

在分布式系统的架构下,金丝雀用于限制软件版本的波及半径。 根据 Google SRE 手册可知:
为进行金丝雀测试,需要将一部分服务器升级到一个较新版本或配置,随后维持一定时间的孵化期。如果没有出现任何前期未曾预料的问题,发布流程即可继续,其他的软件服务器也会被逐渐升级到新版本。如果出现了问题,这个单独变动过的软件服务器可以很快被还原到已知的正常状态下。
例如,假设您有一项服务,该服务由 100 台运行相同版本 N 的服务器共同支撑,这些服务器均部署在负载均衡器下的云端中,并会占用用户流量。该服务的版本 N + 1 已准备就绪,但仅为 N + 1 版本中创建一个包含 100 台服务器的新集群,并将所有流量切换至新集群中,可能会导致服务中断。 为了进行金丝雀测试,你可能需要这样做:
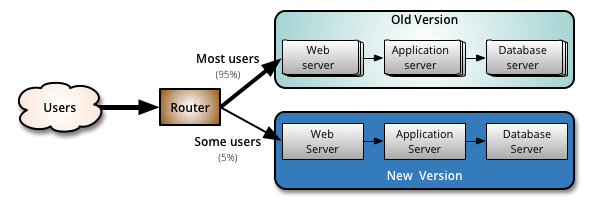
图片源自(https://martinfowler.com/bliki/CanaryRelease.html)
1.为 N + 1 版本创建一个仅有一台服务器的集群,作为金丝雀群集,并将其置于与生产环境集群相同的负载均衡器中;
2.静候一段时间,比如 1 个小时;
3.孵化期过后,以某种方式比较金丝雀和生产环境集群之间的指标(后文将详细介绍);
4.如果指标看起来不错,则继续进行下一步:将版本 N + 1 调整为流量的 X%(例如,扩大金丝雀集群的规模至 X 台服务器,并禁用生产环境集群中的 X 台服务器)。 这可以重复任意多次,直到 X 为 100%,每次多多少少有一定程度的增加。
该过程看起来相对比较简单,但在实践中仍有一些重要的细节需要认真考虑:
在生产环境中进行测试:最好不要将金丝雀测试当成某种常规测试,无论怎么说,这都是不断地将潜在客户置于新开发的软件中,并且您自己对这个软件能否 100%高效运转也没有十足的信心。 金丝雀测试有可能会失败,现实中的客户可能会遇到各种问题。这听起来似乎很正常呀,但也的确需要得到认可和理解。 还有一些其他的潜在道德问题,比如粘性金丝雀问题。
粘性金丝雀:可能有一些错误需在新版本基础上进行多次反复测试才能反应出来,特别是当与金丝雀进行交互时,针对某些状态的改变,比如客户端上的 cookie 等。 如果每个应用需求均独立地随机分配给一个产品或金丝雀案例,则客户不太可能连续多次碰上金丝雀(并因此暴露出该问题)。要解决这个问题,可以实施粘性金丝雀方案,对于金丝雀不仅给予分配一定比例的流量,而且分配一定比例的用户。 这里潜在的道德难题在于,您可能已经彻底破坏小白鼠用户的使用体验,这些使用者已经被绑定到金丝雀“测试单元”上,不管孵化期的时间有多么漫长。 因此,一定要注意此问题,并尽最大可能地将用户尽快转入和离开金丝雀单元,以便用户别总是被这些问题打扰。
客户端错误正处于盲区:客户端错误处于盲点:上面描述的方法只查看服务器指标,而不是客户指标。金丝雀可能会以优异的成绩通过测试,但当它完全扩散时,客户端错误会导致回滚。对于这个问题没有简单的解决方法,尝试将客户机错误与金丝雀测试关联起来将是一件棘手的事情。
关注小型服务:如果上述示例中提到的主要产品群只有 3 台服务器而不是 100 台,并且负载平衡器只是在所有具备可行性的实例中随机循环,则金丝雀案例将占用 25%的用户流量,而不是 1%。 以这种方式运行金丝雀在当下具有重大的事件风险,理想情况下,您的负载平衡器/服务探索机制将允许您控制一定比例的流量,以完成金丝雀集群的正常发送,而不仅仅是那些基于生产环境实例的部分流量。
关注什么指标:之于如何评价金丝雀,可以说是这里面最重要的一部分了。应关注哪些指标,并且如何对它们进行比较?一方面,你只会面对孵化期间的 HTTP 错误率[1](num_http_4XX + num_http_5XX)/ num_requests(这可以防止灾难性的部署,例如某一个服务一直返回 500,但可能会遗漏业务逻辑相关的微妙问题 )。 另一方面,您可以面向服务公开的所有指标(CPU、延迟、内存使用情况、GC 暂停、业务逻辑错误、下游依赖性、缓存命中和丢失、超时、连接错误…)。 该方法存在的问题是,你可能当前正在处理噪声信号。
处理噪声信号:与性能相关的指标(CPU、内存、延迟、GC)具有自然的差异,可能会导致误报,例如由于 CPU 或延迟峰值而导致金丝雀失败。包含这些内容的理由是,我们不希望随着时间累积小的性能回退。虽然这肯定会发生,并且持续的性能监视是必要的,但我不认为金丝雀是检查性能回退的正确地方。您真的想因为 CPU 或内存使用量增加 2%而推迟发布吗?还有其他一些缺点:
如果任何度量标准的偏差都可能导致金丝雀失败,那么金丝雀很可能从各方面来讲均会失败,并且开发人员针对较差的金丝雀结果将不再敏感(有时会因为即使金丝雀的结果不佳但仍推送,从而导致事故)。
包含一个以上的金丝雀实例也许很有吸引力,可以消除嘈杂度量中的尖峰。如果您使用的是简单的负载均衡器,请再次注意小服务,这会使问题变得更糟。
除非存在导致性能随时间下降的资源泄漏问题,否则 prod 集群中的暖实例可能比新加的金丝雀实例具有更好的性能指标。解决这个问题的方法是在版本 N 中引入一个与金丝雀集群同时创建的专用基线集群。然后将探头与新的基线集群进行比较,而不是与生产环境集群进行比较。但还是要注意小服务。
为了测试指标是否噪音过多,可考虑当金丝雀集群与生产环境集群处于相同版本的前提下运行 A / A 金丝雀测试。 如果金丝雀结果较差,问题就显而易见了。
微弱信号:即使在金丝雀中进行了症状指标分析,在完整运行一遍后,金丝雀仍有可能在看起来一切正常的情况下出现事故。 例如,出现的某个错误会让您 0.1%的客户出现极为糟糕的情况:难以在金丝雀中查出该错误,但可能会导致成千上万满是抱怨的电话打过来。 还有另一种情况,您可能需精准排除从分析中得出的微弱信号:例如,假设基线出现了 0 次错误,且金丝雀遇到了 N> 0 次错误:这是通过基线得出的无限百分比偏差,但依然不是较强的信号。
配置不一致:包含太多的度量结果会导致金丝雀配置在团队和服务之间不一致,因此您最终得到的是已知的片状服务,金丝雀总是失败,但你可以四处推送(大多数情况下),以及“看似”健壮的服务,以金丝雀来看表现很好,而实际上也并没有发现问题。如果可能的话,跨服务寻找最小的(因此是一致的)金丝雀配置,以减少与它们相关的认知负担。作为一个推论,在每次事件发生后,你应该考虑抑制想要添加更多指标的冲动(例如,当有人问“为什么这没有被金丝雀逮住?”)。
推送延迟:即使自动化程度很高,如果变更时间长达 4 小时或以上才可运行的话,那么您有可能最多只能每天推送一次,这就需要在开发速度和风险之间权衡一下了。
当心被遗忘的特征标签:带有禁用特性标志潜行特性可能会通过金丝雀测试。很明显,如果启用了它,会在生产环境中爆炸(往好了说,只有特性需要恢复,而不是整体回滚)。作为一种变通方法,可以考虑在默认情况下启用特性标志,并要求进行显式的配置更改去禁用。
毒丸:即使是一个独立的金丝雀案例,如果在整个孵化期间无人看管,也会造成严重的问题(1 小时内出现 200RPS 已经属于错误量较大的情况了)。尽早适当地自动化处理掉较差的金丝雀,无需花太多时间抛出错误。
区域/ DC:如果您部署到多个云区域(或数据中心,云供应商…),则应该在每个区域运行金丝雀测试,因为这些指标表示的只是 N + 1 代码版本在特定环境以及特定的随机配置中的健康状况。 在 AWS / us-east-1 中运行良好的金丝雀结果并不表示你可以随意运行 N + 1 版本,而是指在该时间点上 AWS / us-east-1 中的 N+1 运行情况还不错,运行配置也处于激活状态(包括指定的一组特征标识)。 这意味着我们必须处理不一致的金丝雀结果,同一版本在这个区间内可能结果较好,但在另一区间可能就惨不忍睹了。
另外,在已经被要求撤出的区域,你不可能完全依赖金丝雀(详见 Chaos Kong),所以你的自动化配置必须保证不要延伸到疏散区,否则当流量返回时,你可能会遇到意外情况。
与警报的关联:感觉金丝雀和警报之间应该有一个更紧密的整合,但具体应该怎么做还需要大家后续共同的研究。
查看英文原文: http://dreynaud.fail/canaries-in-practice/

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论