合到一起。应用程序开发人员只需编写应用程序特定的代码去加载输入数据、生成任务、执行任务和保存结果数据。这个框架提供了全部所需功能——这些功能极大地利用了 Azure 平台的特点。
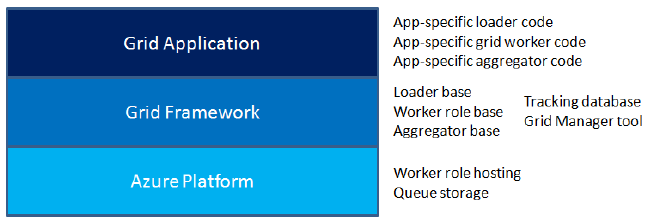
在本篇文章中,我们将利用 Azure Grid ,一个 Neudesic Grid Computing Framework 的社区版本。Azure Grid 提供了 4 个软件组件,来实现列在下面的所有功能:
- 加载器,让你可以添加自己的代码,来从底层资源中提取输入数据并生成任务。
- 执行器角色,让你可以添加自己的代码,来执行应用程序任务。
- 聚合器,让你可以添加自己的代码,来把结果存储回底层资源。
- 网格管理器,让你启动工作运行,并监测它们的执行情况。
Azure Grid 只在你的网格应用程序执行期间才使用云资源,使你的费用尽量最低。底层存储保存着输入数据、结果和 Azure Grid 的跟踪数据库。云存储用于与执行器通信过程的参数传递和结果收集,且在你的网格应用程序执行的时候把它们都清空。一旦你的网格应用程序执行完成,在空闲的时候,你也可以挂起网格执行器的运行实例,那么就无需为存储和计算时间支付持续的费用。
应用程序:Fraud Check
我们将要编码的应用程序是一个虚构的欺诈检查(fraud check)程序,使用某些规则对申请者数据进行计算,以求出欺诈可能性分数。每个申请者的记录都作为一个网格任务来进行处理 。申请者记录具有这样的结构:
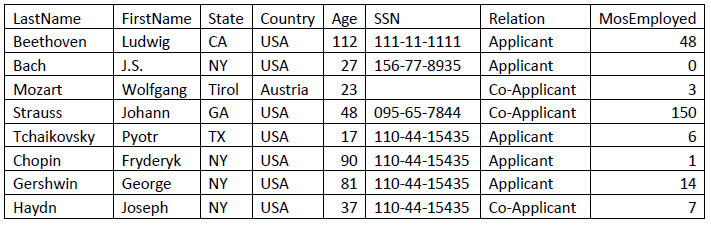
通过在申请者记录上应用业务规则,Fraud Check 程序可算出一个 0 到 1000 之间的欺诈可能性分数,而 0 表示最坏可能的分数。如果分数低于 500,那么申请可能被拒绝。
设计网格应用程序
在你设计网格应用程序的时候,你需要确定能把工作划分到可并行执行的独立任务的最好方法。你首先要考虑 2 个关键问题:
- 你基于什么基础来划分工作为任务?
- 有多少种不同类型的任务?
在 Fraud Check 这个例子中,为每个申请者记录创建单独的任务是很有道理的:为每个记录评出欺诈分数是一个原子操作,而且在所有的记录处理完成后,它们的顺序如何也无所谓。
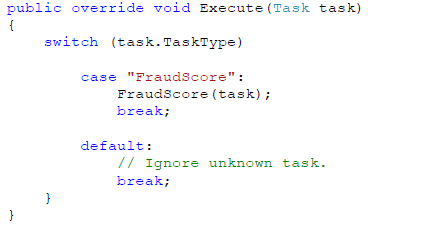
对于 Fraud Check 而言,只需要一种任务类型,我们将其命名为“FraudScore”。FraudScore 任务就是为申请者记录算出欺诈分数。
这些任务需要读取输入数据,生成结果数据。FraudScore 的输入数据也即申请者记录,而结果数据则是欺骗分数加上一个文本字段来解释得到这个分数的原因。FraudScore 所需的参数和返回结果,连同其名称一起显示在下面。
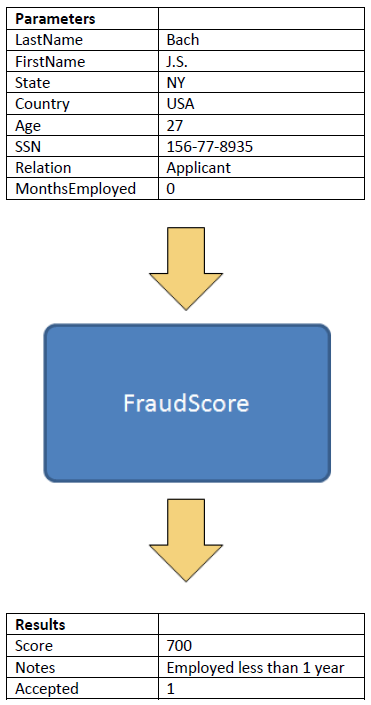
在某些网格计算应用程序中,任务在完成工作的时候可能也需要访问额外的资源,比如数据库或 Web Services。FraudScore 没有这样的需求,不过如果需要的话,可以通过输入参数来提供必需的信息,如 Web Service 地址和数据库连接字符串。
开发网格应用程序
现在,我们的网格应用程序的输入参数、任务和结果字段已经定义好了,我们可以继续编写应用程序了。Azure Grid 只要求我们编写加载器(Loader)、应用程序任务和聚合器(Aggregator)的代码。
编写加载器代码
加载器代码负责读取输入数据,并生成附带参数的任务。大部分时候,这些数据都来自于数据库,不过 Fraud Check 编写成从电子数据表中读取输入数据。
Azure Grid 通过一个名为 AppLoader 的类,为你的加载器提供了一个可以开始编码的模板。需要实现 GenerateTasks 方法,来获取你的输入数据,生成带有任务类型名称和参数的任务。你的代码创建 Task 对象,并作为数组返回。在基类中,GridLoader,把你的任务处理为队列后放到任务执行位置的云存储中。
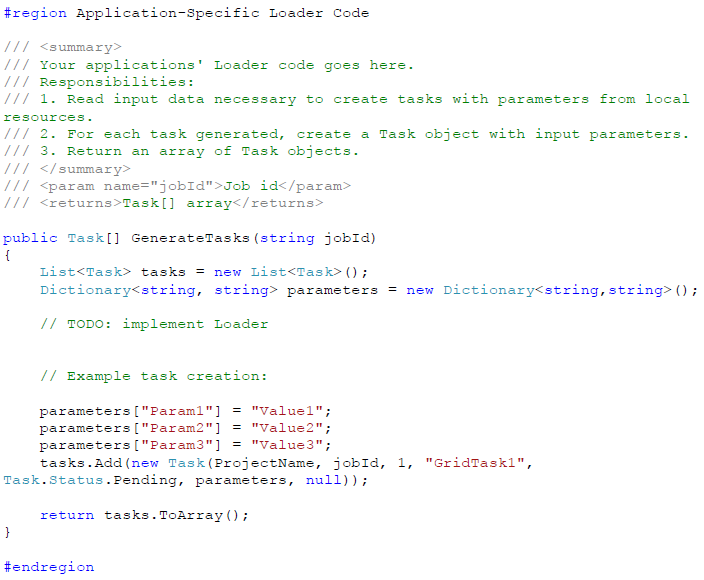
为了实现 Fraud Check 的加载器,我们用下面的代码替换任务创建的示例代码,以从电子数据表 CSV 中读取记录,并为每条记录创建一个任务。

输入的电子数据表的首行应该包含参数名称,而后面的行应该包含值,正如之前显示的那样。创建任务的过程很简单,就是初始化一个 Task 对象,并构造器中赋给它如下信息:
- Project Name:你的应用程序的项目名称。这从配置文件设置中读取。
- Job ID:工作运行的编号,一个字符串。这个值是由外部提供给 GenerateTasks 方法的。
- Task ID:这个任务的唯一标识符,一个整数。
- Task Type:要运行任务的名称。
- Task Status:应该设置为 Task.Status.Pending,以表明这是一个还未运行的任务。
- Parameters:参数名称和值的字典集合对象。
- Results:NULL——结果将由网格执行器在执行任务后来设置。
把 Task 添加到一个列表集合中,就完成了这部分工作。一旦所有的任务都生成好,把 List.ToArray() 作为结果传递给加载器,它就会把这些任务排队到云存储中。
编写聚合器代码
编写好加载器之后,就是聚合器,其处理任务结果,并在本地存储它们。
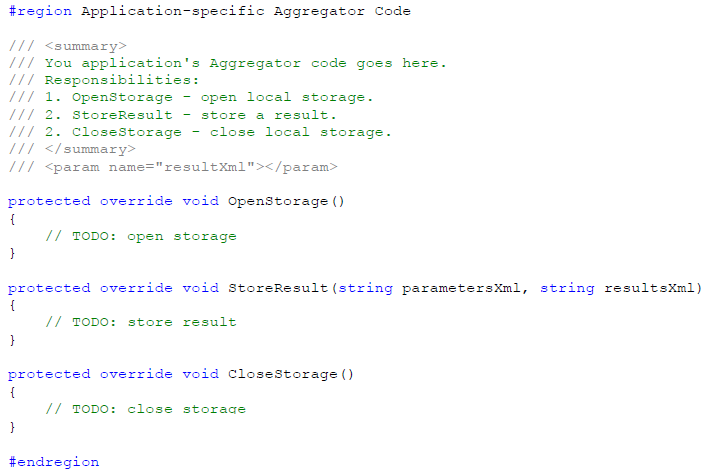
Azure Grid 通过一个名为 AppAggregator 的类,为你的聚合器提供了一个可以开始编码的模板。需要实现 3 个方法:
- OpenStorage,在第一个结果已经准备好可以处理的时候调用,让你有机会打开存储资源。
- StoreResult,在每个结果需要保存的时候调用。输入参数和结果都用 XML 来传递。
- CloseStorage,在最后一个结果已经保存好后调用,让你有机会关闭存储资源。
在基类中,GridAggregator 处理来自云存储中的结果,并调用你的方法来存储这些结果。
在 StoreResult 中,当前任务的参数和结果以如下格式的 XML 来传递:

为了实现 Fraud Check 的聚合器,我们将完成同加载器相反的事情,即把每个结果添加到电子数据表 CSV 文件中。
- 在 OpenStorage 中,打开一个.csv 文件来接受输出,把结果写出到电子数据表 CSV 文件的行列中。
- 在 StoreResult 中,结果(以及包含在这个上下文中的输入参数的第一个和最后一个名称)从 XML 里提取出来,写出到 CSV 文件中。
- 在 CloseStorage 中,文件被关闭。

编写应用程序任务代码
在编写好加载器和聚合器后,还有一块功能需要编写:应用程序代码本身。AppWorker 类用来包含应用程序任务代码。当前任务被传递给一个名称为 Execute 方法,其检查任务类型,以决定执行哪些任务代码。
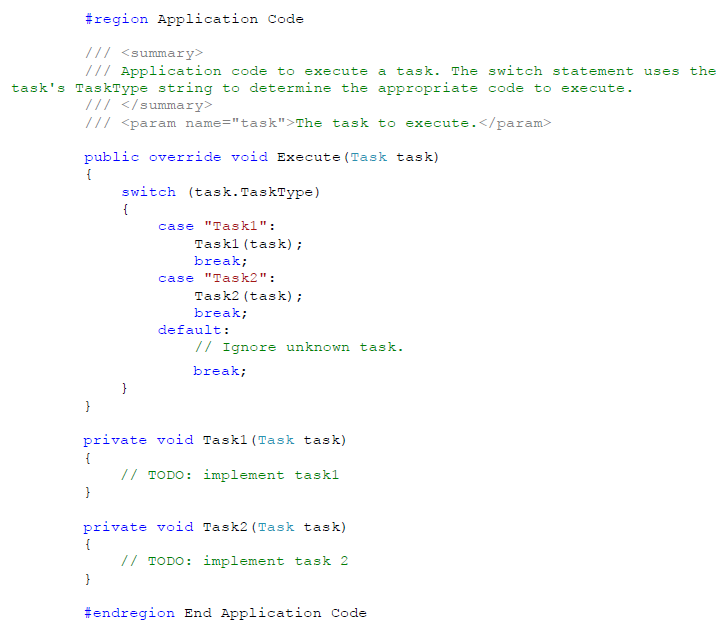
对于 Fraud Check,在我们的应用程序中使用 switch 语句来检查我们任务的类型——FraudScore,并执行代码基于在输入参数中的申请者数据来计算欺诈可能性分数。
FraudScore 代码的首要业务逻辑就是提取输入参数,在 Task 对象中,可以通过名称和字符串值的一个字典集合来逐一访问。

接下来,执行一系列的业务规则算出分数。下面是一个摘录:
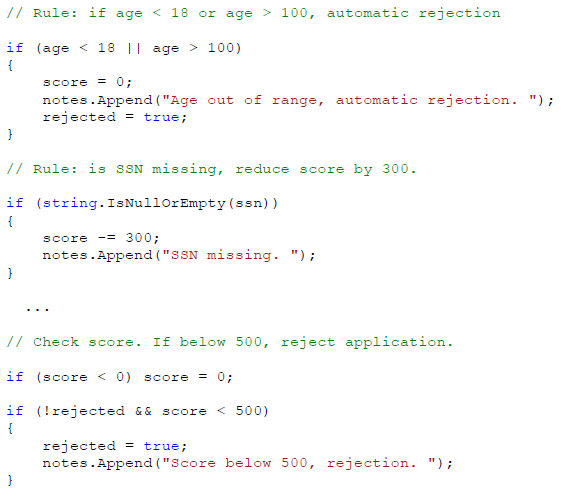
最后,FraudScore 更新任务的结果属性。也是简单地在字典集合中设置名称和字符串值。
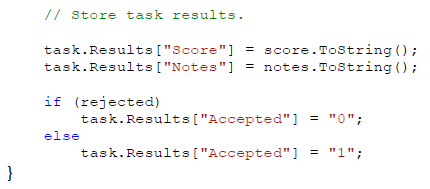
GridWorker 这个基类和 WorkerRole 实现了把结果排队到云存储中,稍后将被聚合器取回。
准备运行
我们已经开发好了自己的网格应用程序,准备来运行它了。稍微回顾一下我们刚刚完成的事情:使用一个框架,实现了加载器、聚合器和任务代码。我们只需编写特定于应用程序的代码。
剩下的事情就是要来运行应用程序。对于网格应用程序,你应该总是仔细测试,且首先在本地用少量任务来运行。一旦你对自己的应用程序设计和代码完整性有把握了,就可以移步到云中大规模的执行了。我们将在本系列的下一篇文章(第 3 部分)中来讲述应用程序的运行。
关于作者
David Pallmann 是 Neudesic 的咨询总监,这个公司是微软金牌合作伙伴和国家系统集成商(National Systems Integrator)。在加入 Neudesic 之前,David 在微软的 WCF 产品团队工作。他出版了 3 本技术书籍,并维护着一个经常更新的 Azure博客。他也是 Azure User Group 的发起成员。
阅读英文原文: Grid Computing on the Azure Cloud Computing Platform, Part 2 。
给 InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。

暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论