

FunCorp 是一家国际性娱乐 App 开发商,知名 App iFunny 就是由 FunCorp 出品的。iFunny 是一款非常有趣的图片和 GIF App,用户可以用它来打发时间,比如看模因、漫画、有趣的图片、宠物 GIF 等,也可以上传和分享自己的内容。iFunny 一直使用 Redshift 作为后端服务和移动 App 的事件存储数据库。他们之所以选择 Redshift,是因为当时从成本和便利性方面来看确实没有更好的选择。然而,ClickHouse 的发布改变了这种状况。他们对它进行了一番彻底的研究,对成本和可能的架构作了一番比较。去年夏天,他们终于决定要尝试一下,看看是否可以使用它。这篇文章将介绍 Redshift 曾经帮助他们解决的挑战,以及他们如何将这个解决方案迁移到 ClickHouse。
我们面临的挑战
iFunny 需要类似 Yandex.Metrika 那样的服务,但要求专门为内部使用而设计。让我解释一下原因。
外部客户端——包括移动 App、网站或内部后端服务——会创建很多事件。如果后端服务出现问题,我们很难向这些客户端说明事件处理服务当前不可用,让它们“在 15 分钟或者一小时后再试一次”。我们有很多客户端,它们持续不断地发送事件消息,一丁点都不想等待。
当然,我们的一些内部服务和用户在这方面却相当宽容:即使分析服务不可用,它们也能够正常运行。大多数产品指标和 A/B 测试每天只需要检查一次,甚至可能更少。这就是为什么读取吞吐量会很低。如果发生故障或进行协调更新,数据库有可能在几个小时内(最坏的情况下可能是几天)不可用或无法保持一致。
从数字方面来看:我们每天需要接收大约 50 亿个事件(300 GB 的压缩数据),同时将数据保存在热存储中三个月,以便为 SQL 查询提供服务。我们还需要将数据保存在冷存储中几年或更长时间,同时能够在短短几天内将数据恢复到热存储中。
通常,我们的数据是按时间排序的事件集。大约有三百种类型的事件,每种事件都有自己的一组属性。我们还有一些来自外部源(例如 MongoDB 或外部 AppsFlyer 服务)的数据需要与分析数据库同步。
最终我们需要为数据库提供大约 40 TB 的磁盘空间,以及大约 250 TB 的磁盘空间用于冷存储。
基于 Redshift 的解决方案
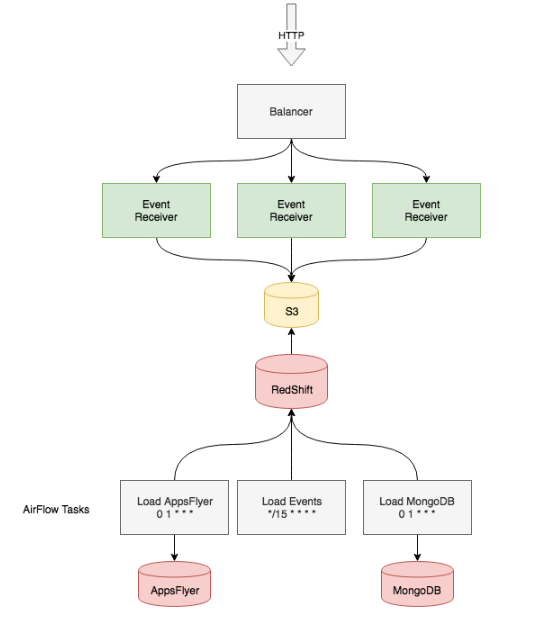
我们有发送事件的移动客户端和后端服务。HTTP 服务接收数据,执行基本的验证,按照分钟将事件分组到文件中,保存在本地磁盘上,然后压缩并发送到 S3 存储。这个服务的可用性取决于应用程序服务器和 AWS S3 的可用性。应用程序是无状态的,所以容易进行负载均衡、缩放和替换。S3 是一个相当简单的文件存储服务,具有良好的声誉和高可用性,我们认为完全可以信任它。
然后我们需要以某种方式将数据发送到 Redshift。这部分相对简单:我们使用内置的 S3 导入器将数据上传到 Redshift。每 10 分钟执行一次脚本,脚本连接到 Redshift,并要求接收以 s3://events-bucket/main/year=2018/month=10/day=14/10_3*为前缀的请求数据。
我们使用 Apache Airflow 来跟踪任务上传状态,可以在发生错误时重启任务,而且它提供了易于读取的任务执行日志,如果任务数量很大,那么这些日志就非常有用。如果我们出现任何问题,可以重复上传特定时间间隔的数据,或者上传 S3 存储中的冷数据,最早可以追溯到一年前。
Airflow 还提供了一些调度脚本,可连接到数据库,并定期从外部存储上传数据或使用类似 INSERT INTO…SELECT…的操作进行事件聚合。
Redshift 的可用性保证很差。AWS 每周一次停止集群进行更新或计划维护,每次最长可达半小时。当一个节点离线时,集群也将变为不可用,直到离线的主机重新上线。这通常需要约 15 分钟,这种情况大约每年发生两次。这对当前系统来说这不是问题,因为我们从一开始就知道数据库会定期不可用。
我们为 Redshift 使用了 4 个 ds2.8xlarge 实例(36 核 CPU、16 个 TB 硬盘),总磁盘空间为 64 TB。
最后一个问题是备份。备份计划可以在集群中设置,运行得非常顺利。
为什么要迁移到 ClickHouse
当然,如果没有遇到任何问题,没有人会想到要迁移到 ClickHouse。我们也不例外。
在将 ClickHouse 的存储模式与 Redshift 进行比较时,我们发现它们的结构非常相似。这两个数据库都是基于列的,它们都擅长处理大量的列和压缩磁盘上的数据(在 Redshift 中,你甚至可以为每个列配置压缩类型)。甚至数据的存储方式都可以是一样的:它们按照主键排序,因此在读取时只读取特定的块,并且不需要在内存中保留特定的索引,这在处理大量数据时起到至关重要的作用。
但是,魔鬼存在于细节之中。
一天一张表
当运行 VACUUM 命令时,数据会在磁盘上排序,并从 Redshift 中删除。
vacuum 过程适用于表中的所有数据。但是,如果三个月的数据都在一个表中,完成这个过程需要很长时间,而我们需要每天至少运行一次,因为在删除旧数据的同时也会添加新数据。我们必须每天创建一张特殊的表,并使用视图合并它们,这不仅使视图轮换和支持变得更加复杂,还减慢了查询速度。“explain”显示,在执行查询时会扫描所有表,即使扫描一张表只需要不到一秒钟的时间,但当我们有 90 张这样的表时,每个查询至少需要一分钟才能执行完。
数据重复
第二个问题是数据重复问题。在线传输数据总会出现两个问题:数据丢失或数据重复。我们不允许丢失消息,所以只能接受出现一小部分重复数据。为了给日数据表去重,我们先创建新表,将旧表中具有唯一 ID 的数据(使用窗口函数删除具有相同 ID 的行)插入到新表中,然后删除旧表并重命名新表。因为视图是从日数据表派生出来的,在重命名表时需要将它们删除。我们还要注意锁,如果收到一个锁定视图或某个表的查询,将会导致这个过程变长。
监控和维护
针对 Redshift 的查询几乎没有几个是少于几秒的。即使你只是想添加用户或列出活跃查询的清单,也需要等待上几十秒。当然,我们习惯了等待,对于这类数据库来说,这样的延迟是可接受的,但不管怎样,我们还是浪费了很多时间。
成本
根据我们的计算,在具有相同资源的 AWS 实例上部署 ClickHouse 只需要一半的成本。这是有道理的,因为 Redshift 是一个开箱即用的数据库。你只需要在 AWS 控制台中单击几下,然后使用 PostgreSQL 客户端连接数据库,剩下的事情就交给 AWS。但这些真的值那么些钱吗?我们已经拥有了基础设施,并且知道如何进行备份、监控和配置内部服务。既然这样,为什么不使用СlickHouse 呢?
迁移
最初,我们部署了一个小型的 ClickHouse:只有一台机器。我们使用内置工具定期从 S3 导入数据。因此,我们能够测试我们对 ClickHouse 性能和功能的假设。在花了几个星期测试一个小数据副本之后,我们找到了在用 Clickhouse 完全替换 Redshift 之前需要解决的一些问题:
应该使用哪些类型的实例和磁盘进行部署?
需要进行复制吗?
如何安装、配置和启动它?
如何监控?
应该使用什么样的 schema?
如何从 S3 将数据发送给它?
如何将所有的标准 SQL 重写为非标准 SQL?
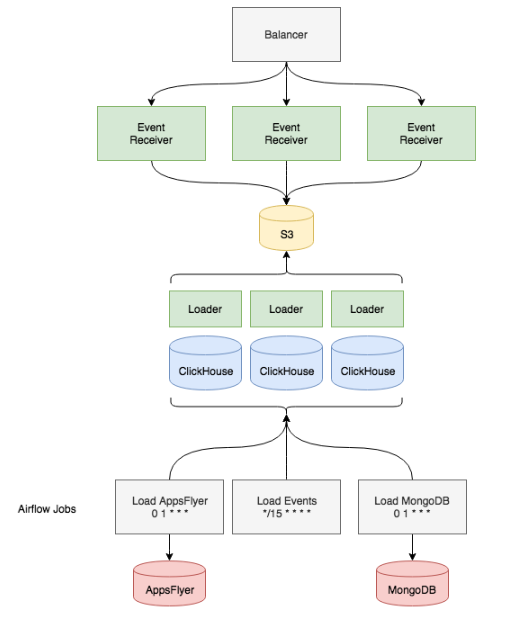
实例和磁盘类型。我们决定使用当前安装的 Redshift 作为参考来确定 CPU 的核心数量、磁盘数量和内存。我们有几种选择,包括带有本地 NVMe 磁盘的 i3 实例,但最终我们选择了 r5.4xlarge 和 8T ST1 EBS 存储。根据我们的估计,这样的性能可能与 Redshift 相当,而价格只有原来的一半。有了 EBS 磁盘,我们就可以通过磁盘快照进行简单的备份和恢复,这与 Redshift 几乎相同。
复制。因为是将现有的 Redshift 配置作为参考,所以我们决定不使用复制。这样做的另一个好处是我们不需要去学习 ZooKeeper,我们的基础设施中本来就没有这项服务(但我们现在可以在需要时进行复制)。
安装。这是最简单的部分,我们只需要用一个 Ansible 角色来安装 RPM 软件包,并在每台主机上使用相同的配置。
监控。我们使用 Prometheus、Telegraf 和 Grafana 来监控所有的服务。我们将 Telegraf 代理安装到 ClickHouse 主机上,并准备了一个 Grafana 仪表盘,用来显示服务器 CPU、内存和磁盘的工作负载。我们使用了一个 Grafana 插件来显示对当前集群的查询情况、从 S3 导入数据的状态以及其他有用的东西。效果比 AWS 控制台提供的仪表盘更好,信息更丰富,速度更快!
schema。我们在 Redshift 中犯的主要错误之一是将主要事件字段保存在单独的列中,然后将其他很少用到的列合并成一个叫作 properties 的列。事实上,在早期我们还不了解所收集的事件以及它们具有哪些属性(它们可能每天变 5 次)时,我们能够灵活地编辑字段。但另一方面,对 properties 列查询所花费的时间越来越长。在 ClickHouse 中,我们决定从一开始就把事情做对,我们采用了所有可能的列,并为它们指定最合适的类型。最终,我们得到了一张包含约两千个列的表。
下一步是为存储和分区选择合适的引擎。
至于分区,我们决定不重新发明轮子:我们重用了在 Redshift 中使用的方法,即每天创建一个分区,只是现在所有分区都存储在一个表中,这大大加快了查询速度并简化了维护工作。我们选择了 ReplacingMergeTree 引擎,因为我们可以使用 OPTIMIZE…FINAL 命令从特定分区中删除重复数据。此外,因为使用了日分区模型,我们只处理一天的数据,如果发生错误或故障,比处理一个月的数据要快得多。
将数据从 S3 传输到 ClickHouse。这是最耗时的过程之一,因为我们无法使用 ClickHouse 的内置工具上传数据。S3 以 JSON 格式存储数据,因此必须通过 jsonpath 提取每个字段,有时候甚至不得不进行转换:例如,将 UUID 从标准格式 DD96C92F-3F4D-44C6-BCD3-E25EB26389E9 转换为字节,并放入 FixedString(16 位)。
我们想要一个类似于 Redshift COPY 命令那样的特殊服务,但无法找到开箱即用的解决方案,所以我们必须自己开发。要描述这个解决方案可能需要另写一篇文章,所以长话短说,它就是一个 HTTP 服务,部署在与 ClickHouse 相同的主机上。在查询参数中,我们指定了 S3 前缀(表示应该从哪里获取文件)、jsonpath 列表(用于将 JSON 转换为一组列),以及每列的转换集。接收查询的服务器从 S3 扫描文件,并将解析任务分配给其他主机。我们需要将无法导入的行保存到单独的СlickHouse 表中,并记录错误消息,这个非常重要。这对于诊断事件处理服务和生成这些事件的客户端来说非常有用。当我们直接将导入器部署在数据库主机上时,我们利用了空闲的资源,因为它们不会全天候接收到复杂的查询。如果查询数量增加,我们还可以将导入器服务移动到独立主机。
从外部导入数据对我们来说并不是个大问题。我们在已有的脚本中将目的地从 Redshift 更改为 ClickHouse。
还有一种办法,就是将 MongoDB 作为字典,而不是每日进行复制。可惜的是,这种方式并不适合我们,因为字典必须始终保存在内存中,而大多数 MongoDB 集合的大小不允许这么做。不过,我们仍然使用了字典,因为从 MaxMind 连接 GeoIP 数据库非常方便,而且在查询时也非常有用。为此,我们使用服务提供的 ip_trie 布局和 CSV 文件。例如,geoip_asn_blocks_ipv4 字典的配置像下面这样:
将这个配置放在/etc/clickhouse-server/geoip_asn_blocks_ipv4_dictionary.xml 中,你就可以通过 IP 地址向字典发出请求以获取提供者名称:
更改数据 schema。如前所述,我们决定放弃复制,因为我们可以承受因发生故障或进行计划维护导致的不可用,而且 S3 中已经保存了一个数据副本,可以在合理的时间内恢复到 ClickHouse。如果我们不使用复制,就不需要部署 ZooKeeper,但少了 ZooKeeper 就无法在 DDL 查询中使用 ON CLUSTER 表达式。我们用一个 Python 脚本解决了这个问题,这个脚本会连接到任意一台 ClickHouse 主机(现在只有 8 台)并执行指定的 SQL 查询。
ClickHouse 对 SQL 的不完整支持。在我们开发导入器的同时,我们将查询语法从 Redshift 转换为 ClickHouse,这个任务主要是由分析师团队完成的。我们的问题主要不在于 JOIN,而在于窗口函数,这看起来可能有点奇怪。我们花了几天时间了解如何使用数组和 lambda 函数来实现它们。庆幸的是,这个问题在 ClickHouse 的众多文章中已经得到了解决,例如,https://events.yandex.ru/lib/talks/5420/。当时,我们的数据同时被记录到两个地方,Redshift 和新的 ClickHouse 数据库,因此我们可以在传输查询时对结果进行比较。尽管如此,要比较性能仍然相当困难,因为我们删除了一个属性列,并且大多数查询只使用了实际需要的列。当然,在这种情况下,性能方面的提升还是很容易看得出来的。对于未解决属性列的查询,具有相当或略高的性能。
结果,数据库 schema 看起来像下面这样:
结果
最后,我们获得了以下这些东西:
一张表,而不是 90 张;
毫秒级的服务查询;
成本减半;
可以简单删除重复事件。
当然也有一些缺点,但我们为它们做好了应对准备:
如果发生故障,我们必须自己恢复集群;
必须分别在每台主机上执行 schema 变更;
我们必须自己更新系统。
我们无法对查询速度进行直接比较,因为数据 schema 发生了很大变化。很多查询的速度得到明显的提升,因为从需要从磁盘读取的数据更少了。
我们花了三个月的时间准备和实现迁移。7 月初,两名专家开始参与该项目,并于 9 月份完成。9 月 27 日,我们关闭了 Redshift。从那时起,我们一直在使用 ClickHouse。已经过去三个月了,时间不算很长,不过我们确实没有遇到会导致整个集群离线的数据丢失或严重错误。我们期待升级到新版本!
英文原文:https://www.altinity.com/blog/migrating-from-redshift-to-clickhouse


暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论